
Blueprint - Rate Limit por Pods com Istio Service Mesh

Este blueprint tem objetivo de mostrar a forma de utilizar o EnvoyFilter para implementar um rate limit local, a nível de pod, para preservar o capacity a nível proativo e restritivo de cada unidade da aplicação.
A prova de conceito busca validar formas de estabalecer uma restrição estável e fixa do quanto “cada pod da aplicação pode receber sem degradar”. Uma vez que essa informação é conhecida, podemos implementar rate limit de forma granular para preservar a saturação progressiva de cada unidade computacional. Para isso, vamos utilizar o Istio Service Mesh e o Envoy Filter para configurar a estabilidade local do serviço.
Se um cliente concentrar toda a carga em apenas um Pod (por afinidade de conexão ou hash), ele estará limitado a 3 TPS. Isso significa que o sistema, mesmo escalado horizontalmente, ainda respeita limites individuais de cada pod em execução, e não globalmente.
Entendendo o Algoritmo de Token Bucket do Envoy Proxy
O algoritmo de Token Bucket implementado pelo Envoy é um mecanismo de controle de taxa de requisição baseado numa ideia de crédito acumulativo de acordo com o tamanho do bucket e sua taxa de reposição.
Diferente de abordagens puramente restritivas como fixed window counters, o token bucket permite absorver pequenos bursts controlados, mantendo previsibilidade sob carga sustentada.
No contexto do envoy.filters.http.local_ratelimit, cada sidecar mantém localmente um bucket com três parâmetros fundamentais:
- max_tokens — capacidade máxima do bucket.
- tokens_per_fill — quantidade de tokens adicionados a cada intervalo.
- fill_interval — periodicidade de reposição.
-
1 2 3 4 5 6 7 8
# ... value: stat_prefix: http_local_rate_limiter token_bucket: max_tokens: 3 tokens_per_fill: 3 fill_interval: 1s # ...
Caso o max_tokens e o tokens_per_fill possuam valores iguais, passamos convergir para um algoritmo de Leaky Bucket, onde não acumulamos creditos no bucket e passamos a aceitar e recusar requisições sobre uma taxa estável e fixa, cenário cujo qual vamos abornar dessa prova de conceito.
Implementação via EnvoyFilter
A implementação via EnvoyFilter insere o filtro HTTP local_ratelimit diretamente no HTTP Connection Manager do listener inbound do sidecar. O uso de context: SIDECAR_INBOUND garante que o controle seja aplicado na entrada do Pod, protegendo o workload antes mesmo da requisição atingir o container da aplicação
Exemplo - 3 Transações por Segundo por Pod
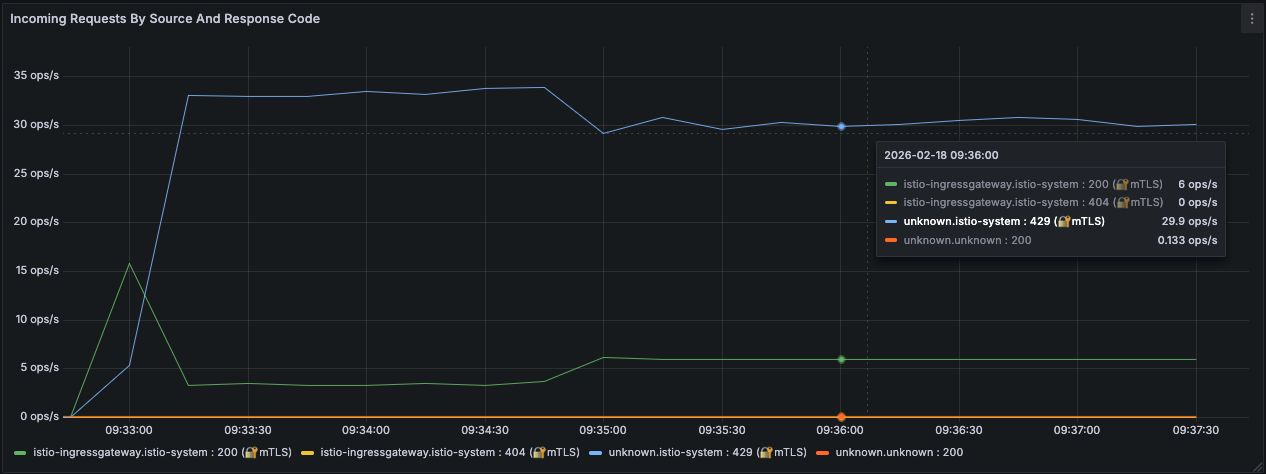
O cenário de entrada busca estabelecer um limite local de 3 transações por segundo para cada POD em serviço na estratégia de leaky bucket, ou seja, não existe margem para absorver picos de crédito.
- 2 pods
- max_tokens: 3
- tokens_per_fill: 3
- fill_interval: 1s
O throughput máximo agregado será aproximadamente:
1
3 TPS × 2 Pods = 6 TPS
Exemplo Completo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: shard-router-local-rate-limit
namespace: istio-system
spec:
workloadSelector:
labels:
app: shard-router
configPatches:
- applyTo: HTTP_FILTER
match:
context: SIDECAR_INBOUND
listener:
filterChain:
filter:
name: "envoy.filters.network.http_connection_manager"
patch:
operation: INSERT_BEFORE
value:
name: envoy.filters.http.local_ratelimit
typed_config:
"@type": type.googleapis.com/udpa.type.v1.TypedStruct
type_url: type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit
value:
stat_prefix: http_local_rate_limiter
token_bucket:
max_tokens: 3
tokens_per_fill: 3
fill_interval: 1s
filter_enabled:
runtime_key: local_rate_limit_enabled
default_value:
numerator: 100
denominator: HUNDRED
filter_enforced:
runtime_key: local_rate_limit_enforced
default_value:
numerator: 100
denominator: HUNDRED
response_headers_to_add:
- append: false
header:
key: x-local-rate-limit
value: 'true'
Exemplo - 10 Transações por Segundo por Pod
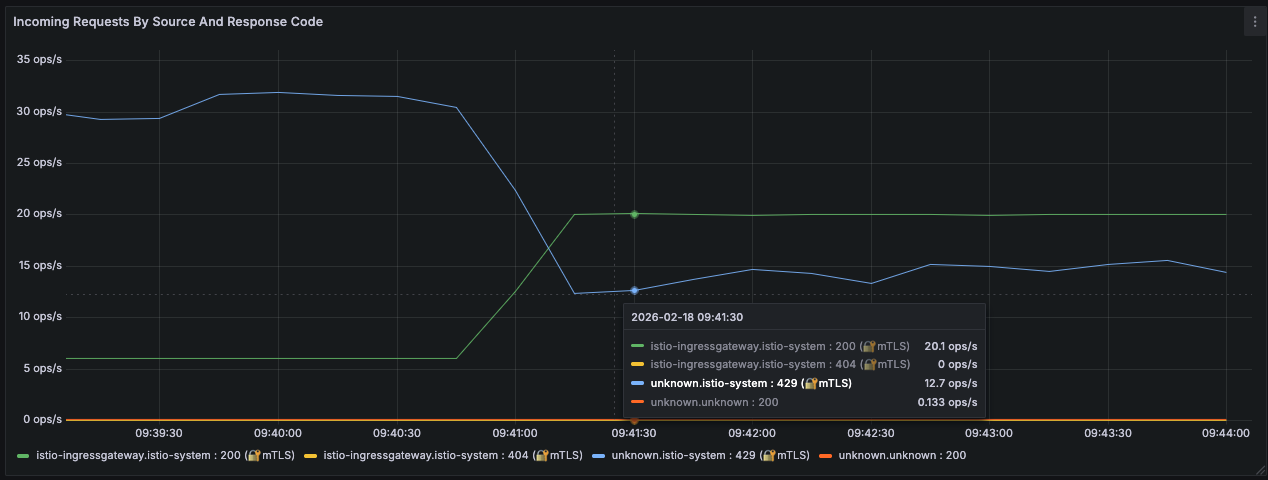
O segundo cenário busca estabelecer um limite local de 10 transações por segundo também na estratégia de leaky bucket.
- 2 pods
- max_tokens: 10
- tokens_per_fill: 10
- fill_interval: 1s
O throughput máximo agregado será aproximadamente:
1
10 TPS × 2 Pods = 20 TPS
Exemplo Completo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: shard-router-local-rate-limit
namespace: istio-system
spec:
workloadSelector:
labels:
app: shard-router
configPatches:
- applyTo: HTTP_FILTER
match:
context: SIDECAR_INBOUND
listener:
filterChain:
filter:
name: "envoy.filters.network.http_connection_manager"
patch:
operation: INSERT_BEFORE
value:
name: envoy.filters.http.local_ratelimit
typed_config:
"@type": type.googleapis.com/udpa.type.v1.TypedStruct
type_url: type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit
value:
stat_prefix: http_local_rate_limiter
token_bucket:
max_tokens: 10
tokens_per_fill: 10
fill_interval: 1s
filter_enabled:
runtime_key: local_rate_limit_enabled
default_value:
numerator: 100
denominator: HUNDRED
filter_enforced:
runtime_key: local_rate_limit_enforced
default_value:
numerator: 100
denominator: HUNDRED
response_headers_to_add:
- append: false
header:
key: x-local-rate-limit
value: 'true'
