
System Design - Protocolos e Comunicação de Rede

Neste capítulo, abordaremos de forma simplificada os conceitos essenciais dos principais tópicos de comunicação de rede sob a perspectiva de System Design. Compreender os protocolos de comunicação é de extremo valor e pode representar um divisor de águas para aprimorar tópicos de performance e resiliência. Entender os fundamentos de protocolos como TCP e UDP, assim como outros que são desenvolvidos a partir deles, nos capacita a tomar decisões arquiteturais, projetar estratégias eficazes, melhorar níveis de performance e tempo de resposta ao aplicar suas características mais vantajosas de maneira adequada.
Observando meus colegas e profissionais de engenharia com quem tive a oportunidade de trabalhar ao longo dos anos, percebi que o entendimento da camada de rede frequentemente representa uma lacuna significativa no entendimento da topologia de sistemas. Este artigo é baseado em discussões e sessões de design das quais tive o prazer de participar ao longo desses anos, compilando de maneira acessível os tópicos práticos e teóricos mais relevantes. O objetivo é que a informação aqui apresentada seja facilmente compreendida e aplicada no cotidiano daqueles que dedicarem tempo a esta leitura. Espero que encontrem grande valor neste conteúdo.
Modelo OSI
O Modelo OSI (Open Systems Interconnection) é um modelo conceitual desenvolvido pela International Organization for Standardization (ISO) na década de 1980, com o objetivo de padronizar as funções de sistemas de telecomunicações, componentes de rede e protocolos. Representando uma abstração com base acadêmica, o modelo serve como fundamento para o entendimento de redes de alta disponibilidade, especificação de componentes de rede, além de troubleshooting de protocolos de comunicação e conexões entre serviços. É importante compreender como funciona esse modelo teórico antes de entrarmos, de fato, em implementações de protocolos, para conseguirmos mentalmente classificar onde cada um deles opera entre as camadas propostas por ele. Normalmente, as camadas mais altas do modelo são implementadas com base em software.
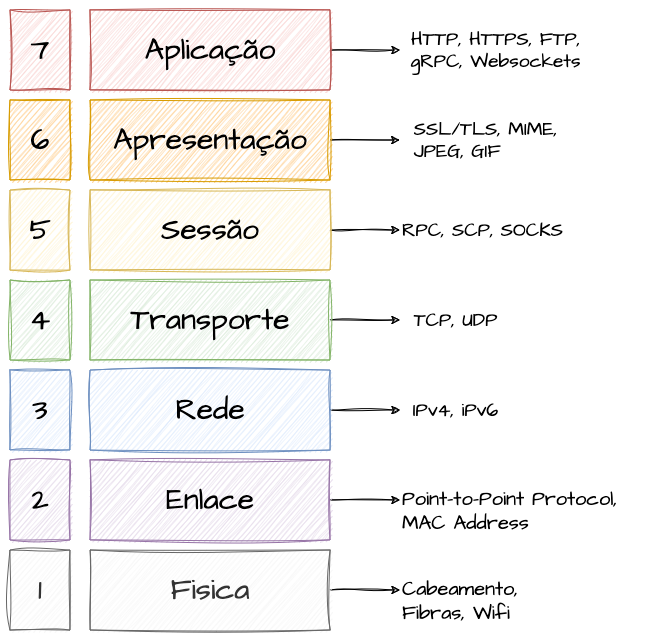
O Modelo OSI é dividido em sete camadas, cada uma responsável por funções específicas:
Camada 1: Física
A primeira camada é responsável pela transmissão e recepção de dados brutos não tratados sobre um meio físico. Define especificações elétricas, mecânicas, procedurais e funcionais para ativar, manter e desativar conexões físicas. Inclui cabos de rede, cabos de cobre, fibra óptica e tecnologias Wi-Fi, englobando todos os meios físicos de entrada e saída para a rede. Basicamente resumida em dispositivos palpáveis.
Camada 2: Enlace
A segunda camada fornece transferência de dados confiável entre dois componentes de rede adjacentes, detectando e corrigindo erros do nível físico. Inclui implementações de Ethernet para transmissão de dados em LANs, PPP (Point-to-Point Protocol) para conexões diretas entre dois nós e seus endereços físicos (MAC Address), que identificam dispositivos de forma única.
Camada 3: Rede
A terceira camada controla a operação da sub-rede, decidindo o encaminhamento de dados com base nos endereços lógicos e nas condições das redes. Utiliza roteamento para enviar pacotes através de múltiplas redes, com protocolos como IP, fornecendo endereçamento lógico através de IPv4 e IPv6. O protocolo ARP usa uma abordagem de broadcast, permitindo que dispositivos em uma rede descubram o endereço MAC (físico) associado a um endereço IP (lógico), o que é essencial para o encaminhamento de pacotes da camada de rede para a camada de enlace de dados.
Camada 4: Transporte
Gerencia a transferência de dados entre sistemas finais, segmentando dados em pacotes e controlando o fluxo de tráfego. Destacam-se os protocolos TCP, que entregam pacotes de forma confiável e ordenada, e UDP, que oferece conexões rápidas, porém menos confiáveis.
Camada 5: Sessão
Responsável por iniciar, gerenciar e finalizar conexões entre aplicações, sendo frequentemente utilizada em serviços com conexões autenticadas de longa duração.
Camada 6: Apresentação
Traduz dados do formato da rede para o formato aceito pelas aplicações, realizando criptografia, compressão e conversão de dados. Funciona como uma “Camada de Tradução”, implementando protocolos de segurança como SSL/TLS e suportando formatos de dados como JPEG, GIF e PNG.
Camada 7: Aplicação
Fornece serviços de rede para aplicações do usuário, incluindo transferência de arquivos e conexões de software. É a camada mais próxima do usuário, atuando como interface entre o software de aplicação e as funções de rede. Implementa protocolos como HTTP, HTTPS, WebSockets, gRPC, além de suportar sessões de SSH e transferências FTP.
Os Protocolos de Comunicação
Entrando agora, de fato, nos protocolos de comunicação, vamos entender algumas das implementações mais importantes e comuns dentro do dia a dia da engenharia de software e de usuários de aplicações de rede, resumidamente qualquer pessoa do planeta Terra que possua conexões com a internet. Temos várias implementações diferentes, com diversas vantagens e desvantagens quando olhamos um mapa de protocolos existentes, ainda levando em consideração que alguns protocolos são construídos utilizando outros protocolos mais estabelecidos como base, como é o caso do UDP e do TCP. Inicialmente, vamos olhar como funcionam essas duas implementações, tratando os mesmos como protocolos base, para depois detalhar protocolos mais complexos que se utilizam deles para cumprir seus papéis.
Definindo um Protocolo
A comunicação entre dispositivos é o objetivo principal do funcionamento de uma rede, interna ou externa. Na construção dessa comunicação, está um conjunto de regras e padrões conhecidos como protocolos. Um protocolo é, conceitualmente, um acordo que define o formato e a sequência das mensagens trocadas entre dois ou mais sistemas. Essas regras determinam como os dados são enviados, recebidos e interpretados, garantindo que as informações sejam compartilhadas de maneira compreensível entre dispositivos distintos e aplicações de software.
Protocolos Base
Para compreender detalhadamente os protocolos e tecnologias de comunicação modernas, é importante primeiro revisitar os protocolos de rede de baixo nível que servem como sua base. Antes de explorar protocolos como HTTP/2, HTTP/3, gRPC e AMQP, precisamos entender os mecanismos de conexão fundamentais, principalmente o TCP e o UDP, que são essenciais para o desenvolvimento dessas tecnologias avançadas.
Protocolo IP, IPv4 e IPv6
O Protocolo de Internet (IP) opera na camada de rede do modelo OSI (camada 3) e é o coração da comunicação de dados na Internet, permitindo que dispositivos diferentes se conectem e compartilhem informações em uma rede interna ou externa. Este protocolo define endereços IP únicos para cada dispositivo na rede, garantindo que os dados enviados de um ponto cheguem corretamente ao seu destino. Existem duas versões principais deste protocolo em uso: IPv4 e IPv6.
IPv4
IPv4, ou Internet Protocol version 4, é a versão mais antiga e ainda a mais utilizada do protocolo IP. Ela utiliza um formato de endereço de 32 bits, o que resulta em cerca de 4,3 bilhões de endereços IP possíveis, ou exatamente 4.294.967.296 endereços possíveis. Embora este número possa parecer grande, no início da Internet, grandes blocos de endereços IP foram distribuídos para empresas, universidades e agências governamentais. Com o crescimento da Internet, o aumento no número de dispositivos conectados esgotou os endereços IPv4 disponíveis, levando à necessidade de uma solução mais robusta. O IPv4 suporta várias técnicas para mitigar a escassez de endereços, incluindo NAT (Network Address Translation) e a alocação de IPs privados para redes locais.
{kind=link}
IPv6
IPv6, ou Internet Protocol version 6, foi desenvolvido para resolver o problema da escassez de endereços do IPv4. Com um formato de endereço de 128 bits, o IPv6 possui um espaço de endereçamento praticamente ilimitado, oferecendo trilhões de trilhões de endereços IP, chegando ao número de 340.282.366.920.938.463.463.374.607.431.768.211.456 endereços. Esta expansão não apenas resolve o problema de escassez de endereços, mas também simplifica o processamento de pacotes em roteadores e oferece melhor segurança integrada, com suporte nativo para criptografia e comunicações seguras através do IPsec (Internet Protocol Security).
Dual Stack
A comunicação entre redes que utilizam IPv4 e IPv6, dois esquemas de endereçamento IP distintos, obrigatoriamente requer um mecanismo de transição ou interoperação, pois os dois protocolos são incompatíveis em termos de endereçamento direto. Para esse tipo de cenário, onde os dois protocolos precisam coexistir, a estratégia de Dual Stack pode ser utilizada.
Com essa configuração, um dispositivo pode se comunicar tanto com redes IPv4 quanto com redes IPv6, escolhendo o protocolo apropriado com base no destino da comunicação. Essa é considerada uma das soluções mais simples e eficazes para a transição, mas requer que o hardware e o software suportem ambos os protocolos.
UDP - User Datagram Protocol
O UDP, ou User Datagram Protocol, é um protocolo da camada de transporte (camada 4) notavelmente simples, que possibilita a transmissão de dados entre hosts na rede de maneira não confiável e sem a necessidade de estabelecer uma conexão prévia. Diferentemente de outros protocolos de rede, o UDP sacrifica a confiabilidade em favor da performance, eliminando o processo de estabelecimento, manutenção, gerenciamento e encerramento de conexões. Isso permite que os dados sejam enviados ao destinatário sem o custo desse processamento extra, mas sem garantias de recebimento ou integridade.
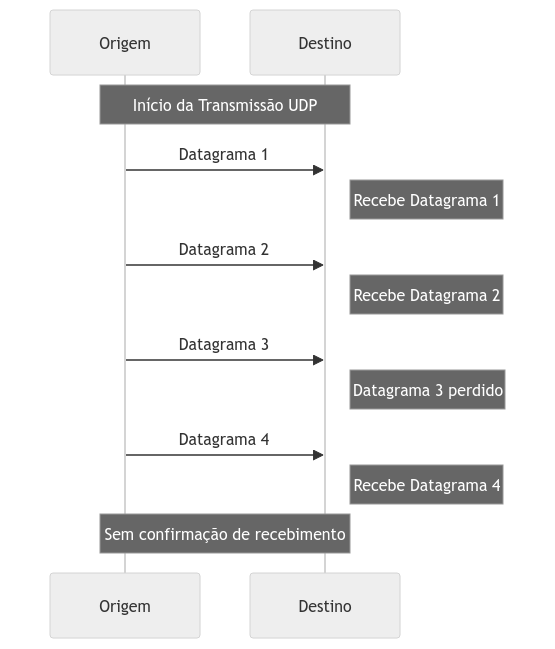
O protocolo UDP segmenta os dados a serem enviados em pacotes menores chamados Datagrams. Utilizando Datagramas, o UDP permite a transmissão de dados independentes que não requerem entrega em uma ordem ou prioridade específica, nem dependem de confirmação de recebimento. Essa característica torna o UDP adequado para aplicações que demandam comunicação em tempo real, mas que podem tolerar certa perda ou corrupção de dados.
Protocolos e arquiteturas que exigem envio e recebimento de dados com complexidade próxima ao tempo real, e que podem suportar perdas e corrupções, geralmente são construídos sobre o UDP. Analogamente, o funcionamento do UDP pode ser comparado a entregadores que deixam correspondências debaixo do portão, na calçada ou na janela das casas, prosseguindo para as próximas entregas sem confirmar se o destinatário recebeu a mensagem.
TCP - Transmission Control Protocol
Diferentemente do UDP, o TCP (Transmission Control Protocol) é um protocolo orientado à conexão. Ele é responsável por abrir, manter, verificar a saúde e encerrar a conexão, assegurando que os dados enviados cheguem ao destino de forma íntegra, confiável e na ordem correta. Atuando na Camada de Transporte (camada 4), o TCP estabelece uma conexão antes de qualquer transmissão de dados entre os hosts, utilizando mecanismos de controle de erro e de fluxo para garantir a correta ordem e a integridade dos dados enviados.
O modelo TCP emprega termos como ACK, SYN, SYN-ACK e FIN para descrever o gerenciamento de suas conexões. Existem outras flags, como URG, PSH e RST, mas focaremos em um fluxo simplificado para entender como uma conexão TCP funciona.

Todas as ações dentro do ciclo de vida de uma conexão TCP são confirmadas por ACKs (Acknowledgments).
O início de uma conexão TCP exige uma série de confirmações entre o cliente e o servidor para assegurar sequencialidade e confiabilidade. Esse processo é conhecido como “three-way handshake”, ilustrado pela sequência de três ações: SYN, SYN-ACK e ACK, daí o termo “three-way handshake”.
No início, o cliente inicia o processo enviando um segmento TCP com a flag SYN (synchronize) marcada para o servidor, indicando a intenção de estabelecer uma conexão. Este processo inicial envolve um número de sequência conhecido como ISN (Initial Sequence Number), utilizado para sincronização e controle de fluxo.
Após este primeiro contato, o servidor responde ao cliente com um segmento TCP contendo as flags SYN e ACK (acknowledgment). O ACK confirma o recebimento do SYN do cliente, enquanto o SYN do servidor indica sua própria solicitação de sincronização, efetivamente repetindo o processo, mas na direção inversa. Este segmento inclui tanto o número de sequência do servidor quanto o número de reconhecimento, que é o ISN do cliente incrementado de um.
Após receber o SYN do servidor, o cliente envia um segmento de ACK de volta ao servidor, confirmando o recebimento do SYN-ACK do servidor. Este ACK também contém o número de sequência inicial do cliente (agora incrementado) e o número de sequência inicial do servidor incrementado de um. Com este passo, a conexão é formalmente estabelecida, permitindo que os dados comecem a ser transmitidos.
Com a conexão estabelecida, os dados são enviados entre cliente e servidor em segmentos TCP. Cada segmento é numerado sequencialmente, possibilitando que o receptor reordene segmentos que cheguem fora de ordem e detecte quaisquer dados perdidos. O receptor envia um ACK para cada segmento recebido, indicando o próximo número de sequência que espera receber. Segmentos que não são confirmados com um ACK são enviados novamente, garantindo assim a entrega confiável e a integridade dos dados.
Para encerrar uma conexão TCP, ambas as partes devem fechar a sessão em sua respectiva direção através de um processo conhecido como “four-way handshake”. O cliente inicia o encerramento enviando um segmento com a flag FIN marcada, sinalizando que não tem mais dados a enviar. Após receber um ACK do servidor e um segmento com a flag FIN, indicando que o servidor também concluiu a transmissão de dados, o cliente envia o último ACK, finalizando a conexão.
Comparado ao UDP, o TCP oferece maior confiabilidade, embora com mais burocracia, o que pode resultar em uma velocidade reduzida. A maioria dos protocolos de comunicação entre serviços e componentes de software é construída sobre o TCP, justamente pela sua confiabilidade.
Analogamente, se o protocolo UDP pode ser comparado a um entregador que deixa correspondências sem confirmação de recebimento, o TCP seria como um entregador que exige sua assinatura, foto e confirmação pessoal para entregar a correspondência em mãos.
Escolhendo Entre TCP e UDP para Construção e Uso de Protocolos
A decisão entre usar UDP ou TCP para desenvolver protocolos depende das exigências específicas da aplicação quanto à confiabilidade, ordem, integridade dos dados e eficiência. O UDP é preferido para aplicações que demandam entrega rápida de dados e podem tolerar perdas de pacotes, enquanto o TCP é escolhido para aplicações que requerem entrega de dados confiável e ordenada. Essas características são de extrema importância ao implementar soluções que dependem de conexões de rede eficientes e confiáveis para cumprir seus objetivos.
SSL/TLS - Transport Layer Security
O TLS (Transport Layer Security) é um protocolo crítico para a segurança na internet e em redes corporativas, projetado para prover comunicação segura entre cliente e servidor. Sucessor do SSL (Secure Sockets Layer), seu objetivo principal é assegurar a privacidade e a integridade dos dados durante a transferência de informações entre sistemas, através de criptografia, garantindo que os dados enviados de um ponto a outro na rede permaneçam inacessíveis a interceptadores.
O funcionamento do TLS se dá por meio de um “handshake”, onde cliente e servidor estabelecem parâmetros da sessão, como a versão do protocolo e os métodos de criptografia a serem utilizados, por meio de uma troca de chaves públicas e privadas. Essa troca resulta na criação de uma chave de sessão única, utilizada para criptografar os dados transmitidos, assegurando assim a segurança da comunicação. Ao término da sessão, a comunicação pode ser finalizada de forma segura, com a possibilidade de renegociar os parâmetros para futuras sessões.
Existem várias versões do TLS, com aprimoramentos contínuos em segurança e desempenho. As versões mais adotadas atualmente são TLS 1.2 e TLS 1.3, sendo esta última a mais recente e segura, oferecendo vantagens como um processo de “handshake” mais ágil e eficiente em comparação com as versões anteriores.
Demais Protocolos e Aplicações de Rede
Os Protocolos de Aplicação são uma parte importante da arquitetura de redes internas e externas, permitindo a comunicação entre diferentes sistemas e aplicações que possuem padrões específicos que precisam ser respeitados. Eles definem um conjunto de regras e padrões que governam a troca de dados entre servidores e clientes em uma gama muito grande de contextos. Esses protocolos operam na camada mais alta do modelo OSI, a Camada de Aplicação, onde o foco se desloca da transferência de dados pura para a maneira como os dados são solicitados e apresentados ao usuário, de acordo com a tecnologia utilizada.
Se, devido a alguma necessidade específica de tecnologia, você precisa implementar seu próprio protocolo de comunicação, criando suas próprias regras, validações e comportamentos utilizando como base protocolos básicos como TCP e UDP, esse protocolo pode ser considerado pertencente à camada de aplicação. Se você está utilizando um protocolo específico para troca de mensagens assíncronas, esse protocolo de comunicação entre o cliente e o servidor de mensagens, por ser algo construído sobre uma comunicação TCP, está na camada de aplicação. Vamos entender algumas das principais tecnologias e protocolos que funcionam nessa camada, que tende a ser a mais presente no dia a dia da engenharia e na construção de soluções de praticamente todos os tipos de arquitetura. A tendência é que vários deles, além deste capítulo, sejam abordados de forma mais detalhada, como veremos nos capítulos de mensageria e comunicações síncronas. Nesta sessão, o objetivo é detalhar outros protocolos comuns presentes na grande maioria das implementações arquiteturais de redes.
DNS - Domain Name System
O Sistema de Nomes de Domínio, ou Domain Name System (DNS), é uma premissa fundamental da internet, atuando como uma “lista telefônica” da internet e da sua rede interna. Sem o DNS, teríamos que memorizar os endereços IP complexos para acessar sites, o que seria impraticável tanto em IPv4 quanto praticamente impossível em IPv6. Em vez disso, o DNS nos permite digitar nomes de domínio amigáveis, como fidelissauro.dev, e automaticamente encontrar o endereço IP correto para se conectar ao site ou host desejado.
Funcionamento Lógico do DNS
O processo do DNS começa quando você digita um URL no seu navegador. O navegador consulta um servidor DNS para encontrar o endereço IP correspondente ao nome do domínio. Este processo envolve várias etapas:
Consulta ao DNS Local: Primeiro, o navegador verifica se o endereço IP está armazenado em cache localmente. Se não estiver, a consulta é enviada ao DNS Resolver, geralmente fornecido pelo seu provedor de internet.
Resolver para Servidores Raiz: O Resolver consulta um dos servidores raiz do DNS para descobrir quem gerencia o TLD (top-level domain, como .com, .net, .org) do domínio solicitado.
Consulta aos Servidores de Nomes de Domínio (TLD Servers): O servidor TLD aponta para o servidor de nomes autoritativo do domínio, que conhece o endereço IP correspondente.
Resolução do DNS na Prática
“O que acontece quando você digita google.com no seu navegador?” — essa pergunta ganhou até um aspecto cômico nas entrevistas de system design nos últimos anos. Mas a ideia é propor um case prático para finalmente respondê-la de forma completa, aproveitando o que já entendemos sobre o DNS. O que aconteceria se digitássemos https://demo.fidelissauro.dev no navegador?
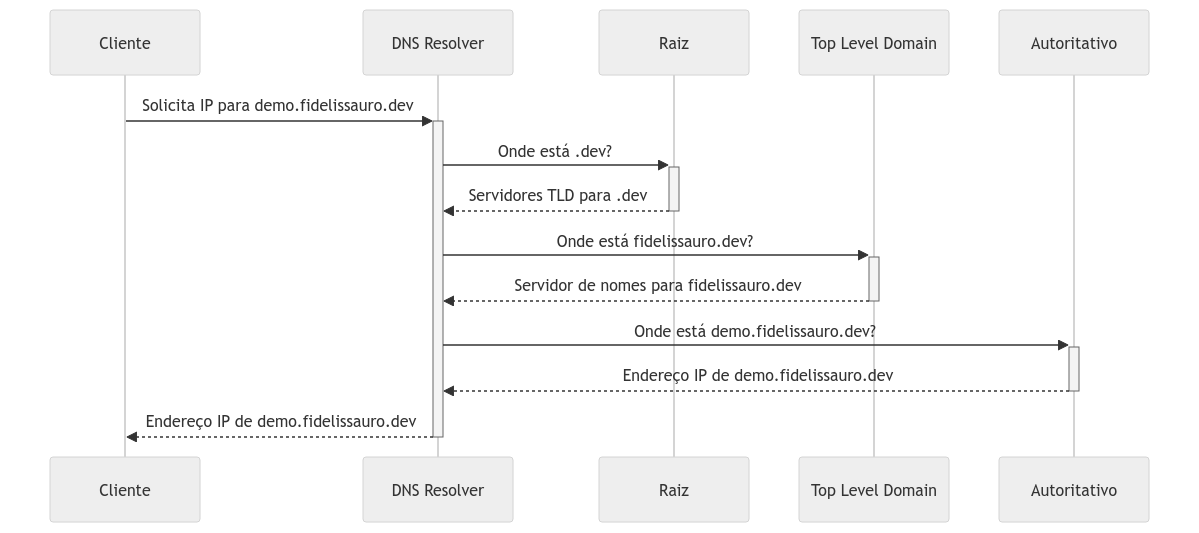
1. Consulta ao Servidor Raiz: Tudo começa com os servidores raiz do DNS. Existem 13 conjuntos de servidores raiz DNS, identificados de a.root-servers.net até m.root-servers.net, que são a base da hierarquia do DNS e representam o ponto final de cada endereço DNS, que são abstraídos ao máximo, mas que, na verdade, existem. Sim, no caso, o google.com na verdade é o google.com..
Quando um resolver DNS (geralmente operado por seu provedor de internet) precisa resolver demo.fidelissauro.dev, ele começa perguntando a um desses servidores raiz (.) onde encontrar informações sobre o TLD (top-level domain), que neste caso é .dev..
- "Olá root server (.), por um acaso você conhece quem é o .dev.?
- Claro, os servidores DNS desse cara são os seguintes: xx.xx.xx.xx"
- Ok, muito obrigado!
2. Consulta ao Servidor Top-Level Domain para .dev: O servidor raiz responde com o endereço dos servidores DNS responsáveis pelo TLD .dev. O resolver então faz uma consulta a um desses servidores para encontrar quem controla o domínio fidelissauro.dev.
- "Olá senhor TLD do .dev., por um acaso você conhece quem é o fidelissauro.dev?
- "Conheço sim, gente fina! Você pode encontrá-lo no servidor de DNS xx.xxx.xx.xxx"
- "Muito agradecido!
3. Consulta ao Servidor de Nomes Autoritativo para fidelissauro.dev: Os servidores de Top-Level Domain respondem com o endereço dos servidores de nomes (DNS servers) autoritativos para fidelissauro.dev. Esses servidores de DNS autoritativos são responsáveis por conhecer todos os detalhes sobre o domínio, incluindo os endereços IP de quaisquer subdomínios. O resolver então pergunta a eles onde encontrar demo.fidelissauro.dev.
- "Olá senhor fidelissauro.dev., o demo.fidelissauro.dev está? Gostaria de falar com ele
- Você pode encontrá-lo no endereço 123.123.123.123, mande um abraço!
- Certo, vou me conectar com ele!
4. Conexão de Fato: Após o servidor autoritativo finalmente responder onde o host demo.fidelissauro.dev está, o cliente pode se conectar com o serviço de fato. Este processo é otimizado por meio de cache em vários níveis. Resolvers de DNS, navegadores e até mesmo os próprios servidores de nomes armazenam respostas de consultas anteriores para reduzir a latência e o tráfego na rede. Ao acessar um domínio frequentemente, é provável que as informações de DNS já estejam armazenadas em cache, acelerando significativamente o processo de resolução e evitando a repetição de todo esse fluxo.
DHCP - Dynamic Host Configuration Protocol
O Protocolo de Configuração Dinâmica de Host (Dynamic Host Configuration Protocol) é um protocolo de rede que permite a servidores com essa responsabilidade designar automaticamente um endereço IP e outras informações a dispositivos que se conectam à rede. O DHCP é usado para a gestão de endereços IP em redes grandes e pequenas, facilitando a conectividade e reduzindo conflitos de endereços. É utilizado principalmente em projetos de networking que possibilitam a entrada e saída de hosts com certa frequência, sem a necessidade de alocar IPs fixos e evitando conflitos de dois dispositivos tentarem utilizar o mesmo IP.
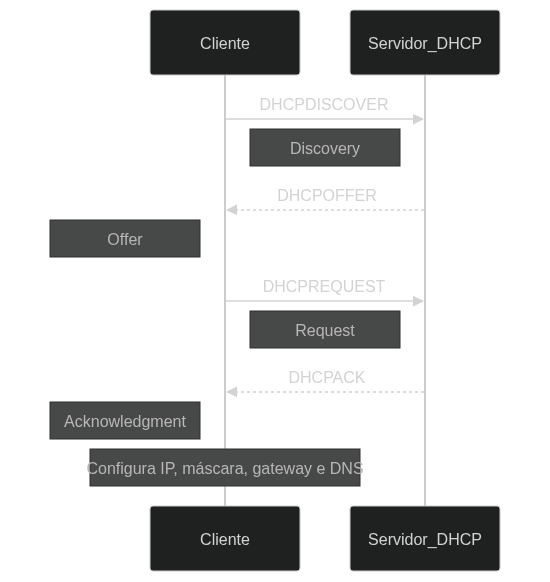
Quando um dispositivo — cliente DHCP — se conecta a uma rede, ele solicita informações de configuração de rede a um servidor DHCP. O processo segue quatro etapas básicas, conhecidas como DORA (Discovery, Offer, Request, Acknowledgment).
1. Discovery: O cliente envia um pacote DHCPDISCOVER para a rede, procurando por servidores DHCP disponíveis.
2. Offer: Servidores DHCP na rede respondem ao cliente com um pacote DHCPOFFER, oferecendo um endereço IP disponível e outras configurações de rede.
3. Request: O cliente responde a uma das ofertas com um pacote DHCPREQUEST, indicando sua intenção de aceitar os parâmetros oferecidos por um servidor específico.
4. Acknowledgment: O servidor confirma a alocação do endereço IP ao cliente com um pacote DHCPACK, completando o processo de configuração.
O DHCP elimina a necessidade de configurar manualmente os parâmetros de rede em cada dispositivo, gerenciando dinamicamente o pool de endereços IP e reutilizando endereços de dispositivos que não estão mais na rede. É um protocolo “default” que já é abstraído em players de nuvem pública, mas tende a ser considerado quando precisamos projetar soluções em nível de networking além do software. Na sua casa, o seu roteador Wi-Fi provavelmente está atuando como um servidor DHCP. Sem ele, você precisaria configurar manualmente o IP de cada dispositivo que se conecta à rede.
NTP - Network Time Protocol
O Network Time Protocol (NTP) é um protocolo de rede utilizado para sincronizar relógios de computadores através de redes de dados com latências variáveis. Ele opera dentro da camada de aplicação do conjunto de protocolos da Internet, utilizando o protocolo de transporte UDP na porta 123. Ele é construído sobre uma arquitetura cliente-servidor, onde múltiplos clientes (computadores que precisam de sincronização de tempo) fazem requisições a um ou mais servidores NTP. Esses servidores estão conectados a fontes de tempo de alta precisão, como relógios atômicos, GPS ou rádio-relógios.
A precisão do tempo é crítica para muitas aplicações em redes de computadores. Transações financeiras, comunicações seguras, sistemas de banco de dados distribuídos e redes de telecomunicações são apenas alguns exemplos onde a sincronização de relógios entre diferentes sistemas é vital. O NTP permite que essas aplicações funcionem de forma coesa, garantindo que todos os sistemas estejam “no mesmo tempo”, evitando problemas de ordem de operações, registros de log inconsistentes e falhas de segurança.
SSH - Secure Shell
O SSH (Secure Shell) é um protocolo de rede criptográfico utilizado para comunicação e operações de rede seguras. O SSH permite o acesso controlado e criptografado a dispositivos remotos, sendo o método padrão para administração remota de sistemas Linux/Unix, junto a uma ampla gama de dispositivos de rede. Além do acesso remoto, o SSH pode criar túneis seguros para encapsular outros protocolos de rede, permitindo a segurança de transferências de arquivos (via SCP ou SFTP), encaminhamento de portas, entre outros.
O SSH é o protocolo mais utilizado por administradores de sistema para configuração e manutenção de servidores, e existem ferramentas de gestão de configuração que utilizam o SSH para conectar, configurar e gerenciar o estado dos hosts em escala.
O SSH opera na camada de aplicação, utilizando o protocolo TCP, geralmente na porta 22. Ele emprega uma combinação de criptografia assimétrica para o estabelecimento de conexão e troca de chaves, e criptografia simétrica para a sessão de comunicação propriamente dita, garantindo confidencialidade, integridade dos dados e autenticação.
1. Estabelecimento de Conexão: O cliente SSH inicia uma conexão com o servidor. Eles negociam a versão do protocolo, um algoritmo de criptografia compartilhado e trocam chaves públicas.
2. Autenticação: O usuário no cliente SSH é autenticado pelo servidor. Isso pode ser feito através de senha, chaves de criptografia públicas/privadas ou métodos de autenticação mais avançados, como Kerberos.
3. Sessão Segura: Uma vez autenticados, cliente e servidor estabelecem um canal criptografado. Comandos e dados podem então ser trocados com segurança, com a criptografia protegendo contra a interceptação e alteração dos dados.
Telnet
Telnet é um protocolo de rede utilizado para proporcionar uma comunicação baseada em texto interativa bidirecional e permite aos usuários acessar e gerenciar remotamente dispositivos ou servidores através da Internet ou redes locais. Apesar de ter sido amplamente substituído por protocolos mais seguros, como SSH, Telnet ainda é usado em certos contextos, especialmente em ambientes de teste, educação e em sistemas legados, ou para testes de conexões de rede.
Telnet opera na camada de aplicação e utiliza o protocolo TCP para estabelecer uma conexão entre o cliente e o servidor. O protocolo é projetado para funcionar de forma independente da plataforma, o que significa que não existem limitações de versões, sistemas operacionais e afins.
O uso do Telnet não é recomendado para execução de manutenções e configurações de fato, mas é uma ótima ferramenta de troubleshooting de rede e testes de conectividade em portas específicas.
A principal limitação do Telnet é sua falta de segurança. O protocolo não possui nenhum mecanismo de criptografia, o que significa que todas as informações, incluindo nomes de usuário, senhas e outros dados sensíveis, são transmitidas em texto claro. Isso torna o Telnet extremamente vulnerável a interceptações e ataques de “man-in-the-middle”, onde um atacante pode facilmente capturar e ler os dados transmitidos.
Protocolos HTTP/1, HTTP/2 e HTTP/3
Ao examinar o protocolo HTTP (Hypertext Transfer Protocol) sob a perspectiva de System Design, é importante entender seu impacto na arquitetura, desempenho, escalabilidade e segurança de aplicações modernas. Operando na Camada 7 do Modelo OSI, ou Camada de Aplicação, o HTTP é predominantemente baseado em conexões TCP para gerenciar solicitações, constituindo a espinha dorsal da internet e da comunicação entre sistemas modernos, com exceção do HTTP/3 que é baseado em UDP pelo protocolo QUIC.
O HTTP/2 e HTTP/3 representam evoluções do protocolo HTTP, criadas para melhorar a eficiência da comunicação, reduzir latências e otimizar o desempenho em relação às versões anteriores, HTTP/1.1 e HTTP/1.0. Essas versões iniciais dominaram a internet e as redes corporativas por muitos anos.
O HTTP opera em um modelo de solicitação e resposta entre cliente e servidor, onde o cliente faz uma solicitação e o servidor responde. Este paradigma é simples, extensível e compatível com várias arquiteturas de aplicação, incluindo sistemas monolíticos e microserviços. Contudo, a natureza síncrona do HTTP pode introduzir latência e impacto no tempo de resposta em troca da simplicidade de implementação, exigindo otimizações para aprimorar o desempenho das solicitações em ambientes de larga escala.
A escolha de utilizar o protocolo HTTP para comunicação em decisões de engenharia permeia arquiteturas que precisam de uma resposta síncrona de suas dependências, onde sistemas dependentes necessitam que um dado ou ação sejam executados e entregues no momento em que são solicitados, sem a possibilidade de serem executados por um comando ou solicitação assíncrona. Estenderemos essa explicação no capítulo que trata padrões de comunicação, onde abordaremos temas como o REST.
Estruturas de Requisições e Respostas HTTP
Entender a estrutura de uma requisição HTTP é fundamental na arquitetura de sistemas. Embora simples e comum na rotina de engenheiros e arquitetos, compreender detalhadamente suas partes pode facilitar troubleshooting, melhorar a segurança e otimizar a performance. Vamos explorar os principais componentes: Body, Headers, Cookies e Status Codes.
Body
O Body, ou corpo, de uma requisição ou resposta HTTP contém os dados transmitidos entre cliente e servidor. Em requisições, o body pode incluir informações para que o servidor execute funções específicas, como detalhes de um formulário, payloads em JSON ou arquivos de mídia. Na resposta, geralmente contém o recurso solicitado pelo cliente, seja um documento HTML, um objeto JSON ou outros formatos de dados, definidos pelos headers de Content-Type.
Headers
Os Headers, ou cabeçalhos, são elementos presentes tanto em requisições quanto em respostas, fornecendo informações e metadados sobre a transação HTTP em que estão inseridos. Podem especificar o tipo de conteúdo no body (Content-Type), a autenticação necessária (Authorization), instruções de cache (Cache-Control), entre outros metadados. Os headers são fundamentais para configurar e controlar a comunicação HTTP, enriquecendo a interação entre cliente e servidor com informações detalhadas sobre a transação.
A possibilidade de criação dos headers que vão trafegar entre cliente e servidor fica a cargo do direcionamento de engenharia e não precisa necessariamente ser descrita em ordem, nem possuir uma obrigatoriedade ou padrão formal. Porém, por convenção, alguns deles são extremamente comuns e estão presentes na maioria das aplicações. Alguns deles são:
| Header | Descrição |
|---|---|
Accept |
Especifica os tipos de mídia que o cliente pode processar. |
Authorization |
Contém as credenciais para autenticar o cliente no servidor. |
Content-Type |
Indica o tipo de mídia do corpo da requisição ou resposta. |
Cache-Control |
Diretivas para mecanismos de cache tanto nas requisições quanto nas respostas. |
Cookie |
Envia os cookies armazenados no navegador para o servidor. |
Set-Cookie |
Direciona o navegador para armazenar o cookie e enviá-lo em requisições subsequentes ao domínio. |
Host |
Especifica o domínio do servidor (e possivelmente a porta) à qual a requisição está sendo enviada. |
User-Agent |
Contém uma string característica que permite ao servidor identificar o tipo de cliente (navegador ou bot, por exemplo). |
Content-Length |
O tamanho do corpo da requisição ou resposta em bytes. |
Location |
Indica o URL para o qual uma navegação deve ser redirecionada. |
Referer |
Indica o endereço da página web anterior (origem da solicitação). |
Accept-Encoding |
Indica quais codificações de conteúdo (como gzip) o cliente entende. |
Content-Encoding |
A codificação usada no corpo da requisição ou resposta. |
Transfer-Encoding |
O tipo de codificação de transferência que o corpo da mensagem deve usar. |
Access-Control-Allow-Origin |
Especifica os domínios que podem acessar os recursos em uma resposta de origem cruzada. |
Cookies
Cookies são dados enviados pelo servidor para o navegador do usuário, armazenados e reenviados pelo navegador em futuras requisições ao mesmo servidor. São principalmente usados para manter o estado da sessão (como autenticação do usuário ou personalização), facilitando a manutenção do estado do cliente sem necessidade de reautenticação a cada nova solicitação.
Status Codes
Os Status Codes, ou códigos de status, são números de três dígitos enviados pelo servidor em resposta a uma requisição, indicando o resultado. São fundamentais para REST, informando o cliente sobre o sucesso ou falha da operação. Veja alguns comuns:
| Código | Classe | Descrição |
|---|---|---|
1xx |
Informativo | Respostas provisórias, indicam que o servidor recebeu a solicitação e o processo está em andamento. |
2xx |
Sucesso | Indicam que a solicitação foi bem-sucedida. |
3xx |
Redirecionamento | Ações adicionais são necessárias para completar a solicitação, geralmente envolvendo redirecionamento. |
4xx |
Erro do Cliente | Erros de solicitação, indicam problemas como parâmetros inválidos ou requisições não processáveis. |
5xx |
Erro do Servidor | Falhas no processamento pelo servidor, indicam problemas internos ou sobrecarga. |
HTTP/1.x
O HTTP/1.1, lançado em 1997, trouxe melhorias significativas em relação ao HTTP 1.0 (que não vou abordar aqui em detalhes devido à descontinuidade) para se adaptar às novas formas de uso da internet e das aplicações web. Uma mudança fundamental foi a introdução de conexões persistentes, eliminando a necessidade de estabelecer uma nova conexão TCP para cada requisição, o que aumentou a eficiência da comunicação de forma drástica no lado do servidor e do cliente, evitando a abertura de sockets de forma desenfreada.
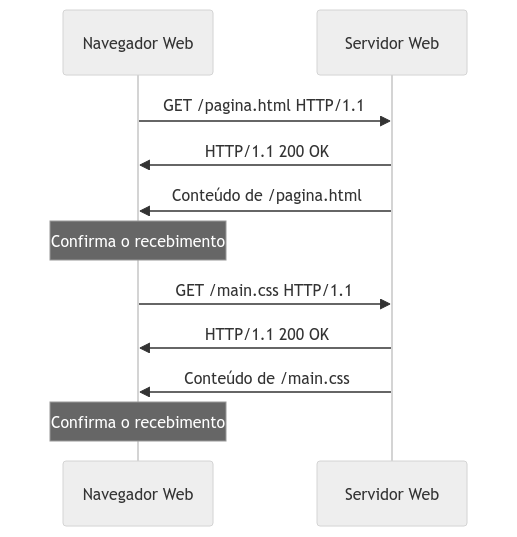
Esta versão também implementou o conceito de pipelining, permitindo o envio de várias requisições em sequência sem aguardar pela resposta da anterior. Esse recurso visava aprimorar a utilização da conexão.
Do ponto de vista da performance, melhorias no caching e no gerenciamento de estado com cookies contribuíram para a redução significativa do número de requisições repetidas ao servidor.
Contudo, o HTTP/1.1 enfrentava problemas como o “head-of-line blocking” (HOL), onde a espera por uma resposta impedia o processamento de requisições subsequentes. Esse e outros desafios levaram à evolução do protocolo em direção a melhorias subsequentes.
HTTP/2
Lançado em 2015, o HTTP/2 foi desenvolvido para superar as limitações do HTTP/1.1, aprimorando a formatação, priorização e transporte de dados. Essas otimizações abriram caminho para a implementação de protocolos adicionais e métodos de comunicação mais avançados, enriquecendo as estratégias de System Design.
Uma inovação chave do HTTP/2 é a multiplexação, que permite o envio simultâneo de requests e responses pela mesma conexão TCP. Isso mitiga o problema de “head-of-line blocking” (HOL blocking) encontrado no HTTP/1.1, onde o processamento de requisições sequenciais poderia ser bloqueado pela espera de uma resposta.
Outra funcionalidade relevante no desenvolvimento de aplicações web é a priorização de requisições. No HTTP/2, é possível definir a prioridade das requisições, permitindo que servidores otimizem a entrega de recursos aos clientes de acordo com a importância designada.
Além disso, a característica de Server Push do HTTP/2 possibilita que servidores enviem recursos ao navegador antes mesmo de serem explicitamente solicitados pelo cliente, melhorando a eficiência da carga de páginas e a experiência do usuário.
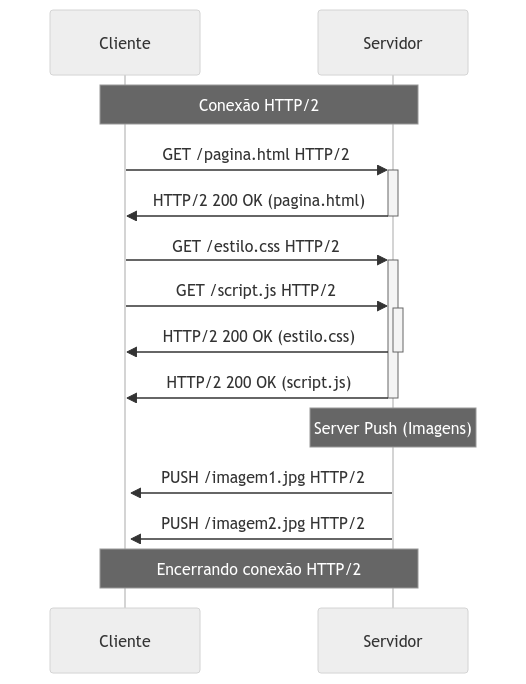
HTTP/3 (QUIC)
O HTTP/3 representa a iteração mais avançada do protocolo até o presente momento da escrita deste capítulo, trazendo inovações significativas, especialmente na camada de transporte (camada 4), ao substituir o TCP pelo QUIC (Quick UDP Internet Connections). Baseando-se no UDP em vez do TCP, essa mudança marca um avanço disruptivo na implementação do protocolo.
Desenvolvido originalmente pelo Google e adotado pelo HTTP/3 através da Internet Engineering Task Force (IETF), o QUIC oferece várias melhorias sobre o TCP, destacando-se em latência, segurança e eficiência na transmissão de dados.
Apesar das preocupações iniciais, o QUIC alcança objetivos de redução de latência mantendo handshakes criptografados e mecanismos de recuperação de erros, comparáveis aos do TCP, porém com uma performance de comunicação aprimorada.
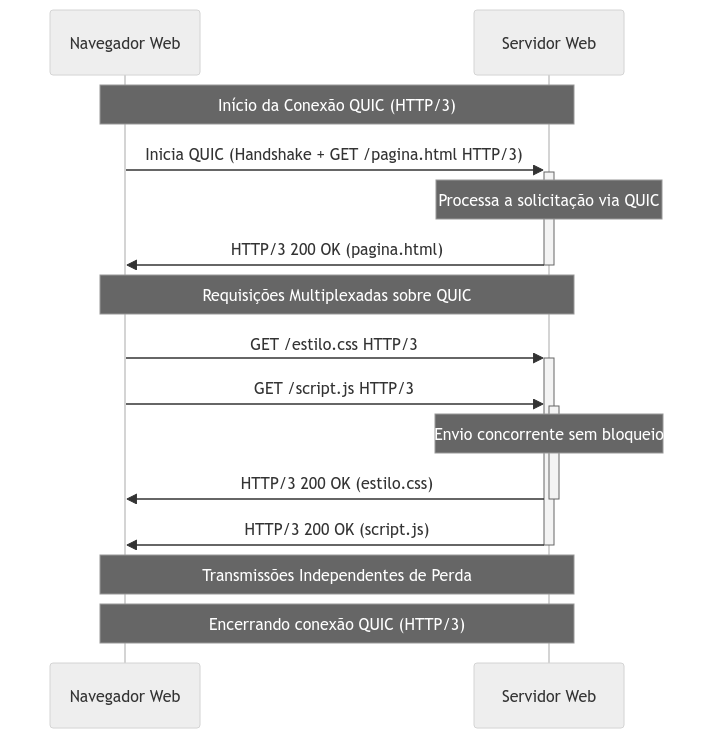
O QUIC diminui a latência de conexão por meio de um handshake criptografado mais eficiente. Enquanto o TCP necessita de um processo de troca prolongado para estabelecer uma conexão segura, o QUIC otimiza este processo combinando o handshake do controle de transmissão com o TLS, diminuindo as etapas necessárias para iniciar a conexão. A multiplexação, introduzida no HTTP/2, é aprimorada no HTTP/3, permitindo uma execução mais eficaz sem bloqueios, facilitando o tráfego de dados e arquivos por uma conexão UDP, em detrimento do TCP.
A implementação do HTTP/3 com o QUIC é particularmente vantajosa para diversos tipos de aplicações, especialmente aquelas que demandam transmissões de dados rápidas e seguras, como streaming de vídeo, jogos online e comunicações em tempo real. Uma característica notável do QUIC é sua habilidade de manter conexões ativas mesmo com a mudança de redes (por exemplo, de Wi-Fi para dados móveis), devido à identificação por connection ID, em vez de endereços IP e portas, facilitando a continuidade das sessões sem interrupções.
Revisores
Referências
OSI-Model - Open Systems Interconnection model
Livro: Redes de Computadores - Andrew Tanenbaum
Introdução a Redes de Computadores
What is Transmission Control Protocol (TCP)?
Explicação do handshake de três vias via TCP/IP
O que é SMTP, IMAP e POP, qual a diferença
Examining HTTP/3 usage one year on
HTTP 1.1 vs. HTTP 2 vs. HTTP 3: Key Differences
O que é um certificado SSL/TLS?

