
Disaster Recovery — Projetando e Gerenciando Arquiteturas Multi-Region na AWS com Terraform

Este artigo foi o mais longo e cansativo que escrevi em muito tempo, então considere esse disclaimer como um pedido de desculpas escrito após a finalização do mesmo. Recomendo que leia aos poucos, com calma. Entrei em um hiperfoco violento que me fez cuspir tudo que estava na minha cabeça de uma vez, então peço perdão por isso e insisto que você não desista dessa leitura pela extensão.
Refleti muito se deveria lança-lo por partes menores, mesmo não gostando desse modelo. Na verdade nada me deixa mais decepcionado do que estar empolgado na leitura de um artigo e do nada ele acabar no “like pra parte 2”. Então salve esse cara nos seus favoritos e por favor, não desista dele.
Terraform e Disaster Recovery
O Disaster Recovery (Recuperação de Desastres) é uma estratégia essencial para garantir a continuidade dos negócios e a resiliência de sistemas críticos em caso de falhas ou interrupções inesperadas. Com o aumento da dependência de serviços e aplicações na nuvem, a adoção de soluções de recuperação de desastres se tornou ainda mais crucial para proteger os dados e garantir a disponibilidade dos serviços.
Além de ser uma poderosa ferramenta de Infraestrutura como Código, o Terraform pode desempenhar um papel fundamental na implementação de estratégias de chaveamento (failover) e recuperação de desastres (DR) na nuvem. Com sua capacidade de gerenciar recursos de infraestrutura em várias regiões e provedores de nuvem, o Terraform se torna uma escolha natural para automatizar a criação e a configuração de ambientes de chaveamento e DR altamente resilientes.
Neste artigo, exploraremos como o Terraform pode ser utilizado como uma ferramenta abrangente para orquestrar ambientes de chaveamento e DR na AWS (Amazon Web Services). Veremos como podemos aproveitar a flexibilidade e a facilidade de uso do Terraform para criar arquiteturas de failover que garantem a continuidade dos serviços em caso de falhas ou interrupções inesperadas. Como exemplo prático, implementaremos uma proposta funcional de uma arquitetura reduzida que pode se manter funcionando em casos de abordagens ativo/ativo ou ativo/passivo, fazendo uso de algumas estratégias e serviços que possuam features de replicação, balanceamento chaveamento automático, e trabalhando de forma espelhadas entre duas regiões da AWS.
Premissas e estratégias da nossa arquitetura
É possível pensar e filosofar em centenas de possibilidade de se projetar uma estrutura em nuvem, porém a que vamos escolher aqui tem o objetivo central de se manter o mais simples possível e aproveitar o máximo de coisas “as a service” que a AWS oferece por meio dos seus produtos.
Nesse caso, vamos assumir de antemão as seguintes premissas:
- Vamos dar prioridade para o máximo de serviços Serverless possível. Nossa estratégia será desenhada em torno dessas soluções para mantermos o máximo de simplicidade possível. Por serem altamente gerenciados pelos provedores de nuvem, esses serviços costumam ser mais rápidos e fáceis de provisionar e utilizar.
- Vamos dar extrema prioridade para serviços que ofereçam replicação de dados, principalmente que funcionem de forma bilateral e nos facilite na virada e no retorno entre a região primária e de DR de forma rápida.
- Voltando ao tópico anterior, a AWS possui vários e vários serviços que possibilitam trabalhar em Multi-Region de alguma forma, porém a maioria deles serão despriorizados por necessitarem de algum tipo de intervenção manual para o DR, ou que não possibilitem trabalhar ATIVO/ATIVO, como no caso de serviços que mantenham uma região Read Only, Replica e etc.
- Iremos presumir que a estratégia de DR seja executada manualmente e com base em certos critérios estabelecidos de maneira lúdica previamente. Uma forma bonita de dizer que pro DR acontecer, será necessário executar o Terraform por algum lugar, por alguém, por algum motivo.
Terraform em Multi-Region
Configurar o Terraform para trabalhar em multi região na AWS é um passo crucial dentro desta proposta para estabelecer uma estratégia eficaz de Disaster Recovery. Através do uso de variáveis e providers específicos para cada região, você pode garantir que seus recursos críticos sejam replicados e disponibilizados em regiões geograficamente distantes, aumentando a resiliência e a disponibilidade da sua aplicação.
O Terraform suporta múltiplas definições do mesmo provider, sendo diferenciado por um alias para ser referenciado posteriormente. Nesse caso, vamos estabelecer dois providers idênticos da AWS e criar os alias primary e disaster-recovery.
Para essa demonstração iremos assumir a região primary seja em São Paulo (sa-east-1) e a região de disaster-recovery sendo em Norte Virginia (us-east-1).
1
2
3
4
5
6
7
8
9
provider "aws" {
alias = "primary"
region = "sa-east-1"
}
provider "aws" {
alias = "disaster-recovery"
region = "us-east-1"
}
Recursos Modulares — Especialistas ou Genéricos
Para que esta prova de conceito funcione, precisaremos investir em uma arquitetura de Infraestrutura como Código Modular, ou criar objetos de IaC (Infraestrutura como Código) que resolvem problemas de forma padronizada e que podem ser reutilizados diversas vezes, com base em parâmetros de entrada. Isso nos permitirá fornecer o mesmo recurso em ambas as regiões com a mesma linha de base de configuração.
E como fazemos isso?
Para este exemplo, utilizaremos variáveis que são construídas por meio de maps, para então usarmos a função lookup para recuperar os valores. Neste caso, a chave dos maps será o nome da região, ou seja, sa-east-1 e us-east-1. Poderia ser primary ou secondary, active ou passive, ou qualquer outra denominação que faça sentido.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
variable "vpc_cidr" {
type = map(any)
default = {
us-east-1 = "10.0.0.0/16"
sa-east-1 = "172.0.0.0/16"
}
}
variable "public_subnet_1a" {
type = map(any)
default = {
us-east-1 = "10.0.0.0/20"
sa-east-1 = "172.0.0.0/20"
}
}
variable "public_subnet_1b" {
type = map(any)
default = {
us-east-1 = "10.0.16.0/20"
sa-east-1 = "172.0.16.0/20"
}
}
// ...
Nesse caso, encapsulamos a criação de toda a rede da VPC em um módulo e utilizamos o mesmo como fonte duas vezes, passando os mesmos inputs, porém com a busca pela chave da região específica no lookup.
Como definimos no primeiro passo os dois provedores da AWS com seus respectivos alias, precisamos informar ao módulo qual deles deve ser utilizado para criar os recursos.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
module "vpc_sa_east_1" {
source = "./modules/vpc"
providers = {
aws = aws.primary
}
project_name = "primary"
vpc_cidr = lookup(var.vpc_cidr, "sa-east-1")
public_subnet_1a = lookup(var.public_subnet_1a, "sa-east-1")
public_subnet_1b = lookup(var.public_subnet_1b, "sa-east-1")
public_subnet_1c = lookup(var.public_subnet_1c, "sa-east-1")
private_subnet_1a = lookup(var.private_subnet_1a, "sa-east-1")
private_subnet_1b = lookup(var.private_subnet_1b, "sa-east-1")
private_subnet_1c = lookup(var.private_subnet_1c, "sa-east-1")
}
module "vpc_us_east_1" {
source = "./modules/vpc"
providers = {
aws = aws.disaster-recovery
}
project_name = "disaster-recovery"
vpc_cidr = lookup(var.vpc_cidr, "us-east-1")
public_subnet_1a = lookup(var.public_subnet_1a, "us-east-1")
public_subnet_1b = lookup(var.public_subnet_1b, "us-east-1")
public_subnet_1c = lookup(var.public_subnet_1c, "us-east-1")
private_subnet_1a = lookup(var.private_subnet_1a, "us-east-1")
private_subnet_1b = lookup(var.private_subnet_1b, "us-east-1")
private_subnet_1c = lookup(var.private_subnet_1c, "us-east-1")
}
Uma pausa do decoro
Eu sei que quem acompanha os meus artigos anteriores vai se sentir um pouco estranho lendo este. Estou intencionalmente tentando escrever algo de forma mais séria, e isso vai acontecer. Mas antes, preciso de uma pausa antes de continuarmos para alinhar algumas premissas:
- Puts, mas eu prefiro trabalhar com Workspaces / Tfvars em vez de modular: O céu é o seu limite!
- Prefiro separar tudo e trabalhar com tfvars separadas em vez de lookups: Te amo, você é incrível!
- Acho que fazer um módulo que entrega nas duas regiões é melhor: segura na mão do pai e vai
- Acho isso ruim, prefiro separar tudo e disponibilizar os outputs de outras formas: confia no seu potencial, você é incrível
- No mais: Apega-se mais na mensagem do que na cor da meia do carteiro.
Voltamos…
Parte 1: Ingress e o Fluxo Síncrono
Na primeira parte deste artigo, vamos nos concentrar em como funcionará o fluxo síncrono de consumo do nosso serviço, considerando a necessidade de consumir uma API REST que é atendida por N aplicações (nesse escopo reduzido, apenas uma).
O nosso fluxo síncrono é bastante simples, e o caminho para atender a uma requisição será o seguinte:
- Route53: Faremos o apontamento e chaveamento de DNS por meio do Route53. Ele nos permite gerenciar e redirecionar o tráfego de forma eficiente para o local correto. Aprenderemos como utilizá-lo para chavear o tráfego entre a região primária e as de disaster recovery.
- Custom Domain Name: Utilizaremos o Custom Domain Name para gerenciar o domínio e o certificado HTTPS/SSL da nossa API. Isso garantirá a segurança das comunicações entre o cliente e a nossa infraestrutura.
- API Gateway Regional: A exposição da API na DMZ (zona desmilitarizada, vulgo internet, terra de ninguém) será realizada por meio do API Gateway Regional. Ele nos permitirá disponibilizar a API para o consumo externo.
- Network Load Balancer: O Network Load Balancer funcionará como um VPC Link, direcionando o tráfego externo para dentro da nossa VPC (Virtual Private Cloud). Ele será responsável por encaminhar as requisições recebidas do API Gateway na internet para dentro da nossa infraestrutura de forma segura e correta.
- Application Load Balancer: A gestão da camada 7 das aplicações que compõem o nosso Workload será feita pelo ALB, Application Load Balancer. Ele nos permitirá distribuir o tráfego de maneira eficiente entre os diferentes containers que executam a nossa aplicação REST. Essa camada 7 é responsável por processar solicitações HTTP e HTTPS.
- Aplicação REST: A aplicação REST será executada em containers, que podem estar em qualquer lugar, nesse caso, utilizaremos o ECS (Elastic Container Service). O ECS nos oferece um ambiente flexível para executar nossos containers, garantindo escalabilidade e disponibilidade de forma estupidamente simples.
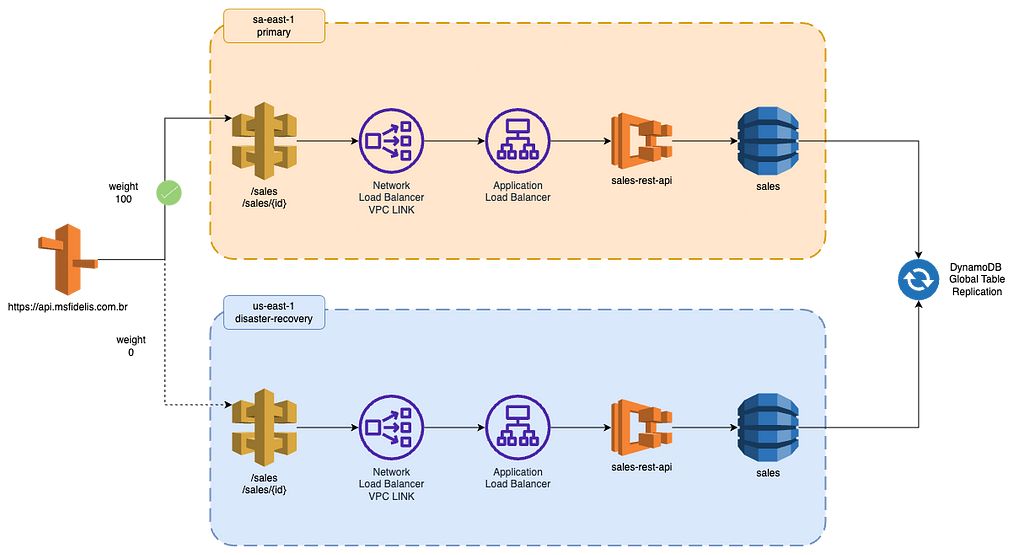
Seguindo a premissa inicial utilizando a VPC de exemplo, vamos entregar todos os recursos de forma duplicada, usando as duas configurações de provedores configurados nas duas zonas de disponibilidade.
1.1 — API Gateway Regional
Neste exemplo, optamos por encapsular todos os mapeamentos da nossa API dentro de um módulo dedicado do API Gateway. Ao contrário de um módulo genérico que poderia ser replicado para diversos cenários, o objetivo deste módulo é fornecer todos os mapeamentos para todo o workload. Essa abordagem simplifica o encapsulamento de todas as definições do OpenAPI 3.0 e facilita o entendimento da proposta.
É importante ressaltar que também é possível criar um módulo que aceite o OpenAPI de forma genérica, o que seria uma opção viável em um ambiente de trabalho. Optei por seguir dessa forma por praticidade do exemplo.
É importante considerar que o API Gateway é um recurso provisionado fora da VPC, o que significa que não temos controle físico direto sobre ele, como saber em qual Zona de Disponibilidade de determinada região ele está alocado. Nesse caso específico, é necessário fazer o deployment do API Gateway em modo Regional.
Embora o API Gateway seja um recurso externo à VPC, o modo Regional de implantação nos permite ter uma visibilidade clara sobre a região em que a distribuição será entregue, o que é fundamental para garantir o controle que estamos almejando para o chaveamento dos workloads.
Para mais detalhes, o módulo do gateway da aplicação está aqui.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
module "api_gateway_app_demo_sa_east_1" {
source = "./modules/api-gateway-app-demo"
providers = {
aws = aws.primary
}
gateway_name = "app-demo"
stage_name = "prod"
vpc_link = module.cluster_sa_east_1.vpc_link
}
module "api_gateway_app_demo_us_east_1" {
source = "./modules/api-gateway-app-demo"
providers = {
aws = aws.disaster-recovery
}
gateway_name = "app-demo"
stage_name = "prod"
vpc_link = module.cluster_us_east_1.vpc_link
}
1.2 — ACM Regional
Para garantir um deployment confiável, também faremos o deploy do ACM (AWS Certificate Manager). O ACM é um serviço gerenciado pela AWS que permite provisionar, gerenciar e implantar certificados SSL/TLS (Secure Sockets Layer/Transport Layer Security) para uso em serviços da AWS, incluindo o API Gateway.
Ao utilizar o ACM, facilitamos a aquisição, implantação e renovação automática de certificados SSL/TLS, garantindo comunicações seguras entre os clientes e os recursos da AWS. Nesse caso, utilizaremos o ACM para garantir a segurança do domínio em um nível regional.
É importante ressaltar que as duas regiões provisionarão certificados com o mesmo nome. Essa duplicação é necessária para que possamos associar os Custom Domain Names e API Gateways específicos de cada região.
Exploraremos esse tópico no próximo tópico do artigo.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
module "acm_sa_east_1" {
source = "./modules/acm"
providers = {
aws = aws.primary
}
domain_name = format("*.%s", var.route53_domain)
route53_zone_id = var.route53_hosted_zone
}
module "acm_us_east_1" {
source = "./modules/acm"
providers = {
aws = aws.disaster-recovery
}
domain_name = format("*.%s", var.route53_domain)
route53_zone_id = var.route53_hosted_zone
}
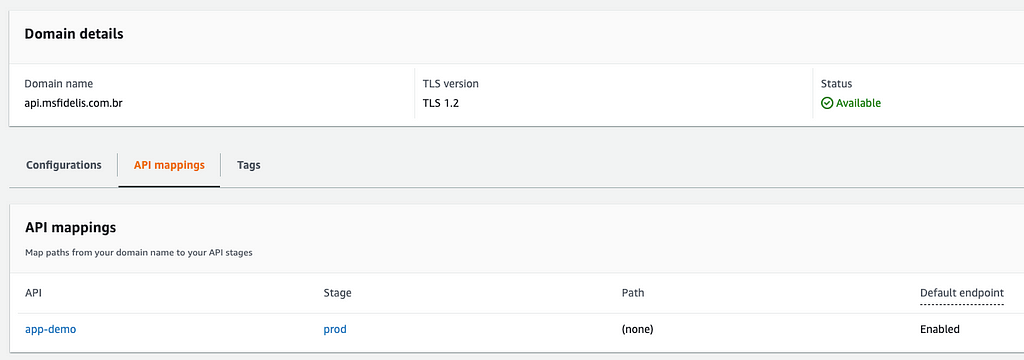
1.3 — Custom Domain Name
O Custom Domain Name é a porta de entrada funcionando como um roteador de API Gateways, é onde vamos definir um domínio human-like e realizar os devidos mapeamentos. Nesse exemplo, vamos fazer um redirecionamento completo de tudo que bater nesse domínio, mas é uma das capacidades do Custom Domain Name permitir que diversos API Gateways sejam expostos através de um único domínio.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
module "custom_domain_sa_east_1" {
source = "./modules/api-gateway-custom-domain"
providers = {
aws = aws.primary
}
acm_arn = module.acm_sa_east_1.arn
api_gateway_domain_name = var.api_gateway_domain
base_path_mappings = [
{
base_path = "/",
api_id = module.api_gateway_app_demo_sa_east_1.id,
stage = module.api_gateway_app_demo_sa_east_1.stage,
}
]
}
module "custom_domain_us_east_1" {
source = "./modules/api-gateway-custom-domain"
providers = {
aws = aws.disaster-recovery
}
acm_arn = module.acm_us_east_1.arn
api_gateway_domain_name = var.api_gateway_domain
base_path_mappings = [
{
base_path = "/",
api_id = module.api_gateway_app_demo_us_east_1.id,
stage = module.api_gateway_app_demo_us_east_1.stage,
}
]
}
1.4 — Route53, Gestão de DNS
Uma parte fundamental para uma estratégia de Disaster Recovery em multi-região é a capacidade de realizar o chaveamento (failover) entre os sites de forma automática e rápida. Para realizar essa tarefa, vamos utilizar o Amazon Route53, que é o serviço de DNS da AWS, junto ao Terraform para automatizar o processo de failover.
Vamos assumir que nossa zona já está criada e vamos referenciá-la com base na variável hosted_zone_id para criar os recursos de chaveamento.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
variable "route53_hosted_zone" {
type = string
default = "Z102505525LUE9SZ7HWTY"
}
variable "route53_domain" {
type = string
default = "msfidelis.com.br"
}
variable "api_gateway_domain" {
type = string
default = "api.msfidelis.com.br"
}
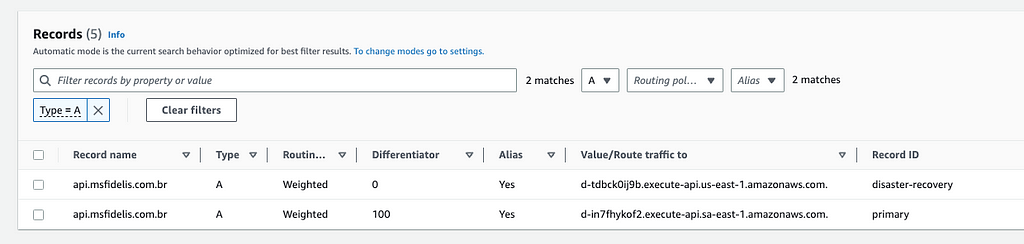
Chaveamento entre as Regiões da AWS
Com base nas premissas iniciais, a proposta é fornecer um chaveamento simples, no qual apenas um commit, uma rodada de pipeline, um apply, seja possível redirecionar todo o tráfego para uma ou outra região de DR.
Vamos manipular uma variável chamada state, onde em cada chave de região vamos manter as strings ACTIVE e PASSIVE. Com base nesses valores vamos decidir muita coisa.
1
2
3
4
5
6
7
variable "state" {
type = map(any)
default = {
"sa-east-1" : "ACTIVE",
"us-east-1" : "PASSIVE",
}
}
Com base no valor dessa variável, podemos definir por exemplo o quanto queremos setar de peso entre os records
1
lookup(var.state, "região") == "ACTIVE" ? 100 : 0
Com base no valor ACTIVE, podemos configurar no Route53 um redirecionamento com weight policy de peso 100, e para o valor PASSIVE um peso 0. Invertendo os valores dessas variáveis, temos a flexibilidade de desabilitar o roteamento de DNS da região sa-east-1 e direcionar todo o tráfego para us-east-1, conforme os pesos atribuídos.
Adicionalmente, é viável configurar ambas as regiões como ACTIVE, o que possibilita a implementação de um balanceamento Round Robin na resolução de nomes, distribuindo as cargas de trabalho entre as duas regiões de forma equilibrada.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
resource "aws_route53_record" "primary" {
provider = aws.primary
zone_id = var.route53_hosted_zone
name = var.api_gateway_domain
type = "A"
weighted_routing_policy { <-------------
weight = lookup(var.state, "sa-east-1") == "ACTIVE" ? 100 : 0
}
set_identifier = "primary"
alias {
evaluate_target_health = true
name = module.custom_domain_sa_east_1.regional_domain_name
zone_id = module.custom_domain_sa_east_1.regional_zone_id
}
}
resource "aws_route53_record" "dr" {
provider = aws.disaster-recovery
zone_id = var.route53_hosted_zone
name = var.api_gateway_domain
type = "A"
weighted_routing_policy { <-------------
weight = lookup(var.state, "us-east-1") == "ACTIVE" ? 100 : 0
}
set_identifier = "disaster-recovery"
alias {
evaluate_target_health = true
name = module.custom_domain_us_east_1.regional_domain_name
zone_id = module.custom_domain_us_east_1.regional_zone_id
}
}
Exemplo do DR desligado
1
2
3
4
5
6
7
variable "state" {
type = map(any)
default = {
"sa-east-1" : "ACTIVE",
"us-east-1" : "PASSIVE",
}
}
Exemplo do DR Ligado
1
2
3
4
5
6
7
variable "state" {
type = map(any)
default = {
"sa-east-1" : "PASSIVE",
"us-east-1" : "ACTIVE",
}
}
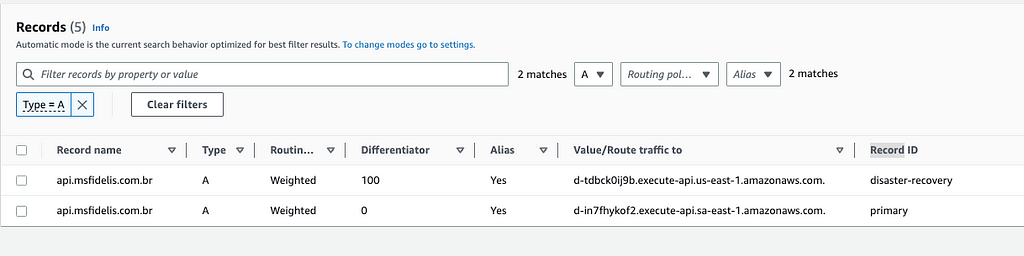
Exemplo do DR Ativo/Ativo
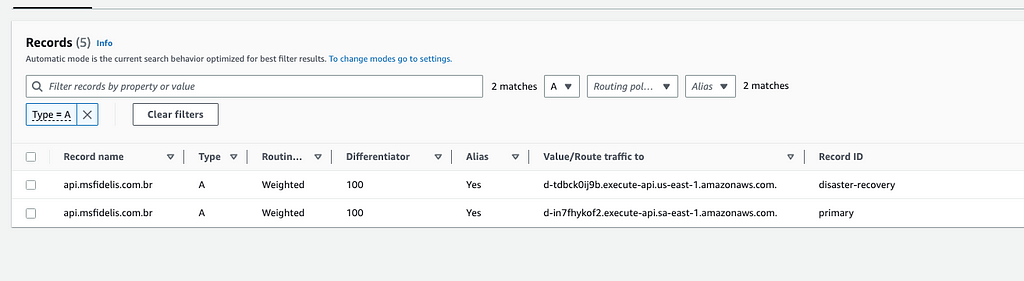
1
2
3
4
5
6
7
variable "state" {
type = map(any)
default = {
"sa-east-1" : "ACTIVE",
"us-east-1" : "ACTIVE",
}
}
Parte 2: Computing
Parte crucial pra uma estratégia de DR funcionar, é escolher como rodar nossas aplicações. Essa decisão precisa levar em conta o quão replicável a forma como publicamos e fazemos a governança desses serviços é. No o modelo computacional que cabe como uma luva são containers, e principalmente opções Serverless como o AWS Lambda, e na intersecção entre os dois modelos, o AWS Fargate que tem opções de rodar no modelo de EKS (Elastic Kubernetes Service) e de ECS (Elastic Container Service).
Como você vai fazer e qual modelo e tecnologia você vai usar é necessário uma análise cuidadosa a respeito das skills do time e do nível de complexidade que você quer atingir ou evitar com sua arquitetura no fim do dia. Neste exemplo vamos utilizar containers, rodando em ECS Fargate. Poderia ser um EKS, Nomad, o Próprio Lambda tranquilamente. O importante é que consigamos replicar nosso serviço em qualquer lugar, isso inclui poder parametrizar os recursos externos por meio de variáveis ambiente, gestão de secrets para que o serviço em si funcione de forma padronizada, porém consumindo diferentes recursos em diferentes apontamentos.
A partir daqui vou reduzir os exemplos de código, porém você pode acompanhar tudo que foi desenvolvido nessa PoC através deste repo, e vou deixando pontualmente os links para os respectivos módulos.
Modulo do Cluster ECS Disponível Aqui
Modulo do Service ECS Disponível Aqui
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
module "cluster_sa_east_1" {
source = "./modules/cluster"
providers = {
aws = aws.primary
}
cluster_name = "my-demo"
vpc_id = module.vpc_sa_east_1.vpc_id
subnets = module.vpc_sa_east_1.private_subnets
route53_private_zone = var.route53_private_zone
}
// ...
module "app_demo_sa_east_1" {
source = "./modules/service"
providers = {
aws = aws.primary
}
vpc_id = module.vpc_sa_east_1.vpc_id
cluster_name = module.cluster_sa_east_1.cluster_name
route53_zone = module.cluster_sa_east_1.private_zone
service_name = "sales-api"
service_image = "fidelissauro/sales-rest-api:latest"
service_port = 8080
service_hostname = [
format("app-demo.%s", var.route53_private_zone)
]
// ...
envs = [
{
name : "AWS_REGION",
value : "sa-east-1"
},
{
name : "DYNAMO_SALES_TABLE",
value : aws_dynamodb_table.sales.name
},
{
name : "SNS_SALES_PROCESSING_TOPIC",
value : module.sales_sns_sa_east_1.arn
},
{
name : "SSM_PARAMETER_STORE_STATE",
value : module.ssm_parameter_state_sa_east_1.name
}
]
}
Parte 3: Dados - A real dificuldade
Talvez a parte mais importante e complexa de todo plano de Disaster Recovery, trabalhar com os dados.
É fundamental garantir a integridade dos dados durante o processo de recuperação. Os dados devem ser replicados ou backup em tempo real para garantir que não haja perda ou corrupção de dados durante uma interrupção.
E mais difícil que virar para o DR, e garantir que os dados estarão lá disponíveis para serem consumidos, mesmo que com algum delay ou com consistência eventual, é voltar ao estado original.
Voltar ao Site/Região/DC primário com os dados que foram alterados durante o tempo de atividade da Região de DR é extremamente complexo, porém dentro do ferramental que a AWS nos dispõe é razoavelmente simples se tomarmos as decisões arquiteturais corretas.
Nessa parte do artigo, vamos detalhar como criar um fluxo de dados resiliente e eficiente, pensando em replicação bilateral de todas as fontes de dados, offload de processamento, mensageria e eventos, tudo pensado para que exista uma sincronia e replicação com tempo considerável das duas regiões, para que seja possível chavear, deschavear e manter as duas ativas ofertando os mesmos dados de ambas as partes.
Nesse parte vamos tornar possível:
- SNS e SQS Multi-Region
- DynamoDB Global Tables
- Two-way replication no S3
No final, iremos chegar em uma solução parecida com essa entre as duas Regiões.

3.1 — Eventos e Mensageria; SNS e SQS Multi Region
No nosso fluxo hipotético presume que nossa aplicação REST, durante o registro de uma venda, salve um registro de venda no Dynamo, publique uma mensagem para processamento posterior desse item. Para essa solução vamos inserir um fluxo:
- App REST -> SNS Topic -> SQS Queue -> Aplicação Worker -> Dynamo
Porém para garantir as premissas de replicação, e garantir que uma mensagem recebida por uma região seja replicada automaticamente para a outra, precisamos fazer uso do SNS Cross-Region Delivery.
O SNS Cross-Region Delivery (Entrega Inter-regional do SNS) é um recurso fornecido pelo Amazon Simple Notification Service (SNS) que permite enviar notificações entre regiões na AWS. O SNS é um serviço gerenciado pela AWS que permite enviar mensagens para várias plataformas, como aplicativos móveis, e-mails, SMS e endpoints HTTP, e neste caso, o Amazon SQS, e essa configuração deve ser feita de forma bilateral, em ambos os tópicos SNS e ambas as filas SQS.

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
resource "aws_sqs_queue_policy" "main" {
queue_url = aws_sqs_queue.main.id
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": "*",
"Action": [
"sqs:SendMessage"
],
"Resource": [
"${aws_sqs_queue.main.arn}"
],
"Condition": {
"ArnLike": {
"aws:SourceArn": [
"arn:aws:sns:sa-east-1:${data.aws_caller_identity.current.account_id}:${var.sns_topic_name}",
"arn:aws:sns:us-east-1:${data.aws_caller_identity.current.account_id}:${var.sns_topic_name}"
]
}
}
}
]
}
EOF
}
1
2
3
4
5
6
7
8
9
10
11
12
resource "aws_sqs_queue" "main" {
name = var.queue_name
delay_seconds = var.delay_seconds
max_message_size = var.max_message_size
message_retention_seconds = var.message_retention_seconds
receive_wait_time_seconds = var.receive_wait_time_seconds
visibility_timeout_seconds = var.visibility_timeout_seconds
redrive_policy = jsonencode({
deadLetterTargetArn = aws_sqs_queue.dlq.arn
maxReceiveCount = var.dlq_redrive_max_receive_count
})
}
E em seguida criar um tópico SNS fazendo subscribe das filas de SQS
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
resource "aws_sns_topic" "main" {
name = format("%s", var.name)
# fifo_topic = true
# content_based_deduplication = true
}
resource "aws_sns_topic_subscription" "primary" {
protocol = "sqs"
raw_message_delivery = true
topic_arn = aws_sns_topic.main.arn
endpoint = var.sqs_queue
}
resource "aws_sns_topic_subscription" "replica" {
protocol = "sqs"
raw_message_delivery = true
topic_arn = aws_sns_topic.main.arn
endpoint = var.sqs_queue_replica
}
Fechando um pouco o capô do carro, e ligando ele pra botar pra funcionar, nossa declaração de módulos trabalharia de forma com que ambas as declarações dos providers recebesse respectivamente qual seria a queue primária e a replica, alternando entre ambos.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
module "sales_processing_queue_sa_east_1" {
source = "./modules/sqs-queue"
providers = {
aws = aws.primary
}
queue_name = "sales-processing-queue"
delay_seconds = 0
max_message_size = 2048
message_retention_seconds = 86400
receive_wait_time_seconds = 10
dlq_redrive_max_receive_count = 4
visibility_timeout_seconds = 60
sns_topic_name = var.sales_sns_topic_name
}
//..
module "sales_sns_sa_east_1" {
source = "./modules/sns-multiregion-sqs-delivery"
providers = {
aws = aws.primary
}
name = "sales-processing-topic"
sqs_queue = module.sales_processing_queue_sa_east_1.sqs_queue_arn
sqs_queue_replica = module.sales_processing_queue_us_east_1.sqs_queue_arn
}
// ...
Independente do uso de um modulo, desse modulo, de outro modulo, ou fazer na mão, o esperado é que o tópico SNS tenha sempre duas subscriptions, para as queues das duas regiões como no print a seguir, e a devida subscription do SNS de cada região deve aparecer nas configurações das duas filas SQS mostradas.
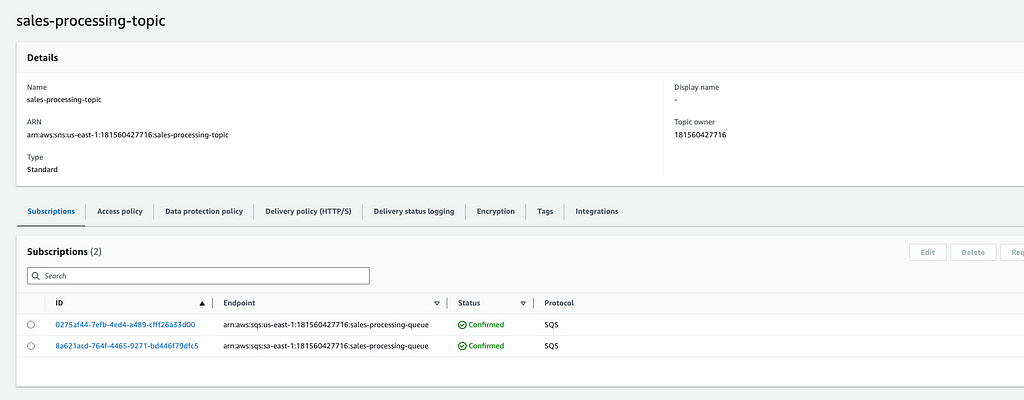
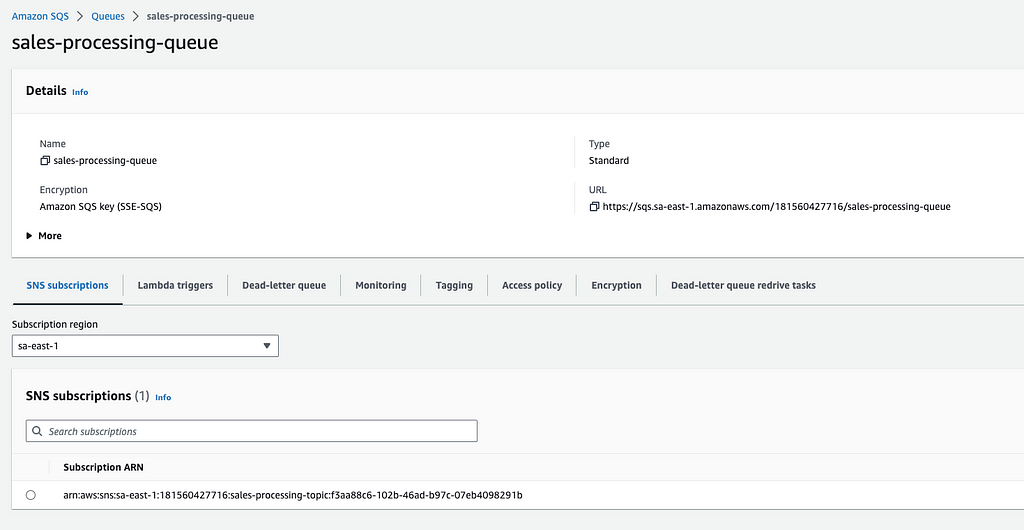
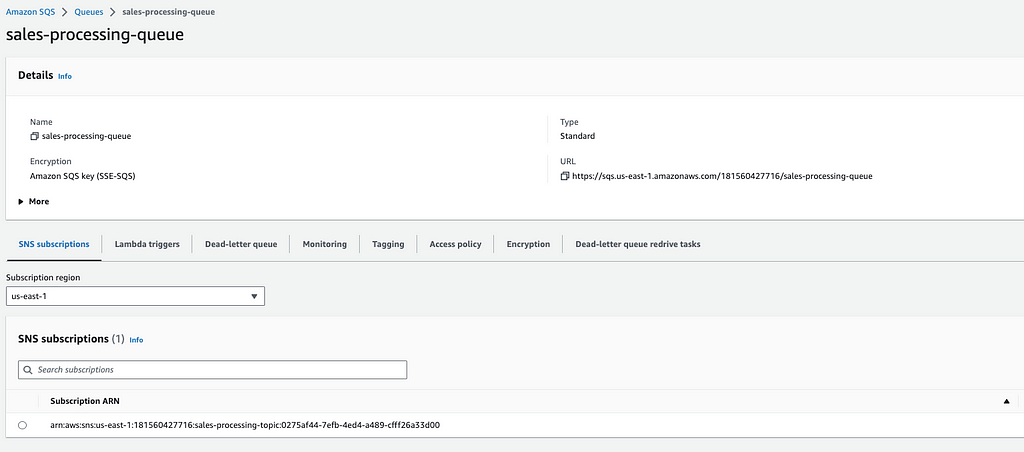
3.2 — DynamoDB Global Tables
As DynamoDB Global Tables (Tabelas Globais do DynamoDB) são uma funcionalidade do serviço que permitem que você crie e mantenha tabelas do DynamoDB automaticamente replicadas e sincronizadas em várias regiões da AWS. Perfeito para nossa proposta de DR.
Com as DynamoDB Global Tables, você pode ter cópias de tabelas em várias regiões da AWS, garantindo replicação e failover automático, permitindo que as apps leiam e gravem dados de forma local em cada região.
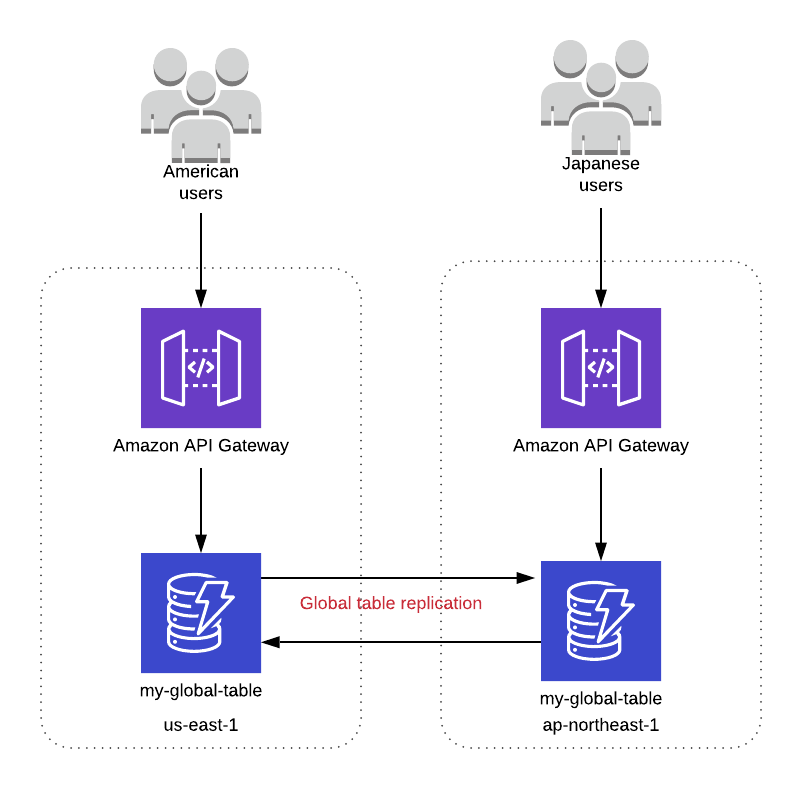
Elas são particularmente úteis quando você precisa espelhar sua aplicação entre diversas regiões e disponibilizá-las paralelamente, utilizando a mesma base de dados.
Por exemplo, em caso de Weighted Routing Policy utilizado neste exemplo entre Regiões, onde teremos Round Robin do consumo de recursos em caso de ACTIVE/ACTIVE, ou num caso legal as Geolocation routing policy, onde você pode disponibilizar o workload geograficamente mais proximo do cliente, por exemplo:
- Quem está no Brasil, acessa São Paulo
- Quem está em Miami, acessa Virginia
Mas no nosso caso de Disaster Recovery, podemos contar que teremos um banco de dados replicado de forma bilateral com baixa latência e consistência eventual, independente das regiões que eu estiver manipulando esse dado.
O provisionamento de uma Global Table é simples, e não requer provisionamento duplicado com base em módulos, por isso não iremos fazer uso desse artifício nesse recurso.
Os pontos de atenção para o provisonamento adequado é a necessidade de habilitar o DynamoDB Streams no provisionamento da tabela informando o valor booleano no parâmetro stream_enabled e informando o stream_view_type como NEW_AND_OLD_IMAGES para que por meio do stream a replicação aconteça em todas as replicas.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
resource "aws_dynamodb_table" "sales" {
provider = aws.primary
hash_key = "id"
name = "sales"
stream_enabled = true
stream_view_type = "NEW_AND_OLD_IMAGES"
read_capacity = lookup(var.dynamodb_sales, "read_min")
write_capacity = lookup(var.dynamodb_sales, "write_min")
billing_mode = lookup(var.dynamodb_sales, "billing_mode")
point_in_time_recovery {
enabled = lookup(var.dynamodb_sales, "point_in_time_recovery")
}
attribute {
name = "id"
type = "S"
}
server_side_encryption {
enabled = true
kms_key_arn = module.cluster_sa_east_1.kms_key
}
lifecycle {
ignore_changes = [
read_capacity,
write_capacity,
replica
]
}
}
// Omitindo configs de autoscaling
Em seguida precisaremos criar um outro recurso chamado aws_dynamodb_table_replica informando qual tabela será replicada e em qual região. Nesse caso precisaremos informar o provider do terraform da zona de DR.
1
2
3
4
5
6
7
8
9
10
11
12
13
resource "aws_dynamodb_table_replica" "sales" {
provider = aws.disaster-recovery
global_table_arn = aws_dynamodb_table.sales.arn
kms_key_arn = module.cluster_us_east_1.kms_key
depends_on = [
aws_appautoscaling_target.sales_read,
aws_appautoscaling_target.sales_write,
aws_appautoscaling_policy.sales_read,
aws_appautoscaling_policy.sales_write
]
}
Para testar, vamos consumir nossa API do produto hipotético tentando criar uma venda, em seguida executar um Scan na tabela nas duas regiões para garantir que ele está lá.
1
2
3
4
5
6
7
8
9
10
11
12
❯ curl -X POST https://api.msfidelis.com.br/sales -d '{"product":"registro que viajou entre duas regiões", "amount": 666.00}' -i
HTTP/2 201
date: Wed, 12 Jul 2023 00:22:26 GMT
content-type: application/json; charset=utf-8
content-length: 128
x-amzn-requestid: bb696387-4a2c-46b4-b68c-82adbefc9fd1
x-amzn-remapped-content-length: 128
x-amzn-remapped-connection: keep-alive
x-amz-apigw-id: H7LKVG88mjQEO6Q=
x-amzn-remapped-date: Wed, 12 Jul 2023 00:22:26 GMT
{"id":"d2673f99-d632-453d-aedd-13a30fc3bc78","product":"registro que viajou entre duas regiões","amount":666,"processed":false}
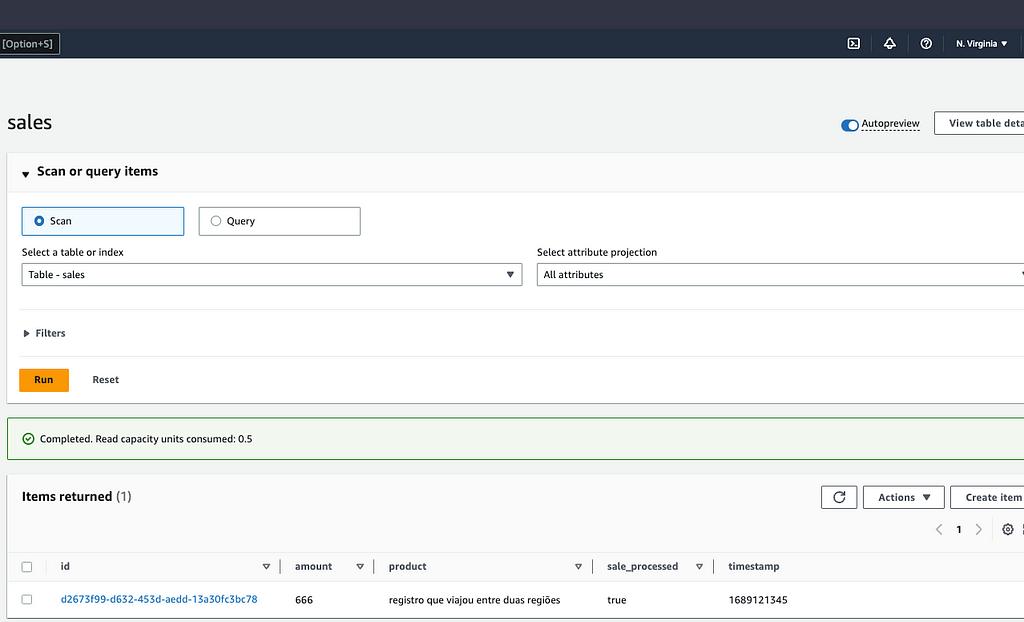
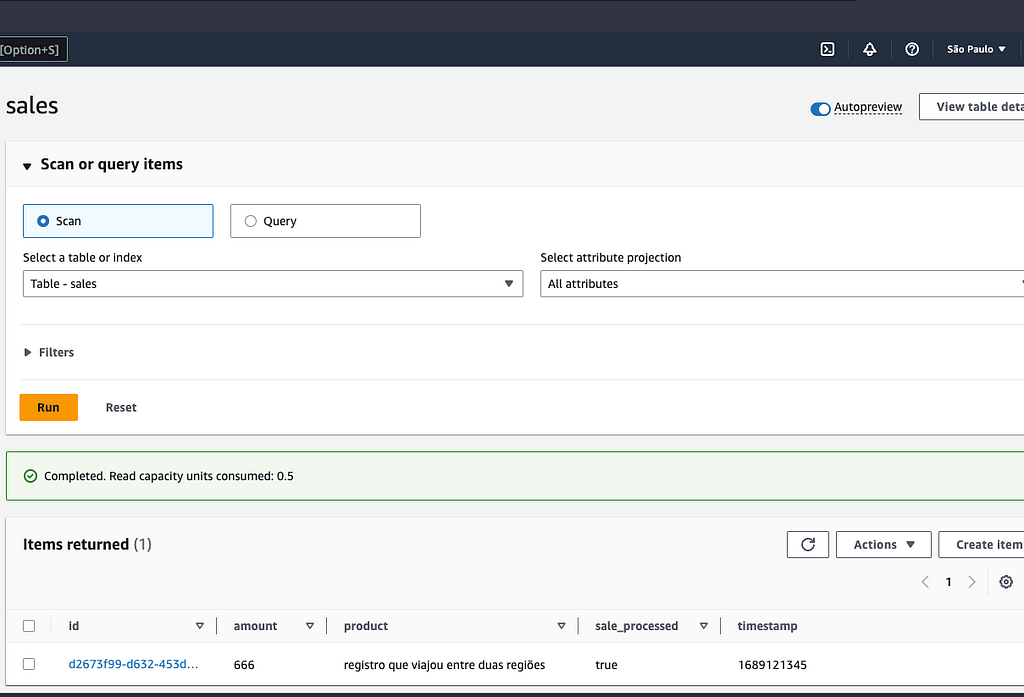
3.3 — S3 Two Way Replication
Nosso produto hipotético, após nosso worker consumir a mensagem no SQS de uma nova venda, ele faz uma série de processamento também hipotético, atualiza a flag de processamento no DynamoDB e em seguida sobe o registro para o S3 para Backup e ingestão futura de um Data Lake hipotético do Athena. (Não iremos abordar o Amazon Athena por enquanto)
O Amazon S3 (Simple Storage Service) é um serviço popular de armazenamento de objetos oferecido pela AWS. Ele fornece uma solução escalável, segura e durável para armazenar e recuperar dados de forma eficiente. Uma das funcionalidades avançadas do Amazon S3 é o S3 Two Way Replication, que oferece uma abordagem bidirecional para replicar dados entre buckets do S3 em regiões diferentes.
A Replicação Bidirecional do S3 Two Way permite a replicação contínua e síncrona dos objetos armazenados em um bucket do S3 para um bucket correspondente em outra região. Isso significa que qualquer alteração, inclusão ou exclusão feita em um objeto em um bucket será automaticamente replicada para o bucket de destino em tempo real. Com essa abordagem, você pode manter cópias atualizadas dos seus dados em regiões distintas, aumentando a disponibilidade e a durabilidade dos objetos armazenados no S3.
Para o nosso objetivo de DR e replicação de dados, essa solução serve muito bem. Podemos escrever e ler dos dois buckets da replicação e contar que ambas as modificações serão espelhadas na região vizinha.
Nesse caso, o provisionamento é bem simples. Vamos também utilizar um módulo onde iremos provisionar dois buckets com as mesmas configurações nas duas regiões, primária e disaster-recovery.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
module "bucket_sa_east_1" {
source = "./modules/s3_bucket"
providers = {
aws = aws.primary
}
bucket_name_prefix = "processed-sale"
}
module "bucket_us_east_1" {
source = "./modules/s3_bucket"
providers = {
aws = aws.disaster-recovery
}
bucket_name_prefix = "processed-sale"
}
Devemos prepara uma IAM Role que permita ser assumida pelo S3 com as devidas permissões de replicação e manipulação de objetos.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
// Replication IAM
data "aws_iam_policy_document" "assume_role" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["s3.amazonaws.com"]
}
actions = ["sts:AssumeRole"]
}
}
resource "aws_iam_role" "replication" {
provider = aws.primary
name = format("sales-s3-replication")
assume_role_policy = data.aws_iam_policy_document.assume_role.json
}
data "aws_iam_policy_document" "replication" {
statement {
effect = "Allow"
actions = [
"s3:GetReplicationConfiguration",
"s3:ListBucket",
]
resources = [
module.bucket_sa_east_1.arn,
module.bucket_us_east_1.arn,
]
}
statement {
effect = "Allow"
actions = [
"s3:GetObjectVersionForReplication",
"s3:GetObjectVersionAcl",
"s3:GetObjectVersionTagging",
"s3:ReplicateObject",
"s3:ReplicateDelete",
"s3:ReplicateTags",
]
resources = [
"${module.bucket_sa_east_1.arn}/*",
"${module.bucket_us_east_1.arn}/*"
]
}
}
resource "aws_iam_policy" "replication" {
provider = aws.primary
name = format("sales-s3-replication")
policy = data.aws_iam_policy_document.replication.json
}
resource "aws_iam_role_policy_attachment" "replication" {
provider = aws.primary
role = aws_iam_role.replication.name
policy_arn = aws_iam_policy.replication.arn
}
Podemos duplicar o recurso aws_s3_bucket_replication_configuration alternando em cada um o bucket origem e destino.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
resource "aws_s3_bucket_replication_configuration" "primary" {
provider = aws.primary
role = aws_iam_role.replication.arn
bucket = module.bucket_sa_east_1.id
rule {
id = "sales"
filter {
prefix = "sales"
}
delete_marker_replication {
status = "Enabled"
}
status = "Enabled"
destination {
bucket = module.bucket_us_east_1.arn
storage_class = "STANDARD"
}
}
}
resource "aws_s3_bucket_replication_configuration" "disaster_recovery" {
provider = aws.disaster-recovery
role = aws_iam_role.replication.arn
bucket = module.bucket_us_east_1.id
rule {
id = "sales"
filter {
prefix = "sales"
}
delete_marker_replication {
status = "Enabled"
}
status = "Enabled"
destination {
bucket = module.bucket_sa_east_1.arn
storage_class = "STANDARD"
}
}
}
Vamos consumir novamente a aplicação inserindo um novo hipotético registro de venda de um produto.
1
2
3
4
5
6
7
8
9
10
11
12
❯ curl -X POST https://api.msfidelis.com.br/sales -d '{"product":"registro que viajou entre duas regiões e caiu em dois buckets", "amount": 333.00}' -i
HTTP/2 201
date: Wed, 12 Jul 2023 00:44:43 GMT
content-type: application/json; charset=utf-8
content-length: 151
x-amzn-requestid: 7194a8c3-e4f1-48f2-baea-77c347174130
x-amzn-remapped-content-length: 151
x-amzn-remapped-connection: keep-alive
x-amz-apigw-id: H7ObVER4mjQEH_w=
x-amzn-remapped-date: Wed, 12 Jul 2023 00:44:43 GMT
{"id":"db218024-3974-4ad7-9490-2c88560298de","product":"registro que viajou entre duas regiões e caiu em dois buckets","amount":333,"processed":false}
Agora vamos conferir no bucket se existe o registro db218024-3974-4ad7-9490-2c88560298de.json em ambas as regiões.
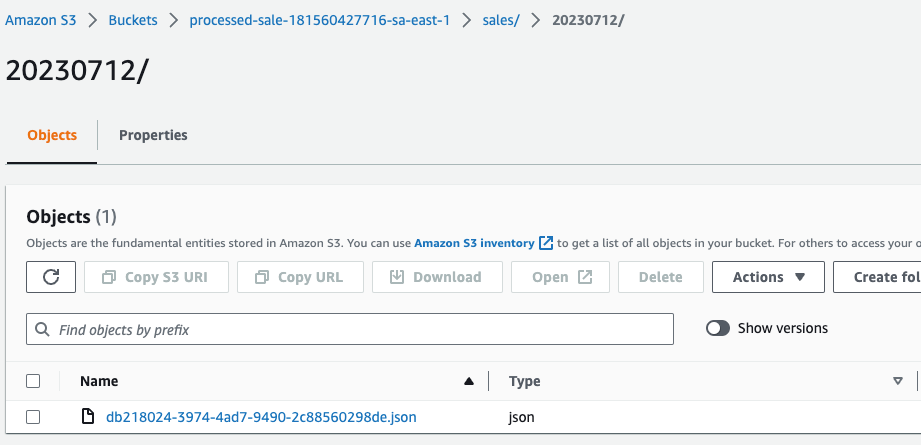
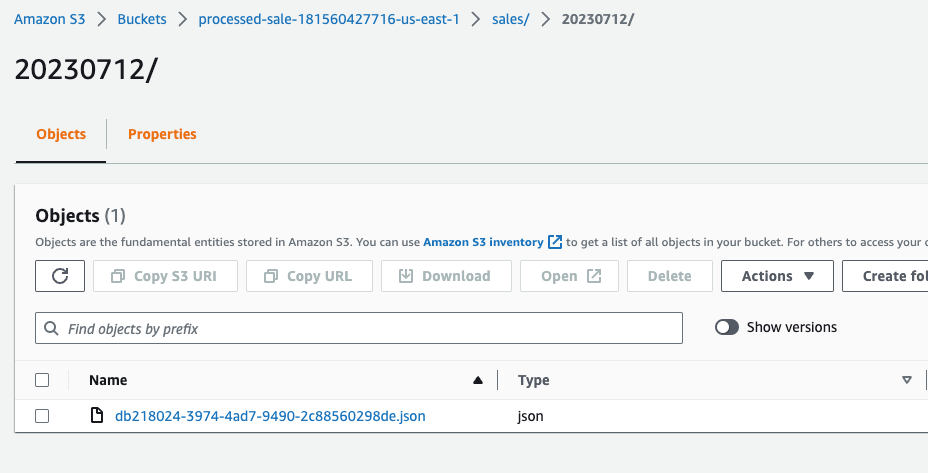
Parte 4: Escrevendo Código Multi Region e Sugestões Arquiteturais
Achou mesmo que é só subir infra que resolve? Achou errado, amigo.
Trabalhar em Multiregião é uma escolha, um projeto, um objetivo, não um hotfix, então devemos trabalhar nossas aplicações para que as mesmas sejam resilientes não só a falhas mas também para trabalhar de forma inteligente esse chaveamento de regiões. Temos diversos padrões que podem nos ajudar, nesse artigo trabalharemos os seguintes:
- Feature Toggle com Parameter Store
- Dry-Run
- Idempotência
4.1 — Feature Toggle com Parameter Store
Um Feature Toggle, também conhecido como Feature Flag dependendo pra quem você pergunta, é um mecanismo de controle que permite habilitar ou desabilitar recursos ou funcionalidades específicas em um software, sem a necessidade de fazer uma nova implantação ou alteração na codebase. É uma técnica comumente utilizada no desenvolvimento de software para ativar ou desativar recursos de forma flexível e controlada, possibilitando a entrega contínua e incremental de novas funcionalidades.
Com um Feature Toggle, você pode ocultar uma funcionalidade em produção enquanto ainda está em desenvolvimento, permitindo que você teste, experimente e valide essa funcionalidade em um ambiente de produção controlado.
No nosso caso, iremos utilizá-lo para desabilitar ou habilitar o processamento inteiro de uma região e das aplicações que compõe o nosso Workload de vendas em tempo de DR.
O Parameter Store é um serviço gerenciado pela AWS que oferece armazenamento seguro e gerenciamento de parâmetros e configurações. Ele permite armazenar e recuperar informações sensíveis, como senhas, chaves, strings de conexão e outros valores de configuração, de forma centralizada e segura.
Uma forma inteligente de trabalhar com Feature Toggle no Parameter Store é fazer com que pragmaticamente, a aplicação sempre consulte o valor do parâmetro de X em X tempo e salve em memória por um determinado período de tempo. Sempre que esse registro expirar, a aplicação consiga consultar e atualizar o parâmetro de forma global para o runtime.
Por exemplo, durante uma determinada interação eu consulto o valor do parameter store que contém o valor do estado do meu Site/Região, e digo para salvar essa informação em cache em memória por 30 segundos.
1
2
ssm_site_state_parameter := os.Getenv("SSM_PARAMETER_STORE_STATE")
site_state, err := parameter_store.GetParamValue(ssm_site_state_parameter, 30)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
package memory_cache
import (
"time"
"github.com/patrickmn/go-cache"
)
var instance *cache.Cache
func GetInstance() *cache.Cache {
if instance == nil {
instance = cache.New(5*time.Minute, 10*time.Minute)
}
return instance
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
package parameter_store
import (
"fmt"
"os"
"time"
"sales-worker/pkg/log"
"sales-worker/pkg/memory_cache"
"github.com/aws/aws-sdk-go/aws"
"github.com/aws/aws-sdk-go/aws/session"
"github.com/aws/aws-sdk-go/service/ssm"
)
func GetParamValue(parameter string, cacheTime int64) (string, error) {
m := memory_cache.GetInstance()
log := log.Instance()
if cacheTime > 0 {
if value, found := m.Get(parameter); found {
log.Info("Parameter found in cache")
return fmt.Sprint(value), nil
}
}
sess, err := session.NewSession(&aws.Config{
Region: aws.String(os.Getenv("AWS_REGION")),
})
if err != nil {
return "", err
}
svc := ssm.New(sess)
result, err := svc.GetParameter(&ssm.GetParameterInput{
Name: aws.String(parameter),
WithDecryption: aws.Bool(false),
})
if err != nil {
return "", err
}
if cacheTime > 0 {
m.Set(parameter, *result.Parameter.Value, time.Second*time.Duration(cacheTime))
}
return fmt.Sprint(*result.Parameter.Value), nil
}
E voltando para a parte de infraestrutura que anda junto com esse tipo de lógica, no nosso workload hipotético vamos salvar o valor da variável state do Terraform no Parameter Store, e com base nessa informação vamos desenvolver nossos fluxos, com base que se essa variável for trocada, no deploy em sequencia todas as aplicações sejam informadas quase que automaticamente de como elas devem se comportar.
1
2
3
4
5
6
7
variable "state" {
type = map(any)
default = {
"sa-east-1" : "ACTIVE",
"us-east-1" : "PASSIVE",
}
}
Com base nisso vamos duplicar também o parâmeter store nas duas regiões utilizando o mesmo nome.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
module "ssm_parameter_state_sa_east_1" {
source = "./modules/parameter_store"
providers = {
aws = aws.primary
}
name = format("/%s/site/state", var.project_name)
value = lookup(var.state, "sa-east-1")
}
module "ssm_parameter_state_us_east_1" {
source = "./modules/parameter_store"
providers = {
aws = aws.disaster-recovery
}
name = format("/%s/site/state", var.project_name)
value = lookup(var.state, "us-east-1")
}
Podemos conferir via painel o resultado das duas operações, tanto na Região Primária (sa-east-1) quanto na de Disaster Recovery (us-east-1).
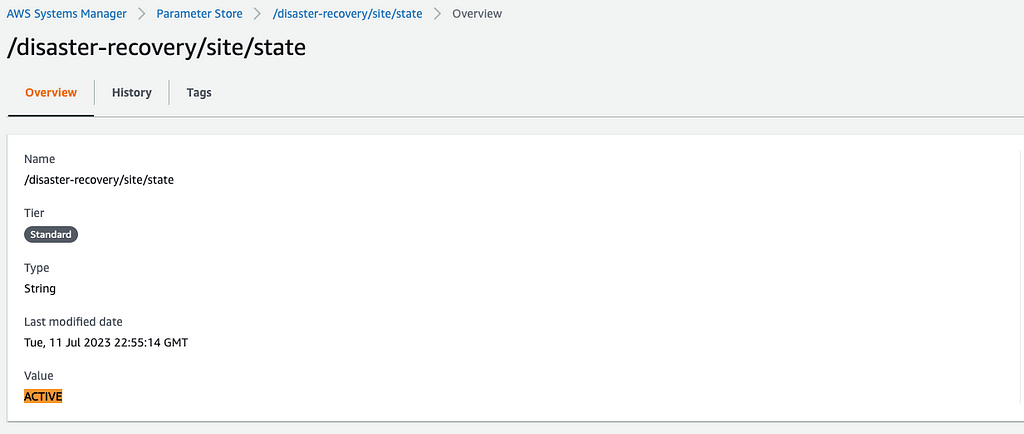
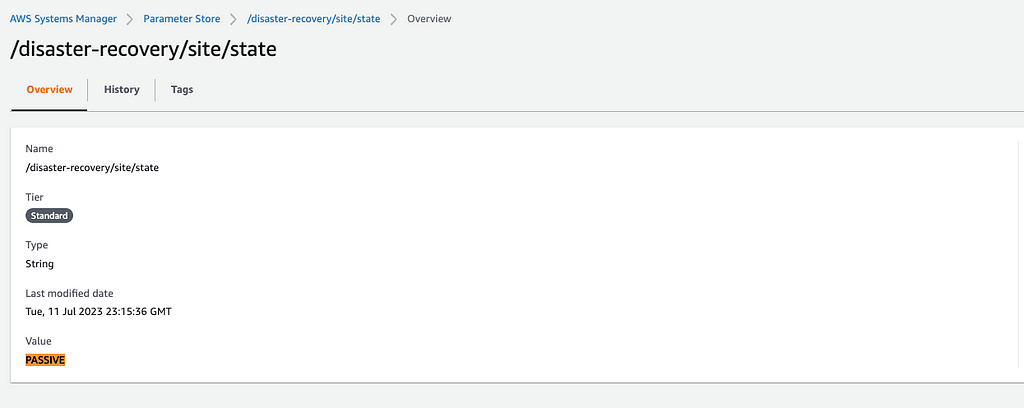
Trabalhando dessa forma, podemos recuperar nosso estado no início de um fluxo e trabalhá-lo até o final do mesmo, fazendo sempre uma validação do estado para saber se precisamos trabalhar o registro ou não. Detalharemos isso no próximo passo.
1
2
3
4
if state != "ACTIVE" {
return nil
}
continueOqueEstavaFazendo()
4.2 — Dry-Run, processamento café com leite
Dry-Run, também conhecido como teste simulado ou simulação de execução, é uma prática comum no desenvolvimento de software e testes. Consiste em executar um programa, algoritmo ou conjunto de instruções em um ambiente simulado, sem a efetiva execução das ações ou operações previstas.
Durante um Dry-Run, o código é analisado e executado passo a passo, e os resultados são simulados sem realizar alterações no estado real do sistema ou afetar os dados existentes. O objetivo principal é identificar erros, validar a lógica do programa e verificar a saída esperada, tudo isso sem impactar o ambiente de produção ou introduzir mudanças irreversíveis. Para essa arquitetura, vamos sair da definição da literatura e fazer com que o princípio do Dry-Run simplesmente não cometa nenhuma alteração, mesmo que consuma as mensagens e instruções com base no estado do feature toggle.
No nosso Workload hipotético, após a API Rest salvar a venda no DynamoDB, ela publica uma mensagem no tópico do SNS e o mesmo envia para o SQS em ambas as regiões. Essa mensagem deveria ser consumida pelos workers de ambas as regiões, e esses workers devem fazer um processamento falso, atualizar a flag de processado na tabela do DynamoDB e salvar o item no S3 conforme já explicado.
Por mais que a mensagem seja replicada em ambas as regiões, é um desperdício de dinheiro e poder computacional literalmente processar a mensagem duas vezes. Para isso, vamos utilizar o Feature Toggle do estado da Região para dizer para o nosso worker se ele deve processar a mensagem de fato ou executar um Dry-Run na mesma, ou simplesmente descartá-la e esperar que o processamento seja realizado e replicado para ela pela região ativa.
Um exemplo de um processamento de Feature Flag e Dry-Run
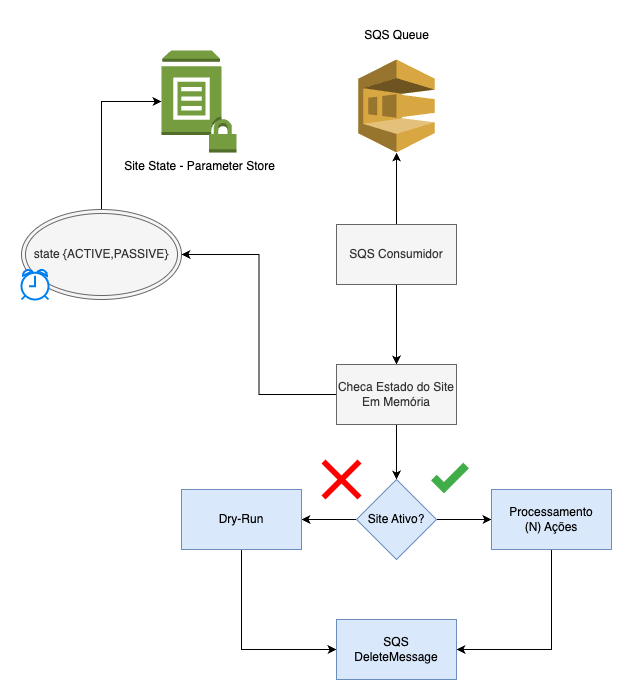
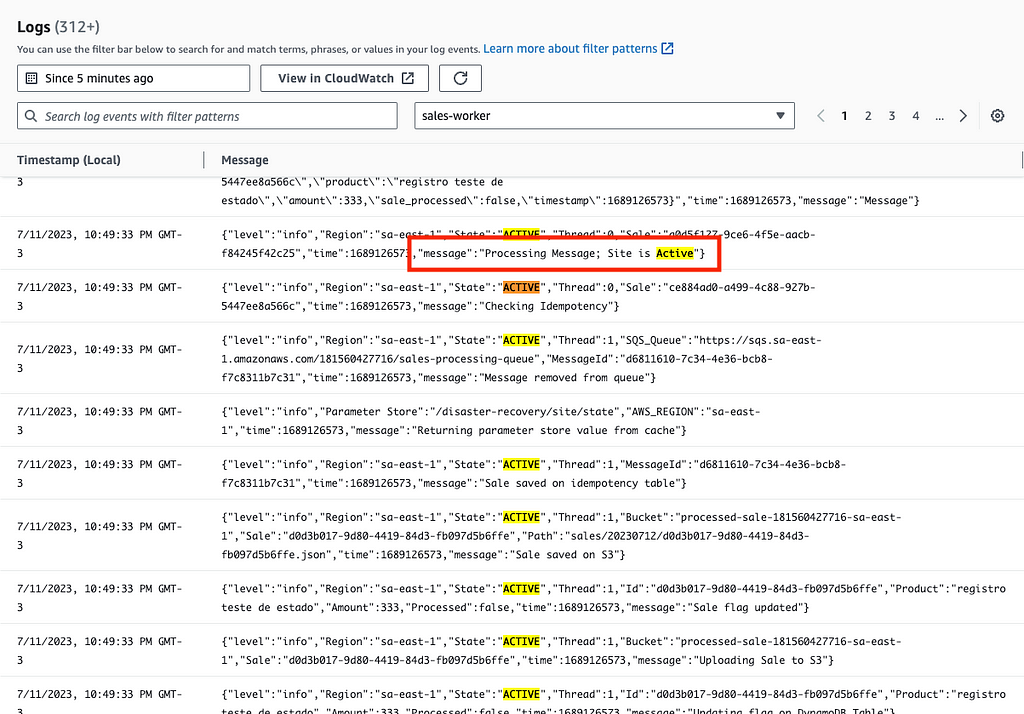
Basicamente, de tempos em tempos atualizamos o estado do nosso runtime com o definido no Parameter Store e com base nesse estado, checamos se o Site/Região está ativo ou passivo. Caso esteja com o estado ACTIVE, executa o processamento em N ações descritas anteriormente, e caso esteja PASSIVE, executa o Dry-Run, remove a mensagem da fila em seguida.
Exemplo do comportamento do Worker quando a região está ativa
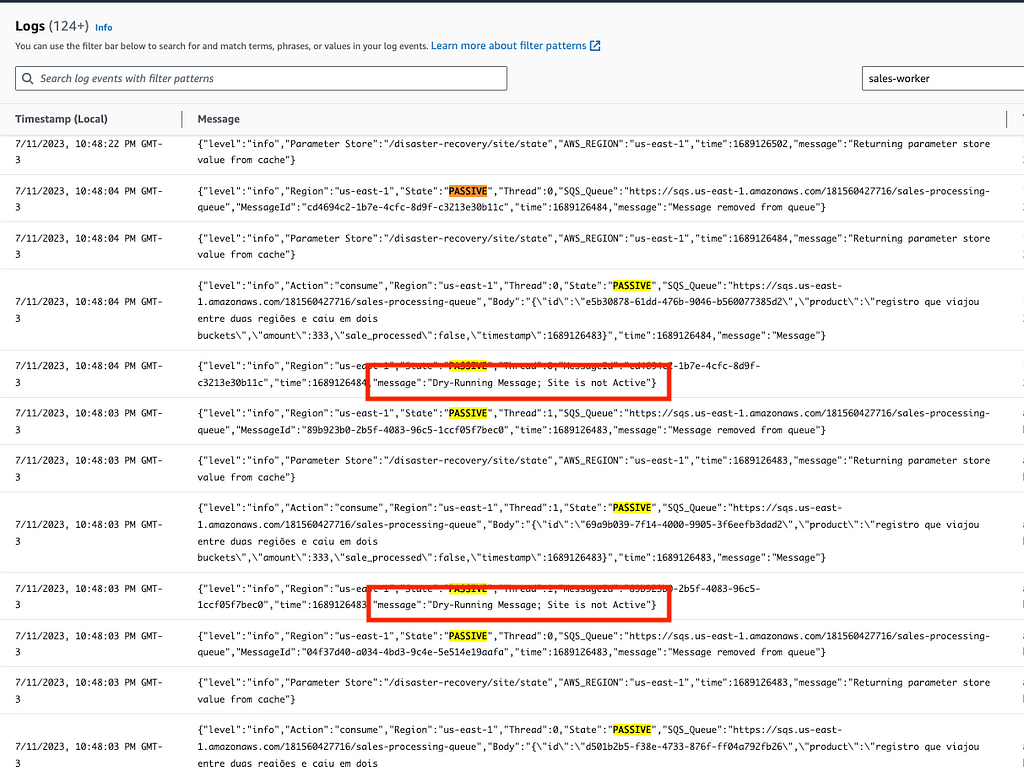
Exemplo do comportamento do Worker quando a região está passiva
4.3 — Idempotência
Talvez o padrão arquitetônico mais importante quando falamos de qualquer coisa que se propõe a ser resiliente e distribuída.
Na arquitetura de software, a idempotência é um conceito importante que descreve a propriedade de uma operação ou função que pode ser aplicada repetidamente sem alterar o resultado além da primeira aplicação. Em outras palavras, uma operação idempotente produz o mesmo resultado, independentemente do número de vezes que é executada.
A idempotência é uma característica desejável em sistemas distribuídos e transações de software, pois garante que a reexecução de uma operação não resulte em efeitos colaterais indesejados ou em um estado inconsistente do sistema. Isso é particularmente importante quando ocorrem falhas de rede, erros transientes ou reexecuções automáticas devido a mecanismos de recuperação de erros.
Existem várias formas de estender a capacidade de um padrão de idempotência. Alguns exemplos fora desse assunto de Disaster Recovery que são naturalmente idempotentes:
- Operações de Atualização de Estado: Em APIs REST, as operações de atualização de estado geralmente seguem o princípio da idempotência. Por exemplo, se uma requisição DELETE, PUT ou PATCH for repetida várias vezes, o estado final do recurso será o mesmo.
- Operações de Pagamento na Indústria Financeira: Em sistemas de pagamentos online, as transações de pagamento são geralmente idempotentes. Isso significa que, se uma transação de pagamento for repetida devido a um problema de comunicação ou a uma resposta de confirmação perdida, ela não resultará em cobranças duplicadas ao usuário.
Porém, nesse exemplo, iremos implementar uma idempotência pragmática com base no ID único gerado ao longo de cada venda criada através da nossa API. Nesse caso, iremos controlar a idempotência garantindo um certo tempo de replicação dos recursos em uma tabela do DynamoDB exclusivamente preparada para isso.
O objetivo desse processo de idempotência no nosso workload hipotético é evitar o reprocessamento de uma venda criada e disponibilizada para consumo durante uma virada ou uma possível duplicação de dados, ou tentativa de reprocessamento por algum outro mecanismo não tratado aqui.
Exemplo do fluxo de Idempotência de Processamento
Vamos estender o diagrama que vimos no Dry-Run. Nesse caso, após validarmos que estamos numa região ativa, chegamos na tabela do DynamoDB de idempotência procurando pelo ID da venda. Caso ela já tenha sido processada, descartamos a mensagem. Caso o ID ainda não esteja presente na tabela, realizamos todos os fluxos de processamento que tratamos aqui e no final salvamos o mesmo na tabela de idempotência, também rodando como Global Table.
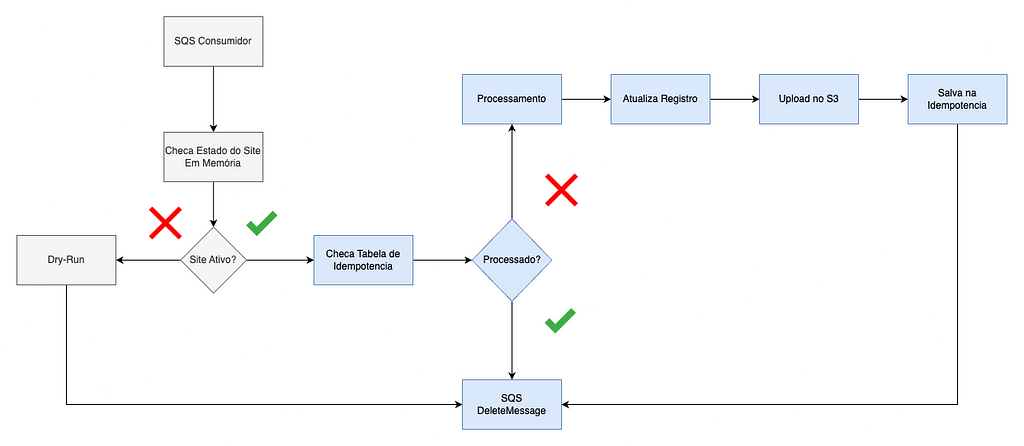
Por exemplo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
idempotency, err := dao.CheckIdempotency(sale.ID)
if err != nil {
return err
}
if idempotency {
log.Info().
Str("Region", aws_region).
Str("State", state).
Int("Thread", thread).
Str("Sale", sale.ID).
Msg("Sale already processed, item found in idempotency table")
return nil
}
// Continua
Parte 5: Testando o Fluxo de Disaster Recovery
Agora chegou a parte legal. Fizemos muitos desenhos bonitinhos, módulos lindos, explicamos um monte de paradigmas arquiteturais filosóficos, e agora precisamos validar de fato o funcionamento desse exemplo.
Vamos injetar carga utilizando o k6, uma ferramenta já conhecida de outros carnavais aqui no Medium. Injetaremos carga e monitoraremos o comportamento dos recursos das duas regiões via CloudWatch.
A ideia é fazer todo o espelhamento e chaveamento via Terraform. Então vamos estruturar essa parte com base em passos de formiga, exemplificando ação e reação do workload.
5.1 — Status Inicial
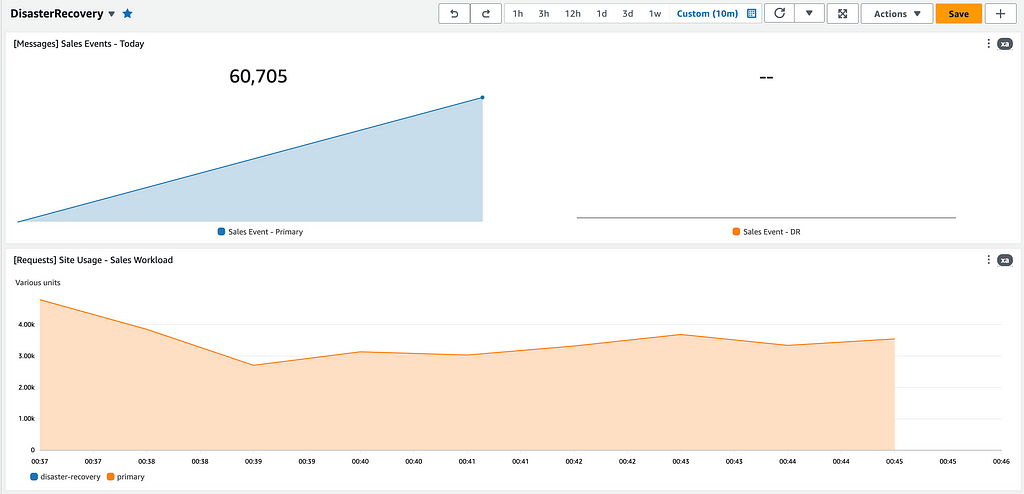
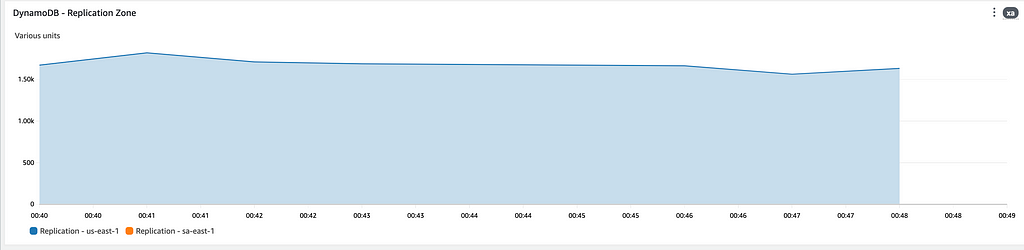
Inicialmente, temos o workload atendendo e performando de forma prevista, somente na zona primária. Temos um contador de eventos de vendas e de requests por minuto no API Gateway para ambas as regiões.
Em paralelo, temos o registro de replicação das nossas tabelas do DynamoDB. Como estamos escrevendo e lendo da tabela na região primária (sa-east-1), devemos ver o fluxo de replicação indo para a região de DR (us-east-1).
Resumindo, nosso estado de configuração do chaveamento no Terraform está da seguinte forma: chaveando 100% do tráfego para São Paulo e mantendo nosso feature toggle em ACTIVE para o mesmo.
1
2
3
4
5
6
7
variable "state" {
type = map(any)
default = {
"sa-east-1" : "ACTIVE",
"us-east-1" : "PASSIVE",
}
}
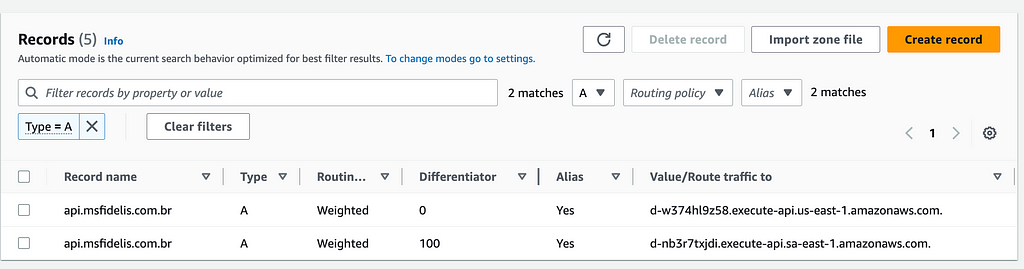
5.2 — Chaveando o DR
Vamos alterar o estado no Terraform para desligar a zona de São Paulo e direcionar o tráfego diretamente para a região de Virginia.
1
2
3
4
5
6
7
variable "state" {
type = map(any)
default = {
"sa-east-1" : "PASSIVE",
"us-east-1" : "ACTIVE",
}
}
Independente de onde e como você está executando isso, no fim essa mudança irá refletir com base em um apply
1
terraform apply --auto-approve
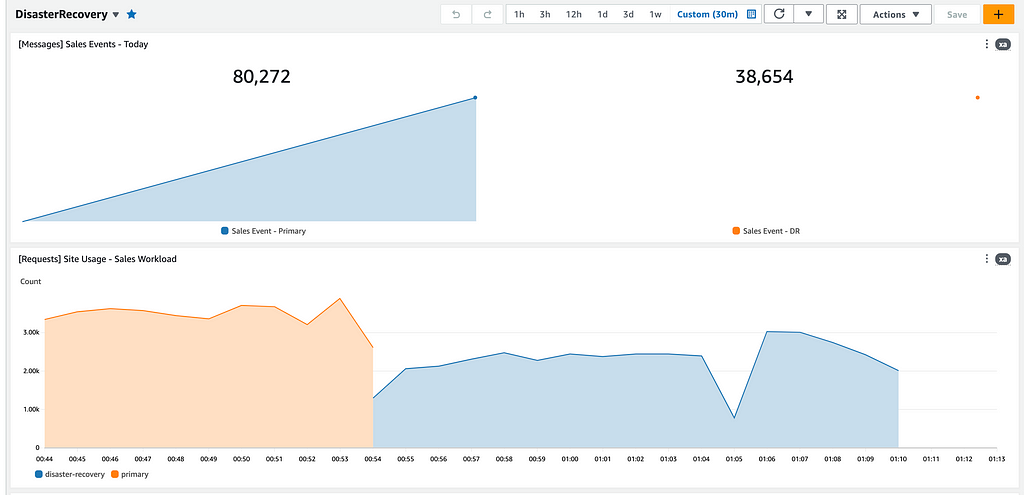
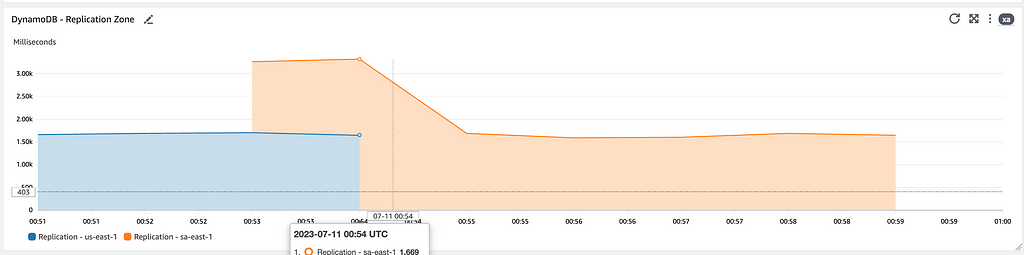
Após aplicar as alterações com o Terraform, chaveando a Região primária para o DR sem interromper o teste de carga, podemos ver o início imediato da operação da região de DR, que começa a contabilizar eventos de vendas por ela iniciados, entrada de fluxo no API Gateway e a inversão do sentido de replicação das tabelas do DynamoDB.
Nesse cenário, começamos a utilizar os recursos da zona de DR como ACTIVE, enviando todo o tráfego da API para lá e desabilitando a zona primária em São Paulo, colocando-a como PASSIVE.
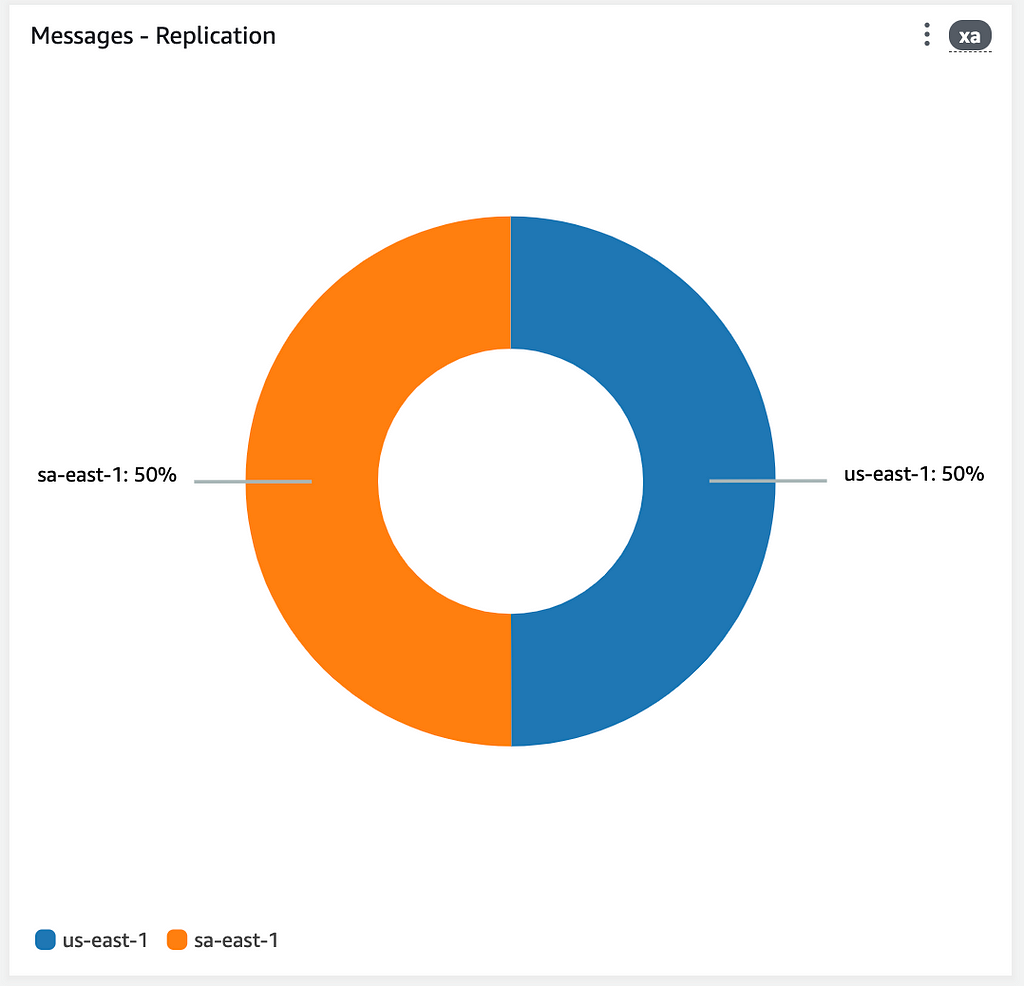
Acompanhamos também uma métrica de replicação das mensagens. Esse pode ser um bom indicador para o chaveamento de retorno para a Região Primária.
Parte 6: Estratégias Adicionais
Como mencionado no início do artigo, algumas soluções e produtos da AWS projetados para Disaster Recovery foram desconsiderados durante a concepção deste texto. No entanto, vale a pena mencionar algumas das opções disponíveis.
6.1 — Route53 Failover
O Route53 Failover é um recurso que esteve perto de ser incluído, se não fosse pela parametrização de feature flag.
Usando o Route53 Failover, é possível redirecionar o tráfego de maneira inteligente entre várias regiões, assegurando que as solicitações dos usuários sejam redirecionadas para uma região de backup caso a primária fique indisponível. Isso é extremamente valioso em cenários de disaster recovery, onde manter a continuidade dos negócios é crítico.
O funcionamento do Route53 Failover é baseado em health checks configurados para monitorar a saúde das instâncias ou endpoints em cada região. Se um recurso falhar, o Route53 pode automaticamente redirecionar o tráfego para outra região que esteja operacional. Em caso de falha na região primária, o tráfego é redirecionado automaticamente para uma região secundária.
A implementação desta estratégia é ideal para operações que possam funcionar de forma ATIVO/ATIVO, onde uma região pode gerenciar as solicitações de outra a qualquer momento.
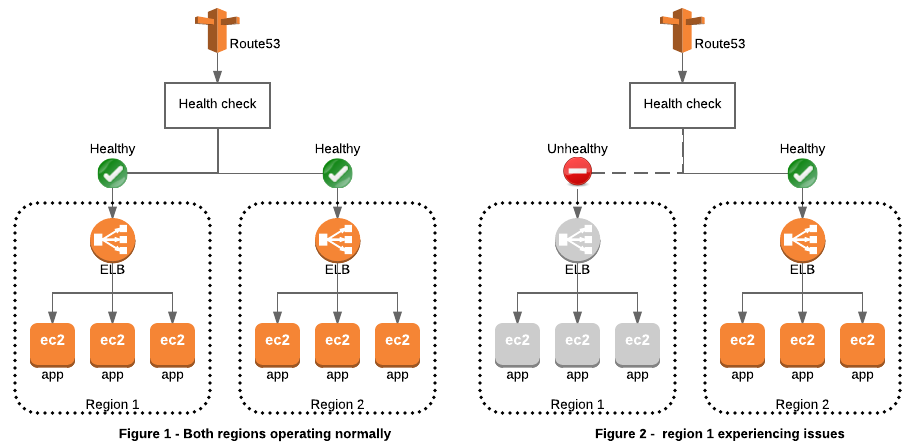
Exemplo da implementação em Terraform dos Healthchecks do Route53.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
resource "aws_route53_health_check" "primary" {
fqdn = var.api_gateway_dns_primary
port = 443
type = "HTTP"
resource_path = "/healthcheck"
request_interval = 30
failure_threshold = 3
}
resource "aws_route53_health_check" "secondary" {
fqdn = var.api_gateway_dns_secondary
port = 443
type = "HTTP"
resource_path = "/healthcheck"
request_interval = 30
failure_threshold = 3
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
resource "aws_route53_record" "primary" {
zone_id = var.route53_hosted_zone
name = var.api_gateway_domain
type = "A"
ttl = 60
failover_routing_policy {
type = "PRIMARY" # Identificando que e o Registro Primário
ttl_override = 60
}
set_identifier = "primary"
health_check_id = aws_route53_health_check.primary.id
}
resource "aws_route53_record" "secondary" {
zone_id = var.route53_hosted_zone
name = var.api_gateway_domain
type = "A"
ttl = 60
failover_routing_policy {
type = "SECONDARY" # Identificando que e o Registro Secundário
ttl_override = 60
}
set_identifier = "secondary"
health_check_id = aws_route53_health_check.secondary.id
}
Configurar failover de DNS - Amazon Route 53
6.2 — Elasticache Multi Region com Global Datastores
O Global Datastore é um recurso do Amazon ElastiCache, um serviço gerenciado de cache na nuvem da Amazon Web Services (AWS). Ele permite a replicação automática e síncrona de dados entre regiões geográficas distintas, proporcionando uma solução de cache altamente disponível e resiliente.
Configurar um Global Datastore significa criar um ambiente de cache que é distribuído em várias regiões da AWS. Isso beneficia aplicações ou serviços que operam em escala global, exigindo acesso rápido a dados em cache, não importando onde os usuários estão localizados.
Com o Global Datastore, o ElastiCache cuida da replicação dos dados em tempo real entre as regiões de forma automática, assegurando que os dados estejam sempre atualizados e acessíveis em todos os locais.
Este recurso não foi incluído no artigo pois os replication groups não suportam escrita bilateral nos clusters de replicação de outras regiões, apenas permitindo promoção automática em caso de failover provocado por uma falha no primário.
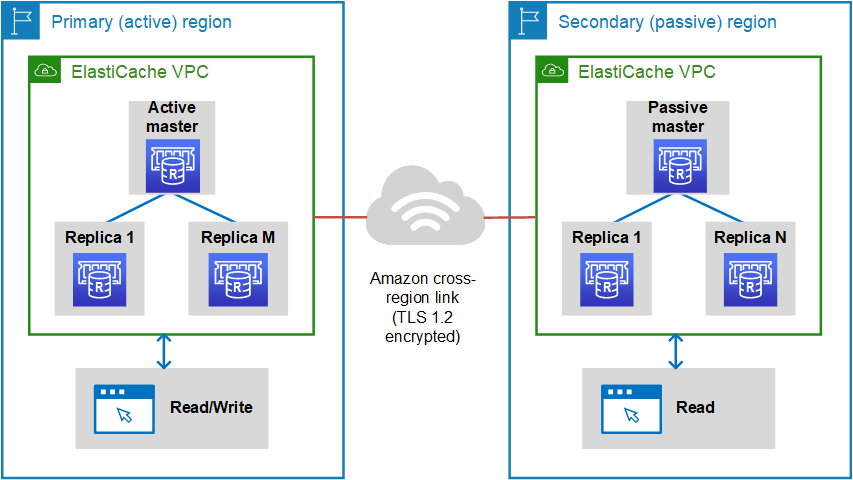
Exemplo de Implementação em Terraform
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
resource "aws_elasticache_global_replication_group" "main" {
providers = {
aws = aws.primary
}
global_replication_group_id_suffix = var.project_name
primary_replication_group_id = aws_elasticache_replication_group.primary.id
engine_version = "6.2"
}
resource "aws_elasticache_replication_group" "primary" {
providers = {
aws = aws.primary
}
replication_group_id = "${var.project_name}-primary"
description = "primary replication group"
engine = "redis"
engine_version = "6.0"
node_type = "cache.m5.large"
num_cache_clusters = 1
lifecycle {
ignore_changes = [engine_version]
}
}
resource "aws_elasticache_replication_group" "secondary" {
providers = {
aws = aws.disaster-recovery
}
replication_group_id = "${var.project_name}-secondary"
description = "secondary replication group"
global_replication_group_id = aws_elasticache_global_replication_group.example.global_replication_group_id
num_cache_clusters = 1
lifecycle {
ignore_changes = [engine_version]
}
}
Replication across AWS Regions using global datastores - Amazon ElastiCache for Redis
6.3 — RDS Cross Region Read Replicas
O Cross-Region Read Replicas do Amazon RDS (Relational Database Service) é um recurso que permite replicar dados de um banco de dados em uma região para outras regiões. Isso melhora a disponibilidade, desempenho e resiliência de bancos de dados globais.
Ao usar Cross-Region Read Replicas, você pode criar cópias de leitura do seu banco de dados em regiões distantes, que são úteis para consultas intensivas, carga distribuída e redução de latência.
O recurso é limitado a operações de leitura, não permitindo escritas bilaterais.
Cross-Region read replicas - Amazon Relational Database Service
6.4 — Aurora Global Database
O Aurora Global Database é um recurso do Amazon Aurora, compatível com MySQL e PostgreSQL. Permite a criação de um ambiente de banco de dados com replicação automática entre múltiplas regiões.
Você pode criar um cluster primário e replicar dados para até cinco regiões secundárias. As secundárias são leitura ou requerem intervenção manual para outros usos, o que também limitou sua inclusão neste artigo.
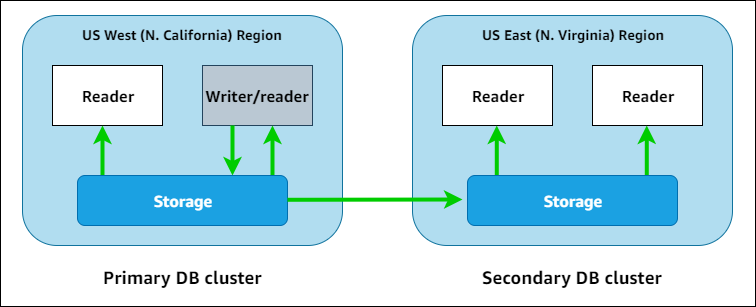
Using Amazon Aurora global databases - Amazon Aurora
6.5 — Secrets Manager Multi-Region Replication
A replicação Multi-Region do Secrets Manager permite replicar secrets para regiões adicionais para DR, conformidade ou baixa latência.
A replicação é automática: atualizações em uma região primária são replicadas para todas as secundárias. Não foi considerado para o artigo por não ter uso em contextos não relacionados à gestão de segredos e por ainda não estar disponível para Terraform.

How to replicate secrets in AWS Secrets Manager to multiple Regions | Amazon Web Services
6.6 — Mirror Maker e MSK
O Mirror Maker é uma ferramenta do Amazon Managed Streaming for Apache Kafka (MSK), que permite replicar tópicos e partições de um cluster para outro.
O Mirror Maker replica dados do Kafka entre regiões, suportando DR, leitura de baixa latência e distribuição de carga.
Para replicar usando o Mirror Maker, é necessário configurar um link entre VPCs de diferentes regiões.
Migrating to an Amazon MSK Cluster - Amazon Managed Streaming for Apache Kafka
Setting up Mirror Maker
Conclusão
Minha conclusão é que esse artigo foi muito extenso e cansativo. E a porcentagem de pessoas que vão chegar até esse ponto deve ser muito baixa. Se você chegou até aqui, saiba que eu estou muito feliz, e por favor, me deixe saber disso. Esse foi de longe o artigo mais extenso e cansativo que eu já escrevi nos últimos anos, e espero de coração que ajude na firmação de conceitos e a pensar em estratégias paupáveis para o seu contexto depois de ver os exemplos daqui.
E um agradecimento de coração a todos os revisores que dedicaram seu tempo pra avaliar o artigo.
Repositórios do Artigo
- GitHub - msfidelis/aws-multi-region-disaster-recovery: Example to explain how to implement minimal multi-region architecture on AWS with disaster recovery
- GitHub - msfidelis/aws-multi-region-disaster-recovery-apps: Apps to aws-multi-region-disaster-recovery example
Links e Referências
- Terraform — Global Replication Groups (https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/elasticache_global_replication_group)
- Terraform – Lookup (https://developer.hashicorp.com/terraform/language/functions/lookup)
- Terraform – Maps (https://developer.hashicorp.com/terraform/language/expressions/types#maps-objects)
- AWS Disaster Recovery Workshop (https://disaster-recovery.workshop.aws/en/)
- Creating Disaster Recovery Mechanisms Using Amazon Route 53 (https://aws.amazon.com/blogs/networking-and-content-delivery/creating-disaster-recovery-mechanisms-using-amazon-route-53/)
- Resilience in Amazon Route53 (https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/disaster-recovery-resiliency.html)
- Amazon DynamoDB Global Tables (https://aws.amazon.com/dynamodb/global-tables/)
- AWS Disaster Recovery Strategies (https://xebia.com/blog/aws-disaster-recovery-strategies-poc-with-terraform/)
- How To Build a Custom Disaster Recovery Process for AWS Applications (https://www.encora.com/insights/how-to-build-a-custom-disaster-recovery-process-for-aws-applications)
- Google Disaster recovery planning guide (https://cloud.google.com/architecture/dr-scenarios-planning-guide)
- Disaster Recovery for Multi-Region Kafka at Uber (https://www.uber.com/en-KW/blog/kafka/)
Obrigado aos Revisores
- Rafael - (@ raffasarts)
- Caio Delgado — (@ caiodelgadonew)
- Bernardo — (@ indiepagodeiro)
- Kaleb — (@ kalves_rohan)
- Luis Garavatti — (@ lhgaravatti)
- Luiz Aoqui – (@ luiz_aoqui)
Me sigam no Twitter para acompanhar as paradinhas que eu compartilho por lá!
Te ajudei de alguma forma? Me pague um café (Mentira, todos os valores doados nessa chave são dobrados por mim e destinados a ongs de apoio e resgate animal
Chave Pix: fe60fe92-ecba-4165-be5a-3dccf8a06bfc
