
System Design - Event Sourcing

Dando sequência à exploração de patterns arquiteturais da série de System Design, hoje vamos colocar um marco de complexidade estrutural falando de Event Sourcing e dos conceitos e componentes que viabilizam a implementação do mesmo. O objetivo deste capítulo será oferecer uma revisão honesta e conceitual sobre a adoção desse modelo, e também suas complexidades sistêmicas, que são altas.
Ao longo do conteúdo, são discutidos os principais conceitos que compõem esse modelo, como Event Store, Event Bus, Projections, Read Models, Snapshotting e Rehydration, e como eles se relacionam para formar um ecossistema transacional e historicamente reconstruível.
Além dos fundamentos conceituais, o texto aborda estratégias práticas para lidar com consistência eventual, versionamento, idempotência e controle de concorrência, temas essenciais para o design de sistemas distribuídos de alta confiabilidade e larga escala.
Definindo Event Sourcing
Event Sourcing é um padrão arquitetural que busca registrar todos os eventos que alteram o estado de uma entidade em uma base de dados de forma histórica. Esse padrão é usado para “contar a história” de uma transação ou entidade ao longo de todo o seu ciclo de vida.
Em sistemas em que uma entidade muda com frequência, como, por exemplo, os estados de um pagamento, os estados de um usuário ou operador do sistema, uma compra ou as fases de fabricação de um produto, o Event Sourcing visa registrar cada alteração de forma imutável.
O objetivo não é armazenar apenas o estado atual, mas todas as alterações ao longo do tempo de forma cronológica, como um log de eventos que podem ser auditados e recompostos. Isso é útil em sistemas event-driven, que emitem eventos constantemente para outros sistemas e que, eventualmente, precisam recompor os estados de forma distribuída.
Persistência Tradicional e Event Sourcing
À medida que a evolução arquitetural de sistemas distribuídos ocorre e desenvolve integrações e dependências mais complexas, a forma tradicional de persistir o “estado atual” de um registro dentro do sistema tende a se tornar limitada devido a critérios de resiliência e recuperação de falhas.
Em modelos tradicionais, o paradigma central é o “State Mutation”, onde o estado atual é sempre substituído a cada operação que ocorre. A proposta é responder como uma entidade do sistema “está agora”, mas não “como ela chegou até aqui”.
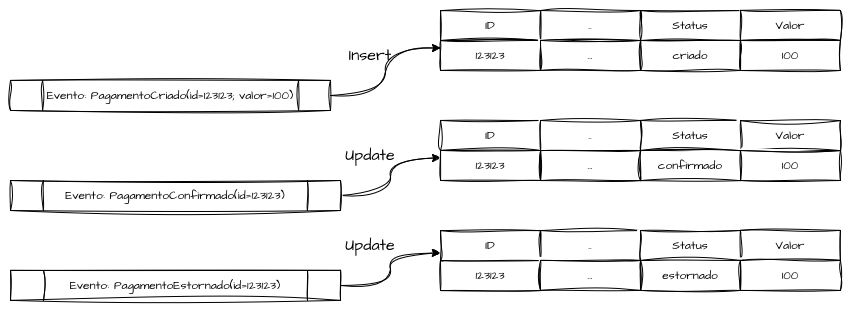
Como visto, o estado de cada entidade é mutável por padrão, ou seja, cada operação de INSERT, UPDATE e DELETE substitui as informações anteriores, apagando o histórico. Por exemplo, em um sistema de pagamentos, podemos receber uma série de eventos de domínio que representam ações realizadas diretamente sobre a entidade.
| Evento | Ação | Status |
|---|---|---|
| PagamentoCriado(valor=100) | Insert | status=criado |
| PagamentoConfirmado | Update | status=confirmado |
| PagamentoEstornado | Update | status=estornado |
O modelo de Event Sourcing propõe uma inversão conceitual, onde, em vez de armazenar o estado atual de entidades e registros após uma série de operações de INSERT, UPDATE e DELETE, o sistema acumula uma sequência de eventos imutáveis e armazena todos eles para derivar o estado atual.
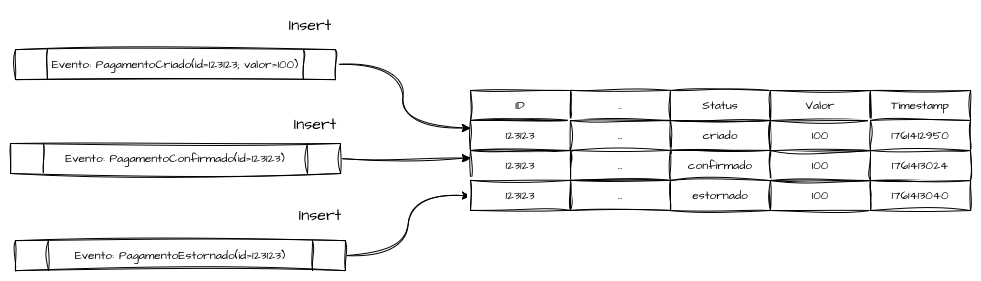
Cada operação representa uma ação imutável que indica que “algo aconteceu” e está permanentemente registrada, fazendo com que o estado represente, de fato, uma sequência ordenada e temporal de eventos, e não apenas sua atualização mais recente.
Todas as operações em um sistema baseado em Event Sourcing são naturalmente inserções de novos dados sobre o estado da entidade, sendo necessário recuperar o último estado sempre que ele precisar ser consultado. Isso exige mais das operações de leitura em casos de alto volume — um trade-off conhecido, em que é necessário empregar otimizações avançadas.
Esse modelo de persistência, quando construído de forma consciente e responsável, permite criar sistemas auditáveis, reproduzíveis e naturalmente reativos, mas exige um nível elevado de maturidade de engenharia para evitar pontos de gargalo e custos excessivos.
Arquitetura Event-Sourcing
Agregados
Dentro de uma arquitetura de Event Sourcing, o agregado é a unidade lógica e transacional que agrupa uma entidade e todas as regras de negócio necessárias para garantir sua consistência interna. Ele representa o objeto no qual eventos são aplicados, validados, ordenados e evoluídos, assegurando que o estado resultante seja sempre derivado de uma sequência determinística de fatos temporais.
Agregados são a estrutura de dados que permite um contexto de consistência, responsável por decidir quais eventos podem ocorrer, em que ordem e sob quais condições, preservando as modificações das entidades dentro do domínio. Dentro do agregado, as mutações de estado são convertidas em eventos imutáveis, que posteriormente serão armazenados no Event Store e publicados no Event Bus, sendo a principal fonte de dados de uma arquitetura de Event Sourcing.
Event Store
O Event Store é o banco de dados central de uma arquitetura baseada em Event Sourcing. Um banco de dados de Event Store deve ser tratado como um ledger imutável, responsável por armazenar o log de todos os eventos que registram mudanças de estado das entidades do sistema, respeitando uma ordem temporal e absoluta.
A estrutura de dados de um Event Store, em vez de atualizar o estado atual, deve anexar um novo evento ao final do fluxo (stream) associado a uma determinada entidade ou agregado. Cada stream representa a linha do tempo de uma transação.
Um Event Store não armazena o estado de fato, apenas a história completa dos fatos. Por isso, o ponto crítico da construção dessas soluções está em garantir ordenação e atomicidade, para que seja possível reconstruir a entidade reaplicando os eventos em sequência.
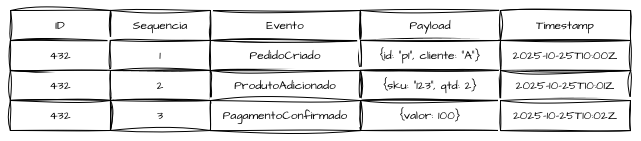
Ao reaplicar os três eventos da transação 432, o estado é reconstituído totalmente e de forma fiel, resultando no estado pago, com dois produtos adicionados ao cliente a.
Esse modelo é análogo ao append-only log, usado por sistemas como Kafka ou bancos contábeis — os dados nunca são substituídos, apenas acumulados. Por isso, é comparado a um ledger distribuído: um registro permanente, auditável e verificável ao longo do tempo de tudo o que aconteceu dentro de um domínio.

Modelar o Event Store de forma agnóstica em relação ao tipo de operação efetuada é um requisito obrigatório. Isso envolve utilizar campos livres ou blobs para armazenar dados e metadados do evento com fins de replicação e reprocessamento, além de empregar índices para otimização de consultas transacionais e recuperação de estados históricos.
Não é necessário utilizar bancos relacionais ou não relacionais para projetar Event Stores, embora isso seja o mais indicado. É possível utilizar opções como EventStoreDB e Apache Kafka para tais finalidades, considerando seus trade-offs de flexibilidade na gestão dos dados.
Event-Bus e Publishers
Dentro — e fora — de uma arquitetura de Event Sourcing, o Event Bus é o componente responsável por permitir que os eventos gerados dentro de um domínio sejam publicados e propagados para outros domínios, sistemas e subsistemas interessados nos acontecimentos e nas mudanças de estado de suas entidades.
Seu objetivo é carregar esses eventos de forma desacoplada até os consumidores do sistema.
O Event Store é o registro de verdade — a golden source dos eventos —, enquanto o Event Bus é o meio de projeção das consequências desses eventos.

Os publishers são componentes de um sistema baseado em Event Sourcing responsáveis por publicar os eventos confirmados no Event Store em tópicos, filas ou barramentos.
Esse comportamento de publicação deve ser atômico, e os eventos só podem ser emitidos no Event Bus quando a gravação e outras operações forem bem-sucedidas.
O Event Bus pode ser implementado sobre tecnologias como Kafka, RabbitMQ, SQS, NATS ou Pulsar, dependendo do SLA e das garantias necessárias.
Embora não sejam componentes obrigatórios em uma arquitetura de Event Sourcing, o Event Bus e o Event Store são grandes facilitadores em implementações de microserviços orientados a eventos.
De qualquer forma, um Event Bus deve preservar a ordenação dos eventos por stream ou aggregate e garantir que o evento seja entregue pelo menos uma vez, com deduplicação para evitar repetições não intencionais e idempotência no nível dos consumidores para permitir reprocessamentos seguros.
Um sistema baseado em Event Sourcing pode possuir múltiplos barramentos de service bus, responsáveis por registrar e transmitir eventos de domínio para consumidores específicos, com ações distintas em diferentes domínios.
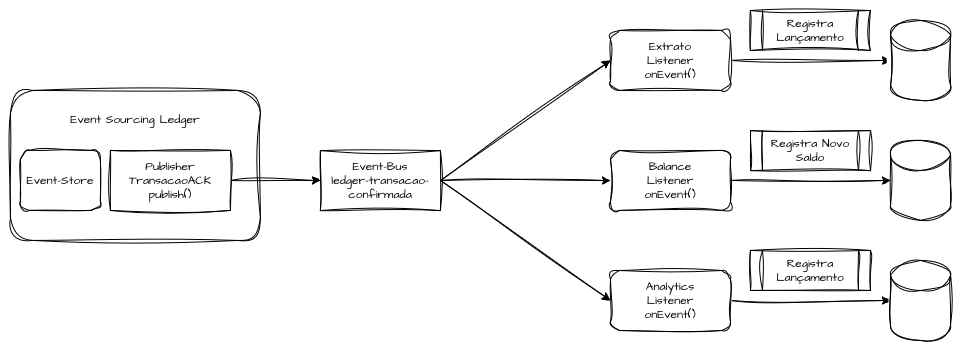
Um Event Bus com características de ledger distribuído, responsável por registrar de forma histórica todas as ações efetuadas dentro de contas bancárias ou livros-caixa, pode emitir eventos como “Nova Conta Registrada” para domínios que precisam persistir previamente uma estrutura base de conta antes de começar a consumir o evento central, como, por exemplo, uma transação, um saldo (Balance) ou um extrato (Statement).
Assim que forem emitidos eventos dentro do Event Sourcing responsável por registrar as transações, essas mensagens de transações persistidas são transmitidas para outro barramento de Event Bus, encarregado de notificar os domínios de que esses eventos ocorreram, permitindo compor o saldo e registrar de forma histórica os eventos de extrato.
Dessa forma, conseguimos notificar e recompor entidades inteiras dentro de domínios que aplicam suas próprias características de Event Sourcing ou persistência transacional, mantendo arquiteturas orientadas a eventos de forma eventualmente consistente.
Projections e Modelos de Leitura
Os Event Stores em sistemas baseados em Event Sourcing são otimizados para grandes volumes de escrita, porém podem apresentar desafios de leitura e recuperação de dados. Os bancos de dados principais devem conter apenas os logs dos fatos.
Para criar consultas sistêmicas e alimentar APIs ou outros processos, precisamos construir modelos otimizados para leitura.
Eventos, por definição, são ações que ocorreram no passado.
Projections são componentes ou processos utilizados para interpretar esses fatos e transformá-los em algo utilizável sistemicamente, em termos de leitura.
Uma projection é a consolidação de vários eventos de um mesmo identificador ou entidade que, após interpretados, resultam em um modelo de leitura (Read Model) armazenado para consultas otimizadas.
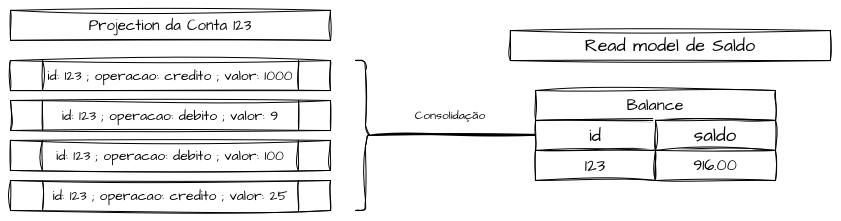
Em outras palavras, as projections são processos que “ouvem” os eventos do Event Store e atualizam uma visão derivada em um formato otimizado para leitura, seja do próprio sistema ou de outros.
Esses modelos são conhecidos como Modelos de Leitura (Read Models) e podem, sim, ser construídos sob uma visão de State Mutation.
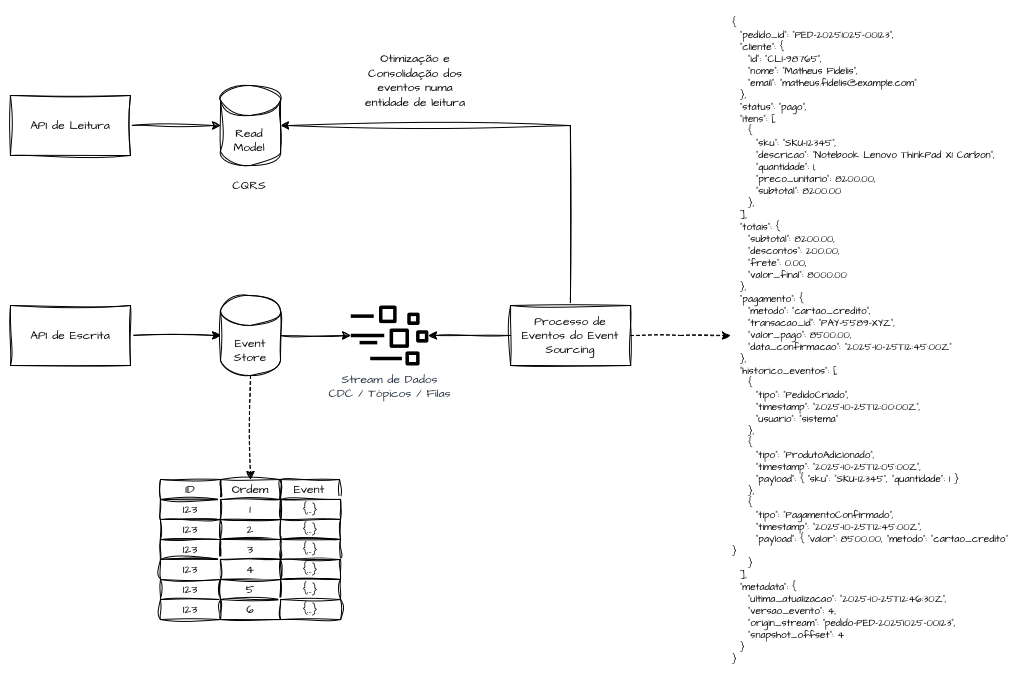
Projections são normalmente construídas com base no padrão CQRS (Command-Query Responsibility Segregation), no qual se porta, de forma síncrona ou assíncrona, um modelo otimizado para escrita para outro modelo otimizado para leitura.
Nos Read Models, podemos utilizar bancos de dados em memória para respostas rápidas, bancos orientados a documentos para buscas textuais ou ainda modelos relacionais e não relacionais para relatórios consolidados.
Read Models não são apenas caches de leitura — são representações materializadas e derivadas de fatos históricos ocorridos e registrados no Event Store.
Isso significa que eles devem evoluir junto com o domínio e com a semântica dos eventos, operando em tempo próximo do real.
Ao contrário do Event Sourcing, as projections são determinísticas em relação ao estado atual.
Os processos de replay dos eventos — em caso de reprocessamento temporal para recomposição de estados — devem refletir também nas projections, garantindo que elas representem o estado atual do sistema.
Em sistemas maiores, múltiplas projections coexistem, cada uma representando uma visão específica: analytics, relatórios, dashboards, filas de envio, catálogos etc.
Seguindo boas práticas de reprocessamento e elasticidade inerentes ao domínio principal, as Read Models distribuídas tornam-se efêmeras e descartáveis, podendo ser reconstituídas a qualquer momento.
Projections e Read Models Transacionais
Dentro de um modelo transacional, podemos agrupar pequenas projections dentro do mesmo banco de dados do Event Store de forma atômica.
Um Event Store não é otimizado para leitura — é otimizado para escrita intensiva.
Em processos que exigem alta carga de trabalho e grandes volumes de dados, uma quantidade maior de operações dentro de uma única transação do Event Store pode gerar gargalos e demandar escalabilidade vertical das aplicações e bancos de dados.

Nesse modelo, a prioridade é preservar atomicidade e consistência imediata.
Isso significa que, dentro de uma única transação, tanto o evento quanto a projeção derivada são persistidos de forma atômica.
O maior benefício desse modelo é a eliminação da latência entre escrita e leitura, permitindo consistência imediata em valores que não toleram divergência em nenhum estado.
Por outro lado, ele adiciona complexidade operacional ao Event Sourcing e aumenta a carga de operações sobre o Event Store, tornando-se um possível gargalo em cenários de alta volumetria.
Em contextos de grande volume, é comum aplicar o padrão “Transactional Outbox” como mecanismo mitigador.
Nesse padrão, o evento é escrito junto da projeção dentro da mesma transação, mas publicado posteriormente de forma assíncrona — garantindo atomicidade sem bloquear o throughput e criando uma ponte para o modelo semissíncrono.
Projections e Read Models Semissíncronos
O propósito inicial de um Event Sourcing é gerar uma fonte segura e confiável de dados transacionais, que possam ser reconstituídos e replicados.
No modelo transacional, como visto anteriormente, mesmo que algumas Read Models sejam construídas dentro do próprio Event Store de forma atômica, idealmente elas devem ser encaminhadas para aplicações responsáveis por tratar e otimizar esses dados para leitura, lidando com os dados transacionais apenas para atualização e reconstrução das projections.
Em outras palavras, é necessário reduzir qualquer outra operação que possa comprometer a capacidade dedicada à escrita e à confiabilidade.
Nesses casos, podemos aproveitar a afinidade transacional do Event Store para tratá-lo como uma “golden source atômica”, atualizando as Read Models de forma assíncrona e eventual.
Dessa forma, mantemos duas fontes do mesmo dado — uma voltada exclusivamente para persistência e confiabilidade, e outra otimizada para consulta, modelo ideal para grandes volumes de dados.
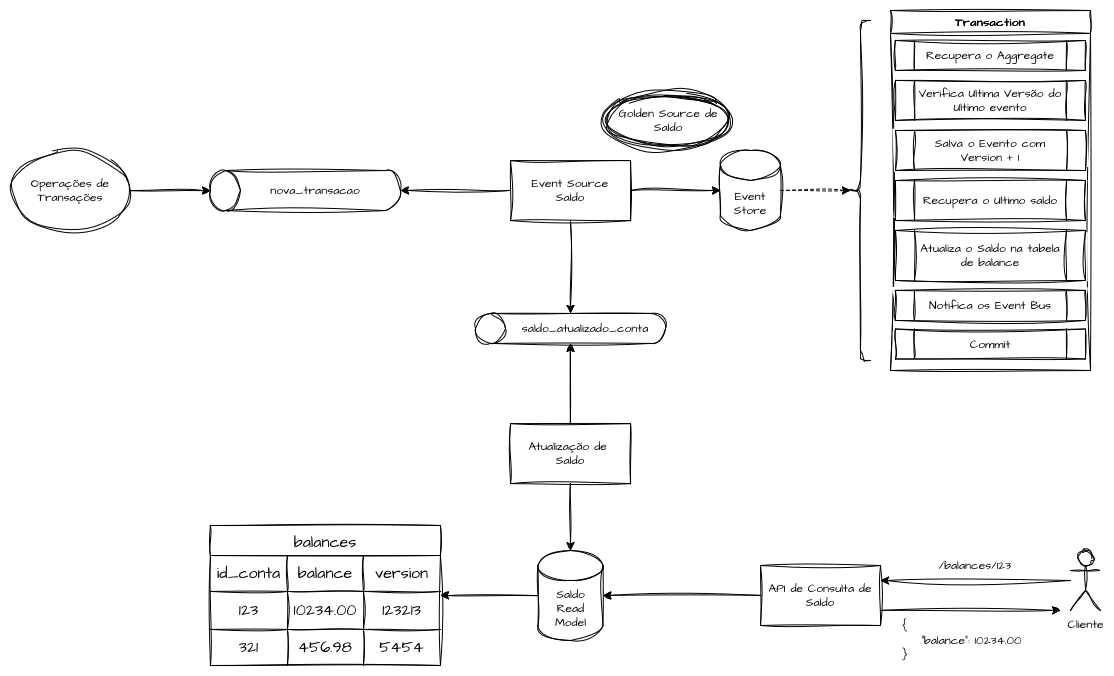
Operações de saldo precisam ser executadas de forma atômica e transacional para evitar inconsistências.
Devemos garantir exclusão mútua e lidar com diversas operações por meio de transações, assegurando que todos os lançamentos e movimentações sejam processados corretamente para se chegar ao saldo atual.
Essas operações podem ser executadas dentro de um Event Store.
Após cada transação, o novo saldo é calculado de forma atômica e publicado no Event Bus, onde pode ser consumido por um Read Model otimizado para consulta e exposição em cenários de alto volume de requisições.
Assim, o Event Store atua como a “fonte de verdade” e o Read Model como o “estado derivado seguro”.
Esse modelo deve ser adotado apenas quando é possível lidar com otimismo entre os níveis de consistência.
Projections e Read Models Assíncronos
Em sistemas que toleram consistência eventual, podemos encaminhar os dados registrados no Event Sourcing via Event Bus para a construção de Read Models diretamente nos domínios interessados, removendo assim qualquer complexidade adicional do Event Store.
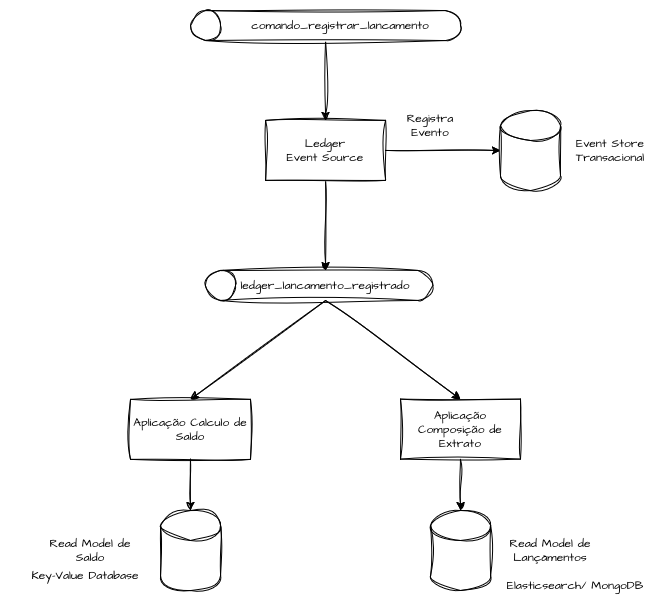
Dessa forma, a capacidade do Event Store permanece dedicada exclusivamente a registrar, confirmar e repassar os logs temporais, garantindo uma sequencialidade atômica.
Todos os modelos de leitura são construídos e processados de forma totalmente desacoplada do Event Store, porém assumimos que há um aumento computacional significativo em cada processo de reconstrução, sendo necessário o envio completo dos logs para reconstituição.
Eliminamos a complexidade e a demanda computacional do motor de eventos, transferindo-as para cada aplicação e domínio responsáveis por tratar os dados de forma agnóstica.
Reconstituição de Estados e Rehydration
A reconstituição de estado de um agregado dentro do Event Sourcing, popularmente conhecida como Rehydration, é o processo pelo qual utilizamos os logs sequenciais registrados no Event Store para reconstruir o estado de entidades e operações dentro e fora do domínio principal.
Um Event Store deve, idealmente, possuir ferramentas que permitam o reprocessamento sequencial de todos os registros, reaplicando os eventos associados a cada entidade. Esse processo é central ao Event Sourcing e permite que a história contada pelos logs seja novamente reconstituída.
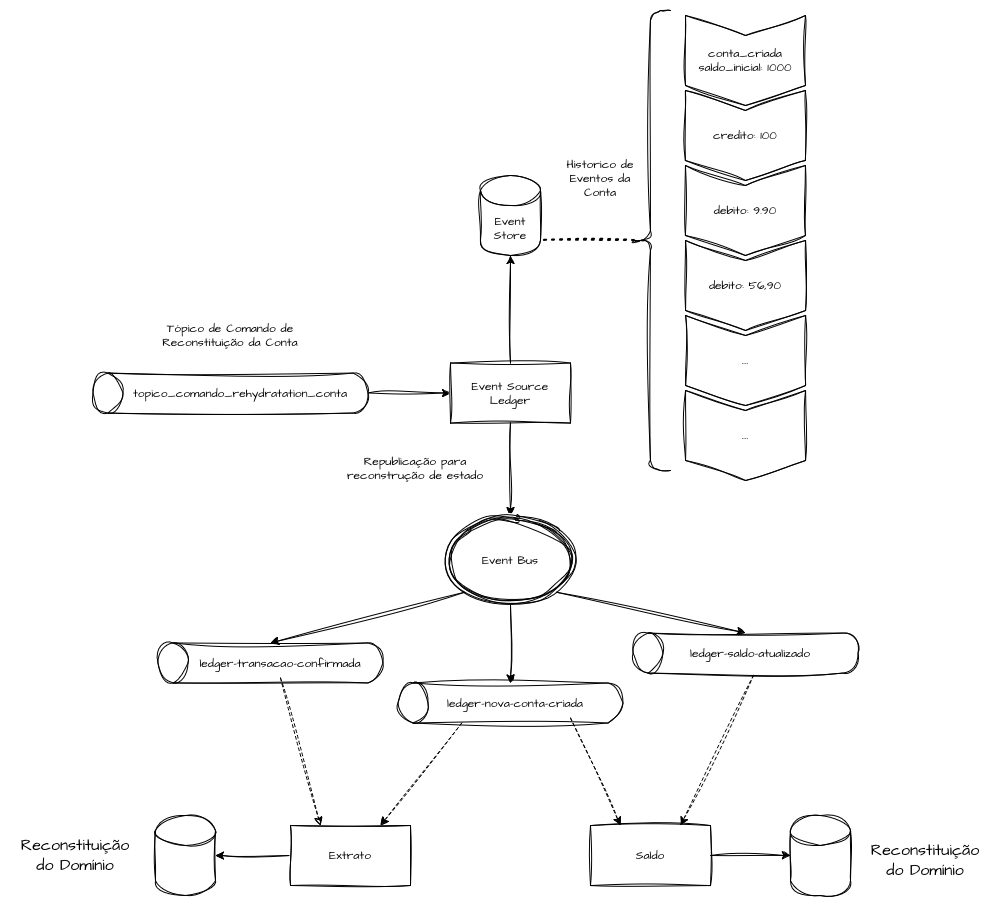
No cenário hipotético de um Event Store que registra todas as transações de crédito e débito e publica esses eventos confirmados para outros domínios, como saldo ou extrato do cliente — que disponibilizam Read Models sumarizados dessas informações —, imagine que um desses domínios sofra algum grau de inconsistência sistêmica ou manual, perdendo total ou parcialmente os dados e comprometendo a integridade das informações.
Nossa aplicação de Event Sourcing deve oferecer mecanismos para reaplicar todos os eventos e reenviá-los sequencialmente ao Event Bus, permitindo que os domínios subsequentes se reconstituam a partir dessas informações temporais, recalculando o saldo atual ou reconstruindo as visualizações de lançamentos.
Essa estratégia é especialmente útil em domínios complexos que exigem rastreabilidade e reconstituições auditáveis, como cadeias farmacêuticas (rastreio de medicamentos), linhas de fabricação, aplicação de descontos, prontuários médicos e históricos de pacientes ou processos de fechamento contábil.
Snapshotting
O modelo transacional propõe que todas as alterações e operações de estado sejam armazenadas para que esses dados possam ser auditados e recompostos ao longo do tempo.
Em um exemplo transacional de uma conta bancária, podemos saber pontualmente o saldo atual da conta, mas perdemos a trilha de eventos que levaram até esse estado.
Depósitos, saques, transferências e estornos, em conjunto, constroem o estado atual do saldo.
Em domínios onde auditabilidade, rastreabilidade ou causalidade são importantes, a ausência desse histórico representa um problema significativo.
No entanto, reconstruir o estado completo pode se tornar computacionalmente caro com o crescimento da base de eventos.
É nesse ponto que surge o conceito de Snapshotting.
Snapshotting é uma técnica de otimização que cria “pontos de restauração” intermediários do estado, como “fotografias” que permitem reconstruí-lo de forma incremental, sem precisar recalcular todas as transações a cada operação.
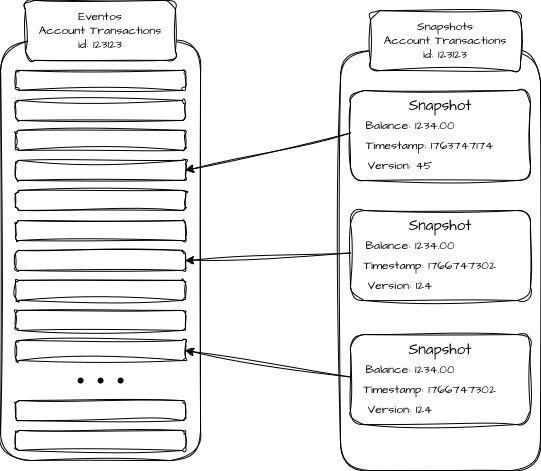
Um snapshot representa o estado de um agregado ou entidade em um determinado ponto no tempo, acompanhado de um índice do último evento aplicado para gerar aquele estado. Assim, caso seja necessário “reidratar” o estado, o sistema, em vez de processar todo o histórico do início ao fim, pode iniciar o processamento apenas a partir dos eventos ocorridos depois dele.
Por exemplo: a entidade “Saldo”, dentro do agregado “Conta”, pode possuir 1.000.000 de eventos históricos de lançamentos e movimentações.
Para recalcular o saldo, em vez de processar todos os eventos dispersos no banco de dados, o sistema pode gerar um snapshot a cada 10.000 eventos, contendo o saldo consolidado a partir do último evento. Para reconstruir o estado atual, basta carregar o último snapshot e aplicar os eventos posteriores a ele, reduzindo de forma considerável o tempo e o custo computacional de leitura.
No entanto, snapshots devem ser tratados como artefatos derivados e descartáveis, não como fonte primária de verdade. O Event Store continua sendo o “single source of truth”, e os snapshots são mecanismos auxiliares de performance pontual para a operação.
Versionamento e Garantias de Ordem em Consistência Eventual (Last-Write-Wins)
Quando existe a necessidade de reidratar um, alguns ou todos os agregados, precisamos garantir que os domínios consumidores desses eventos atendam a certos critérios para que o processo ocorra da melhor forma possível, assegurando um resultado final consistente das operações.
Dentro do Event Sourcing, o Event Store deve garantir a ordenação local dos eventos de um mesmo agregado, ou seja, todos os eventos relacionados à mesma entidade precisam ser aplicados na sequência temporal em que ocorreram.
Essa ordenação local é o que permite reconstruir estados de forma determinística.
Quando falamos de Event Bus, o Event Store pode garantir a publicação dos eventos à medida que ocorrem, porém a ordem em que serão consumidos não é globalmente garantida por padrão.
Isso significa que eventos publicados em ordem podem chegar fora de ordem em réplicas distintas ou sistemas diferentes, sofrendo variações de tempo de processamento até a devida atualização de estado.
Em arquiteturas event-driven, isso não é uma falha — é o comportamento esperado da consistência eventual.
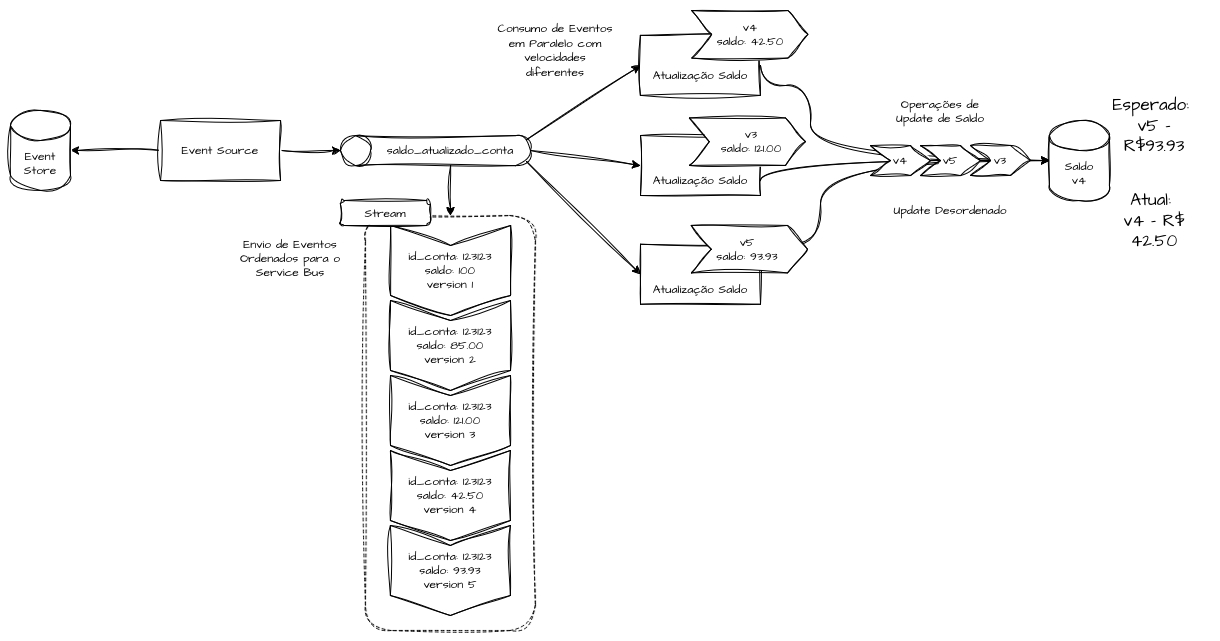
Em uma operação de saldo, podemos ter várias transações atualizando o saldo de um cliente em um curto intervalo de tempo, mas todas são inseridas com característica temporal e atômica no Event Store e publicadas sequencialmente no Event Bus.
Porém, a ordem de consumo e processamento nos clientes finais pode ocorrer de forma paralela e desordenada, o que pode, por exemplo, gerar uma Read Model final incorreta ao processar eventos mais novos antes de eventos antigos.
Nesse cenário, o modelo Last-Write-Wins (LWW) é uma forma simples de lidar com conflitos de escrita ou reprocessamentos duplicados.
Ele define que, em caso de eventos concorrentes para o mesmo agregado, o último evento válido (por timestamp ou version) deve prevalecer.
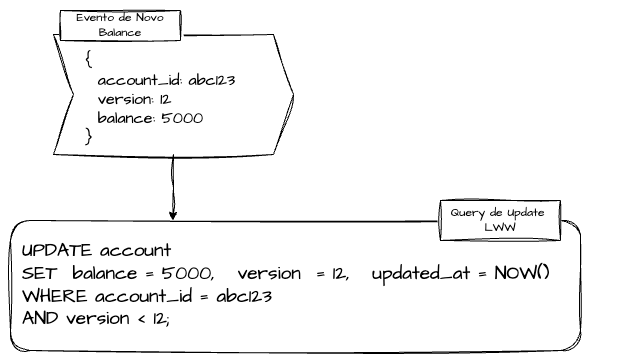
Em eventos e sinais produzidos por arquiteturas baseadas em Event Sourcing, cada evento deve possuir um id único e uma version incremental, que identificam a versão do evento a ser comparada.
Isso evita duplicações em sistemas subjacentes e permite evoluir o stream de eventos com segurança.
Esse processo também pode ser conduzido com timestamps Unix, indicando a ordem temporal direta.
Os sistemas que consomem eventos produzidos no Event Bus devem realizar checagens constantes da versão do evento em relação ao estado atual persistido, para evitar sobrescritas indevidas.
Essas verificações podem ser realizadas de forma transacional, com condicionais em nível de código, ou por meio de escritas condicionais em bancos de dados que suportem esse tipo de operação.
Idempotência em Domínios Complexos
A idempotência é a propriedade que permite que uma operação seja executada múltiplas vezes sem alterar o resultado final.
Em sistemas centralizados, isso pode ser garantido por meio de transações ACID.
Mas em arquiteturas distribuídas, onde eventos são propagados de forma assíncrona e cada serviço mantém sua própria consistência, a idempotência precisa ser explicitamente e cuidadosamente projetada.
Em sistemas distribuídos baseados em eventos, ou em arquiteturas assíncronas em geral, a idempotência é um requisito fundamental que permite operar arquiteturas complexas de forma segura.
Isso se deve ao fato de que a entrega e o processamento de eventos são inerentemente inconstantes e não determinísticos, podendo ocorrer em duplicidade, sofrer race conditions ocasionais ou falhar durante a execução e precisar ser reiniciados, o que reforça a necessidade de evitar esforço computacional redundante.
Em arquiteturas baseadas em Event Sourcing, podemos decidir reprocessar todos os eventos de um período específico para recompor projeções e notificações para sistemas subjacentes de forma histórica.
Para que esse processo ocorra corretamente tanto dentro do domínio quanto nos domínios adjacentes, é necessário garantir processos de idempotência distribuída e controle de versão dos eventos, assegurando que eventos já processados não gerem efeitos colaterais ou resultados inconsistentes.
Todos os domínios downstream devem realizar checagens e manter chaves de idempotência fortes e consistentes a todo momento.
Referências
- Github: Event Source Distributed Ledger
- Event Sourcing
- Event sourcing pattern
- Eventsourcing e EventStore, Projeções, Snapshots
- Event store
- Explorando o EventStore – Overview
- Event Bus & Event Store
- How to Create a Event Bus in Go
- Implementing event-based communication between microservices (integration events)
- Guide to Projections and Read Models in Event-Driven Architecture
