
System Design - Performance, Capacidade e Escalabilidade

Neste capítulo, vamos abordar três tópicos: Capacidade, Performance e Escalabilidade (não necessariamente nessa ordem), sempre com uma perspectiva conceitual de System Design. Ao escrever, me questionei se deveria dividi-lo em três textos separados. Contudo, fiquei tão satisfeito com o resultado que não consegui tomar essa decisão. À medida que criava tópicos, estudava e coletava referências, uma estranha sensação de querer que este capítulo nunca terminasse surgiu. Com base nisso, levantei muitos outros tópicos adicionais para explorar e abordar nas próximas etapas.
Definindo Performance
Performance, em termos simplistas, refere-se a quão rápido e eficiente um sistema ou algoritmo pode ser ao processar uma única transação. Isso pode ser medido de forma isolada ou em meio a um grande volume de outras transações. A aplicação prática da “performance” envolve diversos termos técnicos e complexidades dentro das disciplinas que compõem a engenharia de software em geral, sendo mais perceptível pelos usuários finais de nossas soluções.
A performance deve ser considerada em relação aos requisitos funcionais e não funcionais do sistema. Por exemplo, um sistema projetado para processamento de dados em tempo real terá diferentes expectativas de performance em comparação a um sistema de armazenamento de dados de longo prazo.
Métricas de Performance

É de extrema importância entender como o desempenho do sistema varia sob diferentes condições, como picos de carga, falhas de componentes ou mudanças no padrão de uso.
A avaliação de performance de um sistema ou algoritmo requer mecanismos de monitoramento de indicadores-chave, também conhecidos como KPIs, Service Levels, entre outros. Observar essas métricas de forma sequencial e contínua, por vários períodos de tempo, pode trazer ideias valiosas sobre como o sistema está operando e dar autonomia para os times de engenharia tomarem decisões sobre design, manutenção e operação do mesmo, além de fornecer dados para identificar tendências, fazer comparações de benchmarks, projetar e prever capacidade e identificar e priorizar quais partes precisam de melhoria de forma mais urgente.
Existem várias métricas importantes na hora de avaliar um sistema. Algumas são padrões quase universais e podem ser aplicadas em quase todos os cenários, enquanto outras são provenientes de negócios e necessidades mais específicas, que só são aplicadas e fazem sentido em contextos muito específicos. Saber identificar oportunidades de métricas a serem monitoradas representa um trabalho árduo e contínuo, que depende muito da maturidade e das “horas de voo” de um software.
Para este texto, vamos trabalhar com o “feijão com arroz” das métricas de performance, também conhecidas no mercado como Four Golden Signals.
Os “Four Golden Signals” são um conceito dentro do monitoramento e observabilidade de sistemas, popularizado pelo Google no livro “Site Reliability Engineering” (SRE). Eles representam as quatro métricas mais importantes que você deve monitorar para entender a saúde de um sistema distribuído. Essas métricas ajudam os engenheiros a detectar problemas rapidamente e a manter sistemas estáveis e eficientes. Essas métricas são Saturação, Tráfego, Tempo de Resposta e Taxa de Erros.
Não vamos abordar essas métricas do ponto de vista de observabilidade, pois mais adiante teremos um capítulo dedicado a esse tema, onde vamos abordar esse e mais alguns conceitos de forma mais profunda, mas sim do ponto de vista de performance.
Utilização e Saturação de Recursos
A Utilização de Recursos refere-se a quanto do recurso disponível está sendo usado. Um recurso é considerado Saturado quando a sua taxa de utilização se aproxima do valor máximo possível ou esperado. Um sistema pode estar saturado em termos de CPU, memória, disco ou mesmo um pool de conexões de rede. Medir a saturação ajuda a prever problemas de desempenho e a entender quando é necessário escalar recursos.
Algoritmos que fazem uso intensivo de recursos computacionais, como CPU, Memória, Disco e Rede, costumam ser muito sensíveis a otimizações e degradações desses recursos. Ter visibilidade da taxa de utilização em relação às capacidades disponíveis desses recursos em um sistema é essencial para determinar a saúde do serviço e fornecer insights sobre otimização, custos e desempenho.
O objetivo de avaliar a saturação, juntamente com outras métricas de desempenho, é poder identificar gargalos de recursos, como, por exemplo, “a partir de qual porcentagem de uso de CPU meu tempo de resposta e taxa de erro começam a ser afetados?” ou “a partir de qual uso de I/O de escrita e leitura de disco meu banco de dados começa a degradar o tempo de consulta?”. Responder a essas perguntas de forma eficiente evidencia a maturidade e a senioridade de equipes e produtos.
Podemos representar matematicamente a utilização e saturação de um recurso computacional por meio de uma fórmula simples:
\begin{equation} \text{Utilização de Recurso} = \left( \frac{\text{Recurso Utilizado}}{\text{Recurso Disponível}} \right) \times 100 \end{equation}
Vamos imaginar um caso em que precisamos analisar o uso de memória alocada para um sistema. Basicamente, presumimos um cenário em que temos disponível para executar um algoritmo 2 GB de RAM, ou 2048 MB. Após coletar métricas e observar o algoritmo em execução, foi constatado que o uso atual dessa memória disponível está em 1 GB, ou 1024 MB.
\begin{equation} \text{Utilização de Memória} = \left( \frac{1024}{2048} \right) \times 100 \end{equation}
\begin{equation} \text{Utilização de Memória} = 50\% \end{equation}
De acordo com o cálculo no cenário hipotético, a utilização de memória do sistema está em 50% da capacidade disponível. Um recurso pode estar saturado e começar a afetar o desempenho do sistema mesmo antes de a utilização chegar a 100%. Analisar a utilização de recursos é importante para otimizar o desempenho de um serviço e fornecer informações necessárias para criar sistemas mais econômicos, eficientes e performáticos.
Throughput, ou Tráfego
O Throughput, de maneira geral, descreve o número de operações que um sistema consegue realizar dentro de um determinado período de tempo. Ele mede quantas unidades de trabalho (como transações ou requisições) um determinado sistema ou algoritmo pode processar por unidade de tempo, como requisições por segundo, vendas por minuto, arquivos por dia ou eventos por mês. É uma métrica de extrema importância para entender a capacidade e o desempenho de aplicações. Em sistemas projetados para lidar com protocolos web, o Throughput é contabilizado a partir da quantidade de requisições HTTP que a aplicação recebe e responde.
A fórmula utilizada para calcular o throughput pode ser representada matematicamente da seguinte forma:
\begin{equation} \text{Throughput} = \frac{\text{Unidades de Trabalho Processadas}}{\text{Tempo}} \end{equation}
Desenhando um cenário hipotético em que um sistema recebeu 6.000 requisições no último minuto, podemos calcular o throughput por segundo da seguinte forma:
\begin{equation} \text{Throughput} = \frac{6000}{60} \end{equation}
\begin{equation} \text{Throughput} = 100.00\ \text{rps} \end{equation}
Representar matematicamente o throughput do sistema é muito valioso em termos de performance, pois nos ajuda a entender até que ponto nosso sistema consegue atender requisições antes de começar a afetar suas métricas de aceitação, como tempo de resposta e taxa de erros. Podemos utilizar o throughput dentro de períodos lógicos de tempo para efetuar operações de escalabilidade dinâmica, como veremos na seção de escalabilidade.
Tempo de Resposta
O Tempo de Resposta é o tempo total que leva desde o envio de uma solicitação até o recebimento da resposta. Ele inclui tanto a latência (tempo de ida e volta da rede) quanto o tempo de processamento no servidor, sendo, na maioria dos casos, uma soma de ambos. Em um contexto de usuário final, é o tempo que leva desde que um usuário realiza uma ação (como clicar em um link ou pressionar uma tecla) até que ele veja o resultado dessa ação e, portanto, é medido entre um cliente e um servidor. Em sistemas escaláveis, é importante que o tempo de resposta não aumente significativamente à medida que a utilização da aplicação se eleva.
A Latência pode ser definida como o atraso de rede ou o tempo que uma solicitação leva para viajar do remetente ao receptor. Em outras palavras, é o atraso entre o início de uma ação e o início da reação, podendo ser influenciado pela distância física entre os comunicantes, pela velocidade do meio de transmissão e por qualquer atraso introduzido por dispositivos intermediários, como roteadores.
O Tempo de Processamento é o tempo que um sistema leva para processar uma solicitação após recebê-la. Esse termo é frequentemente usado para descrever o tempo necessário para que uma CPU ou servidor processe uma tarefa específica.
O cálculo do tempo de resposta pode ser representado da seguinte forma, a partir do cliente, subtraindo o tempo de início da requisição do tempo final da resposta observada:
\begin{equation} \text{Tempo de Resposta} = \text{Timestamp da Resposta} - \text{Timestamp da Requisição} \end{equation}
Todas as três variáveis apresentadas podem ser observadas e medidas independentemente, em diversos pontos da operação, de acordo com as necessidades do ambiente, sendo, inclusive, uma boa prática para executar troubleshooting mais granular em investigações de problemas, como identificar em que ponto exato da transação ocorreu a degradação em questão.
Taxa de Erros
Uma das principais métricas que podem ser utilizadas para avaliar performance, capacidade e disponibilidade de sistemas é a taxa de erros. Essa métrica pode ser utilizada junto com métricas de tempo de resposta e throughput para tirar conclusões valiosas a respeito do comportamento de um sistema.
A taxa de erros corresponde à porcentagem de todas as requisições que resultam em erro em relação ao total de requisições. Entendemos que um sistema escalável, com capacidade planejada, deve manter ou reduzir sua taxa de erro à medida que a carga aumenta.
Para calcular a taxa de erros de um sistema, geralmente usamos uma fórmula simples que relaciona o número de eventos de erro com o número total de eventos ou tentativas. A taxa de erros é frequentemente expressa como uma porcentagem. Aqui está a fórmula básica:
\begin{equation} \text{Taxa de Erro} = \left( \frac{\text{Número de Erros}}{\text{Número Total de Tentativas ou Eventos}} \right) \times 100 \end{equation}
Suponha que você tenha um sistema que processou 1.000 transações, das quais 50 resultaram em erros. A taxa de erros seria calculada da seguinte forma:
\begin{equation} \text{Taxa de Erro} = \left( \frac{50}{1000} \right) \times 100 \end{equation}
\begin{equation} \text{Taxa de Erro} = 5.0\% \end{equation}
Essa métrica é particularmente útil para avaliar a confiabilidade e a qualidade de sistemas de software, especialmente em ambientes de produção, onde a estabilidade é crítica. Acompanhar a taxa de erros ao longo do tempo pode ajudar a identificar tendências, avaliar o impacto de mudanças ou atualizações no sistema e determinar áreas que podem precisar de melhorias.
Utilizando Percentis em Métricas de Performance
Os percentis são medidas que dividem uma amostra de dados ordenados em cem partes iguais. São amplamente utilizados em estatísticas para entender a distribuição dos dados e representam ferramentas valiosas na análise de performance, oferecendo uma visão mais aprofundada do comportamento em cenários específicos. Em certos cenários, apoiar-se apenas na média pode ser insuficiente para analisar a performance de uma funcionalidade, sistema ou transação. Os percentis são particularmente úteis em conjuntos de dados como tempos de execução de operações em bancos de dados, tempos de resposta e utilização de recursos. Eles podem revelar insights valiosos que a média pode ocultar, como outliers e picos que normalmente não são refletidos por ela.
Um percentil é um valor abaixo do qual uma certa porcentagem dos dados cai. Por exemplo, ao analisar tempos de resposta, o 90º percentil ou p90 é o valor abaixo do qual 90% das respostas são mais rápidas. Um p90 de 800ms indica que 90% das requisições são atendidas em até 800ms. Utilizar percentis permite aos engenheiros identificar e analisar variações extremas, como casos em que o sistema se comporta lentamente. Percentis altos (como 95º ou 99º) são extremamente úteis para identificar comportamentos anormais e extremos do sistema que podem estar afetando negativamente a experiência de uso.
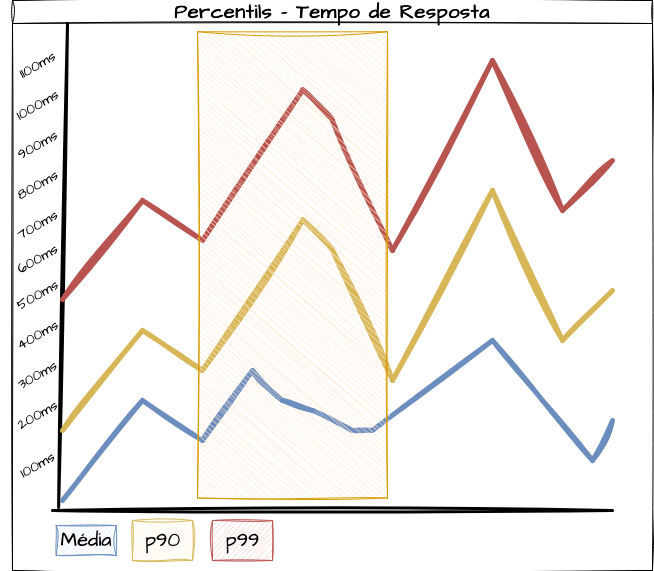
Além de considerar apenas o tempo médio de resposta, analisar os percentis (como 50º, 95º, 99º) em conjunto com a média pode fornecer uma compreensão mais precisa do comportamento real do sistema sob diferentes condições.
Imagine um cenário onde estamos medindo o tempo de resposta de um sistema web em uma janela de tempo específica. Após coletar os dados, observamos que o tempo médio de resposta é de 200ms, um tempo considerado ótimo. No entanto, ao analisar os percentis, descobrimos que o 95º percentil é de 700ms e o 99º percentil é de 1000ms. Isso indica que, embora a maioria das requisições seja rápida, existe um número significativo de casos onde a resposta é muito mais lenta do que a média sugere. Avaliar o comportamento desses outliers pode ser de grande valor para o planejamento de capacidade, identificação de gargalos e ajustes de performance.
Definindo Capacidade

A capacidade, ou “capacity”, no contexto da engenharia de software, refere-se à quantidade máxima de trabalho que o sistema pode receber e processar de maneira eficaz em um determinado período de tempo. É uma forma de medir e encontrar o limite atual do sistema, incluindo recursos como CPU, memória, armazenamento e largura de banda de rede, bem como a performance de algoritmos. Quando olhamos para a capacidade, monitorar os recursos e dependências pertinentes ao sistema é tão importante quanto monitorar o desempenho, principalmente quando trabalhamos em oportunidades de projetar sistemas pensados para curto, médio e longo prazo.
Este conceito é fundamental na arquitetura e no design de sistemas, bem como no planejamento da infraestrutura geral dos componentes de software. A capacidade abrange vários aspectos do sistema, que vão desde a habilidade do sistema de processar dados ou transações, o que está vinculado diretamente ao poder de processamento computacional e à velocidade, eficácia e eficiência desse processamento, até a capacidade de suportar uma quantidade de usuários ou processos simultaneamente, sem degradação do desempenho e conseguindo se adaptar a cargas de trabalho crescentes, aumentando recursos conforme necessário para manter a experiência constante dos usuários em meio a variações dos cenários de carga.
Pensar e medir a capacidade de sistemas envolve não apenas o dimensionamento adequado dos recursos computacionais do sistema, mas também a implementação de estratégias para monitoramento, observabilidade, gerenciamento de desempenho, automações e escalabilidade.
Gargalos de Capacidade
Dentro do contexto de capacidade de software, “gargalos” referem-se a pontos no sistema onde o desempenho ou a capacidade são limitados devido a um componente específico que não consegue lidar eficientemente com a carga atual, e pode ser representado pelo fato de que a demanda atual é maior que a capacidade do componente. Esses gargalos podem afetar negativamente a capacidade geral do sistema de funcionar de maneira otimizada e podem ocorrer em várias áreas, incluindo hardware, software ou na arquitetura de rede. Isso pode incluir CPU, memória, espaço em disco ou capacidade de rede insuficientes, entre várias outras coisas. Por exemplo, um servidor com CPU sobrecarregada não conseguirá processar requisições rapidamente. Erroneamente, profissionais de diversos níveis de senioridade podem associar gargalos sistêmicos à infraestrutura da aplicação; porém, é muito mais comum cenários onde código mal otimizado, algoritmos ineficientes ou gerenciamento de concorrência (como deadlocks ou uso excessivo de bloqueios) podem limitar a capacidade do sistema e se tornar gargalos muito difíceis de lidar e superar no dia a dia de times de engenharia.
Um design de sistema que não distribui a carga de maneira eficiente pode, invariavelmente, criar gargalos. Por exemplo, um ponto central de processamento de uma rotina em que a arquitetura deveria ter a capacidade de quebrar essa carga em várias partes e torná-la distribuída.
\begin{equation} \text{Gargalo} = \text{Demanda} > \text{Capacidade} \end{equation}
Identificar e resolver gargalos é o ponto-chave para otimizar a performance e a escalabilidade de sistemas de software. Isso geralmente envolve monitoramento detalhado, testes de desempenho e ajustes finos do sistema. Em ambientes de nuvem e sistemas distribuídos, a identificação de gargalos também pode incluir a análise da distribuição de carga e a escalabilidade dinâmica.
Um ponto importante de se lembrar é que, ao resolver um ponto de gargalo, a carga sobre os sistemas após esse ponto irá aumentar, o que pode gerar um novo gargalo. Portanto, a análise e a busca de gargalos na capacidade do sistema são um processo dinâmico e contínuo.
Backpressure de Capacidade
O conceito de "backpressure", ou "repressão" em software e, especialmente, em arquiteturas baseadas em microserviços, pode ter várias definições dependendo de onde é empregado. Em alguns contextos, o backpressure pode ser a capacidade ou um mecanismo intencional de um sistema para gerenciar sua entrada/saída, evitando gargalos de processamento do sistema seguinte. Aqui, vamos usar a definição da engenharia física, mais precisamente da gestão de fluidos, onde o termo se refere à resistência oposta ao movimento de um fluido.
De acordo com o Wikipedia,
Backpressure, ou Repressão, é o termo usado para definir uma resistência ao fluxo desejado de fluido através de tubos. Obstruções ou curvas apertadas criam contrapressão devido à perda de carga por atrito e queda de pressão.
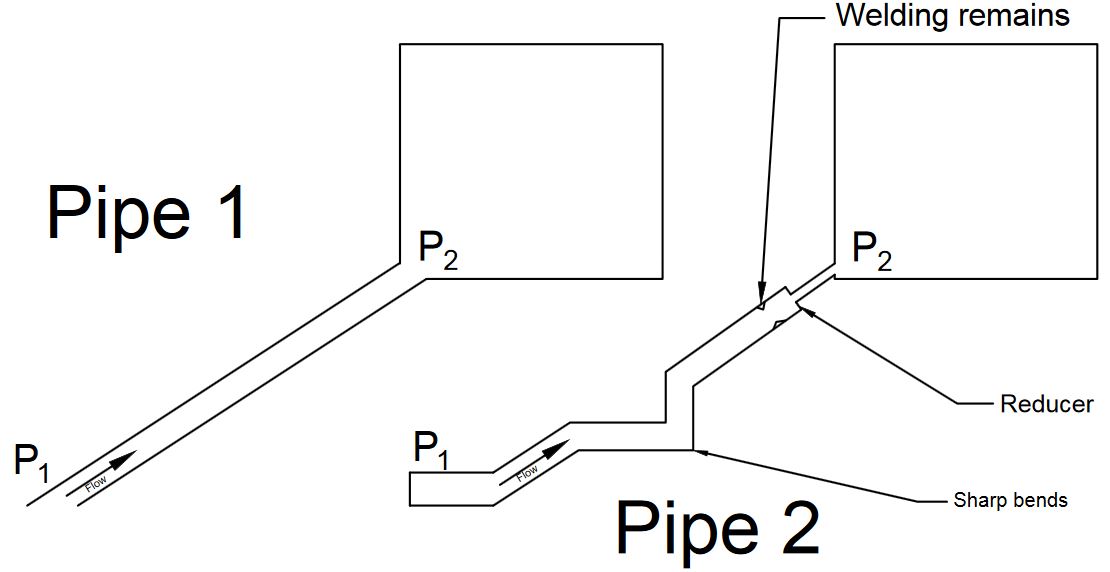
No contexto de software, o backpressure ocorre quando um componente ou serviço em um sistema distribuído começa a receber mais dados ou solicitações do que é capaz de processar. Isso pode levar a uma série de problemas, como aumento do tempo de resposta, falhas e perda de dados.
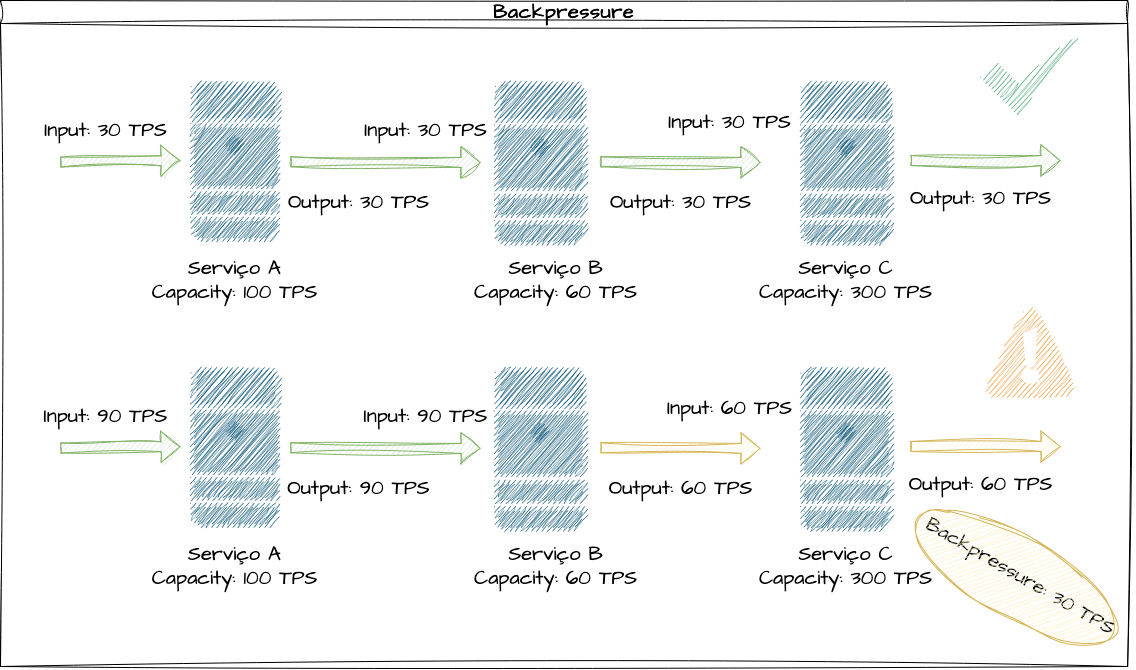
Vamos ilustrar uma solicitação em um sistema fictício que é atendida pelos serviços A, B e C sequencialmente. Respectivamente, esses serviços que compõem a transação suportam 100, 60 e 300 transações por segundo. Em uma carga de trabalho de 90 transações por segundo, todos os componentes desse sistema conseguem receber e dar vazão de forma eficiente para toda a carga de trabalho inserida, sem maiores problemas.
Nesse mesmo cenário, caso esse sistema receba 100 transações por segundo, o que é suportado, em níveis de capacidade, por 2 dos 3 serviços do conjunto, o serviço B terá um backpressure de 40 transações a cada segundo, pois ele só suporta dar vazão a 60 delas.
Em um cenário mais crítico, entendendo que o serviço C consegue suportar até 300 transações, se injetarmos 120 transações por segundo nesse conjunto, a diferença do input do serviço A para o B será de 20 transações, pois ele só suporta 100 delas nesse tempo e, em seguida, 100 dessas transações que foram repassadas para o serviço B, que só suporta 60, serão represadas por capacidade computacional, fazendo com que o backpressure total dessa solicitação seja de 60 TPS, representando 50% de degradação entre o input inicial e o output final, independentemente da capacidade do sistema mais performático de todo o fluxo, que, em 100% do tempo, terá sua real capacidade sempre ociosa devido aos limites de capacidade dos serviços anteriores.
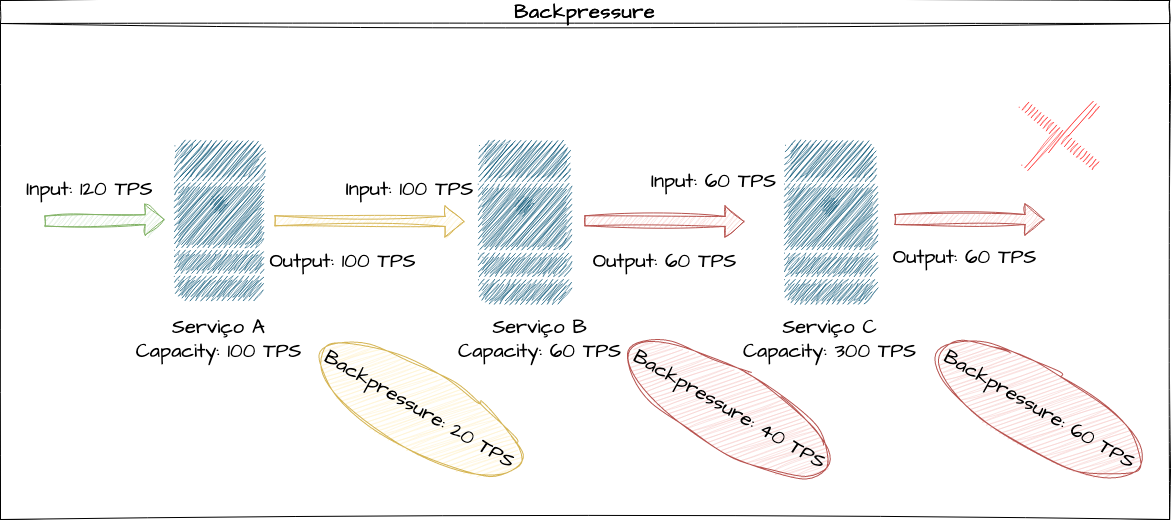
Henry Ford popularizou a frase que dizia que “uma corrente é tão forte quanto seu elo mais fraco”. O backpressure nos ajuda a evidenciar que, por mais que existam serviços mais performáticos que outros compondo um sistema, nosso throughput e capacidade serão limitados ao componente mais degradado.
Custo de Transação por Capacidade
Analisar o custo por transação é muito interessante para avaliar a eficiência e o custo-benefício da capacidade alocada para o sistema. O cálculo do custo de transação em sistemas é uma métrica financeira que avalia o custo total associado à execução de uma operação ou transação. Essa métrica é particularmente relevante quando construímos sistemas em nuvens públicas, onde as considerações financeiras são altamente sensíveis. Podemos calcular o custo de transação com base nos dados de transações totais do cliente. Normalmente, essa métrica é coletada apenas das requisições provenientes do cliente final, não sendo multiplicada pelo número de subsistemas e microserviços transparentes às interações com o cliente.
Essa métrica ajuda as organizações a entender melhor onde e como seus recursos estão sendo gastos e como podem ser feitas economias ou melhorias. Ela pode ser representada pelo custo total da operação em questão dividido pelo número total de transações dentro do mesmo período de tempo.
\begin{equation} \text{Custo por Transação} = \frac{\text{Custo Total Operacional}}{\text{Total de Transações}} \end{equation}
Em sistemas com padrões de demanda variáveis, o custo por transação pode mudar ao longo do tempo. É importante considerar os picos de demanda e como eles afetam o custo médio. Geralmente, um custo por transação mais baixo indica maior eficiência e uso eficaz dos recursos.
Definindo Escalabilidade
Escalabilidade é a capacidade de um sistema, aplicação ou negócio de crescer e lidar com um aumento na carga de trabalho, sem comprometer a qualidade, o desempenho e a eficiência. Isso pode incluir o aumento de usuários, transações, dados ou recursos. É um atributo crítico para sistemas que esperam um aumento no volume de usuários ou dados e uma característica de design que indica quão bem um sistema pode se adaptar a cargas de trabalho maiores ou menores. Escalabilidade é especialmente importante em ambientes de nuvem, onde as demandas podem mudar rapidamente e os sistemas devem ser capazes de se adaptar a essas mudanças.
De acordo com o livro “Release It!” de Michael T. Nygard, a escalabilidade pode ser definida de duas formas. A primeira forma descreve como o Throughput muda de acordo com variações de demanda, utilizando um gráfico de requisições por segundo comparado com tempo de resposta de um sistema. A segunda forma se refere aos modos de escala que um sistema possui. Aqui, assim como no livro, vamos definir escalabilidade como a capacidade de adicionar ou remover capacidade computacional de um sistema.
Uma forma lúdica de exemplificar a escalabilidade é considerar um sistema de ar-condicionado. Imagine que a temperatura desejada para o ambiente seja de 20°C. Se a temperatura do ambiente estiver aumentando devido a condições externas, o ar-condicionado aumentará sua potência para estabilizar a temperatura na marca definida. Por outro lado, se a temperatura estiver diminuindo, o sistema reduzirá sua potência para alcançar o mesmo objetivo.
Importância da Escalabilidade em Sistemas Modernos
A escalabilidade permite que os sistemas se adaptem rapidamente a mudanças no volume de tráfego ou demanda de recursos, garantindo um desempenho consistente mesmo sob carga variável. Em ambientes de negócios dinâmicos, a capacidade de escalar recursos conforme necessário é essencial para manter a continuidade e a eficiência operacional. Além disso, permite manter tempos de resposta rápidos e desempenho confiável, mesmo sob cargas leves, médias e pesadas, resultando em uma experiência de usuário mais satisfatória.
Sistemas escaláveis também podem ser mais econômicos, pois permitem dimensionar recursos de forma mais eficiente. Isso significa pagar apenas pelos recursos que são usados, reduzindo o desperdício e otimizando os custos operacionais. Também podem facilitar a implementação de novas funcionalidades e a expansão de negócios sem a necessidade de reestruturar completamente a infraestrutura existente já projetada.
Escalabilidade Vertical e Escalabilidade Horizontal
Existem dois tipos principais de escalabilidade frequentemente discutidos no design de sistemas: a Escalabilidade Horizontal e a Escalabilidade Vertical. Vamos usar este tópico para discutir a terminologia em torno desses conceitos.
Para ilustrar essas ideias, consideremos um exemplo lúdico de uma empresa que gerencia uma frota de ônibus. Essa empresa tem como missão levar passageiros de um ponto A a um ponto B dentro da cidade. Inicialmente, a empresa investiu em uma frota que comportava aproximadamente 100 passageiros simultaneamente por horário de ônibus. Recentemente, esse número de passageiros aumentou gradualmente, levando a filas de espera nos pontos de embarque, atrasos e reclamações constantes. Com base nesse cenário, vamos começar a explorar os exemplos de escalabilidade.
Escalabilidade Vertical

Uma das abordagens consideradas para resolver os problemas de superlotação dos ônibus foi substituir alguns veículos da frota por ônibus de 2 andares, o que dobraria a capacidade de cada veículo para transportar passageiros. Esse paralelo exemplifica como funciona a escalabilidade vertical.
Podemos entender a escalabilidade vertical como o processo de aumentar ou reduzir a capacidade de um componente, adicionando ou removendo recursos desse mesmo componente. A escalabilidade vertical geralmente envolve aumentar ou reduzir a capacidade de CPU, RAM, disco ou rede de um único recurso, mas não se limita apenas a isso; também pode incluir otimizações em algoritmos para aumentar a capacidade de processamento de entrada/saída. Embora seja uma solução mais simples, a escalabilidade vertical frequentemente encontra limitações físicas e de custo.
Em resumo, no design de sistemas que se baseiam na escalabilidade vertical, o foco está na maximização do processamento e eficiência de um único servidor ou recurso. Isso pode incluir a otimização de algoritmos e a escolha de tecnologias que maximizem o uso da CPU e da memória.
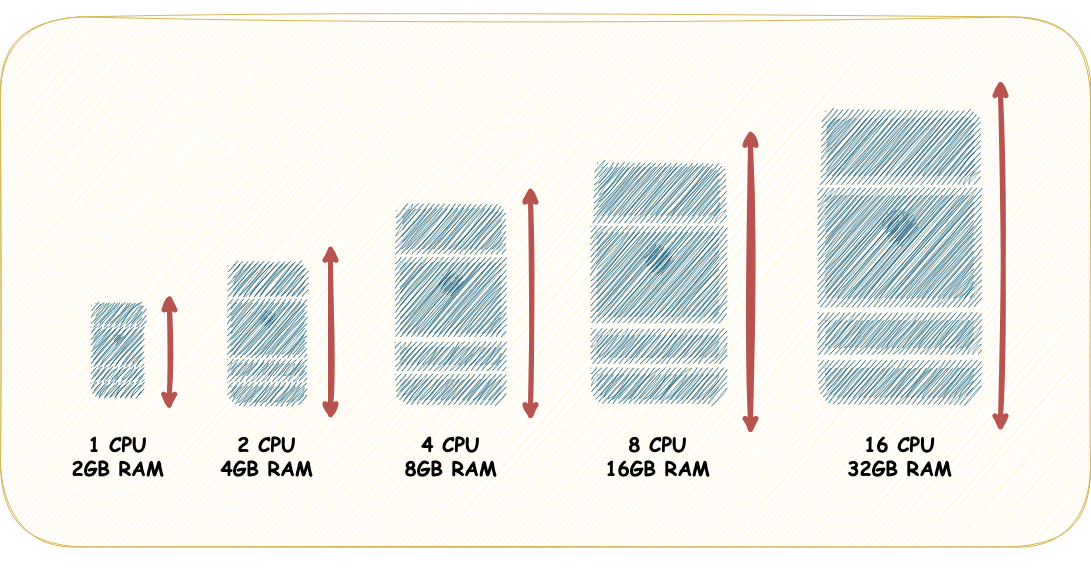
Scale Up e Scale Down
As operações de Scale-up e Scale-down são atividades que ocorrem no contexto da escalabilidade vertical. Elas envolvem o aumento ou a redução dos recursos computacionais de um servidor específico que desempenha determinada funcionalidade. A operação de Scale-up (escalonar para cima) refere-se ao ato de aumentar recursos, como CPU, memória, disco ou rede, para um servidor. Por outro lado, a operação de Scale-down (escalonar para baixo) envolve reduzir esses recursos quando necessário. Em resumo, Scale-up significa adicionar mais recursos de hardware, aumentando o número de CPUs, a quantidade de memória RAM ou a capacidade de armazenamento do servidor, enquanto Scale-down está relacionado a diminuir esses recursos quando apropriado.
Escalabilidade Horizontal

Outra proposta considerada para resolver o problema da superlotação de passageiros foi investir em mais unidades dos modelos de ônibus existentes, em vez de substituir a frota por modelos que comportassem mais passageiros. Isso resultaria em mais veículos operando na rota, distribuindo os passageiros entre eles. Esse paralelo pode ser facilmente associado à forma como a escalabilidade horizontal funciona.
A escalabilidade horizontal refere-se à adição ou remoção de unidades computacionais, como servidores, contêineres ou réplicas, de um componente ou sistema existente. Por exemplo, se você estiver executando uma aplicação web em um único nó e começar a receber muito tráfego, poderá adicionar mais réplicas ao sistema para compartilhar a carga de trabalho, normalmente usando um Balanceador de Carga. A escalabilidade horizontal pode ser implementada de forma eficaz com ferramentas de escalabilidade automática. Esse tipo de conceito também é conhecido como elasticidade.
Para implementar a escalabilidade horizontal de forma eficaz, os sistemas devem ser projetados com uma arquitetura distribuída que seja capaz de processar solicitações com paralelismo externo.
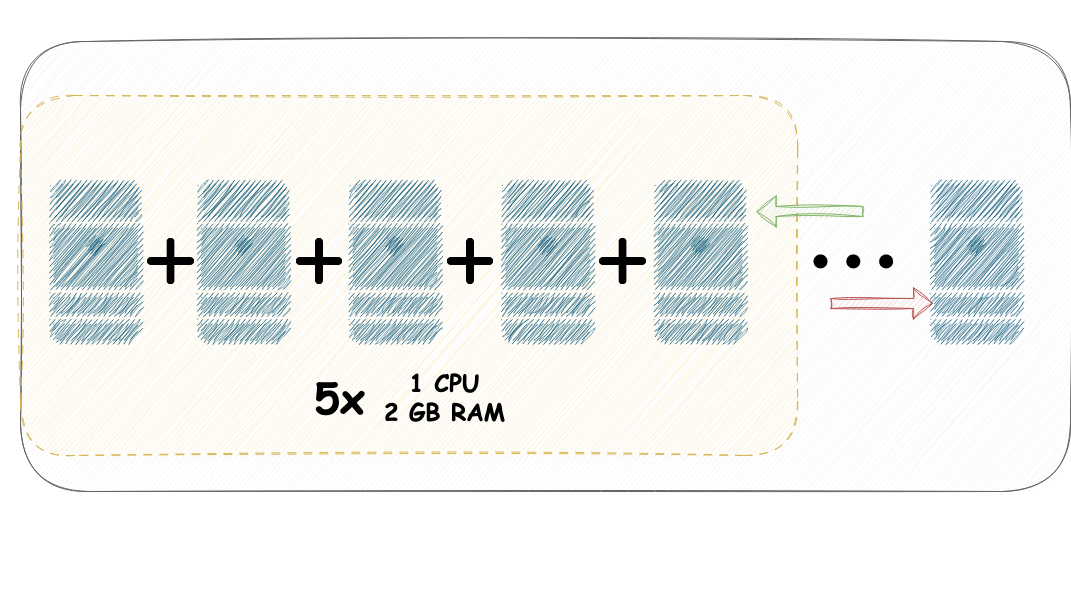
Scale Out e Scale In
As operações de Scale-out e Scale-in são atividades que se enquadram na escalabilidade horizontal. Scale-out (escalar para fora) refere-se a aumentar o número de servidores ou réplicas que desempenham a mesma função, distribuindo, assim, a carga de processamento entre eles. Scale-in (escalar para dentro) é a operação inversa, onde reduzimos o número de servidores ou réplicas no pool de máquinas. Em resumo, Scale-out (para fora) envolve o aumento do número de servidores, enquanto Scale-in (para dentro) envolve a diminuição desse número. Essas duas operações podem ser usadas em conjunto para ajustar dinamicamente a capacidade da carga de trabalho.
Planejamento de Capacidade e Escalabilidade
Neste tópico, vamos explorar uma das métricas essenciais para avaliar a capacidade e a escalabilidade de sistemas, além de como utilizar essas métricas em fórmulas para calcular os ajustes de capacidade que podem ser vinculados a estratégias de escalabilidade horizontal. Apresentaremos uma fórmula base que pode ser adaptada para uma variedade de cenários, ajudando a determinar a capacidade horizontal necessária para aplicações. Este exemplo é apenas uma das várias abordagens disponíveis no mercado, que atuam como mecanismos de escalabilidade automática de recursos. A fórmula base que apresentaremos a seguir foi retirada do funcionamento do “Horizontal Pod Autoscaler” ou “HPA” do Kubernetes, mas pode ser implementada independentemente em diversos contextos.
Vamos começar explorando vários cenários e métricas relevantes para monitorar a escalabilidade de um sistema. Em seguida, aplicaremos a fórmula para determinar a quantidade necessária de recursos computacionais, a fim de que um sistema possa se adaptar a um cenário de gargalo.
Fórmula Básica para Capacidade
Para compreender como os processos de escalonamento funcionam, utilizaremos a seguinte fórmula base. O objetivo é encontrar a quantidade ideal de réplicas para atender aos requisitos do sistema observado:
\begin{equation} \text{Réplicas Desejadas} = \text{Réplicas Atuais} \times \left( \frac{\text{Valor Atual da Variável}}{\text{Valor Desejado da Variável}} \right) \end{equation}
Inicialmente, essa fórmula pode parecer um tanto abstrata, mas exploraremos alguns exemplos para aplicá-la a diferentes cenários. Antes disso, é importante entender os termos usados na fórmula: “Réplicas Desejadas” representam a quantidade ideal de réplicas para o momento da aplicação; “Valor Desejado da Variável” é o valor que queremos que a métrica observada atinja; e “Valor Atual da Variável” é o valor atual dessa métrica. Vamos aprofundar o entendimento por meio de exemplos.
Utilização de Recursos Computacionais
Uma das maneiras mais simples de compreender o cálculo de capacidade é por meio da utilização de recursos computacionais, como CPU e memória. Essas métricas são comumente usadas para configurar processos de escalonamento automático de aplicações, devido à sua facilidade de cálculo, planejamento e monitoramento. O objetivo dessa abordagem é determinar o quanto de cada recurso (CPU, memória, disco, rede) está sendo utilizado. Uma utilização excessiva pode indicar um gargalo, e a fórmula nos ajudará a reajustar o sistema para contornar esse gargalo.
A fórmula básica aplicada a esse cenário seria:
\begin{equation} \text{Réplicas Desejadas} = \text{Réplicas Atuais} \times \left( \frac{\text{Utilização de CPU}}{\text{Utilização Desejada de CPU}} \right) \end{equation}
Antes de aplicarmos a fórmula, precisamos calcular a Utilização de CPU. Para isso, usaremos uma fórmula intermediária, onde dividimos a quantidade de recurso utilizado pela quantidade de recurso autorizado para uso, em relação a todos os recursos computacionais disponíveis. Vamos presumir que 1 core de CPU é composto por 1000m (milicores) para calcular a utilização. Esse exemplo é próximo das unidades utilizadas para capacidade de workloads em clusters de Kubernetes.
\begin{equation} \text{Utilização de Recurso} = \left( \frac{\text{Recurso Utilizado}}{\text{Recurso Disponível}} \right) \times 100 \end{equation}
Nesse cenário, vamos presumir o seguinte:
- Réplicas Atuais: 6 réplicas
- Recurso de Cada Réplica: Cada réplica pode utilizar 200m (200 milicores do sistema)
- Recurso Utilizado: 1200m (1200 milicores do sistema, ou 1 core e 200 milicores)
- Recurso Disponível: 600m (600 milicores do sistema)
- Utilização desejada de CPU: 80%
\begin{equation} \text{Utilização de CPU} = \left( \frac{1200m}{600m} \right) \times 100 \end{equation}
\begin{equation} \text{Utilização de CPU} = 200\% \end{equation}
Agora, com o valor de Utilização de CPU em 200%, podemos aplicá-lo à fórmula base, usando uma utilização desejada de 80% do uso da CPU e considerando as Réplicas Atuais como 6.
\begin{equation} \text{Réplicas Desejadas} = 6 \times \left( \frac{200}{80} \right) \end{equation}
\begin{equation} \text{Réplicas Desejadas} = 15 \end{equation}
Podemos concluir que, nesse cenário de avaliação, caso uma ação de reajuste na capacidade em escalabilidade horizontal fosse realizada, o ideal para contornar o gargalo devido à utilização de recursos de CPU seria aumentar o número de réplicas para 15 unidades. Essa lógica pode ser aplicada não apenas à CPU, mas também a qualquer outro tipo de recurso.
Requisições e Transações por Períodos de Tempo (Throughput)
Uma das minhas abordagens favoritas para planejar capacidade e desenvolver estratégias de escalabilidade horizontal é considerar a quantidade de requisições que a aplicação recebe dentro de um período de tempo. Essencialmente, essa estratégia se baseia na premissa de que cada réplica da aplicação pode processar um determinado número de requisições de forma independente, sem degradar o desempenho e o tempo de resposta. Em resumo, se cada réplica da nossa aplicação é capaz de suportar 10 transações por segundo (TPS) sem comprometer a performance e o tempo de resposta, e a aplicação está recebendo 100 transações por segundo, o ideal seria ter 10 réplicas disponíveis para atender à demanda.
A fórmula para calcular as réplicas desejadas é a seguinte:
\begin{equation} \text{Réplicas Desejadas} = \text{Réplicas Atuais} \times \left( \frac{\text{Requisições por Réplica}}{\text{Base de Requisições}} \right) \end{equation}
Nesse cenário, vamos presumir o seguinte:
- Réplicas Atuais: 6 réplicas
- Capacidade de Cada Réplica: Cada réplica pode lidar com 15 transações por segundo
- Total de Requisições Recebidas no Último Minuto: 10.000
Para aplicar a fórmula, precisamos primeiro calcular o valor das Requisições por Réplica. Para isso, dividimos o total de requisições recebidas no último minuto pelo período de tempo, que é 60 segundos, e depois dividimos esse valor pelo número de réplicas atualmente em uso.
\begin{equation} \text{Transações por Segundo} = \frac{\text{Total de Requisições Atendidas}}{\text{Período de Tempo}} \end{equation}
\begin{equation} \text{Transações por Segundo} = \frac{10.000}{60} \end{equation}
\begin{equation} \text{Transações por Segundo} = 166{,}66 \end{equation}
No exemplo, estamos recebendo uma média de 166,66 requisições por segundo em todo o sistema. Agora, para determinar a quantidade média de requisições que cada réplica da aplicação está recebendo, dividimos essa quantidade de transações pelo número atual de réplicas:
\begin{equation} \text{Requisições por Réplica} = \frac{\text{Transações por Segundo}}{\text{Réplicas Atuais}} \end{equation}
\begin{equation} \text{Requisições por Réplica} = \frac{166{,}66}{6} \end{equation}
\begin{equation} \text{Requisições por Réplica} = 27{,}78 \end{equation}
Agora temos todas as variáveis necessárias para aplicar a fórmula de capacidade e escalabilidade. Substituindo a variável Requisições por Réplica por 27{,}78 e a Base de Requisições por 15, que representa a quantidade desejada de requisições por réplica sem maiores problemas, podemos calcular a quantidade ideal de réplicas:
\begin{equation} \text{Réplicas Desejadas} = 6 \times \left( \frac{27{,}78}{15} \right) \end{equation}
\begin{equation} \text{Réplicas Desejadas} = 11 \end{equation}
Com base nesse exemplo, podemos concluir que, em uma operação de reajuste de capacidade com foco na escalabilidade horizontal, o número ideal de réplicas a serem definidas para a aplicação seria 11 unidades.
Escalabilidade de Software
Como mencionado anteriormente, o conceito de escalabilidade vai muito além do ajuste elástico da infraestrutura para lidar com demandas específicas. A escalabilidade é amplamente aplicada na arquitetura de software e desempenha um papel que está intimamente ligado à escalabilidade de software como um todo. É um erro associar conceitos de escalabilidade apenas a componentes e dependências de infraestrutura. Olhar para a escalabilidade ao projetar um software, considerando a arquitetura, as necessidades e os fluxos de negócios, é uma abordagem inteligente para criar soluções modernas sem aumentar exponencialmente os custos operacionais.
Uma das abordagens mais diretas para melhorar o desempenho é otimizar os algoritmos no código existente. Isso envolve refinar os algoritmos para reduzir a complexidade computacional, eliminar gargalos de processamento, melhorar a eficiência no uso da memória e avaliar oportunidades de paralelismo e tarefas concorrentes.
A otimização de esquemas de banco de dados, índices e consultas pode reduzir significativamente o tempo de resposta e aumentar a capacidade e a escalabilidade de um sistema. O mesmo se aplica à distribuição de carga entre vários servidores disponíveis que são capazes de processar uma tarefa. Considere o uso de bancos de dados NoSQL ou soluções de armazenamento distribuído para cenários de alta demanda. Implementar caching onde for apropriado pode reduzir significativamente o tempo de resposta e a carga nos sistemas de backend. Isso pode incluir caching em memória, caching distribuído e otimizações de cache no lado do cliente. Para o processamento de tarefas intensivas ou operações de I/O, usar filas e mensagens assíncronas para distribuir a carga e melhorar a eficiência geral do sistema é uma estratégia eficaz.
Existem muitas possibilidades relacionadas à escalabilidade e, ao integrar essas estratégias ao desenvolvimento e à manutenção de software, é possível criar sistemas não apenas mais escaláveis, mas também mais eficientes e confiáveis. Isso requer um compromisso contínuo com a qualidade do código, a arquitetura do sistema e o monitoramento contínuo, garantindo que o sistema possa se adaptar e evoluir com as crescentes demandas
Obrigado aos Revisores
Imagens geradas pelo DALL-E e Bing
Referências
Test of the New Infortrend CS Scale-Out NAS Cluster (Part 1)
Horizontal Pod Autoscaling - Algorithm details
HorizontalPodAutoscaler Walkthrough
Livro: Release It: Design and Deploy Production-Ready Software
Kubernetes Instance Calculator
CSE 567-13-01A Course Overview: The Art of Computer Systems Performance Analysis
Backpressure explained — the resisted flow of data through software
AppDynamics: Percentiles Made Easy
Dynatrace: Why averages suck and percentiles are great
Response times and what to make of their percentile values
Um mergulho profundo na lei de Amdahl e na lei de Gustafson
DevOps Monitoring Guide — How to manage the 4 Golden Signals
The four Golden Signals of Monitoring
Livro: Engenharia de Confiabilidade do Google: Como o Google Administra Seus Sistemas de Produção
