
System Design - Observabilidade e Monitoramento

Após elaborarmos diversos tópicos como Performance, Capacidade e Escalabilidade, Métricas de Continuidade de Negócio e diversos outros assuntos relacionados, este capítulo tem o objetivo de fazer um “recap” de alguns conceitos de forma simplificada, trazendo o ponto de vista final de Observabilidade, Monitoramento e Confiabilidade. Nele, vamos conceituar algumas pontas soltas referentes a Logs, Métricas, Traces, Alerting e APM, e principalmente como utilizar a simplicidade de diversos frameworks de mercado, como USE, RED e os Four Golden Signals, alinhados ao negócio para encontrar métricas comuns, de fácil entendimento e, principalmente, alinhadas entre times técnicos e de negócio.
Aqui, vamos elucidar principalmente como os temas de Observabilidade, Monitoramento e Confiabilidade se correlacionam e se complementam entre si. Vamos entender cada um dos pilares da observabilidade e qual tipo de entendimento estratégico precisamos ter sobre cada um deles.
Definindo Confiabilidade
Confiabilidade é a propriedade de um sistema entregar comportamento correto ao longo do tempo, sob condições esperadas e sob uma fração representativa de condições adversas. Confiabilidade vai muito além de uma aplicação “ficar de pé” e não é sinônimo direto de “alta disponibilidade”. Um sistema pode estar tecnicamente disponível e, ainda assim, ser pouco confiável se responde com dados errados, se degrada de forma caótica, se apresenta latência imprevisível ou se não consegue manter invariantes essenciais do domínio quando pressionado.
Confiabilidade, portanto, agrega os conceitos de continuidade de serviço, integridade e previsibilidade em termos operacionais.
A utilidade dessa definição é que ela coloca confiabilidade no lugar certo: como uma restrição arquitetural e um contrato operacional, e não como um “atributo desejável”. A partir daqui, todos os termos que serão abordados neste capítulo, como SLIs/SLOs, error budget, Four Golden Signals, RED e USE, e demais estratégias abordadas em outros capítulos, como estratégias de redundância, padrões de resiliência e práticas de incident response, passam a ser consequência de um objetivo: reduzir a probabilidade e o impacto de comportamentos incorretos, reduzir o tempo para detectar e recuperar e limitar o blast radius quando algo inevitavelmente falhar.
A confiabilidade, então, é um conjunto de práticas e disciplinas da engenharia e arquitetura de software que busca atingir níveis cada vez maiores e auditáveis de continuidade operacional.
Observabilidade
Observabilidade é a capacidade de inferir o estado interno de um sistema a partir de suas saídas externas. O termo tem origem na Teoria de Controle, da década de 1960, introduzida academicamente por Rudolf E. Kalman, por meio de publicações sobre a teoria de sistemas lineares.
A Teoria do Controle é um ramo da engenharia e da matemática que estuda como modelar, analisar e regular o comportamento de sistemas dinâmicos para projetar sistemas complexos que se comportem de maneira estável ao longo do tempo, mesmo diante de perturbações externas ocasionais. Na teoria, um sistema é dito observável caso exista a capacidade de inferir o estado interno de um sistema apenas por suas saídas externas.
A observabilidade em sistemas de software depende de saídas, registros e métricas de desempenho para cumprir esse papel. Trata-se da capacidade de compreender o estado interno de um sistema complexo a partir dos eventos e sinais externos que ele emite.
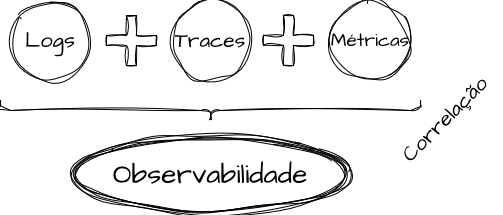
Esses eventos e sinais podem ser traduzidos, inicialmente, nos três pilares da observabilidade: logs, traces e métricas. O objetivo é entender comportamento, padrões e construir estruturas que sejam “interrogáveis” por meio de padrões e dimensões conhecidas e não conhecidas. Podemos presumir que: uma vez que conseguimos correlacionar logs, traces e métricas para elaborar questionamentos complexos sobre o sistema, temos observabilidade. E, ainda mais, se podemos utilizar logs, traces e métricas para conduzir análises exploratórias, temos observabilidade.
Por mais que seja altamente dependente, a observabilidade é uma propriedade estrutural de um sistema, e não um conjunto de ferramentas. É altamente possível que empresas, produtos e estruturas inteiras disponham de ferramentas altamente complexas e caras e, mesmo assim, não possuam observabilidade em essência.
À medida que nosso ferramental é utilizado para interpretar comportamentos, e podemos utilizá-lo, técnica e culturalmente, para entender comportamentos e padrões ocultos de forma histórica, temos observabilidade.
Monitoramento e Observabilidade
O monitoramento e a observabilidade são conceitos que caminham juntos, de forma tão tênue que normalmente são confundidos e referenciados como se fossem a mesma coisa. Entender a diferença entre os dois pode ser de grande ajuda para elevar o nível de confiabilidade nos sistemas. Os dois conceitos não são excludentes, mas complementares em essência.
Monitoramento é a capacidade de coleta e análise de métricas pré-definidas, de contextos já vividos, para verificar o estado de um sistema a partir de dimensões já conhecidas. O monitoramento nos dá a capacidade de monitorar, verificar e alertar quando algo conhecido dá errado, como, por exemplo, aumento de erros em APIs específicas, saturação de recursos, locks em um banco de dados, aumentos no tempo de resposta, etc.
O monitoramento se desenvolve normalmente por meio de medidas quantitativas, como, por exemplo, porcentagem de uso de CPU, latência de rede, quantidade de dados de entrada e saída de rede, taxas de erro, espaço em disco, etc., e, com base nisso, permite configurar thresholds para disparar alertas quando algo sai de um padrão estabelecido.
Observabilidade, por outro lado, é a capacidade de investigar fenômenos desconhecidos por meio da exploração de dados contextuais mais amplos e entender o “porquê” de algo inesperado ter acontecido. Deixamos de observar um estado determinístico, como “minha API está lenta”, e expandimos isso para “por que essa API está lenta agora?”, analisando todos os sinais de forma correlacionada para compreender o comportamento.
Resumindo, o monitoramento está diretamente ligado a identificar e alertar sobre problemas conhecidos, enquanto a observabilidade está ligada ao comportamento. Uma vez que sua observabilidade possibilita encontrar padrões e investigar problemas não óbvios, essas novas dimensões descobertas podem ser utilizadas como insumos para gerar monitoramento. Observabilidade está correlacionada a comportamento e exploração; monitoramento é acompanhamento.
Monitoramento como Detecção de Sintomas
Monitoramento é, em essência, a disciplina de detectar sintomas conhecidos de degradação, falha ou risco operacional. Antes de qualquer coisa, só monitoramos o que é claro e conhecido. Ter clareza sobre esse conceito é muito importante para a sua diferenciação. Ele parte do princípio de que já sabemos, com algum grau de clareza, quais sinais merecem ser acompanhados e quais desvios desses sinais representam uma ameaça à saúde do sistema. O monitoramento trabalha com métricas, eventos e thresholds previamente definidos, observando comportamentos esperados e disparando alertas quando algo sai da normalidade conhecida.
Quando configuramos alertas para dimensões conhecidas, como aumento de taxa de erro, aumento de latência, saturação de CPU e memória, filas ou tópicos acumulando mensagens e eventos, locks em banco de dados ou falhas em health checks, estamos modelando sintomas de que algo pode estar errado. Não estamos necessariamente explicando a causa do problema, mas detectando que algo não está de acordo.
O monitoramento pode ter sinais padronizados dentro de uma organização, mas é de extrema importância entender que ele é evolutivo e amadurece junto ao sistema e ao time de engenharia. Sintomas conhecidos dependem de conhecimento prévio. Monitoramos aquilo que já aprendemos a medir, aquilo que já sabemos que pode falhar ou aquilo que já identificamos historicamente como importante, e revisitamos esses critérios sempre que algo estrutural muda.
Observabilidade como Comportamento
Como vimos, o monitoramento está orientado a sintomas conhecidos. A observabilidade, por sua vez, está orientada a comportamento. Ela é a capacidade de explorar os sinais emitidos por um sistema de forma correlacionada para compreender como ele está se comportando internamente, mesmo quando o problema ainda não foi previamente modelado como uma condição de alerta. Enquanto o monitoramento pergunta “algo conhecido saiu do normal?”, a observabilidade permite perguntar “o que está acontecendo dentro do sistema para que esse comportamento esteja acontecendo agora?”.
Em sistemas distribuídos, uma degradação pode nascer em um ponto e se manifestar em outro. Uma causa pequena pode produzir um efeito grande, dependendo da carga, da topologia e das dependências envolvidas. A observabilidade nos ajuda a correlacionar logs, métricas e traces emitidos por vários serviços envolvidos em uma transação para encontrar a origem de um comportamento com desvio.
Por isso, dizer que observabilidade está ligada a comportamento é dizer que ela se interessa menos por valores isolados e mais pela forma como o sistema reage ao longo do tempo, sob diferentes condições.
Três Pilares da Observabilidade
A observabilidade é a correlação direta de três pilares principais, sendo eles Métricas, Logs e Traces. Todos possuem valor individual e seu contexto sistêmico; porém, quando somados e correlacionados, podemos expandir esses sinais isolados para uma visão de comportamento mais ampla de ambientes complexos. Nesta seção, temos o objetivo de abordar cada um dos três pilares e explorar seus agregados, como Alerting e APM.
Métricas
Métricas são aspectos quantitativos e estatísticos do software que têm o objetivo de medir comportamentos, desempenho e demais estados de um sistema ao longo do tempo. Métricas, por si só, possuem características temporais e fornecem uma visão de tendências ao longo de períodos do dia. Métricas podem operar tanto no nível técnico quanto no de negócio. Existem métricas técnicas, como tempo de resposta, quantidade de sucessos, quantidade de erros, contadores de status codes, métricas de estado de circuit breakers (abertos e fechados), acionamentos de fallbacks, etc. As métricas de negócio operam em um nível mais característico e específico da aplicação e podem ser variações como quantidade de vendas, quantidade de pagamentos aceitos, pagamentos recusados, quantidade de transações autorizadas ou negadas, quantidade de recusas por falta de saldo e demais validações.
Contadores
Contadores são valores que apenas aumentam (ou resetam para zero, como na reinicialização de um serviço). É útil contar o número de eventos, como requisições totais, erros, itens processados com sucesso, itens processados com erro, circuitos abertos, etc. Durante a coleta, esses valores podem ser agregados em séries temporais para entender comportamentos de utilização e picos.
Gauges
Um gauge representa um valor numérico que pode aumentar ou diminuir. É ideal para medir valores pontuais, como uso de CPU, memória em uso, número de conexões ativas, tempos de resposta, etc. Ao contrário dos contadores, os gauges representam registros de valores absolutos que podem variar ao longo do tempo.
Histogramas

Os histogramas agregam observações (como durações de requisições ou tamanhos de resposta) e as agrupam em baldes (buckets) configuráveis. Eles permitem calcular quantis e percentis (ex.: “99% de todas as requisições foram concluídas em menos de 300 ms”), etc. Eles nos ajudam a explorar agregações de métricas de forma mais complexa e aprofundada, analisando a dispersão dos dados por meio de várias dimensões, como média, mediana, percentis e desvio padrão.
Traces
Em ambientes distribuídos de microserviços, uma única transação pode passar por dezenas de serviços diferentes para ser considerada concluída. Traces têm o objetivo de capturar amostras de solicitações, detalhando-as de ponta a ponta, catalogando todas as entradas e saídas de uma transação por meio de múltiplos componentes de um sistema distribuído.
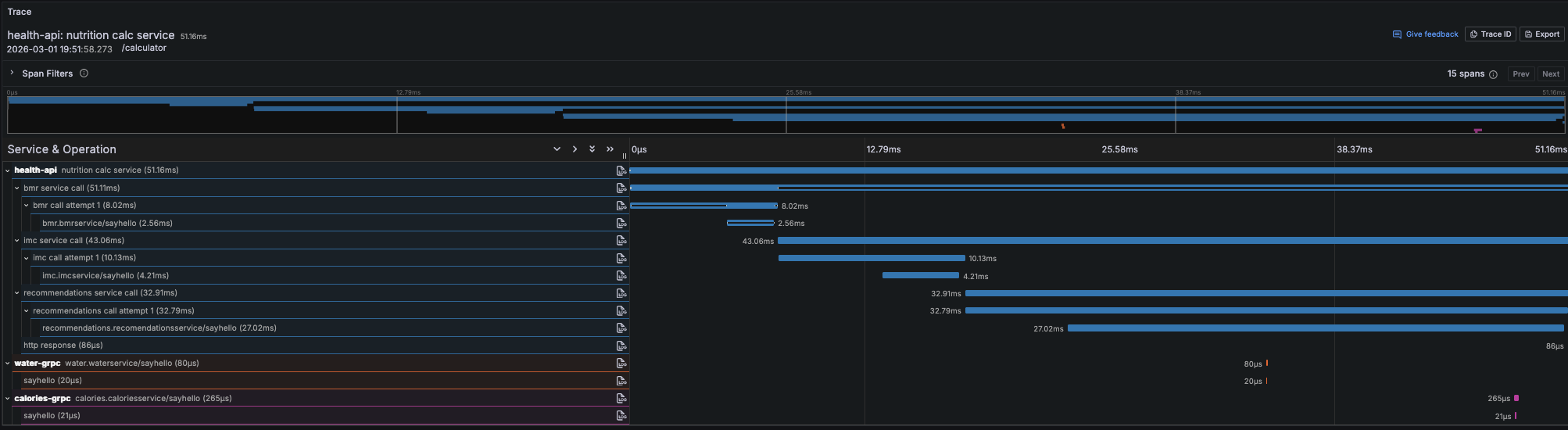
Eles mostram o caminho de ponta a ponta da transação, incluindo tempos de processamento, latência, erros de chamada entre serviços, etc. Diferentemente dos logs, que são isolados, os traces conectam eventos em uma narrativa coesa, revelando como diferentes partes do sistema interagem.
Traces são utilizados para entender erros e desvios de tempos de resposta de uma transação e facilitam o entendimento do “porquê” de um problema em contextos complexos. Em um trace de ponta a ponta, podemos compreender o tempo de execução em nível de funções, métodos, queries de bancos de dados e clientes HTTP de todas as aplicações que interagem durante o funcionamento de uma transação.
Logs
Logs são registros textuais de eventos que ocorrem em um sistema. São a saída do runtime que representa algo que ocorreu. Um log é um registro imutável, vindo da aplicação que o emitiu, de um evento discreto que ocorreu em um ponto específico no tempo dentro de uma aplicação ou sistema e normalmente vem acompanhado de metadados e um timestamp para comparação e ordenação histórica, podendo ser correlacionado em uma linha do tempo, isoladamente ou com outras aplicações, quando estruturado.
Eles capturam informações detalhadas sobre ações, erros e estados em momentos específicos, como mensagens de erro, dados de transação, informações de payloads ou dados de usuários. Em essência, logs funcionam como um diário detalhado do sistema, permitindo que exista uma investigação funcional de problemas e, diferentemente dos traces, possuem uma característica de troubleshooting funcional, onde nem todo “problema” do software é necessariamente um “erro” ou um “desvio”. Eles nos ajudam a responder perguntas como “O que aconteceu com a transação xxx?”, “O que um usuário específico fez?”, “Qual foi o erro exato que causou a falha desta requisição?”, “Quais foram os parâmetros de uma função quando ela foi chamada e qual foi seu retorno?”.
Níveis de Severidade
Quando tratamos os logs como um “diário detalhado” do sistema, a classificação de severidade é o componente semântico que traduz um fluxo textual qualquer em um componente de telemetria “interrogável”. Os níveis de severidade classificam os registros imutáveis de log em criticidade e contexto, que dizem “o que esse evento significa” e “o que alguém deve fazer a respeito”. Os níveis mais comuns (TRACE, DEBUG, INFO, WARN, ERROR e FATAL/CRITICAL) existem para representar intenções diferentes, não apenas a gravidade do ocorrido. Nesta seção, iremos abordar critérios claros de classificação para cada um deles.
| Level | Intenção |
|---|---|
| TRACE | Rastrear passos internos muito finos para investigação pontual |
| DEBUG | Explicar decisões internas e facilitar troubleshooting |
| INFO | Registrar fatos relevantes do fluxo e do domínio |
| WARN | Registrar um desvio recuperável |
| ERROR | Falha de operação |
| FATAL / CRITICAL | Falha terminal em nível de runtime |
Nível TRACE
TRACE é o nível de microscopia. Ele existe para quando você precisa observar o caminho exato que o código percorreu, com granularidade alta e verbosa, tipicamente em investigações pontuais, como ordem de decisões internas, branches condicionais, parâmetros intermediários, transformações de payload, detalhes de serialização/deserialização e qualquer nuance que ajude a reproduzir um comportamento que não aparece em logs mais altos, podendo chegar até à verbosidade do protocolo de uma comunicação.
Nível DEBUG
O DEBUG trabalha em nível de diagnóstico. Ele fica abaixo do “contar a história” e acima do “registrar absolutamente tudo”. A intenção do DEBUG é explicar o porquê de uma decisão do sistema, dando visibilidade a variáveis e estados relevantes para troubleshooting, como escolhas de fallback, impressão de parâmetros que levaram uma regra de negócio a seguir por um caminho, identificação de dependências chamadas e seus tempos, composição de requests para serviços downstream, resultados de validações e checkpoints do fluxo que ajudam a localizar o ponto exato de divergência. Geralmente, é utilizado durante períodos de crise para tratar condicionais muito específicas que levam a desvios não tão óbvios, sendo muito útil para sistemas que possuem múltiplos fluxos e uma visão “não tão” determinística em nível de conhecimento do time técnico e de múltiplas condicionais internas.
Nível INFO
O INFO trabalha em um aspecto narrativo da transação. Ele registra eventos relevantes do ponto de vista do sistema e do domínio, de modo que, quando você costura o fluxo por um correlation ID, você consegue ler uma história. O objetivo do INFO é rastrear uma transação de forma consistente e cronológica, como quando uma requisição entra, quem é a entidade principal envolvida, se uma operação foi aceita ou recusada, se um estado mudou, quando um job iniciou e finalizou, quando e como um evento de domínio foi publicado e como e quando uma transação foi concluída, com todas as informações relevantes para tratar um correlationId em nível de um agregado forte.
Nível WARN
O WARN é o nível do desvio com continuidade. É quando algo saiu do ideal, mas o sistema ainda conseguiu seguir adiante, como uma dependência que respondeu de forma mais lenta e um retry foi necessário, um fallback foi acionado, um circuito abriu por proteção, um timeout quase estourou, uma fila começou a crescer, uma validação marginal foi aceita por regra de tolerância, um cache miss inesperado elevou a latência, uma operação precisou degradar para manter a disponibilidade. Um bom WARN é acionável, deve carregar contexto para permitir triagem e pode ser utilizado para confiabilidade, porque ele frequentemente aparece antes do incidente.
Nível ERROR
O ERROR é falha de operação. Aqui, a execução não atingiu o resultado esperado do ponto de vista daquela transação. A requisição falhou e retornou erro, um critério de domínio foi violado e o comando foi rejeitado, uma dependência falhou sem compensação possível, uma transação abortou, uma transação no banco de dados não foi concluída, uma conexão não pôde ser fechada, uma mensagem não pôde ser processada e foi para DLQ, um dado essencial estava ausente ou um estado ficou inconsistente a ponto de impedir continuidade.
Um ERROR precisa ser pensado como um “log de triagem” e deve dizer o que falhou, por que falhou, junto com sua possível causa, onde falhou e em qual componente, e como correlacionar com o resto do fluxo, respeitando correlation IDs.
Nível FATAL
FATAL (ou CRITICAL, dependendo do ecossistema) é falha terminal, aquela que compromete a continuidade do processo ou do serviço. É quando o runtime não consegue seguir, o processo cai, o serviço não inicia, uma configuração essencial é inválida, um recurso crítico não está acessível na inicialização ou uma condição irrecuperável foi atingida e a única resposta segura é encerrar. Como, por exemplo, um NullPointer crítico, uma dependência crítica que não pode ser acessada, falta de variáveis e parametrizações necessárias para iniciar a aplicação, etc. Logs FATAL são geralmente associados a falhas de runtime e impedem a aplicação de funcionar.
Correlação de Logs
A principal função dos logs está no seu nível de detalhe útil. Uma métrica pode mostrar a quantidade de erros dentro de um período específico; porém, um log tem o objetivo de mostrar os outputs da aplicação que indicam quais erros, exceções e em que cenários esses erros aconteceram. Em ambientes cada vez mais distribuídos, com múltiplos serviços dentro de uma mesma transação, podemos estabelecer padrões de campos que se repetem em todos os serviços pelos quais uma determinada transação passa, para que seja possível correlacionar os logs de diversas aplicações e gerar uma “história” de uma transação.
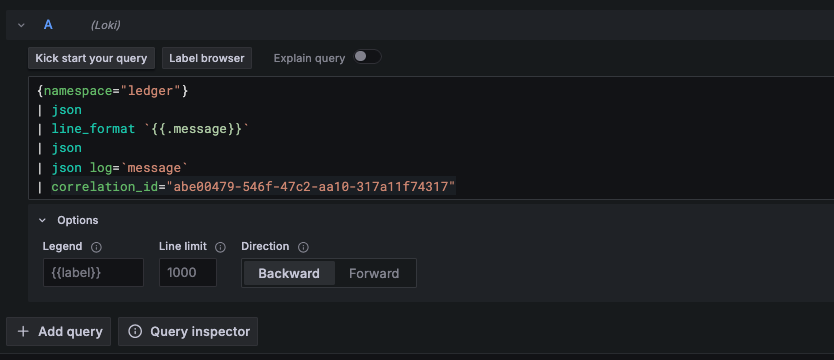
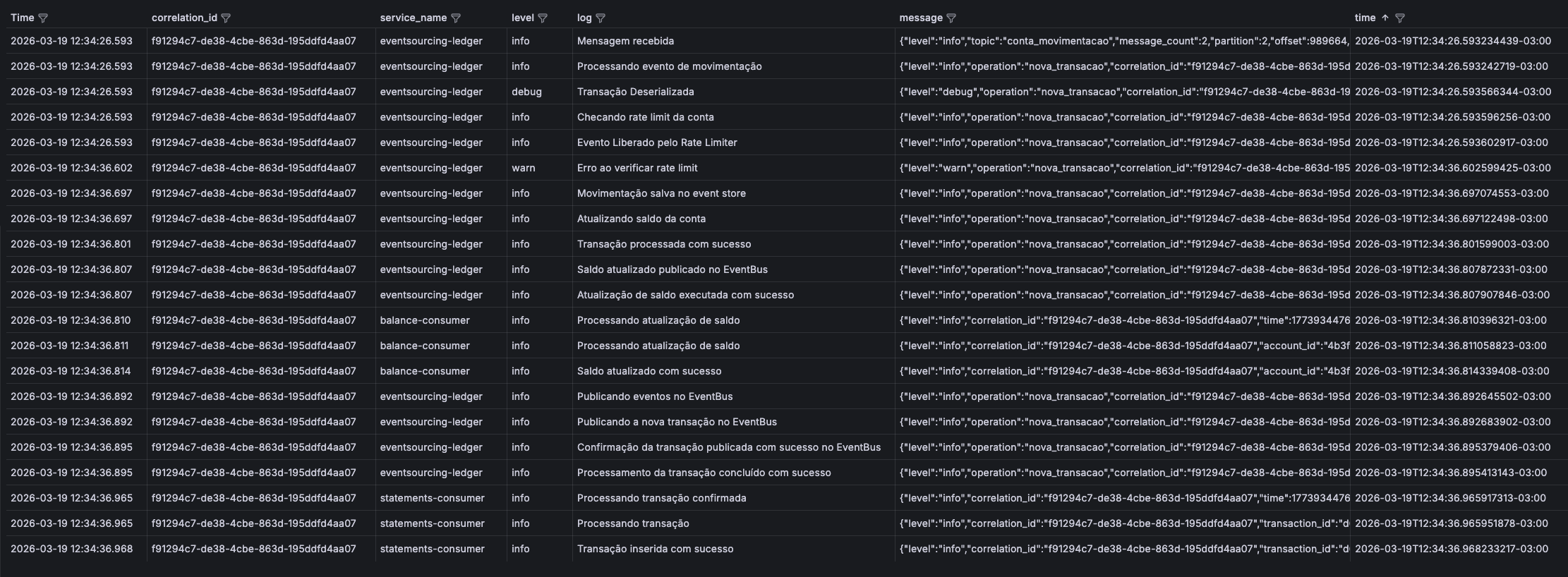
Os logs, para terem valor, precisam contar uma história. Conceitualmente, trabalhamos uma transação como um agregado, e as linhas de log como itens decorrentes desse agregado. Quando bem estruturado, esse padrão nos permite, por meio de identificadores únicos como trace_id, correlation_id, order_id, correlacionar os logs de diversas fontes para explicar como uma determinada transação ocorreu, como o extrato de uma história. Talvez esse seja o cenário em que os logs vão, de fato, gerar todo o seu potencial e justificar seus altos custos de ingestão, armazenamento e retenção.
Estruturação e Indexação de Logs
O maior desafio da ingestão de logs está no custo. Aplicações podem gerar gigabytes ou terabytes de logs por dia, tornando o armazenamento e a análise tarefas muito complexas. Esses logs podem conter uma variedade imensa de informações e valores únicos e despadronizados, como IDs de usuário, IDs de requisição, mensagens de erro detalhadas, stack traces extensos, que são, sim, dados úteis; porém, quando trabalhamos com indexação utilizando os valores desses campos, podemos enfrentar problemas relacionados a performance e custo.
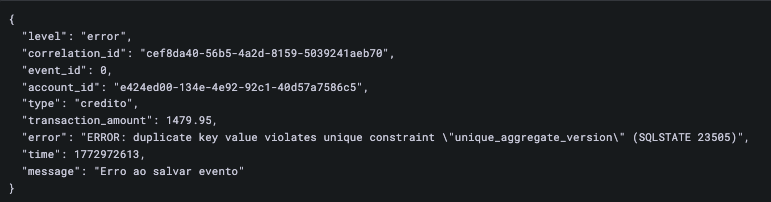
Logs de texto puro são difíceis de analisar em escala. Logs estruturados e padronizados, por exemplo, em JSON, permitem que ferramentas de agregação de logs realizem a indexação por campos específicos mais buscados, além de filtros e agregações, de forma menos custosa computacionalmente e financeiramente. Podemos indexar a partir de correlation IDs, IDs de conta, nível de criticidade e afins. Ter um formato e campos padronizados pode ser, sim, um desafio em ambientes maiores; porém, torna o pilar de logs significativamente mais eficiente em termos de custo de armazenamento, escalabilidade e busca.
Agregados dos Pilares
Além dos três pilares, temos dois outros termos que nos ajudam a agregar confiabilidade aos sistemas: alerting e APM.
Alerting
Alerting, ou alertas, são os mecanismos que transformam os números e dimensões já conhecidos de degradação de um sistema em sinais para intervenção humana. É a disciplina responsável por observar sinais emitidos por logs, métricas, traces ou agregados desses pilares e decidir quando uma condição saiu do campo da simples medição e foi para um campo em que será necessária uma intervenção. É uma forma de saber, de maneira automatizada, que um determinado comportamento do sistema atingiu um nível de risco, desvio ou impacto e que ele merece reação humana ou automatizada.
Do ponto de vista de confiabilidade, o maior valor do alerting está em acelerar feedback loops sobre o comportamento do sistema. Quanto mais cedo um comportamento degradado é percebido pelo time de engenharia responsável, menor tende a ser o tempo de detecção, menor a chance de amplificação do dano para o cliente e maior a possibilidade de contenção do impacto antes de um impacto sistêmico maior para todo o ambiente. Alertas bem definidos reduzem MTTD (Mean Time To Detect), ajudam a proteger o error budget, orientam war rooms e criam um senso de prioridade operacional.
APM
APM, ou Application Performance Monitoring, é a camada de observabilidade voltada a compreender como uma aplicação se comporta durante a execução de trabalho útil, visando entender a experiência do cliente. Enquanto métricas de infraestrutura ajudam a enxergar o estado de recursos alocados, métricas de aplicação ajudam a entender o estado operacional de negócio e os traces ajudam a reconstruir o caminho de uma transação de ponta a ponta, o APM organiza esses sinais ao redor da experiência da própria aplicação, destacando operações, endpoints, dependências, tempos de resposta, throughput, taxas de erro e fragmentos relevantes de execução, para que seja possível observar a saúde do software com mais proximidade do uso real.
O APM tenta responder perguntas como “quais operações estão mais lentas agora?”, “quais delas regrediram após uma mudança?”, “quais endpoints concentram mais erro?”, “quais dependências estão consumindo mais tempo da transação?”, “onde estão os gargalos de latência?”, “qual parte do fluxo ficou mais cara sob carga?” e “quais jornadas estão sofrendo de forma mais perceptível?”. Ele busca agregar todos os sinais de observabilidade sob um guarda-chuva de experiência de uso.
Service Levels
Os Service Levels são o principal framework de mercado para engenharia de confiabilidade. Tendo sua origem na engenharia da Google, eles nos dão direcionamentos simples de como transformar métricas técnicas em “estrelas-guia” de produto, que são capazes de ser interpretadas por diversos níveis de uma empresa. Na prática, tornam-se a interface comum de linguagem entre engenharia e negócio, onde encontramos um acordo claro sobre qual é a experiência mínima aceitável, quais são as tolerâncias operacionais e qual é o custo de sustentar esse patamar desejado.
Um sistema pode ter dashboards extremamente detalhados e, ainda assim, operar no escuro se não houver um referencial explícito de “normalidade” e “aceitável” para a jornada do usuário, e é exatamente esse vácuo que SLA, SLO, SLI e Error Budget preenchem em sistemas maduros.
SLI - Service Level Indicator
O SLI, ou Service Level Indicator, é o indicador mensurável que materializa o SLA e o SLO. O SLI é o dado que será observado, como, por exemplo, Availability/Uptime, Latency, Throughput, Error Rate, Saturation, Recovery Time, etc. Ele indica qual será a métrica observada em ambos os casos. A escolha e a maturidade de um SLI devem ser criteriosas e evolutivas, acompanhando os times de engenharia e os próprios SLOs e SLAs. Podem tanto ser métricas técnicas, como as citadas, quanto métricas de negócio ou específicas de um produto, como, por exemplo, acurácia de um modelo, taxas de aprovação de transações, redução de fraudes, etc.
SLA - Service Level Agreement
O SLA, ou Service Level Agreement, é o indicador mais importante em nível de cliente. O SLA é um compromisso contratual de nível de serviço, normalmente formalizado com clientes, áreas internas ou parceiros. Esse compromisso atua na esfera contratual de um provedor de serviço, seja ele interno ou externo.
Quando contratamos algum serviço, seja ele IaaS, SaaS ou PaaS, ele está inerente a um contrato de disponibilidade. Quando esse contrato é quebrado, podem existir consequências jurídicas para o prestador do serviço. Por isso, SLA não é o lugar para “fidelidade técnica”, e sim para accountability. Ele tende a ser mais estável, mais conservador e menos granular, porque precisa ser mensurável, auditável e defensável. Ele está além de uma métrica do time técnico, que deve trabalhar com margens menores que o SLA como objetivo operacional.
Um SLA está inerente a tudo que permeia a operação do cliente final. Pode ser considerado a partir de disponibilidade, tempo de resposta, tempo de recuperação de desastre, etc. Os SLAs podem ser definidos como “ter 99.99% de uptime, 99.9% de disponibilidade nas requisições, responder uma transação de cartão de crédito em menos de 600 ms, ter um data loss de no máximo 2 h em RPO, ter um tempo de recuperação de falhas de até 1 h”, etc.
Quando estabelecemos SLAs de disponibilidade, a definição dessa métrica nunca deve ser 100%, pois qualquer variação ou desvio pode comprometer o contrato. Ao invés disso, adicionamos “9’s”, como, por exemplo, 99%, 99.9%, 99.99%, etc., mas nunca 100%.
Os SLAs precisam ser declarados e conhecidos por todas as camadas do produto — times técnicos, negócio, marketing e suporte — e devem ter um escopo claro, como disponibilidade mensal, disponibilidade anual, disponibilidade diária, tempos de resposta, etc. O SLA, inclusive, pode ser granular em nível de serviço ou feature do sistema, medido de forma isolada em uma jornada, endpoint, etc.
SLO - Service Level Objective
O SLO, Service Level Objective, é o seu “contrato interno” de confiabilidade. O SLO é, de fato, uma métrica inerente ao time técnico: o critério que o time de engenharia utiliza para operar, decidir e assumir riscos.
Um SLO pode ser “responder em menos de 600 ms em p99 e 500 ms em p95”, “garantir replicação de dados em três fatores”, “ter uma média diária de error rate abaixo de 1%” ou herdar diretamente os critérios do SLA.
Caso os SLIs dos SLOs sejam os mesmos do SLA, eles devem ser mais restritivos que o SLA, pois também funcionam como uma blindagem técnica do contrato. Por exemplo, se o SLA estabelecido por contrato é de uma disponibilidade mensal de 99.9%, com um tempo de resposta de p99 de 800 ms, o SLO precisa ser mais restritivo, considerando, por exemplo, 99.95% de disponibilidade e um p99 de 500 ms. A longo prazo, o objetivo de um SLO é tornar-se o SLA do produto, enquanto o time técnico continua elevando o nível de exigência para atingir excelência operacional.
Error Budget
O Error Budget é o orçamento de erros associado a um contrato. Se o SLO define “quanto erro é aceitável”, o Error Budget define “quanto erro você ainda pode consumir antes de entrar em risco”. Se nosso SLO é 99.95% de disponibilidade e nossos SLIs apontam para 99.98% de disponibilidade, isso significa que temos 0.03% de margem para erros dentro do sistema.
O objetivo do Error Budget, além de mostrar o quanto de margem ainda temos para errar dentro das metas técnicas, é funcionar como um indicador de feedback loop dentro das releases de software. Quando o budget está saudável e possui margens consideráveis, você pode acelerar mudanças e deploys em produção. Ao contrário disso, quando o budget está sendo consumido e está muito próximo de atingir o limite, você desacelera, prioriza correções, reduz blast radius e aumenta o rigor de release e revisões. Se o budget estourou, você congela releases não essenciais, direciona capacidade para estabilidade e conduz war rooms de observabilidade e acompanhamento.
Frameworks de Mercado
Antes de entrar nos frameworks de mercado, vale estabelecer o porquê de eles existirem e qual problema real resolvem. Pois, a princípio, perante vários cases de uso complexos, com múltiplos níveis de observabilidade e operação, em um primeiro momento, eles podem parecer bem simplistas. Mas não são. O objetivo dos frameworks de mercado é fornecer “estrelas-guia” simplificadas para os times de engenharia e produto. Dentro de produtos de tecnologia, a maior parte das discussões operacionais degrada por dois caminhos previsíveis: ou o time se afoga em centenas de métricas desconexas, sem conseguir distinguir sintoma de causa, ou se apega a uma ou duas métricas “fáceis”, como CPU média, 5xx e latência média, e toma decisões erradas com muita confiança.
O objetivo de frameworks como Four Golden Signals, RED e USE é sugerir métricas simples e facilmente compreensíveis, que vão atuar como bússolas de navegação do sistema em produção. Usá-los, de forma alguma, descaracteriza a necessidade de observar dimensões mais detalhadas; apenas simplifica o entendimento da saúde do serviço por meio de métricas direcionadas.
USE Method
O USE Method surge no contexto de engenharia de performance de sistemas, popularizado e formalizado por Brendan Gregg no artigo “Thinking Methodically about Performance”, como uma estratégia de checagem sistemática e padronizada da “saúde” de recursos físicos alocados.
O objetivo do Método USE é dar visibilidade a cada recurso, como CPU, memória, disco, rede e outros, como filas e pools, e observá-los em três dimensões principais: Utilization, Saturation e Errors. Esses recursos podem ser tanto recursos alocados para aplicações dentro de containers ou servidores quanto recursos de suas dependências, como databases, caches, filas, etc.
Ele descreve o USE como um método para iniciar uma investigação de queda de performance de forma simples e objetiva, monitorando sinais vitais e identificando gargalos sistêmicos com rapidez.
Utilization (Utilização)
A Utilization é quanto do recurso está sendo consumido em um intervalo de tempo. Em CPU, pode ser o percentual de tempo em execução ou o percentual utilizado em relação ao alocado. Em memória, pode ser o uso em relação ao provisionado. Em disco, pode ser busy time / throughput em relação ao limite de IOPs. Em rede, pode ser a bandwidth consumida em relação ao total permitido. Em pools, pode ser conexões em uso em relação ao limite do banco, etc. Utilization é um indicador de carga e tendência. Ele é útil para capacity planning, detecção de regressões e para “contextualizar” a saturação.
Saturation (Saturação)
A Saturação é o estado de superalocação de um recurso computacional, como CPU, memória, thread pools e connection pools. Geralmente, é monitorada pela ocupação ou pressão sobre o recurso, e não apenas pela utilização percentual. Por exemplo, quantos processos estão aguardando CPU (run queue) ou quantas requisições estão enfileiradas aguardando processamento. Quando esse recurso começa a degradar por operar próximo de sua capacidade total, entendemos que ele está saturado.
Em CPU, a saturação pode aparecer como run queue (processos esperando CPU), throttling de cgroup e o comumente utilizado load average. Em memória, pode aparecer como swapping, garbage collector em excesso, falhas de alocação, etc. Em disco, aparece como filas de I/O, iowait, latência de I/O, backlog de flush. Em rede, aparece como drops, retransmissões, filas no kernel, etc.
Errors (Erros)
Os Errors no USE são falhas diretamente associadas ao recurso monitorado. Em CPU, falhas por starvation ou erros de scheduling. Em memória, OOMKills, allocation failures, crashes por falta de heap, evictions. Em disco, I/O errors, timeouts, corrupções, falhas de mount. Em rede, connection resets, TLS handshakes falhando por exaustão de recursos, packet loss, DNS failures. Em pools, “too many connections”, “thread pool exhausted”, “queue full”, “rate limit exceeded”. O valor desses erros é o sinal necessário para indicar que o recurso provisionado e alocado não está sendo suficiente para suportar a quantidade de trabalho.
RED Method
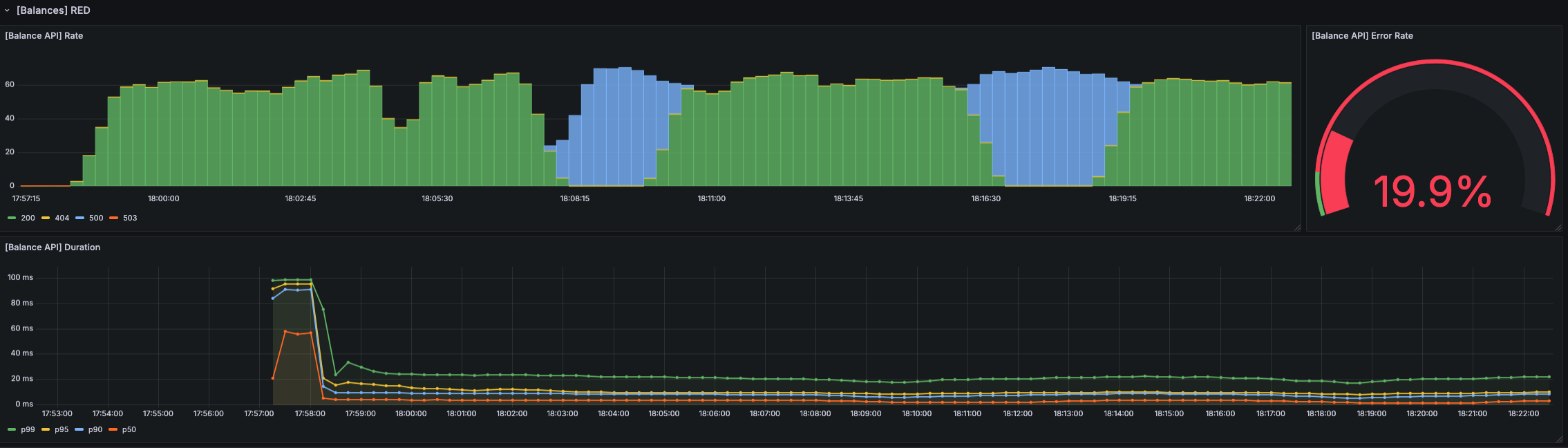
O RED Method nasce de uma necessidade equivalente à do USE, porém voltada para serviços e aplicações. Como vimos, o USE foi concebido para recursos e infraestrutura, enquanto microserviços demandam uma visão de métricas direcionadas à experiência e ao comportamento do serviço em produção, por meio de três dimensões básicas. O termo é associado a Tom Wilkie e à Grafana, por meio de diversos artigos e apresentações técnicas direcionadas à instrumentação e ao monitoramento de serviços, principalmente em sistemas distribuídos.
O RED busca simplificar os sinais vitais mais importantes para qualquer aplicação web, sendo eles Rate, Errors e Duration. Em caso de dúvidas sobre o que monitorar, a base será essa.
Rate (Request Rate / Throughput)
O Rate representa a pressão de demanda sobre o serviço e a sua capacidade efetiva de processar essa demanda. Ele evidencia quantas transações estão chegando ao sistema em um determinado intervalo de tempo, como “transações por segundo”, “requests por minuto”, etc. Ele representa o quanto o sistema está sendo requisitado pelos clientes.
Essa métrica pode ser medida em um contexto global do sistema, mas, além disso, deve ser medida de forma granular também em nível de endpoint e funcionalidade, como requisições por segundo por rota, por operação (GET/POST), por tenant, por região, por versão (canary vs stable), etc.
O request rate é a primeira métrica a ser monitorada, pois o aumento do rate de uma aplicação ou funcionalidade pode acarretar saturação e aumento proporcional de erros e filas internas, caso o sistema não opere com escalabilidade horizontal de forma responsiva. Ele também nos ajuda a identificar picos e tendências de uso do sistema, que podem gerar insights valiosos para capacity planning e aplicação de estratégias de autoscaling.
Errors (Error Rate)
Os Errors estão diretamente ligados ao request rate, pois têm o objetivo de demonstrar a porcentagem das requisições que estão chegando ao sistema e falhando. A métrica tem o critério de medir falhas observáveis do ponto de vista do consumidor, mas só é útil se “erro” for definido de forma semântica.
É comum que essa semântica considere apenas erros “HTTP 5xx”. Isso é insuficiente por dois motivos: primeiro, porque 4xx pode representar degradação com base em desvios, como autenticação falhando por clock skew, validações quebradas por mudança de contrato, “429” por rate limit excessivo, etc. Em confiabilidade, erro é tudo aquilo que viola a expectativa de sucesso do consumidor: falha de autorização indevida, timeout, resposta inválida, inconsistência, idempotência quebrada, duplicidade e até sucesso tardio, quando o usuário já desistiu.
Resumindo, todos os códigos de erro, sejam eles 4xx ou 5xx, devem ser monitorados e considerados; porém, nem todos precisam ser tratados como SLOs, apenas observados em nível de serviço.
Duration (Request Duration / Latency)
Duration mede o tempo para completar uma operação do ponto de vista do consumidor. É o critério mais fácil de medir e também o mais fácil de medir de forma incorreta. O primeiro ponto de atenção é o uso exclusivo da média de latência em sistemas complexos. A média pode ser distorcida quando há problemas de tempos de resposta em uma distribuição de cauda longa, e as caudas são onde a experiência degrada, os timeouts disparam e os retries começam a amplificar a carga. Duration precisa ser analisada em percentis (p50/p95/p99) e, idealmente, com histogramas para observar a forma da distribuição. Quando aplicada também em nível granular por métodos ou endpoints, podemos entender quais funcionalidades estão apresentando desvios de tempo de resposta, acelerando o troubleshooting e o tempo de recuperação.
Four Golden Signals

Os Four Golden Signals são uma forma direcionada e simplificada de descrever a saúde operacional de um sistema user-facing, evitando o caos de métricas infinitas. O conceito foi popularizado pela literatura do Google sobre Site Reliability Engineering e tem o objetivo de realizar uma recomendação explícita de quatro métricas principais, os Sinais de Ouro. Esses quatro sinais têm o objetivo, inclusive, de orientar a definição de SLOs de forma simples.
O objetivo é padronizar métricas em escopos pequenos, médios e grandes, evitando o fenômeno de “monitoramento por acúmulo”, em que times passam a colecionar uma quantidade muito grande de métricas e dashboards, mas, sem um modelo mental coeso, acabam incapazes de responder rapidamente a perguntas simples como “o sistema está saudável do ponto de vista do usuário?”, “quais sistemas estão degradados agora?”, etc.
Os quatro sinais são Latency, Traffic, Errors e Saturation.
Latency
A Latência nos Four Golden Signals corresponde ao tempo que um sistema, transação ou funcionalidade leva para responder a uma requisição. No modelo, isso inclui tanto respostas bem-sucedidas quanto respostas com erro, porque, para a experiência do usuário, “rápido e errado” ainda é um comportamento observável relevante, assim como “lento e correto”.
A latência, assim como em outros frameworks de mercado, não deve considerar apenas a média e precisa levar em consideração a leitura de percentis, que podem dar visibilidade a comportamentos ocultos de outliers, como p99, p95, p90, p50, etc.
Traffic
O Traffic, tráfego ou throughput, busca dar visibilidade à quantidade de solicitações que o sistema está recebendo dentro de um intervalo de tempo e pode ser ilustrado como requisições por segundo, transações por segundo, queries por segundo, bytes, mensagens, etc., representando o “quanto de trabalho” está chegando ao sistema.
Aqui, o objetivo também é dar visibilidade a comportamentos causais, como quando o tráfego sobe e é necessário separar crescimento legítimo de uso do sistema de demandas de amplificação por mecanismos internos, como retries, fanout, reprocessamento, loops, cache miss em massa ou abuso indevido do serviço.
Errors
Os Errors são a taxa de falhas percebidas em relação ao Traffic. Na definição do livro do Google, erros podem aparecer como códigos de erro internos, como 5xx, mas também como falhas explícitas de protocolo e falhas semânticas de resultado, dependendo do que faz sentido para o sistema. A princípio, também é necessário monitorar erros do cliente (4xx) para entender comportamentos e desvios.
Saturation
Saturation é um sinal de proximidade de esgotamento dos recursos provisionados para a aplicação. Responde o quanto o sistema está “no limite” de algum recurso crítico e, principalmente, o quanto trabalho está se acumulando porque o recurso não consegue acompanhar. Por exemplo, o quanto do tráfego está se aproximando dos níveis de rate limit estabelecidos na API, ou o quanto o uso das CPUs da aplicação está próximo de um limite de risco, etc.
Referências
What are SLOs, SLIs, and SLAs?
Time, Clocks, and the Ordering of Events in a Distributed System
Conceitos OpenTelemetry - Ezzio Moreira
Monitoring Distributed Systems
Thinking Methodically about Performance
4 SRE Golden Signals (What they are and why they matter)
The RED Method: How to Instrument Your Services
Monitoring Methodologies: RED and USE
Monitoring and Observability With USE and RED
SLOs: a guide to setting and benefiting from service level objectives
SLI’s, SLA’s e SLO’s :: Não sabe por onde começar com suas métricas? Comece por aqui!

