Keda - Escalando Aplicações por Requisições HTTP em Ambientes de Alta Demanda

O Keda Autoscaler é uma das minhas tecnologias favoritas no Landscape da CNCF. Considero, sem meias palavras, divertidas as possibilidades que ele oferece para trabalhar com autoscaling.
Em serviços de alta demanda, como e-commerces, instituições financeiras e serviços de streaming, o fluxo de requisições é ininterrupto. Porém, a quantidade delas pode variar dramaticamente em determinados períodos do dia, do mês ou do ano. Isso exige que os sistemas subjacentes, que atendem essas solicitações, acompanhem essa demanda em tempo real, adaptando-se rapidamente para manter a performance e a disponibilidade.
Neste artigo rápido, vou apresentar uma prova de conceito interessante para proporcionar o escalonamento da sua aplicação por meio da demanda, ou seja, requisições de consumo dentro de um período de tempo, utilizando o Keda (Kubernetes Event-driven Autoscaling) com métricas customizadas do Prometheus.
Fundamentos e Premissas
O monitoramento de TPS/RPS em ambientes de alta demanda não é apenas uma medida de desempenho, mas também um indicador crucial para direcionamentos e tomadas de decisão arquitetural, tanto na concepção de novos serviços quanto na evolução de serviços existentes. Essa informação permite a escolha mais adequada de estratégias de capacidade, desenhos arquiteturais, identificação de gargalos e otimização de recursos.
Para esta prova de conceito, vamos assumir algumas premissas, como de costume, para tornar a análise o mais objetiva possível.
A ideia é considerar uma aplicação muito sensível ao tráfego, que recebe picos de acesso em períodos aleatórios do dia. Vamos presumir também que já conhecemos algumas informações cruciais para o estudo, como os limiares (thresholds) que cada pod consegue suportar sem degradar sua performance.
Premissas dessa Prova de Conceito
- Cada réplica da minha aplicação hipotética suporta, sem se degradar, 10 tps (transações por segundo).
- Essa informação foi obtida através de testes de carga hipotéticos realizados previamente.
- Com isso, é necessário que minha aplicação tenha 10 réplicas em operação quando as solicitações atingirem 100 tps.
- Similarmente, são necessárias 4 réplicas se o fluxo cair para 40 tps.
- Da mesma forma, são necessárias 20 réplicas se o fluxo aumentar para 200 tps.
- Independentemente do volume de transações, nunca posso ter menos de 3 réplicas em funcionamento por questões de disponibilidade.
- E assim por diante…
O “Problema” de Escalar por Uso e Saturação de CPU e Memória
Sendo bem direto, não existe um “problema” em si ao escalar utilizando CPU e Memória. Na realidade, essa abordagem atende a 99% dos casos de escalabilidade horizontal. Escalar por métricas customizadas ou por volume de transações é uma decisão que pode ou não ser adequada para seu workload. Compreender e comparar alternativas ao autoscaling baseado no consumo de recursos é crucial para explorar os diferentes tipos de abordagens de escalabilidade existentes em ambientes cloud native.
Como em todos os tipos de tecnologia, existem trade-offs a considerar:
Vantagens
- Simplicidade: Fácil de configurar e amplamente adotado como padrão, já que o uso de CPU/Memória é um indicador comum de performance.
- Eficiência: Garante a utilização eficiente dos recursos computacionais alocados no cluster para a carga de trabalho, minimizando desperdícios por recursos subutilizados.
Desvantagens
- Orientação a Uso: O uso de CPU/Memória pode não refletir com precisão a carga real da aplicação, especialmente em serviços de I/O ou com requisitos específicos.
- Aumento no tempo de Resposta: Mudanças no uso de CPU podem não corresponder imediatamente a alterações na demanda, podendo causar picos no tempo de resposta até que os indicadores de CPU acionem o escalonamento.
Portanto, optar por escalar baseado na quantidade de requisições pode ser desafiador, pois requer configuração mais detalhada, maior conhecimento da aplicação e seu comportamento, além de instrumentação adicional. Embora ferramentas convencionais frequentemente sejam plug n’ play, o escalonamento baseado em requisições pode ser ideal para aplicações sensíveis a variações bruscas de tráfego.
Como Definir os Thresholds de Suporte de Cada Réplica?
Responder a essa pergunta é complexo, mas existem métodos para obter essa informação valiosa. O mais indicado é realizar um teste de carga, e o seguinte roteiro pode ser útil para elaborar seus testes:
- Passo 1: Em um ambiente próximo ao de produção, configure manualmente as réplicas para 1. Quanto mais próximo da realidade, maior será a acurácia desse teste em termos de capacidade.
- Passo 2: Estabeleça quais são os limites aceitáveis de tempo de resposta.
- Passo 3: Utilize ferramentas como k6, cassowary, locust para injetar carga gradualmente e identificar em qual volume sua aplicação começa a degradar e ultrapassar o tempo de resposta aceitável.
- Passo 4: Aumente a quantidade de réplicas para 2, 3, 4 e repita o processo para verificar se a estimativa se mantém à medida que o throughput aumenta com o número de réplicas.
- Passo 5: A média desses números pode ser interpretada inicialmente como a resposta para “quanto cada réplica da minha aplicação suporta”.
- Passo 6: Vale lembrar que fatores como dependências, bancos de dados, caches, disco, etc., podem influenciar nesse teste. Portanto, quanto mais você puder simular essas dependências, melhor.
- Passo 7: Esse teste pode evoluir até que você encontre o “limite máximo” de escala da sua arquitetura, um número valioso para entender gargalos e planejar evoluções futuras. Podemos falar mais sobre isso em outro post – é um tema interessante.
Essa configuração também pode ser derivada de uma estimativa experiente (vulgo chutômetro), embora essa abordagem seja menos precisa.
Implementação do Keda
O objetivo aqui não é replicar a documentação do Keda, mas focar nos aspectos cruciais para atingir o objetivo da nossa Prova de Conceito (PoC). Para informações mais detalhadas e exemplos adicionais, consulte as referências ao final deste texto. Agora, vamos abordar os passos necessários para construir um ScaledObject usando métricas do Prometheus, que nos auxiliará a escalar a aplicação com base no tráfego.
Encontrando a Métrica Ideal
Há uma grande chance de que a métrica desejada já exista e esteja sendo bem monitorada. Precisamos identificar qual métrica será utilizada para contabilizar as requisições recebidas pelo nosso workload. Segue uma referência útil:
Istio Service Mesh
A principal métrica que podemos usar para monitorar o tráfego de entrada no Istio é istio_requests_total, especificando o destination_service_name que desejamos observar. Existem outros parâmetros de configuração, como reporter e source_service_name, que podem tornar a escalabilidade mais granular. No entanto, para simplificar, utilizaremos as configurações mais básicas neste exemplo:
1
sum(rate(istio_requests_total{destination_service_name="chip"}[1m]))
Envoy Proxy
Outra opção é utilizar o contador envoy_http_downstream_rq_total do Envoy, que totaliza os requests recebidos. O Envoy é uma das tecnologias mais versáteis e amplamente utilizadas no ecossistema Cloud Native. Ele serve como base para diversos tipos de ingressos, sidecars, service meshes e outros ambientes. Portanto, esta métrica é comumente disponível e pode ser uma escolha eficaz para o monitoramento de tráfego.
1
sum(rate(envoy_http_downstream_rq_total{envoy_http_conn_manager_prefix="chip"}[1m]))
Nginx Ingress Controller
Um dos Ingress Controllers mais utilizados, devido à sua simplicidade e performance, é o Nginx Ingress Controller. Ele disponibiliza um contador de requests na métrica nginx_ingress_controller_requests, que pode ser extremamente útil para monitorar o tráfego de entrada.
1
rate(nginx_ingress_controller_requests{ingress="chip", namespace="chip"}[1m])
JVM - Micrometer
Para aplicações Spring Boot, é comum o uso do Micrometer como biblioteca para criação e exposição de métricas no Actuator da aplicação. Uma métrica útil é requests_total, que contabiliza os requests recebidos pela JVM. Este contador pode fornecer insights valiosos sobre o volume de tráfego processado pela aplicação.
1
sum(rate(requests_total{app="chip", namespace="chip"}[1m]))
Baseado nessas queries do Prometheus, já temos onde começar a buscar a métrica que servirá como guia para efetuarmos o scale das aplicações.
Construindo o ScaledObject
Capacidade Mínima e Máxima
O primeiro passo na construção do nosso manifesto é definir a capacidade mínima necessária para o funcionamento da aplicação, independentemente do uso, e a capacidade máxima, limitada por fatores como custos e limites técnicos. Nas nossas premissas, estabelecemos o mínimo em 3 e o máximo em 200. Esses valores devem ser especificados nos campos .spec.minReplicaCount e .spec.maxReplicaCount.
Janelas de Estabilização
O stabilizationWindowSeconds no KEDA é um parâmetro crucial para configurar o comportamento do autoscaling, influenciando diretamente o HPA (Horizontal Pod Autoscaler) criado para cada ScaledObject. Esse parâmetro ajuda a estabilizar o processo de escalonamento, minimizando mudanças frequentes e abruptas na quantidade de réplicas, especialmente em resposta a variações breves ou picos na carga.
Esse parâmetro é vital para o ajuste fino do processo de escalonamento, seja usando KEDA ou HPA diretamente. O valor padrão é de 300 segundos (5 minutos), que pode oferecer uma estabilidade balanceada, mas também pode ser considerado lento para algumas aplicações.
É recomendável ajustar essa configuração cuidadosamente para se adequar ao cenário ideal da sua aplicação. Para esta PoC, projetei um ambiente que precisa responder rapidamente às mudanças de TPS, tanto para aumentar quanto para diminuir o número de réplicas com base no tráfego, por isso defini o valor para 60 segundos (1 minuto). Com isso, o KEDA poderá tomar decisões de escalonamento de forma mais ágil. Se o objetivo for escalar rapidamente para cima e lentamente para baixo, é possível configurar esses cenários separadamente dentro do horizontalPodAutoscalerConfig.
ScaledObject da Aplicação
No final dessas considerações, teremos um manifesto parecido com o abaixo, onde vamos observar a aplicação chip que vai variar entre 3 e 200 replicas, e tanto para scaleUp quando pra scaleDown vai obedecer uma janela de 60 segundos entre as ações.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: chip-high-tps
namespace: chip
spec:
scaleTargetRef:
name: chip
minReplicaCount: 3
maxReplicaCount: 200
pollingInterval: 10
cooldownPeriod: 30
advanced:
horizontalPodAutoscalerConfig:
behavior:
scaleDown:
stabilizationWindowSeconds: 60
scaleUp:
stabilizationWindowSeconds: 60
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-kube-prometheus-prometheus.prometheus.svc.cluster.local:9090
metricName: istio_requests_total
threshold: "10" # <---- Quantidade de requisições por pod. No exemplo, 10 TPS.
query: |
sum(rate(istio_requests_total{destination_service_name="chip"}[1m]))
Testes e Resultados
Para esta prova de conceito, utilizou-se a ferramenta Cassowary para a injeção de carga. O objetivo foi injetar cargas inconstantes durante períodos específicos de tempo, a fim de validar as stabilizationWindowSeconds curtas. Essa abordagem foi escolhida para demonstrar como o sistema escala de forma sensível às métricas de tráfego.
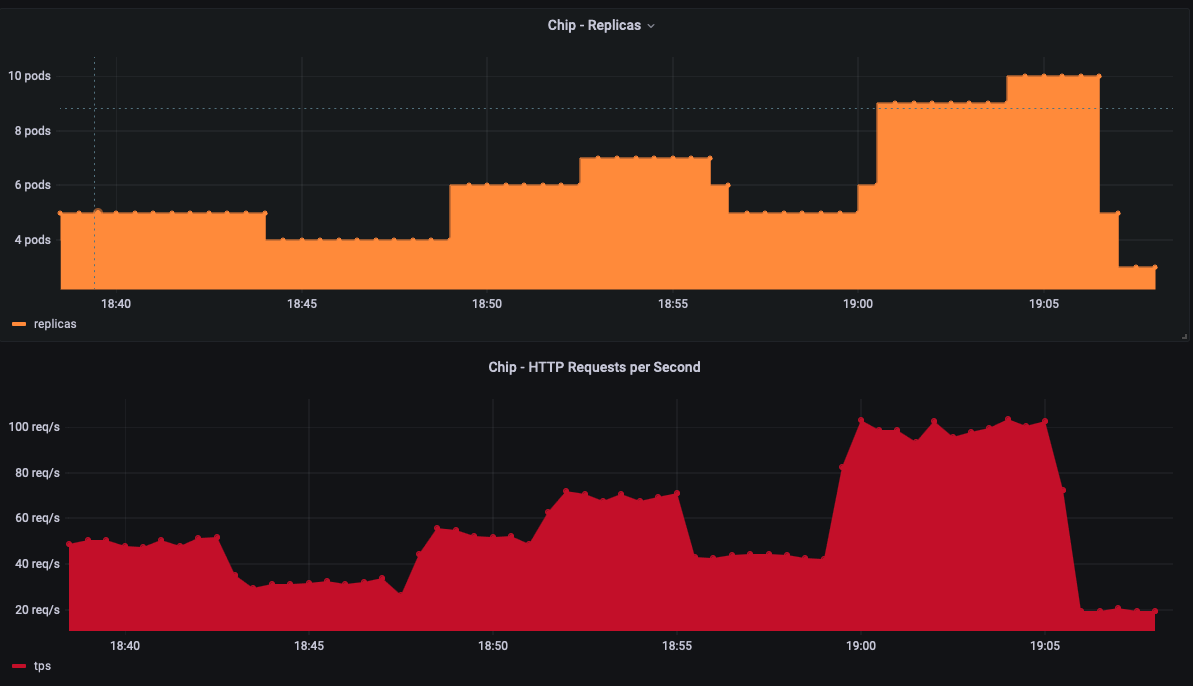
Esse é o primeiro artigo que publico nativamente aqui nesse blog. Espero ter ajudado! :)
Referencias e Recursos Adicionais
- Chip - Smart “dummy” mock for cloud native tests
- EKS with Istio - Terraform template for a production ready EKS Cluster and ISTIO Service Mesh
- Don’t combine ScaledObject with Horizontal Pod Autoscaler (HPA)
- Keda - Scaling Deployments - Advanced
- Keda - Scaling applications based on Prometheus
- Istio Standard Metrics
- Nginx Ingress Controller - User Guide/Monitoring
- Monitoring Spring Boot Applications with Prometheus
- Envoy integration for Grafana Cloud
- Kubernetes - Horizontal Pod Autoscaling
Me sigam no Twitter para acompanhar os demais materiais que eu compartilho por lá!
Te ajudei de alguma forma? Me pague um café (Mentira, todos os valores doados nessa chave são dobrados por mim e destinados a ongs de apoio e resgate animal)
Chave Pix: fe60fe92-ecba-4165-be5a-3dccf8a06bfc
