
System Design - Bulkhead Pattern

O termo “Bulkhead” foi amplamente discutido em vários capítulos desta série de artigos, e o objetivo deste é ilustrar as nuances focadas nesse pattern em sua totalidade. Quando discutimos bulkheads, abordamos uma ampla gama de implementações e possibilidades, desde as mais internas, em nível de runtimes, até amplas aplicações arquiteturais e segmentações de operações e clientes. O objetivo deste artigo é ilustrar as principais capacidades desse tipo de pattern, bem como os tipos de vantagens e desvantagens em discussão.
Definindo Bulkheads
O Bulkhead Pattern é um padrão arquitetural de contenção de falhas, mas cujo objetivo central não é evitar que falhas aconteçam, e sim garantir que uma eventual adversidade em uma parte do sistema não se propague e o comprometa por inteiro. Ele parte do pressuposto de que falhas são inevitáveis em sistemas distribuídos e, portanto, devem ser estruturalmente esperadas, limitadas e absorvidas em diversas dimensões.
A essência do Bulkhead não está em mecanismos de retry, timeout ou fallbacks, mas na separação explícita de domínios operacionais. Quando corretamente aplicado, o sistema deixa de ser um bloco homogêneo e passa a se comportar como um conjunto de compartimentos independentes, cada um com capacidade, escalabilidade, limites e impacto bem definidos.
Bulkheads e a Engenharia Naval
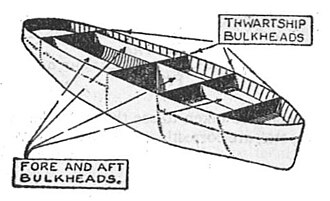
O termo Bulkhead tem sua origem na engenharia naval. Dentro dela, bulkheads são paredes estruturais internas que dividem o casco de um navio em compartimentos isolados, para que, se por ventura ocorrer um dano no casco e um compartimento for perfurado, apenas aquela seção se encha de água, preservando a flutuabilidade do restante da embarcação. O objetivo dessa estratégia não é impedir que o dano aconteça, mas impedir sua propagação e, por sua vez, o naufrágio completo da embarcação. Esse mesmo raciocínio se aplica a sistemas críticos de larga escala e então foi portado para a engenharia de software como um conceito a ser estudado e entendido.
Bulkheads e a Arquitetura de Software
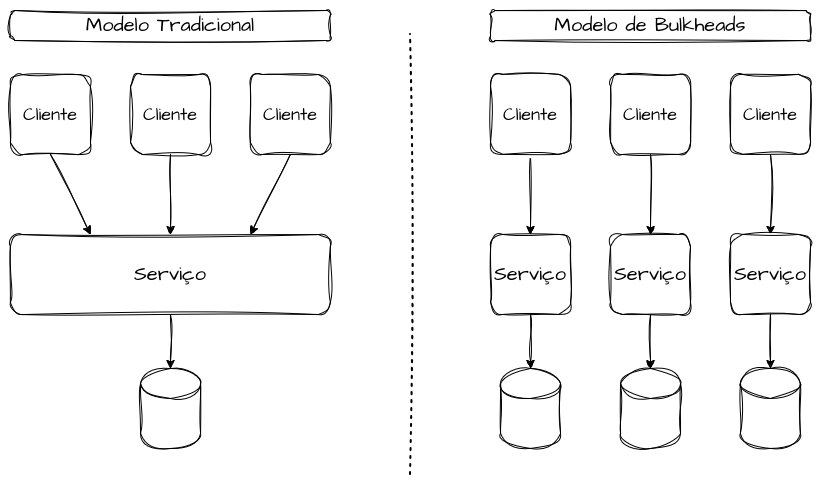
O Bulkhead Pattern é um padrão de design de resiliência aplicado em microsserviços, cujo objetivo é isolar falhas e impedir que um problema em um componente derrube todo o sistema. Na arquitetura de software, um bulkhead representa uma separação explícita e delimitada de recursos e de destinos de execução de transações. A ideia é segregar pools de recursos específicos para evitar que a saturação ou falha de um componente afete outros domínios ou segmentações de clientes de todo o sistema, e representa uma separação explícita de recursos e destinos de execução.
Um erro conceitual recorrente é imaginar que bulkheads precisam existir em apenas uma camada do sistema. Na prática, sistemas resilientes aplicam o mesmo princípio de isolamento de forma consistente ao longo da stack. É comum observar separação no nível de aplicação, mas não no banco de dados ou no isolamento de infraestrutura, mantendo, por exemplo, compartilhamento de filas ou tópicos.
O Bulkhead pode ser aplicado em diferentes dimensões, como pools de threads, filas, tópicos, pools de conexão, bancos de dados, VMs, containers, clusters ou shards. Se dois fluxos compartilham os mesmos recursos, as mesmas conexões ou os mesmos databases, eles não possuem bulkheads, pois a falha de um fluxo inevitavelmente se propaga para os outros.
Quando aplicado de forma correta, o sistema deixa de ser visto como um bloco único e altamente acoplado e passa a se comportar como blocos e partições independentes, cada um com sua própria capacidade, limites, escalabilidade, funcionalidades e usuários bem definidos.
Implementações e Contenção de Falhas
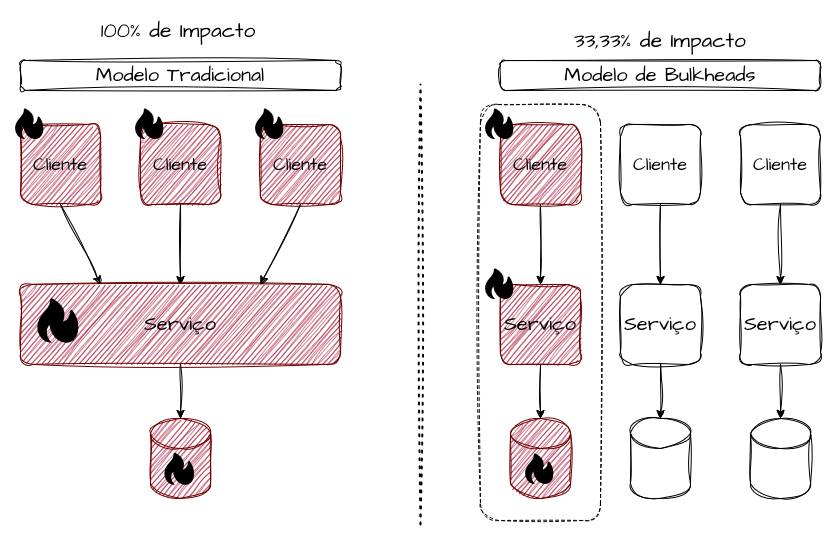
Bulkheads podem ser implementados em diferentes níveis da arquitetura, mas todos compartilham o mesmo objetivo: impedir que a saturação de um recurso consuma a capacidade global do sistema. A implementação correta exige clareza sobre quais recursos são finitos e como eles devem ser particionados. Para direcionar a estratégia de forma correta, precisamos pontuar de forma objetiva quais recursos são finitos no sistema, quais são críticos e como eles devem ser segmentados e, assim, definir formas de identificar, redirecionar, redistribuir e monitorar o tráfego e as operações nesses compartimentos distintos.
Recursos Lógicos
Bulkheads lógicos atuam sobre recursos de execução e concorrência, como threads, filas, conexões e limites de requisição. São os mais comuns e, ao mesmo tempo, os mais frequentemente mal implementados.
Um exemplo é o uso de thread pools dedicados para diferentes tipos de operação. Sem bulkhead, uma operação lenta ou bloqueante pode consumir todas as threads disponíveis, gerando gargalos e filas internas, acarretando saturação e problemas de performance. Com pools dedicados, a falha fica confinada ao fluxo que a originou.
Outro exemplo são filas e tópicos independentes por domínio, evitando que um pico de mensagens em um fluxo impeça o processamento de eventos críticos em outro. Com pools e “gatilhos” sistêmicos segregados, cada tipo de operação possui um limite claro de concorrência. Quando esse limite é atingido, apenas aquele fluxo degrada, enquanto os demais continuam operando dentro de parâmetros aceitáveis. O mesmo raciocínio se aplica a filas e tópicos independentes por domínio ou clientes, evitando que picos de eventos não críticos atrasem ou bloqueiem fluxos essenciais, que são críticos para outro tipo de público ou domínio.
Bulkheads lógicos são frequentemente confundidos com simples aplicações de rate limiting ou com limites globais de concorrência. No entanto, a diferença fundamental está no escopo do impacto. Um limite global protege o sistema como um todo, mas não protege os fluxos críticos entre si. Já o bulkhead lógico cria fronteiras internas, onde cada fluxo opera dentro de sua própria capacidade alocada.
No dia a dia de um time de engenharia, isso se traduz em decisões como pools de threads separados para leitura e escrita, filas distintas para eventos críticos e não críticos, ou até mesmo executores dedicados para integrações externas sabidamente instáveis. Um serviço que consome múltiplas APIs de terceiros não deveria permitir que a lentidão de uma integração consuma os recursos responsáveis por operações internas além desse processo. Cada integração externa representa, por definição, uma superfície de risco distinta e, portanto, merece seu próprio compartimento lógico.
Recursos Físicos
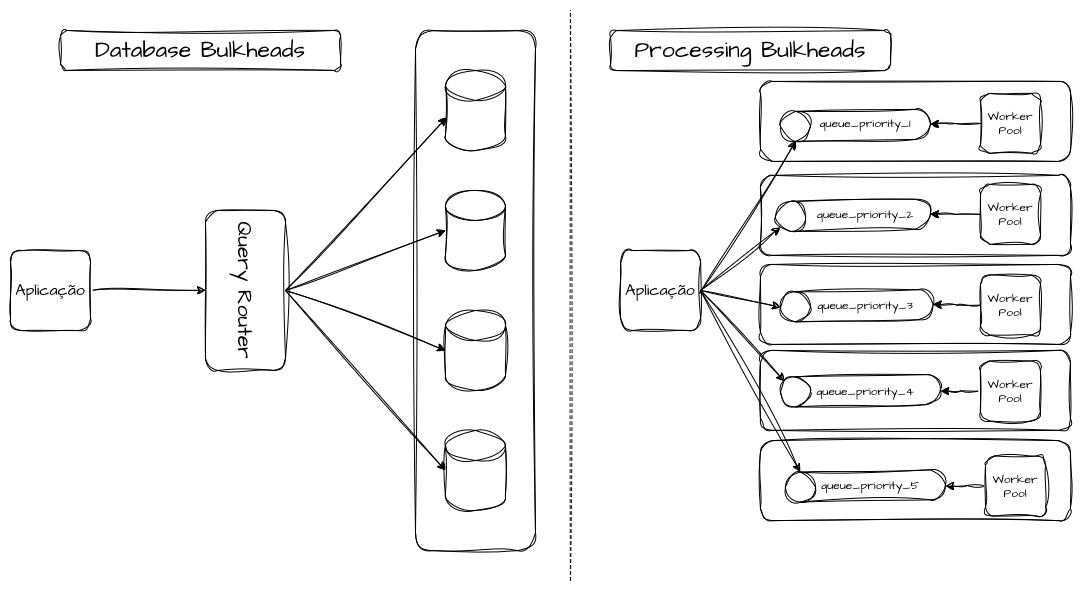
Bulkheads físicos envolvem a separação concreta de infraestrutura, como servidores, nodes, instâncias, zonas de disponibilidade ou até regiões. Aqui, o isolamento passa a ser definitivamente estrutural. Por exemplo, alocar workloads críticos e não críticos nos mesmos nós de um cluster cria um shared fate implícito. A saturação de CPU ou memória por um workload pode derrubar todos os outros. Separar esses workloads em pools de nós distintos cria um bulkhead físico que protege o sistema como um todo. Esse tipo de isolamento é mais caro, mas fornece garantias mais fortes, especialmente em sistemas de alta criticidade.
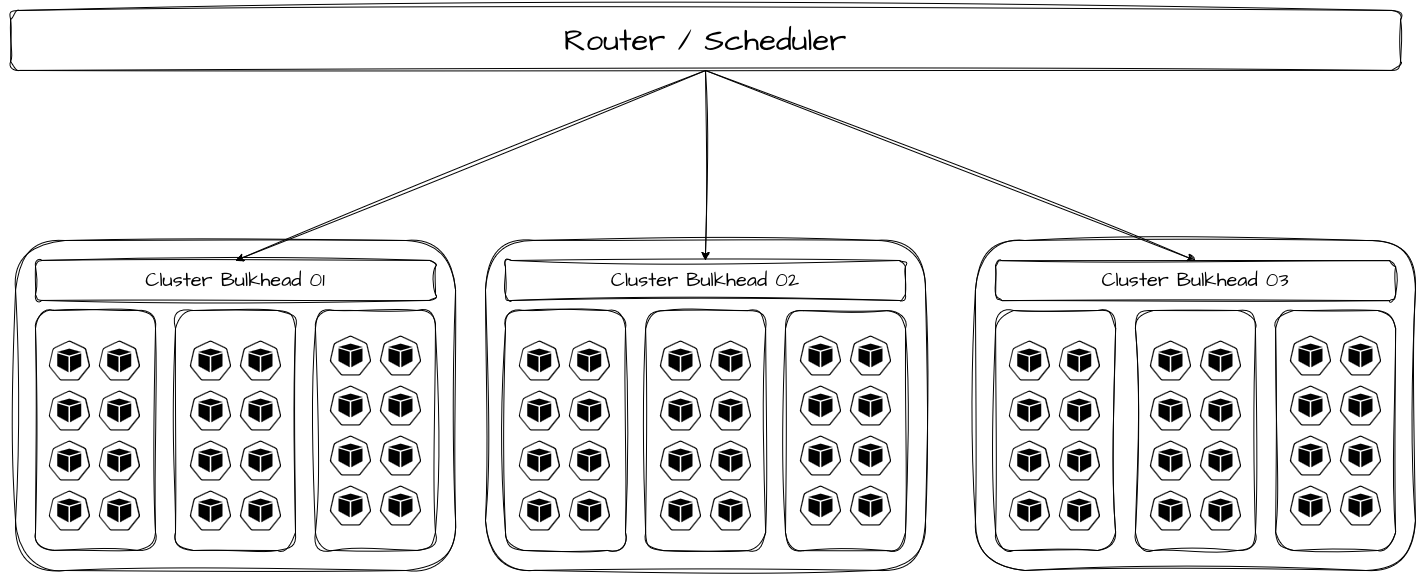
No dia a dia, isso aparece de forma clara em clusters Kubernetes, ambientes de virtualização ou até mesmo em servidores bare metal. Um workload mal dimensionado, com vazamento de memória ou comportamento não linear sob carga pode pressionar o kernel, o scheduler ou o hypervisor, afetando todos os serviços alocados por tabela. Nesse ponto, nenhum thread pool ou fila dedicada é suficiente para conter a falha; é necessária uma segregação física dos recursos. O critério utilizado para isso pode e deve variar, como, por exemplo, tipos de clientes, segmentos, prioridade, criticidade, hashing consistente, identificadores etc.
Bulkheads físicos surgem como resposta a esse tipo de risco. Separar workloads críticos em pools de nós dedicados, usar clusters distintos para domínios com SLOs incompatíveis ou até isolar componentes por região são decisões que aumentam o custo, mas reduzem drasticamente o blast radius.
Distribuição de Bulkheads e Blast Radius
A forma como shards são definidos, roteados e balanceados determina, de maneira explícita, o tamanho do blast radius, o comportamento sob sobrecarga e a previsibilidade da degradação. Em arquiteturas avançadas, sharding deixa de ser um detalhe de armazenamento ou roteamento e passa a ser um mecanismo primário de isolamento operacional.
Cada shard representa, na prática, um bulkhead completo ou parcial. Ele possui capacidade própria, limites próprios e uma curva de degradação própria. A distribuição correta desses shards permite transformar falhas sistêmicas em falhas estatisticamente localizadas. Um pico extremo deixa de ser um evento binário de “o sistema caiu” e passa a ser um evento probabilístico: “X% do sistema foi impactado”.
| Bulkheads | Blast Radius | Disponibilidade | Impacto |
|---|---|---|---|
| 1 | 100% | 0% | Total |
| 2 | 50% | 50% | Muito alto |
| 3 | 33% | 66% | Alto |
| 5 | 20% | 80% | Moderado |
| 10 | 10% | 90% | Moderado |
| 20 | 5% | 95% | Baixo |
| 50 | 2% | 98% | Muito baixo |
| 100 | 1% | 99% | Mínimo |
Quanto maior o número de shards, menor o blast radius, mas maior a complexidade operacional. O ponto central não é apenas quantos shards existem, mas como o tráfego é distribuído entre eles. Distribuições mal balanceadas, chaves de particionamento enviesadas ou algoritmos de roteamento instáveis podem concentrar carga excessiva em poucos shards, anulando completamente o efeito do bulkhead.
Bulkheads e Shardings
Sharding é uma das formas mais poderosas e perigosas de implementar bulkheads. Quando bem aplicado, oferece isolamento estrutural; quando mal projetado, cria acoplamentos invisíveis que só se manifestam sob estresse e acabam não impedindo a propagação de falhas de um recurso isolado. Aqui, é necessário segregar todos os recursos físicos que podem compor o bulkhead, como balanceadores de carga, aplicações, bancos de dados, tópicos, filas e afins, e criar réplicas literais dedicadas apenas para aquele bulkhead, de forma que os fluxos iniciados em uma segmentação do bulkhead permaneçam nele até o fim da execução e, assim, não ofereçam risco de performance e disponibilidade por conta da saturação de uso daquela partição específica do sistema. Outros bulkheads devem estar aptos a executar as mesmas funções, porém com capacidade isolada para outros tipos de públicos e operações.
Eles são especialmente relevantes para lidar com comportamentos não lineares de sistemas sob carga crescente. Em regimes próximos à saturação, pequenas variações de tráfego podem provocar aumentos desproporcionais de latência, consumo de memória, lock contention ou pressão sobre o scheduler. Sem bulkheads, esse comportamento não linear tende a se espalhar por todo o sistema, criando um efeito dominó em que fluxos originalmente saudáveis passam a degradar por compartilharem os mesmos recursos finitos. Tratados como complemento às estratégias de sharding, tendem a elevar os níveis de performance e disponibilidade.
Bulkheads de Sharding Funcional
No sharding funcional, o sistema ou domínio de negócio é dividido por funcionalidades e padrões de uso. Cada shard atende a um conjunto específico de funcionalidades, com recursos próprios e limites bem definidos.
Por exemplo, separar processamento de pagamentos, consultas e relatórios em shards distintos evita que um pico analítico degrade operações críticas de transação. Aqui, o bulkhead é alinhado ao valor de negócio.
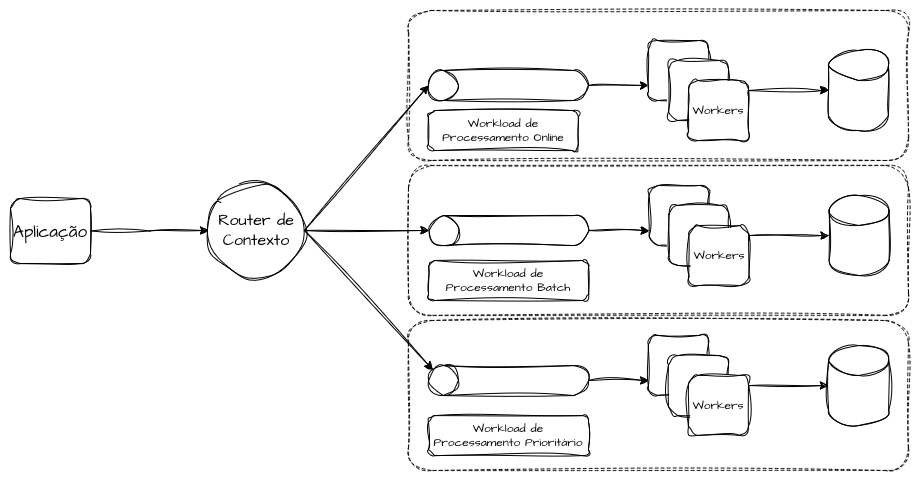
É razoavelmente comum segregar bulkheads específicos para operações transacionais e just-in-time e uma separação dedicada para processamento de lotes e batches. Inserir uma quantidade gigante de processos em repouso para concorrer com fluxos que possuem SLOs e contratos de tempo de resposta e disponibilidade transacionais pode acabar gerando saturação e ofendendo os indicadores. Desse modo, é possível ter infraestrutura dedicada, dentro do possível, para direcionar solicitações em batch ou sincronizações agendadas de outros domínios e parceiros, e outra segregada para as operações convencionais do sistema.
Outra estratégia é ter infraestrutura dedicada para diferentes prioridades de processamento do mesmo tipo de transação, dedicando capacidade exclusiva para transações prioritárias, normais e de baixa prioridade, de forma que, em caso de um spike ou burst de solicitações normais ou de baixa prioridade que cheguem ao sistema, não comprometam as solicitações enviadas para o bulkhead de alta prioridade.
Bulkheads de Sharding Operacional
No sharding operacional, a divisão ocorre por volume ou características de carga, não por função. Exemplos comuns incluem sharding por identificadores de cliente, região ou faixa de tráfego.
Esse modelo é eficaz para limitar o blast radius de picos localizados, mas exige cuidado com operações globais, que podem atravessar múltiplos shards e reintroduzir acoplamento. É comum que shards sejam bem isolados no início, mas gradualmente passem a compartilhar dependências globais, como serviços de configuração, catálogos ou bancos de dados auxiliares. Esses pontos se tornam canais ocultos de acoplamento.
Arquiteturas de Bulkheads
Nesta seção vamos ilustrar algumas das possibilidades de segregação estrutural de bulkheads dentro da arquitetura de software, onde serão apresentadas estratégias para dedicar e isolar capacidade para diferentes tipos de contextos comuns presentes no dia a dia. Muitos deles já foram vistos e citados, mas aqui serão reabordados com uma recapitulação estruturada das estratégias.
Bulkheads por Priorização
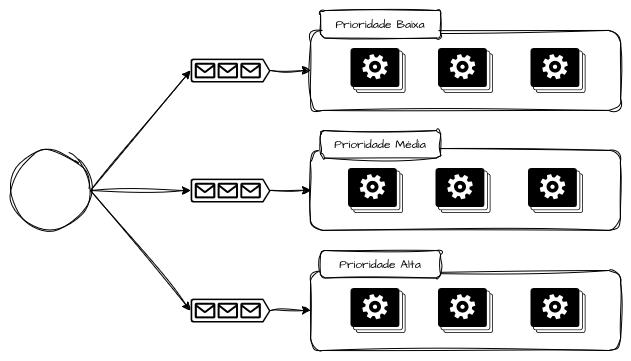
Criar bulkheads de capacidade por priorização parte do princípio de que nem todas as transações possuem o mesmo valor sistêmico em termos de importância. A ideia é garantir capacidade reservada para fluxos com diferentes prioridades, para evitar, por exemplo, que filas FIFO, pools compartilhados ou aplicações generalistas colapsem por bursts ou picos de acesso, fazendo com que requisições críticas concorram e se atrasem por conta de requisições menos relevantes.
Na prática, esse padrão aparece em sistemas financeiros, plataformas de pedidos ou sistemas de autenticação, onde fluxos de escrita transacional, confirmação de pagamento ou autenticação de sessão não podem ser impactados por cargas secundárias, como reprocessamentos, sincronizações ou integrações assíncronas que exijam muito da capacidade computacional.
Bulkheads por Criticidade
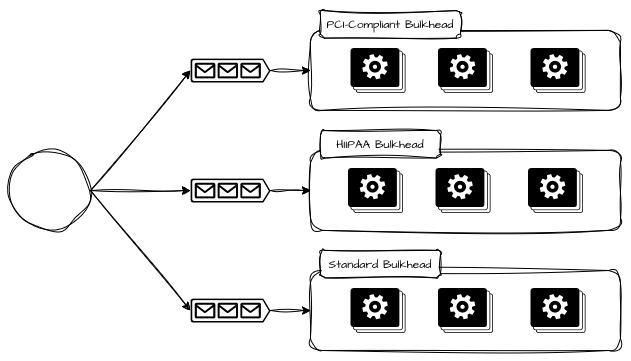
Bulkheads por criticidade vão além da prioridade momentânea e refletem o impacto sistêmico da falha de um fluxo. Enquanto priorização responde à pergunta “o que deve ser atendido primeiro?”, criticidade responde “o que não pode falhar”. Podemos replicar e alocar capacidade computacional para clientes que precisam estar inerentes a infraestruturas auditadas por regulamentações específicas, como, por exemplo, PCI Compliance, certificações ISO ou HIPAA, fazendo com que seja possível atender critérios específicos de isolamento e auditabilidade para cada tipo específico de necessidade.
Bulkheads por Tipo de Uso
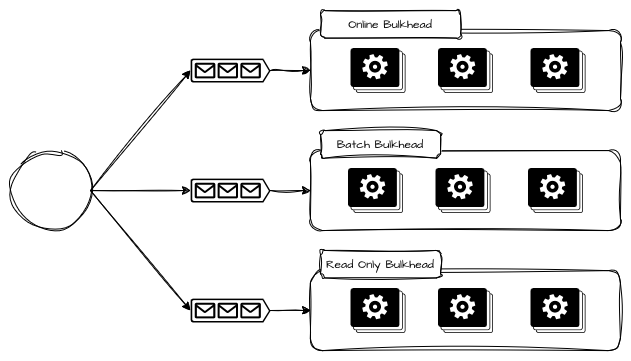
Bulkheads por tipo de uso surgem quando o mesmo sistema atende padrões de carga radicalmente diferentes, e permitem separar usos por fluxos interativos, síncronos e sensíveis à latência de fluxos batch, assíncronos ou orientados a maior throughput. A separação existe porque esses perfis possuem curvas de comportamento opostas, mas precisam da mesma funcionalidade. Operações interativas exigem baixa latência, previsibilidade e rejeição rápida sob sobrecarga. Operações batch toleram latência elevada, mas consomem recursos de forma agressiva e prolongada. Quando ambos compartilham os mesmos recursos, o comportamento batch tende a dominar, pressionando CPU, memória, IO e filas internas, degradando silenciosamente os fluxos interativos.
O bulkhead por tipo de uso não tenta “otimizar” o batch ou operações de leitura intensiva, mas impedir que eles concorram estruturalmente com operações sensíveis. Isso costuma aparecer como filas, workers, clusters ou até pipelines de deploy distintos para cada tipo de uso. O batch pode atrasar, acumular ou até ser pausado, sem que isso altere o SLO das operações online.
Bulkheads por Segmento
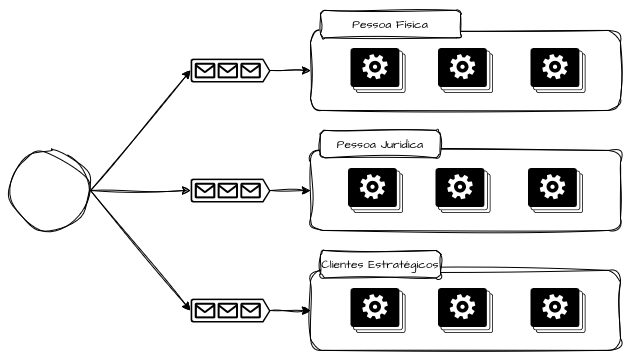
Os bulkheads por segmento tratam explicitamente do problema de heterogeneidade de comportamento entre grupos de usuários, clientes ou regiões. Clientes enterprise, parceiros estratégicos ou segmentos regulados não podem compartilhar o mesmo destino operacional que usuários experimentais, testes A/B ou integrações instáveis.
Sistemas que atendem diversos públicos podem segmentar capacidade operacional para lidar com divergências de criticidade e expectativas, como, por exemplo, públicos de pessoa física, pessoas jurídicas, pessoas publicamente expostas e clientes prioritários. Dessa forma, é possível criar estratégias para que, em caso de contenção de falhas, nem todos os segmentos sejam afetados simultaneamente.
Isso também cria um espaço saudável para negociação de SLOs, precificação diferenciada e evolução independente de capacidade.
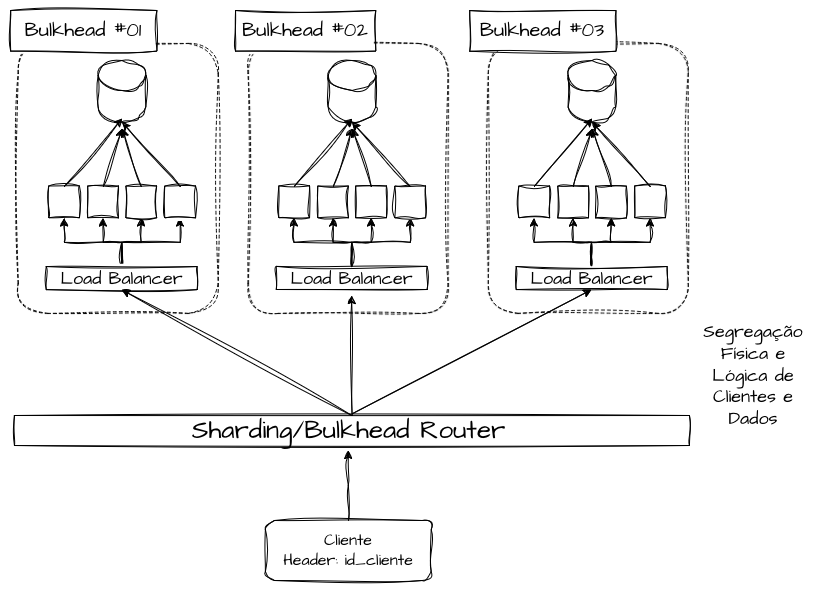
Bulkheads por Hashing Consistente
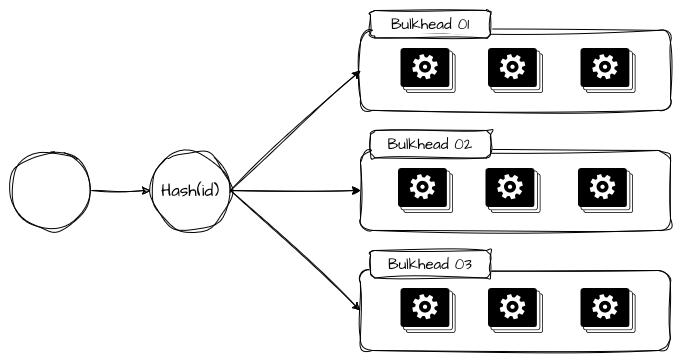
Bulkheads por hashing consistente são a forma mais estatística de aplicar isolamento operacional quando o objetivo é distribuir carga e isolar parcelas de falhas de maneira mais determinística. A ideia é, por meio de um algoritmo de roteamento, proxy ou roteador, utilizar uma chave estável, como tenantId, customerId, accountId ou deviceId, e utilizá-la para enviar as solicitações sempre para o mesmo conjunto de recursos.
Em um balanceamento clássico (round-robin, least-connections), um pico localizado de um único cliente “vaza” para toda a frota, porque o balanceador distribui indiscriminadamente. Com hashing consistente, o pico do cliente fica concentrado no(s) shard(s) aos quais ele foi mapeado.
Bulkheads por Tenants
Isolar tenants vai muito além de separar dados dos mesmos em tabelas ou instâncias de dados diferentes. Trata-se de garantir que o comportamento de consumo, erros ou picos de um tenant não alterem o perfil operacional dos demais. Em plataformas SaaS, isso frequentemente significa criar limites explícitos de capacidade por tenant, combinando bulkheads lógicos e físicos conforme o nível de criticidade e monetização.
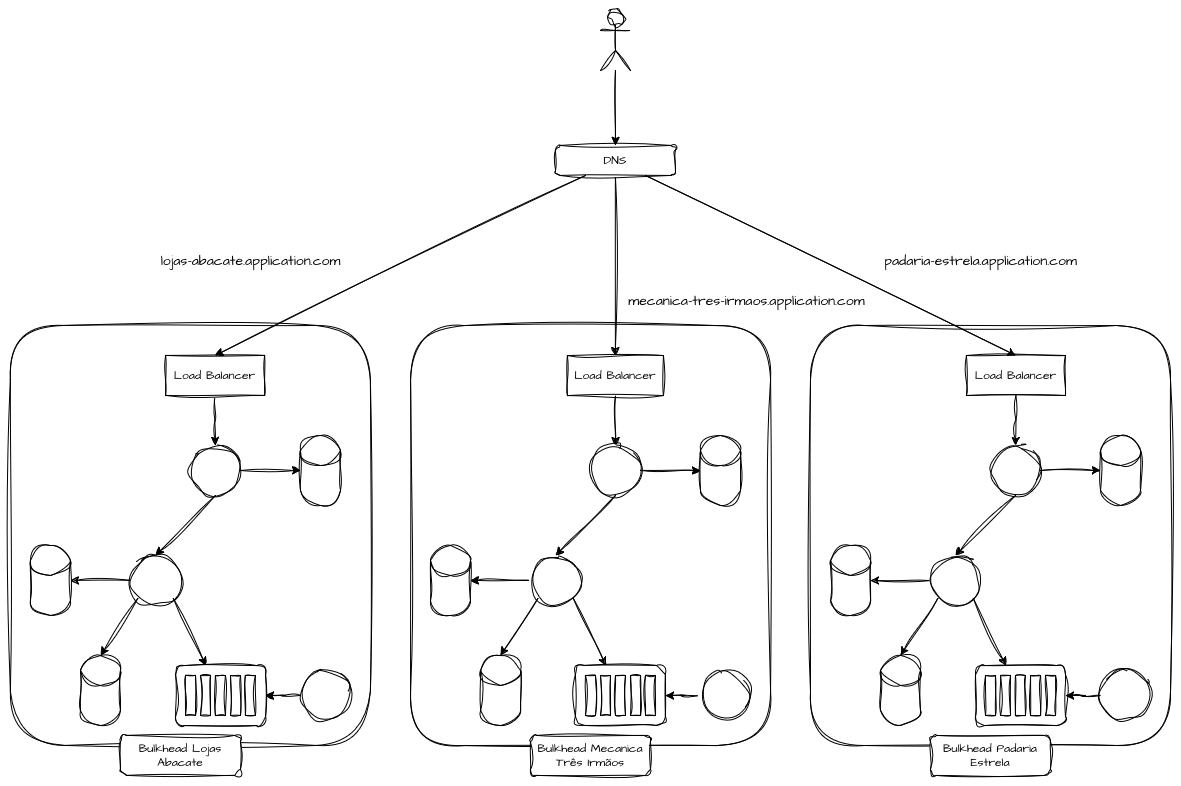
Podemos ter réplicas inteiras de toda a infraestrutura dedicadas para cada um dos tenants, que são roteados por meio de regras de balanceamento, ingress ou DNS, isolando totalmente a operação dos mesmos para evitar noisy neighbor.
No mundo real, é comum observar plataformas que isolam dados, mas compartilham integralmente threads, filas e infraestrutura. O resultado é que um único cliente com comportamento anômalo pode comprometer toda a experiência da plataforma. Bulkheads por tenant transformam esse risco em um problema localizado, em que a degradação é previsível, mensurável e, principalmente, negociável do ponto de vista de negócio.
Noisy Neighbor e Bulkheads Tenants
O problema do “noisy neighbor”, ou vizinho barulhento, surge quando múltiplos tenants compartilham os mesmos recursos físicos e lógicos, e o comportamento de um impacta negativamente os demais. Sem bulkheads, basta um tenant com desvio de comportamento e saturação acima do previsto para degradar toda a plataforma.
Esse problema é especialmente crítico em plataformas SaaS e ambientes multi-tenant de alta escala.
Referências
Bulkhead Pattern — Distributed Design Pattern
Bulkhead Pattern in Microservices
Building a fault tolerant architecture with a Bulkhead Pattern on AWS App Mesh
