
System Design - Testes de Carga e Estresse

Testes de performance são processos extremamente importantes em sistemas de larga escala que precisem garantir o bom funcionamento de forma responsável. O objetivo desse texto complementar é ressaltar os tipos de teste e, principalmente, como elaborar um roteiro que faça sentido não só para o time técnico, mas que também gere insumos valiosos para o produto como um todo.
A importância dos testes de performance
Realizar testes de performance, embora muitas vezes não seja possível por uma quantidade significativa de fatores, deveria ser uma prática que acompanha o ciclo de vida de qualquer software produtivo, desde seus estágios de build até sua maturidade de voo. Eles são, talvez, a forma mais prática e científica de descobrir os limites do seu sistema e também garantir que o mesmo irá cumprir com os requisitos propostos.
Uma vez que os limites do software são conhecidos e impostos pelo produto, a tarefa dos testes de estresse, performance e carga busca dar uma garantia pragmática de que os requisitos-base de uso serão entregues e irão suprir as necessidades do cliente final. Dessa forma, na construção ou refatoração de um sistema, conseguimos oferecer alguns graus de garantia e expectativas de capacidade de curto, médio e longo prazo. Dizendo dessa forma, até parece complexo, burocrático e, de algumas formas, pedante. Mas, ao decorrer deste texto, meu objetivo é te mostrar como arquitetar testes de forma assertiva, dinâmica e facilmente adaptável para diferentes tipos de cenário. Buscando te guiar nos primeiros, segundos e terceiros passos de como direcionar testes de performance e, principalmente, como utilizá-los para elaborar e responder perguntas-chave sobre o seu produto.
A importância de conhecer comportamentos do sistema
Quando estamos projetando sistemas do zero, ou cuidando para que o mesmo tenha um ciclo de vida saudável a longo prazo, é importante existir documentadas todas as funcionalidades e lógicas do sistema. Nem sempre isso é possível e, em muitos casos, é tratado como “o mundo ideal” de muitos times de engenharia. Conhecer a jornada do seu cliente, como ele interage com o seu sistema, quando e com que frequência, tem um valor muito alto. Começar a tratar funcionalidades como comportamentos e jornadas pode nos levar a mapear quais serão os maiores gargalos sistêmicos e nos fazer encontrar inúmeras possibilidades de melhoria.
Quando estamos arquitetando um relatório gerencial de fechamento de caixa, entendemos que, por mais que seja uma tarefa intuitivamente custosa computacionalmente, presumimos também que a frequência com que o mesmo é gerado é baixa, e presumimos, por inferência, que os períodos pelos quais os mesmos serão gerados não irão variar muito dos últimos ou primeiros dias do mês.
Quando temos uma funcionalidade cuja função é registrar e concluir vendas de diversos produtos de um catálogo, podemos, da mesma forma, presumir que, embora esse estímulo seja muito mais frequente em termos de repetição, a demanda computacional não tende a ser um grande problema na maioria dos casos.
Isso quer dizer que, quando começamos a projetar um roteiro de testes, precisamos testar em escala a carga da funcionalidade de vendas e, em estresse, a função de relatórios. Não faz sentido, é claro, nesse caso em específico, testar uma grande volumetria de diversos relatórios contábeis sendo emitidos em paralelo. Assim como talvez não faça sentido testar como a performance de um sistema inteiro varia quando temos apenas uma venda sendo concluída.
Entender a jornada comum de um cliente do nosso sistema pode nos facilitar, e muito, a elaboração de um teste que vai nos permitir entender cientificamente como nosso sistema se comporta e varia em determinadas condições. Como, por exemplo, em uma jornada fictícia, podemos presumir que um cliente médio acessa a home do nosso e-commerce, procura pela categoria que lhe convém, realiza a busca por algum termo aleatório, acessa quatro ou cinco opções do catálogo, coloca uma ou duas no carrinho, volta para “namorar” mais um pouco de opções, retorna ao carrinho, tenta aplicar algum cupom, podendo ter sucesso ou falha; dependendo do sucesso, aplicamos um desconto; ele pode, proativamente, realizar ou reativamente o login ou cadastro, preencher os seus dados, caso não existam, apenas uma vez, efetuar o pagamento e, durante alguns dias, visitar o site para entender o status do produto.
Essa é uma jornada praticamente “comum” e intuitiva de um sistema de e-commerce, por exemplo. Aqui podemos tirar alguns insights de que, por mais que a busca e navegação tenham sido feitas em grande quantidade, o login foi feito uma única vez no processo. Mediante o cadastro que foi executado somente uma vez, o preenchimento dos dados também ocorre muito menos vezes do que as outras operações. A visita de consulta pode variar bastante em quantidade.
Nisso, podemos desenhar testes específicos para esse tipo de jornada, moldando as transações injetadas baseando-nos em comportamento. Entender isso pode ser uma chave interessante para projetar testes que agregam valor instantâneo para a engenharia.
Testes de Performance em Build e Run
Esse tipo de teste pode ser realizado em diversos estágios do ciclo de vida de um software. Para exemplificar, iremos separar em dois grandes marcos genéricos: na fase de Build, que corresponde à construção inicial e aos primeiros estágios do software em seu MVP ou pós-MVP, e no Run, onde constantemente revisitamos a capacidade atual e desejada para garantir que os requisitos não foram muito alterados ou deteriorados conforme a evolução do sistema. Os testes de performance na fase de Run ocorrem em ambientes mais realistas, como pré-produção ou até mesmo produção, em diversos casos, podendo ou não concorrer com o cliente final. O objetivo é fazer com que o sistema seja submetido a cenários que simulam cargas reais ou extremas. O objetivo de um teste agressivo, nesse sentido, é testar de maneira controlada sistemas que já existem e estão consolidados em determinados cenários para entender seus níveis de disponibilidade, resiliência e performance, impedindo que esses insumos cheguem de forma reativa ou em momentos de crise.
Testes de Carga e Estresse
A terminologia dos testes de carga pode ser bastante confusa para definir “o que serve para quê”, e até mesmo se há alguma diferença entre os termos. No entanto, essas diferenças existem e podem ser compreendidas em sua natureza, ajudando-nos a elaborar estratégias para diferentes tipos de cenários.
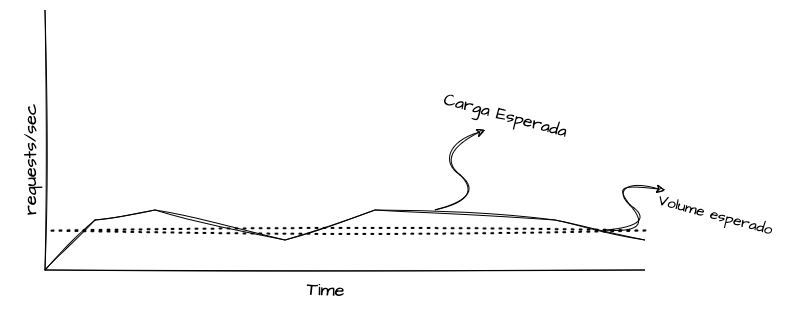
O objetivo de um teste de carga é avaliar como o sistema se comporta sob cargas reais e esperadas. Normalmente, esse teste serve para garantir que as estimativas e expectativas do produto sejam atendidas. Um teste de carga busca garantir as “baselines” que os times de engenharia recebem quando há alguma expectativa de onboarding de clientes, transações esperadas, contratos de disponibilidade, tempos de resposta, entre outros fatores.
Por exemplo, se um produto ou funcionalidade está sendo construído para suportar um cliente que necessita realizar 300 transações por segundo, com o tempo de resposta de cada transação abaixo de 400 ms, o teste de carga nos permite injetar a carga de tráfego esperada e verificar se o sistema está cumprindo esses requisitos. Se o sistema estiver sendo desenvolvido também levando em consideração o onboarding de novos clientes ao longo do tempo, ou se há uma estimativa de crescimento de X% em determinado período, os testes devem ser desenhados para garantir que o sistema acompanhe esse crescimento gradual. Assim, será possível identificar até que ponto o sistema atenderá aos processos esperados antes de atingir um limite que comprometa essas expectativas.
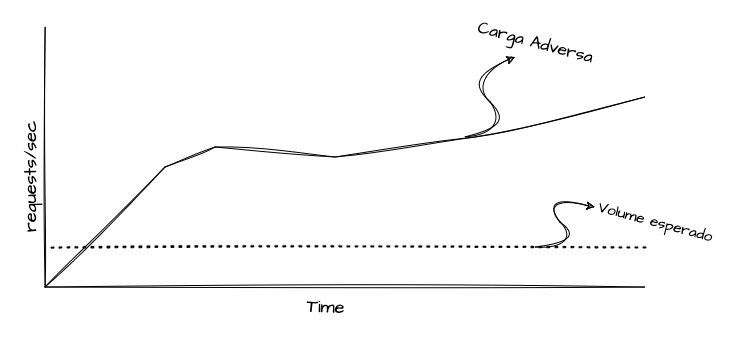
Por outro lado, um teste de estresse busca avaliar as mesmas dimensões, porém em condições adversas, como picos de acesso, cargas repentinas ou volumes muito maiores que o habitual por determinados períodos. O objetivo desse teste é encontrar gargalos e limitações do sistema sob condições não convencionais. É comum que, em um teste de estresse, seja aplicada uma carga muito superior à esperada, justamente para identificar esses gargalos e limitações.
Ambos os cenários nos ajudam a identificar gargalos de capacidade, oportunidades de otimização, realizar análises de recursos e simular o uso de dependências. A seguir, vamos abordar alguns tipos de testes que podem ser aplicados em ambos os cenários e que ajudam a responder perguntas específicas.
Tipos de Teste
O objetivo dessa sessão é especificar alguns dos principais tipos de teste e que tipo de pergunta eles visam responder quando aplicados.
Teste de Fumaça, Smoke Tests
Os testes de fumaça, ou smoke tests, são uma forma simplificada de injetar uma carga mínima e verificar as principais funcionalidades de um sistema sob uma ótica de tráfego básico. Normalmente, a baseline de um smoke test busca garantir o funcionamento mínimo necessário com uma carga minimamente aceitável. Esse tipo de cenário é comumente executado em pipelines de CI/CD, fazendo parte da cadeia de qualidade durante o processo de release de versões ou em automações periódicas aplicadas em ambientes produtivos ou pré-produtivos, para garantir a funcionalidade recorrente e gerar evidências de bom funcionamento.
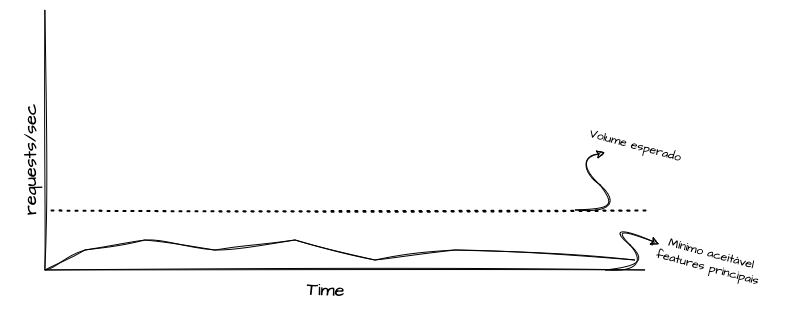
Esses testes são usados para validar se a aplicação está “pronta para ser testada” em cenários mais complexos e intensivos. Não é objetivo do smoke test realizar uma análise detalhada de desempenho, mas sim garantir que não há falhas críticas que impediriam o funcionamento básico da aplicação. Ele serve como uma verificação inicial de que as funcionalidades principais estão operando corretamente antes de seguir para testes mais aprofundados.
Teste de Average Load
O objetivo do Average Load é avaliar como o sistema se comporta sob a carga esperada por longos períodos, verificando se ele consegue manter a performance estabelecida. Ao contrário de testes que simulam cenários adversos ou básicos, o objetivo do average load test é garantir o bom funcionamento e o entendimento do sistema dentro dos limites esperados. Se o direcionamento do produto é, por exemplo, uma carga média hipotética de 400 transações por segundo, garantindo um tempo de resposta de até 200 ms, o teste visa injetar esse volume continuamente por períodos prolongados para avaliar se surgem outliers ou comportamentos inesperados que comprometam a execução uniforme da performance.
Os cenários ideais para a execução de Average Load são aqueles que duram dias ou semanas, permitindo um estudo aprofundado de todas as variações ocorridas durante esse período, a fim de identificar padrões e correlações. Testes desenhados nesse formato podem ser especialmente úteis para verificar a existência de problemas como memory leaks.
Testes de Estresse
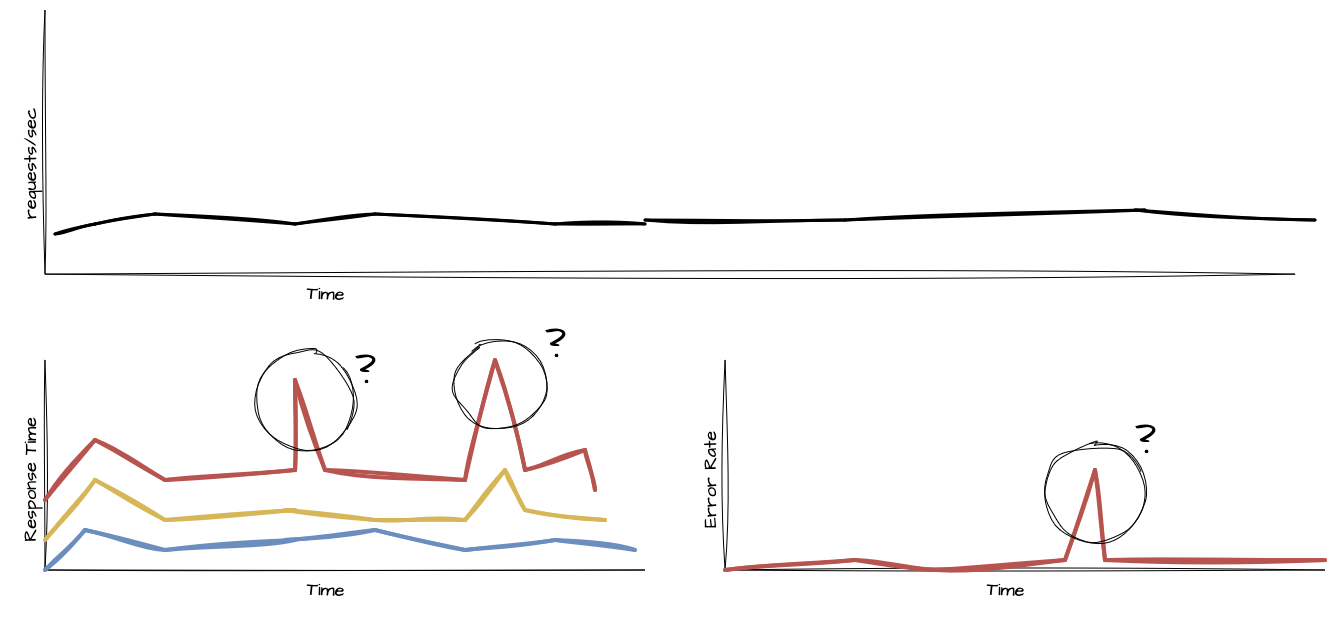
Os testes de estresse são amplamente conhecidos e, muitas vezes, utilizados de forma genérica para se referir a outros tipos de testes de performance. No entanto, o teste de estresse tem um objetivo claro: avaliar o comportamento de um sistema quando este é submetido a condições extremas, que excedem o fluxo normal esperado.
O principal objetivo desse teste é identificar gargalos, limites de capacidade e falhas de resiliência por meio da sobrecarga de uso. A aplicabilidade desse tipo de teste é relevante quando há a necessidade de descobrir como o sistema reage em cenários de sobrecarga, seja em eventos de alto tráfego, seja em picos inesperados de demanda.
Os indicadores comumente avaliados durante um teste de estresse incluem métricas de capacidade, como uso de CPU, memória, rede, I/O e o número de conexões no pool do sistema e de suas dependências. Esses fatores são analisados em conjunto para determinar o ponto de saturação do sistema.
As lições aprendidas com esse tipo de teste são valiosas para identificar, de forma proativa, pontos de falha e oportunidades de melhoria, evitando que esses problemas sejam descobertos apenas em cenários reais, já impactando o cliente final. Além disso, os insights obtidos podem ajudar as equipes de engenharia a identificar quais partes do sistema continuam operando durante falhas graves e se isso é mais benéfico ou prejudicial para a recuperação completa do sistema.
Testes de Spike
Os testes de spike podem ser considerados tanto uma variação quanto um complemento dos testes de estresse. O objetivo desse teste é simular picos repentinos de uso e fornecer dados sobre como o sistema se comporta diante desse cenário. Um teste de spike pode ser programado para ser executado durante um teste de estresse ou de breakpoint convencional, que normalmente aumenta a carga de maneira progressiva. No entanto, o teste de spike é focado em avaliar uma progressão súbita de uso, seguida de uma redução rápida.
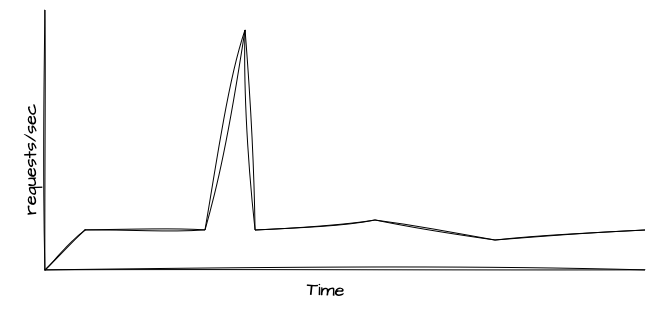
Esse tipo de teste é utilizado para validar a estabilidade do sistema e identificar possíveis degradações momentâneas de desempenho. Ele é especialmente valioso para sistemas que, de fato, experimentam aumentos repentinos e imprevisíveis de uso por parte de seus clientes.
As lições aprendidas a partir desse teste fornecem informações sobre como a arquitetura do sistema pode ser ajustada para absorver esses aumentos repentinos de tráfego sem a necessidade de superdimensionar sua capacidade e infraestrutura. O foco é otimizar o uso dos recursos, garantindo que o sistema possa lidar eficientemente com picos inesperados sem comprometimento significativo de desempenho.
Testes de Breakpoint
Os testes de breakpoint são utilizados para avaliar como o sistema se comporta sob tráfego progressivo por longos períodos, com o objetivo de encontrar o ponto limite de quebra. Esses testes são projetados para identificar o momento exato em que o sistema começa a falhar à medida que a carga aumenta, detectando quando ocorrem degradações no tempo de resposta, aumento na taxa de erros e falhas críticas nos componentes.
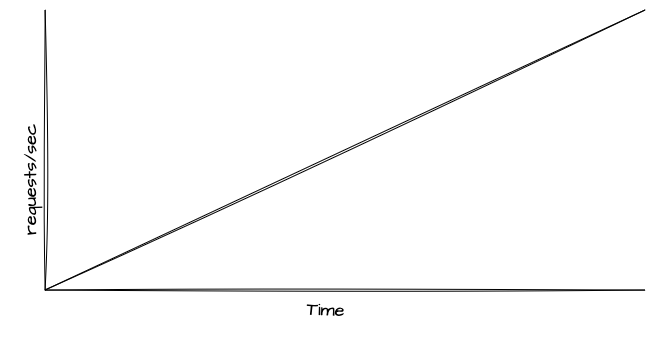
A execução desse tipo de teste deve ser feita de maneira muito mais controlada do que outros tipos de testes, pois o objetivo aqui não é validar a performance ou capacidade para cenários específicos, mas sim levar o sistema até o seu limite real.
Durante o teste de breakpoint, várias métricas precisam ser avaliadas, como a saturação de recursos, incluindo CPU, memória, latência, I/O, disco, rede, taxa de erros do serviço e de todas as suas dependências. Isso permite identificar quais componentes falham primeiro e como a cascata de falhas acontece, facilitando a compreensão dos pontos fracos e das limitações do sistema. Aqui, normalmente, são analisadas as limitações das políticas atuais de escalabilidade horizontal.
Respondendo a Perguntas Chave
O objetivo de um teste de performance ou estresse é responder perguntas específicas sobre o sistema avaliado. Isso significa que apenas injetar carga, sem antes definir que tipo de respostas se quer obter com o teste, não é a estratégia mais eficiente, nem em termos de esforço, nem de resultado. Quando planejamos um teste, ele precisa ser executado em condições que nos permitam compreender detalhadamente, ou estimar, por inferência, as capacidades do sistema ou de suas funcionalidades isoladas. Simplesmente simular carga por simular pode gerar resultados dispersos e de pouco valor para o produto.
Portanto, por mais que a fase de planejamento seja mais demorada em comparação à execução do teste, é essencial alinhar as expectativas e definir objetivos claros. Dessa forma, os resultados obtidos podem realmente auxiliar os times de negócio e engenharia na tomada de decisões técnicas e na definição de prioridades.
Qual é o trafego esperado do meu sistema hoje?
Quantos usuários simultâneos o sistema suporta atualmente? Quantas transações por segundo são processadas em média? O volume de tráfego tem picos em horários específicos? Estas são as primeiras perguntas que devem ser respondidas ao iniciar o planejamento de um teste eficiente, visando estabelecer dados sobre o ciclo de vida completo do produto. Esses pontos são facilmente respondidos em casos em que o sistema já está em operação e conta com mecanismos de observabilidade, que monitoram regularmente o desempenho e fornecem métricas valiosas sobre o comportamento do sistema.
Se o teste estiver sendo proposto para um sistema novo, é importante que essas informações sejam fornecidas pelo time de produto, com base nos acordos estabelecidos com o cliente, seja ele interno ou externo. Esse processo garante que, caso o volume de tráfego ainda não seja conhecido, ele seja pesquisado e comunicado a todos os stakeholders envolvidos no desenvolvimento e na operação do sistema.
Quais são meus objetivos de tempo de resposta, taxa de erros e saturação?
Sabendo o volume de uso do sistema, o próximo passo é determinar quais são os limites aceitáveis de erros nos fluxos e o tempo de resposta considerado ideal. Esse processo pode ser medido por jornadas ou ações específicas, ao invés de tratar o sistema como uma “caixa preta”, onde toda a experiência é considerada em uma única média. Diferentes tipos de ações dentro de um produto geralmente possuem pesos e níveis de complexidade variados. Portanto, mapear essas jornadas é uma abordagem interessante se o objetivo for granularizar os resultados dos testes de performance.
Se todas as jornadas estiverem mapeadas, pode ser valioso realizar testes de performance que simulem comportamentos heterogêneos, com vários usuários executando ações completamente diferentes no sistema. Isso cria um cenário mais próximo do real e permite uma avaliação mais precisa do desempenho. No entanto, para que esses testes sejam realmente válidos no contexto do produto, os limites aceitáveis de erros e tempos de resposta precisem ser conhecidos. Dessa forma, será possível avaliar se o sistema está atingindo ou não os objetivos propostos.
Qual é o trafego esperado do meu sistema em períodos de pico?
Depois de estabelecermos os baselines, é fundamental entender as variações esperadas ou estimadas no uso do sistema. Os sistemas normalmente têm fluxos de uso previsíveis, mas não uniformes. Por exemplo, um sistema de delivery de comida pode ter um uso constante ao longo do dia, com picos próximos aos horários de almoço e jantar.
É importante compreender como esses picos se comportam e como podem influenciar a experiência total do cliente. Esse tipo de dado é extremamente valioso e deve ser utilizado para testes de spike ou estresse, que podem ser configurados para simular capacidades variáveis ou progressivas, sempre refletindo os momentos de maior demanda ou “vales de acesso” no sistema.
Quais os protocolos e estímulos que minha aplicação é exposta?
Agora que definimos os objetivos de uso e os limites aceitáveis de experiência, é necessário aprofundar o nível arquitetural e identificar quais tipos de protocolo a aplicação utiliza. Esse mapeamento é essencial para selecionar as ferramentas e os processos ideais para os testes de performance.
Minha aplicação utiliza protocolos síncronos como HTTP, gRPC ou WebSockets? Ou está exposta a estímulos assíncronos, como o consumo e a produção de mensagens através de AMQP, Kafka, Polling ou MQTT? O ideal é mapear todos os principais protocolos transacionais para garantir que os testes simulem corretamente o comportamento real do sistema, replicando as mesmas vias de comunicação que os clientes utilizam no fluxo normal.
Qual é a expectativa de crescimento do meu sistema?
Depois de responder às necessidades atuais do sistema, ou de um período específico, é importante projetar os testes de carga considerando o crescimento natural. Isso ajuda a responder à pergunta: “Até quando minha capacidade atual será suficiente, e quando precisarei revisitá-la de forma proativa?”. Essa abordagem, quando alinhada com as expectativas do produto, é extremamente eficaz para projetar sistemas que cresçam de maneira saudável a longo prazo.
É extremamente importante manter uma comunicação clara entre os times de produto e engenharia sobre planos de expansão, metas de vendas e expectativas de onboarding de novos clientes. Esse alinhamento permite que os testes de performance sejam realizados com base em projeções reais, garantindo que o sistema esteja preparado para atender à demanda futura sem falhas ou degradação de desempenho.
Qual é o cenário mais extremo que o sistema enfrentará?
Mesmo compreendendo o comportamento natural do sistema, seus períodos de uso regular, baixa utilização e picos de carga, ainda é necessário considerar como ele se comportaria em cenários ainda mais extremos. Isso é especialmente importante em momentos como períodos de promoção, Black Friday, Natal e até mesmo em situações inesperadas que queremos antecipar. Conhecer ou estimar esses cenários extremos é uma das etapas mais críticas — e também mais interessantes — durante o planejamento de testes de performance.
Geralmente, é nesse estágio que encontramos os principais gargalos e pontos de melhoria do sistema, já que os limites são estressados até condições além do normal. Estimar esses cenários não apenas ajuda a encontrar pontos de melhoria de resiliência e escalabilidade, mas também nos ensina a como preparar o sistema para lidar com condições de tráfego incomuns.
Quais são as funcionalidades principais que precisam ser testadas?
Quais são as partes mais críticas da aplicação, como busca, detalhes de itens, carrinho, checkout, pagamento e consulta de dados cadastrais, que precisam de maior atenção? Há funcionalidades que impactam diretamente o core do sistema e que devem ser testadas sob maior carga? Se sim, pode ser interessante desenvolver testes isolados e direcionados para esses cenários antes de testar uma jornada completa. Priorizar funcionalidades específicas pode ser muito valioso, especialmente quando o funcionamento de partes específicas é alterado. Isso ajuda a identificar se alguma mudança introduziu comportamentos prejudiciais ou se trouxe melhorias significativas em termos de desempenho. Focar em testes direcionados para essas partes críticas ajuda a garantir que as áreas mais sensíveis do sistema estejam funcionando de forma eficiente, mesmo sob alta demanda.
Quais são as jornadas comuns do usuário?
Talvez uma das melhores formas de se formular testes de carga e estresse seja simular jornadas completas do usuário dentro do sistema, refletindo a experiência real. Por exemplo, considere um usuário em um e-commerce fictício. Em uma jornada convencional, o usuário segue o “fluxo feliz”, onde acessa a página inicial, faz login, realiza buscas de vários termos no sistema de pesquisa, adiciona itens ao carrinho, remove outros, inicia o checkout e finaliza o pagamento, entre outras ações. Dessa forma, podemos racionalizar o número de interações de maneira mais realista, simulando as funcionalidades do sistema em condições próximas ao uso real.
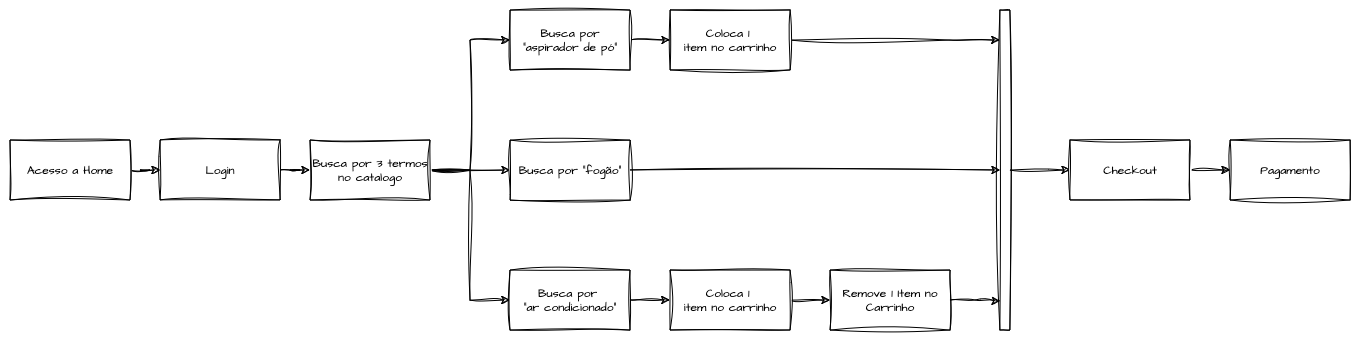
Em um cenário com características mais assíncronas, como um sistema de pagamentos reativo estimulado por clientes internos com ações de cobrança e estorno, podemos aplicar a mesma lógica. Se sabemos que 50% das solicitações são cobranças por cartão, 30% por pagamento instantâneo, 15% por boleto e 5% por estorno, podemos criar mecanismos de teste que estimulem o sistema com essas mesmas porcentagens de uso, garantindo que ele reflita o comportamento real dos usuários e clientes.
Quais os endpoints mais utilizados? E quais os mais caros?
Mapear as jornadas de uso do sistema também tem como objetivo identificar quais funcionalidades são mais utilizadas em comparação com outras. Usando o exemplo anterior, podemos entender que a pesquisa no site é realizada muito mais vezes do que o checkout. Intuitivamente, o cliente pode procurar por várias categorias, navegar por diversos produtos, adicionar itens ao carrinho e iniciar o processo de pagamento apenas uma vez. Além disso, é possível presumir que uma ação de pagamento é computacionalmente mais custosa do que uma pesquisa, desde que ambas estejam otimizadas corretamente. Esse tipo de conhecimento é fundamental para determinar como e quando testar cada funcionalidade do sistema da melhor forma, priorizando aquelas que são mais utilizadas e, ao mesmo tempo, mais onerosas em termos de processamento. Com isso, podemos garantir que o sistema seja robusto e eficiente, mesmo nas operações mais críticas.
Métricas em Testes de Performance
Já discutimos “o que observar” durante a execução dos testes de performance. Agora, vamos recapitular esses pontos, mas sugerindo uma abordagem para aproveitar ao máximo a movimentação gerada pelos testes. É possível criar dashboards, configurar alertas, gerar logs e correlacionar todas essas informações por meio de um único painel de controle, numa abordagem de “Single Pane of Glass”. Essa estratégia visa fornecer uma observabilidade centralizada, onde múltiplos recursos pertencentes à mesma jornada podem ser monitorados em uma ordem lógica. Esse padrão facilita o acompanhamento de recursos, dimensões e aplicações que são afetadas durante o teste e também serve como suporte contínuo para o monitoramento da saúde do produto em operação. A ideia é usar grandes iniciativas, como a criação de testes de performance, para resolver múltiplos problemas de uma vez. Essa estratégia permite otimizar o monitoramento do produto de forma proativa e integrada, gerando valor tanto para a fase de testes quanto para a operação diária do sistema.
Service Levels como objetivos esperados
Como saber se eu “passei no teste”? Uma oportunidade adicional é transformar toda essa pesquisa corporativa e multidisciplinar, feita para descobrir os requisitos e objetivos, em Service Levels oficiais do processo. Isso oferece uma estrela guia para que os times de engenharia, negócios e arquitetura trabalhem com foco e atenção às nuances críticas.
Se, durante o teste, foi determinado que a disponibilidade do checkout deve ser sempre superior a 99,99% e que a conclusão de uma compra não deve ultrapassar 3 segundos, temos a oportunidade perfeita para adotar essas métricas como os SLAs padrão do sistema. Esses parâmetros fornecem uma direção clara para que todos os envolvidos monitorem a saúde dessa funcionalidade no dia a dia. Além disso, a definição de SLAs também permite criar alertas proativos para que a operação seja notificada antes mesmo da quebra do contrato, garantindo que medidas corretivas sejam tomadas rapidamente e minimizando impactos aos usuários.
Estratégias de pré-teste
Antes de realizar um teste por completo, pode ser interessante avaliar a capacidade da aplicação de forma individual e isolada. Isso ajuda a dar insumos iniciais de como o teste irá se comportar e o que esperar. Podemos testar um fluxo completo individualmente antes de iniciar um teste de jornada para maior segurança. Vamos explorar algumas condições que podem ser valiosas como um exercício pré-teste.
Avaliando a capacidade individual de cada réplica
O objetivo da validação de capacidade de unidade é determinar quanto uma única réplica da sua aplicação consegue suportar em termos de carga. Esse teste deve ser feito antes de escalar o número de réplicas, para garantir que a aplicação tenha um comportamento previsível em cenários de múltiplas instâncias e também servir como insumo de como definir e validar políticas de autoscaling.
Comece executando sua aplicação com apenas uma réplica e aplique uma carga incremental a fim de encontrar até quando uma única réplica consegue sustentar tráfego sem comprometer o tempo de resposta e erros. A simulação presume executar as requisições, eventos e mensagens que o sistema normalmente processaria. O objetivo aqui é descobrir os limites de uma única instância em termos de capacidade de processamento, uso de CPU, memória e outros recursos perante aos acordos de disponibilidade.
Em um objetivo em que se deve ter 99% de disponibilidade, respondendo às requisições em até 200 ms, injetamos carga em uma réplica até que esses limites sejam ofendidos. Em um resultado hipotético, caso a réplica da aplicação consiga atender até 10 transações por segundo como limite máximo sem quebrar os SLA’s, adicionamos mais uma réplica e reaplicamos o teste, tentando chegar até 20 transações por segundo. Se isso se comprovar real, podemos adicionar mais uma réplica e tentar mais uma vez até chegar a 30 transações por segundo. Fazemos isso algumas vezes até chegarmos à prova real de que o limite de cada réplica, a nível computacional, seria de 10 transações cada.
O objetivo desse teste pode ser realizado até encontrarmos um limite onde o poder computacional deixa de ser o principal gargalo e passa para uma próxima dependência.
Validação de unidade assíncrona
Em cenários assíncronos que processam eventos ou mensagens, podemos explorar um passo adicional nesse pré-teste, ainda de forma unitária. O objetivo é verificar como uma única réplica da aplicação consome e processa as mensagens e qual a vazão de processamento das mesmas, mas também assegurando que elas não ultrapassem seus limites de capacidade.
Começamos represando um número muito grande de mensagens ou eventos nas filas ou tópicos da aplicação. Iniciamos uma única réplica e verificamos o throughput de processamento e como ela lida sozinha com um número muito grande de eventos. O foco é observar se a aplicação sabe gerenciar a carga e evitar sobrecarga sobre si mesma, evitando que a mesma consuma mais mensagens do que consiga realmente processar e acabe elevando seus níveis de memória, CPU, throughput e até mesmo acarretando a morte do processo. Em termos simplistas, em um lag muito alto, a aplicação deve consumir apenas a vazão programada sem morrer.
Ferramental para Testes
A seguir, vamos explorar um pouco do ferramental de testes de performance e estresse. Vamos abordar, pontualmente, as opções mais famosas atualmente.
Grafana K6
O Grafana K6 é uma ferramenta simples e intuitiva de teste de carga e performance, voltada especialmente para reduzir a carga cognitiva de desenvolvedores. Ela é projetada para testar aplicações inerentes ao protocolo HTTP. Escrito em Go, ele permite que usuários simulem diversos cenários de conexões simultâneas utilizando protocolos como HTTP, WebSocket e gRPC. O K6 é amplamente utilizado em pipelines de CI/CD devido à sua fácil integração. Ele também oferece uma integração nativa com Grafana, facilitando a criação de dashboards para monitoramento em tempo real das métricas de performance, e seus testes são escritos em JavaScript.
Locust
O Locust é uma ferramenta usada para testar a performance e a escalabilidade de aplicações web, tendo a facilidade de simular o comportamento de vários usuários virtuais. Escrito em Python, ele permite que você defina cenários de teste para protocolos como HTTP, HTTPS e WebSocket.
Apache JMeter
O Apache JMeter é uma das ferramentas mais conhecidas e amplamente usadas para testes de carga, performance e estresse. Ele suporta uma ampla variedade de protocolos, como HTTP, JDBC, SOAP, REST, gRPC, TCP e até serviços de mensagens como MQTT. O JMeter permite simular diferentes tipos de tráfego e transações, sendo ideal para testar aplicações web, APIs e até sistemas distribuídos. A flexibilidade da ferramenta e sua extensa gama de protocolos tornam o JMeter um dos mais utilizados, principalmente por dar suporte a roteiros complexos.
Gatling
O Gatling é uma ferramenta poderosa de testes de carga, escrita em Scala, e projetada para testar sistemas distribuídos e aplicações de alta performance. O Gatling oferece suporte nativo a protocolos como HTTP, WebSocket, JMS, Kafka e gRPC. Ele é amplamente utilizado para testar a escalabilidade e a resiliência de diversos tipos de sistemas e permite a criação de cenários de teste detalhados e complexos, com relatórios avançados sobre o desempenho do sistema durante o teste.
Oha / Ohayou
Oha, também conhecido como Ohayou, é uma ferramenta simples e leve para testes de performance de APIs e serviços web. Focada em simplicidade e velocidade, o Oha utiliza principalmente os protocolos HTTP e HTTPS para simular requisições de usuários em alta velocidade, medindo o desempenho de APIs com relatórios de latência, throughput e erros. Sua leveza e interface minimalista o tornam uma escolha prática para quem deseja realizar testes rápidos e diretos, sem muita complexidade.
Modelo de Roteiro de Teste
Aqui vamos tentar compilar os principais tópicos apresentados a fim de montar um documento inicial e extensível para diversos tipos de cenário. A proposta é ser intuitivo o suficiente para que você seja capaz de entender a proposta e modificá-la para atender as necessidades da sua empresa ou produto.
Relatório de Teste de Performance - Produto de Cobrança de Vendas - Time de Engenharia
1. Visão Geral
Data: DD/MM/AAAA
Aplicação / Jornada: Checkout de Cartão de Crédito
Versão: 1.x.x
Ambiente de Teste: Produção / Pré-produção / Desenvolvimento
Ferramentas Utilizadas: Apache JMeter, Grafana K6, Locust, etc.
2. Objetivos do Teste
Finalidade: Avaliar o novo microsserviço de checkout para garantir os SLA’s de produto e encontrar oportunidades de melhoria de gargalos.
Metas:
- Tempo de Resposta: Manter um tempo de resposta abaixo de 800 ms para 95% das requisições.
- Throughput: Garantir que o sistema processe ao menos 600 transações por segundo (TPS) com 800 usuários ativos.
- Taxa de Erros: Taxa de erro inferior a 0.1% em condições normais e de pico.
- Escalabilidade: Verificar as políticas de autoscaling para garantir a capacidade transacional de escalar horizontalmente sem degradação total ou parcial.
3. Cenários de Teste
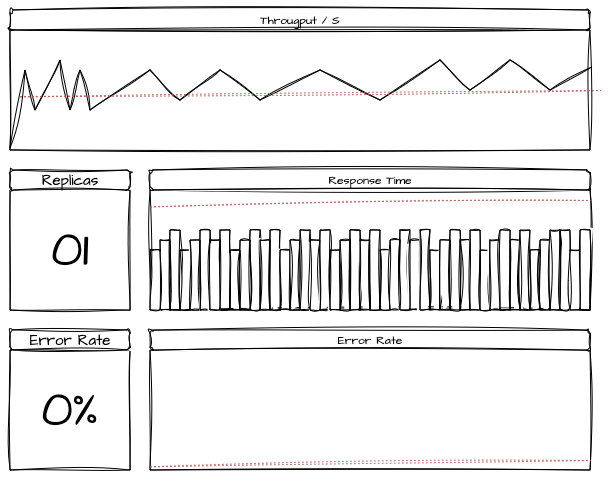
3.0. Pré-teste
- Objetivo: Testar a capacidade de uma única réplica da aplicação de checkout.
- Carga Simulada: 100 requisições/s para 1 réplica
- Protocolos Testados: HTTP
- Duração do Teste: 10 minutos
Expectativas:
- A réplica deve suportar o tráfego sem degradação.
- Recursos como CPU e Memória devem ser utilizados dentro dos limites de 80%.
Resultados:
- CPU: 75% de utilização
- Memória: 60% de utilização
- Tempo de Resposta: 300ms
- Taxa de Erros: 0%
- Observações: O sistema conseguiu suportar a carga sem degradação, mantendo o uso de recursos dentro dos limites.
Evidências:
3.1. Cenário 1: Carga Média (Average Load)
- Objetivo: Avaliar o comportamento do sistema sob condições de carga média constante.
- Carga Simulada: 500 usuários simultâneos
- Protocolos Testados: HTTP e Kafka
- Duração do Teste: 4 horas
Expectativas:
- Tempo de resposta médio < 300 ms
- Tempo de resposta p95 < 800 ms
- Taxa de erro <= 0.1%
Resultados:
- Tempo de resposta médio: 250 ms
- Tempo de resposta do p95: 600 ms
- Taxa de erro: 0.0%
- Observações: O sistema se manteve dentro dos parâmetros esperados, sem sinais de sobrecarga durante todo o tempo proposto.
Evidências:
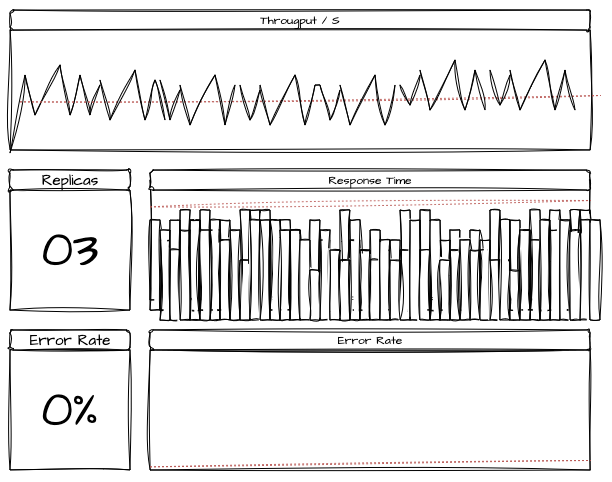
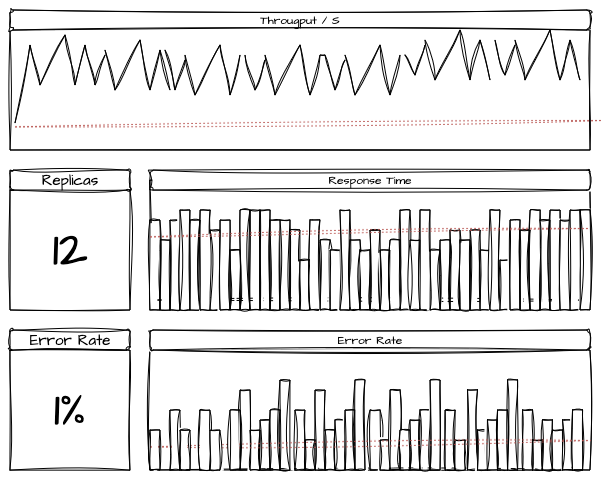
3.2. Cenário 2: Carga de Pico (Spike Test)
- Objetivo: Simular os picos de tráfego dos principais horários de compra para identificar como o sistema reage aos aumentos repentinos.
- Carga Simulada: 2000 usuários simultâneos (pico) por 15 minutos
- Protocolos Testados: HTTP e Kafka
- Duração do Teste: 2 testes de 15 minutos
Expectativas:
- Tempo de resposta médio < 400 ms
- Tempo de resposta p95 < 800 ms
- Taxa de erro <= 0.1%
Resultados:
- Tempo de resposta médio: 400 ms
- Tempo de resposta do p95: 700 ms
- Taxa de erro: 0.1%
- Observações: O sistema se aproximou do limite superior do tempo de resposta. Pequena degradação observada nos componentes de checkout e microsserviços de comunicação com o parceiro.
Evidências:
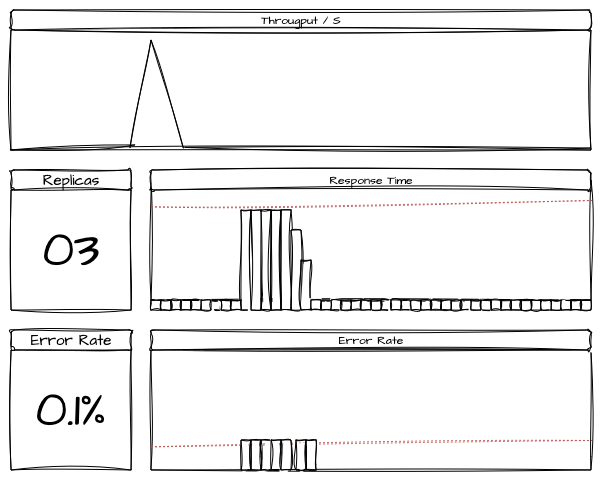
3.3. Cenário 3: Stress Test
- Objetivo: Simular um tráfego de estresse no sistema com carga acima do previsto.
- Carga Simulada: 2000 usuários simultâneos (pico) por 1 hora
- Protocolos Testados: HTTP e Kafka
- Duração do Teste: 1 hora com aumento de 500 usuários a cada 15 minutos.
Expectativas:
- Tempo de resposta médio < 400 ms
- Tempo de resposta p95 < 800 ms
- Taxa de erro <= 0.1%
Resultados:
- Tempo de resposta médio: 500 ms
- Tempo de resposta do p95: 1300 ms
- Taxa de erro: 1%
- Observações: O sistema ofendeu aos limites estabelecidos pelo produto em torno de 1500 usuários. Identificamos a oportunidade de otimização de 2 queries no banco de dados do serviço de checkout que validam a idempotencia da transação e manipulam o estado de conclusão do pagamento. Após análises junto ao time de DBA’s podemos superar esse problema criando um índice novo.
Evidências:
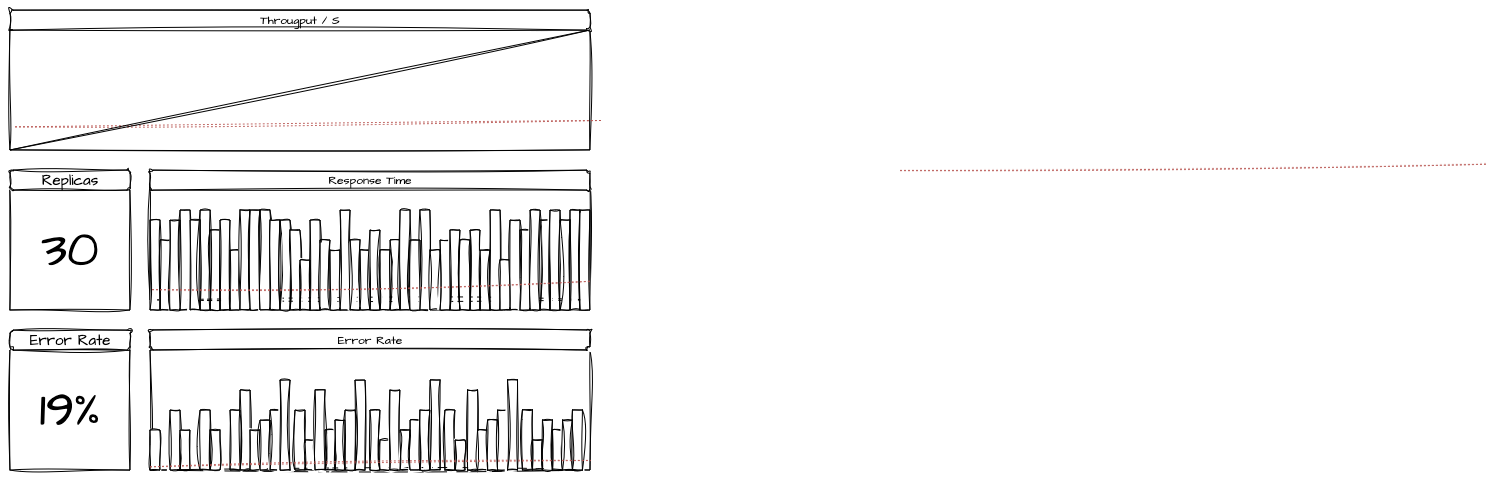
3.4. Cenário 4: Breakpoint
- Objetivo: Encontrar em que momento de uso os limites estabelecidos começam a ser ofendidos e em que momentos as falhas começam a afetar o funcionamento a níveis críticos
- Carga Simulada: de 0 até 10000 usuários simultâneos até um limite de 24 horas.
- Protocolos Testados: HTTP e Kafka
- Duração do Teste: limite de 24 horas com aumento incremental de 10 usuários por minuto
Resultados:
- Após 1300 usuários ativos, os tempos de resposta da aplicação começaram a subir e atingir o p95 de 800ms.
- Após 1600 usuários ativos, os tempos de resposta da aplicação começaram a subir e atingir o p95 de 1500ms com 5% de taxa de erro.
- Após 3000 usuários, os erros por timeout começaram a se tornar constantes, chegando até 10% de todo o tráfego. O p95 chegou até 30 segundos.
- Encontramos o limite de 3700 usuários. As aplicações começaram a falhar em cascata e os databases a travarem. Evidências:
Referências
Breakpoint testing: A beginner’s guide
How to do Load Testing? [A FULL GUIDE]
Teste de Desempenho vs. Teste de Estresse vs. Teste de Carga
