
Sobrevivendo a cenários de caos no Kubernetes com Istio e Amazon EKS

Na sua casa você pode usar o que você quiser, aqui hoje vamos usar Istio. Sem tempo pra chorar irmão…
Introdução
O objetivo desse post é apresentar alguns mecanismos de resiliência que podemos agregar em nosso Workflow para sobreviver em (alguns) cenários de caos e desastres utilizando recursos do Istio e no Amazon EKS.
Obviamente isso não é “plug n’ play” pra qualquer cenário, então espero que você absorva os conceitos e as ferramentas e consiga adaptar para o seu próprio caso.
A ideia é estabelecer uma linha de pensamento progressiva apresentando cenários de desastre de aplicações, dependências e infraestrutura e como corrigi-los utilizando as ferramentas apresentadas.
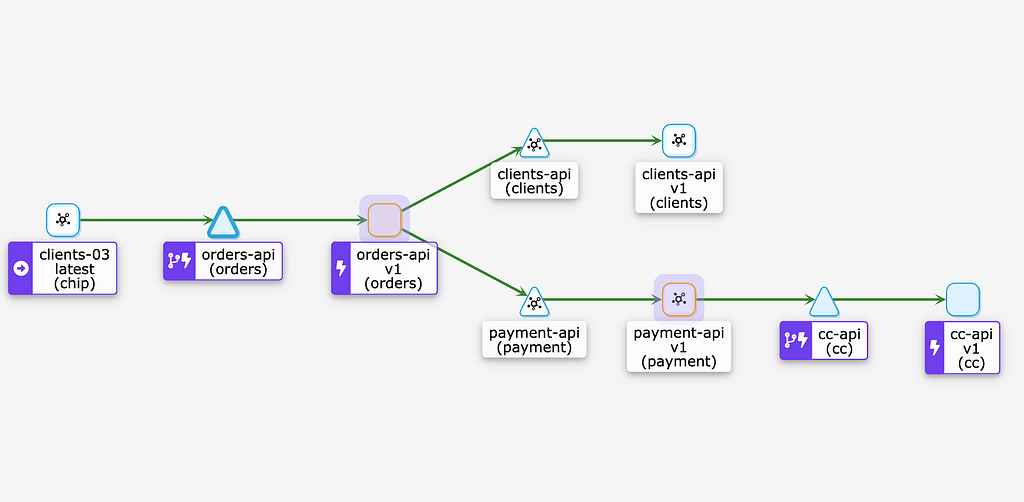
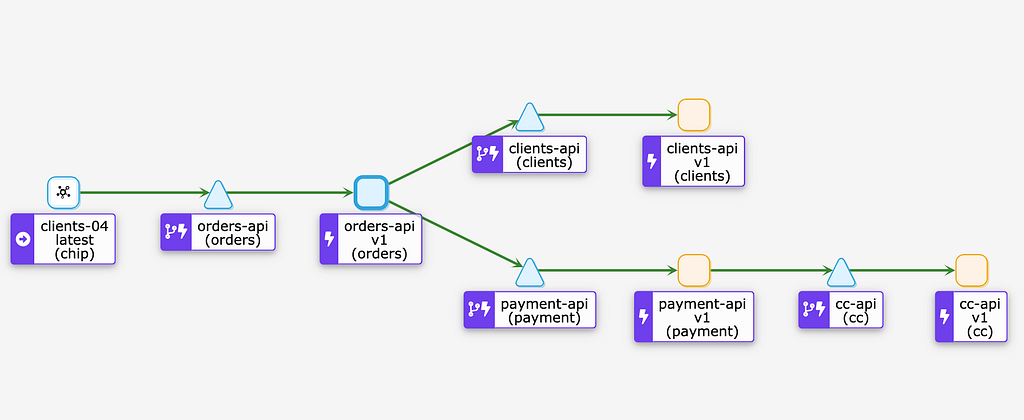
Para este post foi criado um laboratório simulando um fluxo síncrono onde temos 4 microserviços que se comunicam entre si, simulando um sistema distribuído de pedidos, onde todos são estimulados por requisições HTTP.
Premissas Iniciais:
- O ambiente roda em um EKS utilizando a versão 1.20 do Kubernetes em 3 zonas de disponibilidade (us-east-1a, us-east-1b e us-east-1c)
- Vamos trabalhar com um SLO de 99,99% de disponibilidade para o cliente final
- O ambiente já possui Istio default com Gateways e VirtualServices Vanilla configurados pra todos os serviços
- O objetivo é aumentar a resiliência diretamente no Istio, por isso nenhuma aplicação tem fluxo de circuit breaker ou retry pragmaticamente implementados.
- Vamos utilizar o Kiali, Grafana para visualizar as métricas
- Vamos utilizar o K6 para injetar carga no workload
- Vamos utilizar o Chaos Mesh para injetar falhas de plataforma do Kubernetes
- Vamos utilizar o gin-chaos-monkey para injetar falhas a nível de aplicação diretamente no runtime
- O objetivo não é avaliar arquitetura de solução, e sim focar nas ferramentas apresentadas para aumentar resiliência.
Topologia do Sistema
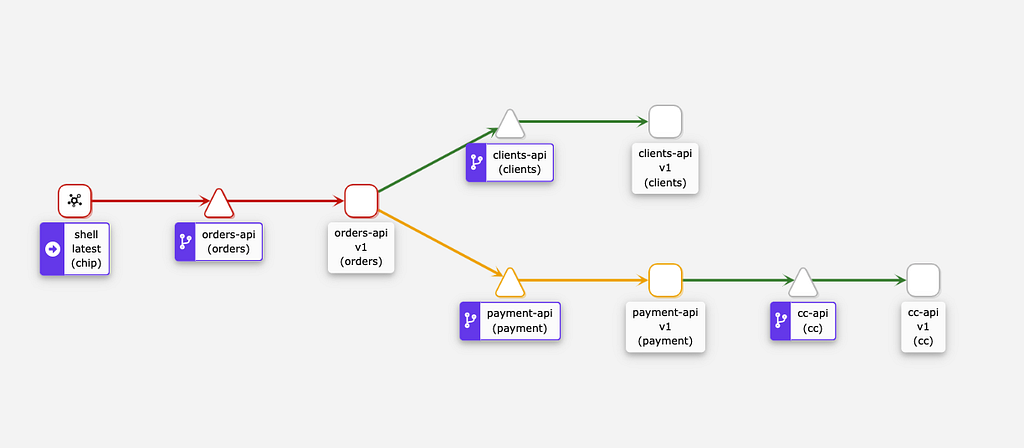
Esta é a representação do fluxo de comunicação entre as aplicações do teste. Todas são mocks mas executam chamadas entre si simulando clientes e servers reais de domínio.
Hipótese 1: Resiliência em falhas de aplicação
O objetivo é coletar as métricas de disponibilidade do fluxo síncrono com qualquer componente podendo falhar a qualquer momento.
Primeiro teste tem o objetivo de injetar uma carga de 60s, simulando 20 VUS (Virtual Users) em todos os cenários, para ver como esses erros se comportam em cascata até chegar no cliente final à medida que vamos criando mecanismos de resiliência.
Todas as aplicações implementando um middleware de chaos que injeta falhas durante a requisição HTTP, portanto em qualquer momento, qualquer uma delas poderá sofrer um:
- Memory Assault — gerando memory leaks constantes
- CPU Assault — injetando overhead de recursos
- Latency Assault — incrementando o response time entre 1000ms e 5000ms
- Exception Assault — devolvendo aleatoriamente um status de 503 com falha na requisição
- AppKiller Assault — fazendo o runtime entrar em panic()
Logo a hipótese a ser testada é:
“Minhas aplicações podem gerar erros sistêmicos aleatoriamente que mesmo assim estarei resiliente para meu cliente final”
Cenários 1.1 — Cenário Inicial
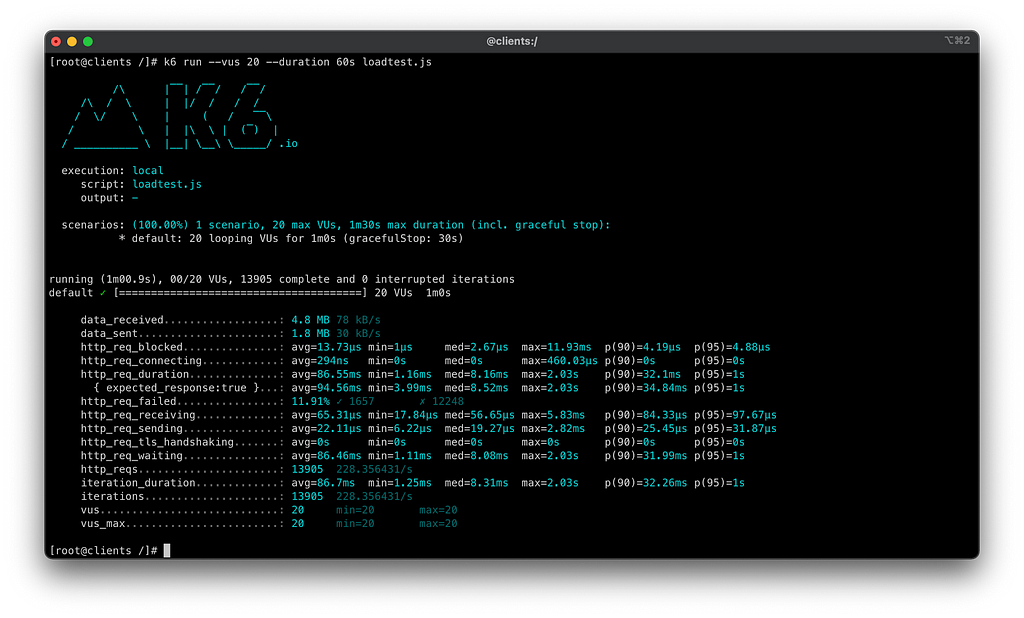
Vamos rodar o teste de carga do k6 no ambiente para ver como vamos nos sair sem nenhum tipo de mecanismo de resiliência:
1
k6 run --vus 20 --duration 60s k6/loadtest.js
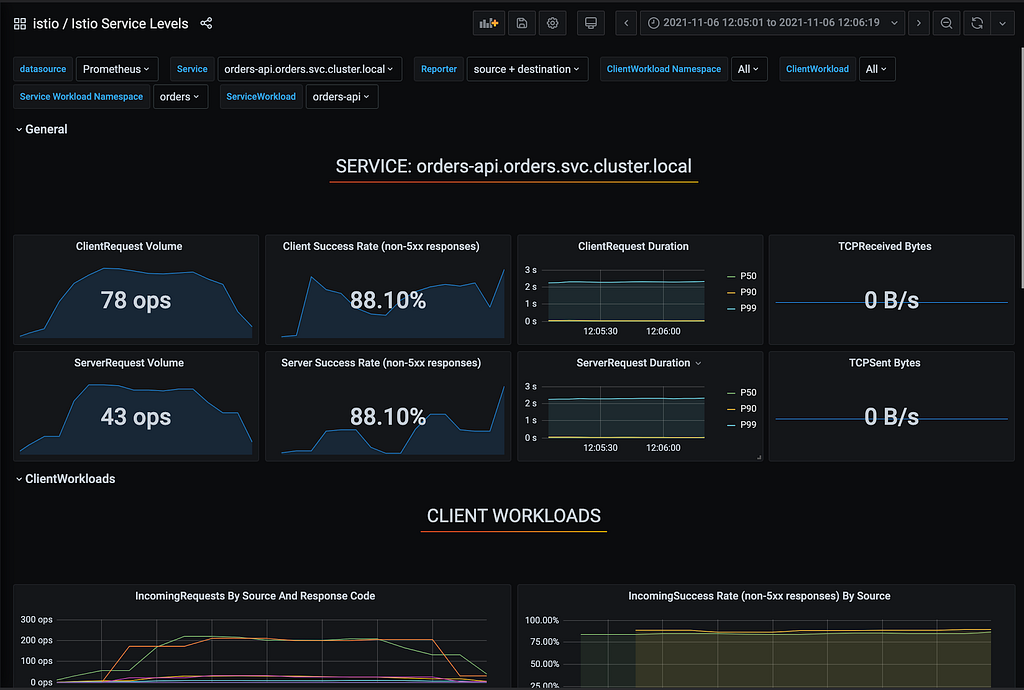
Podemos ver que o chaos monkey da aplicação cumpriu seu papel, injetando falhas aleatórias em todas as dependências da malha de serviços, ofendendo drasticamente nosso SLO de disponibilidade para 88.10%, estourando nosso Error Budget para este período do teste.
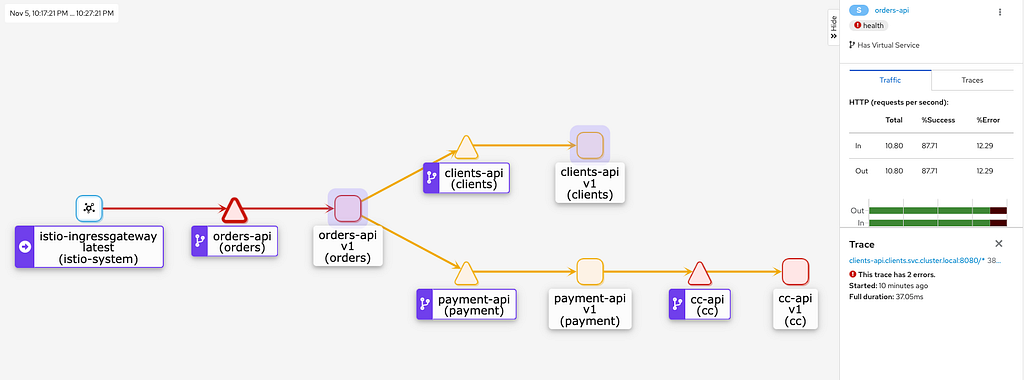
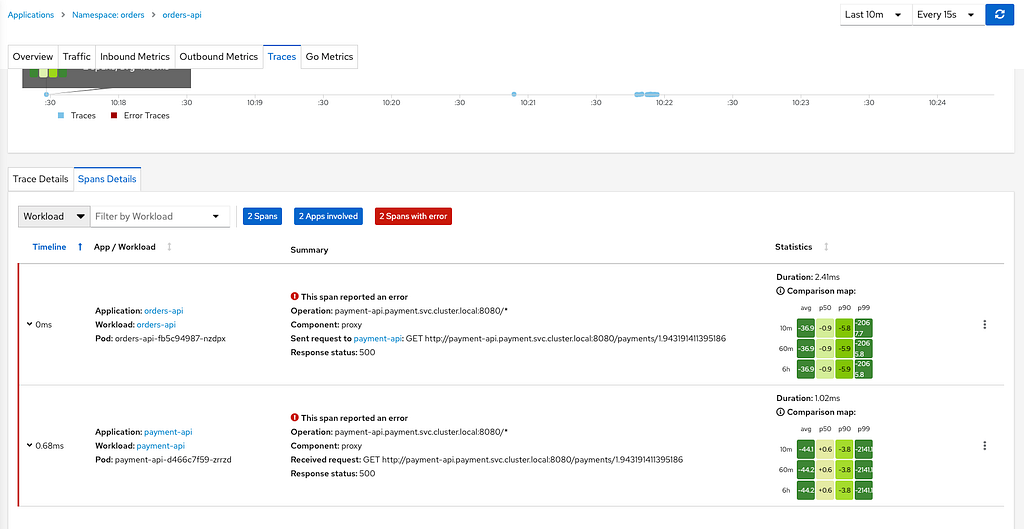
Podemos ver também que todas as aplicações da malha, em algum momento apresentaram falhas aleatórias, gerando erros em cascata.
Sumário do teste 1.1 — Cenário inicial:
- Tempo do teste: 60s
- Total de requisições: 13905
- Requests por segundo: 228.35/s
- Taxa de erros a partir do client: 11.91%
- Taxa real de sucesso do serviço principal orders-api: 88.10%
- Taxa de sucesso dos consumidores do orders-api: 88.10%
- SLO Cumprido: Não
- Yaml dos testes executados no cenário
Cenário 1.2 — Implementando retry para Falhas HTTP
O objetivo do cenário é implementar a política de retentativas para falhas HTTP nos VirtualServices previamente configurados das aplicações. Vamos as opções 5xx, gateway-error, connect-failure. Podendo ocorrer até 3 tentativas de retry com um timeout de 500ms.
As opções de retentativas iniciais de acordo com a documentação, possuem as seguintes funções:
- 5xx: Ocorrerá uma nova tentativa se o servidor upstream responder com qualquer código de resposta 5xx
- gateway-error: Uma política parecida com o 5xx, porém voltadas a falhas específicas de gateway como 502, 503, ou 504 no geral. Nesse caso, é redundante, porém fica de exemplo.
- connect-failure: Será realizada mais uma tentativa em caso de falha de conexão por parte do upstream ou em casos de timeout.
Vamos rodar novamente os testes simulando 20 usuários por 60 segundos com os 3 retries aplicados.
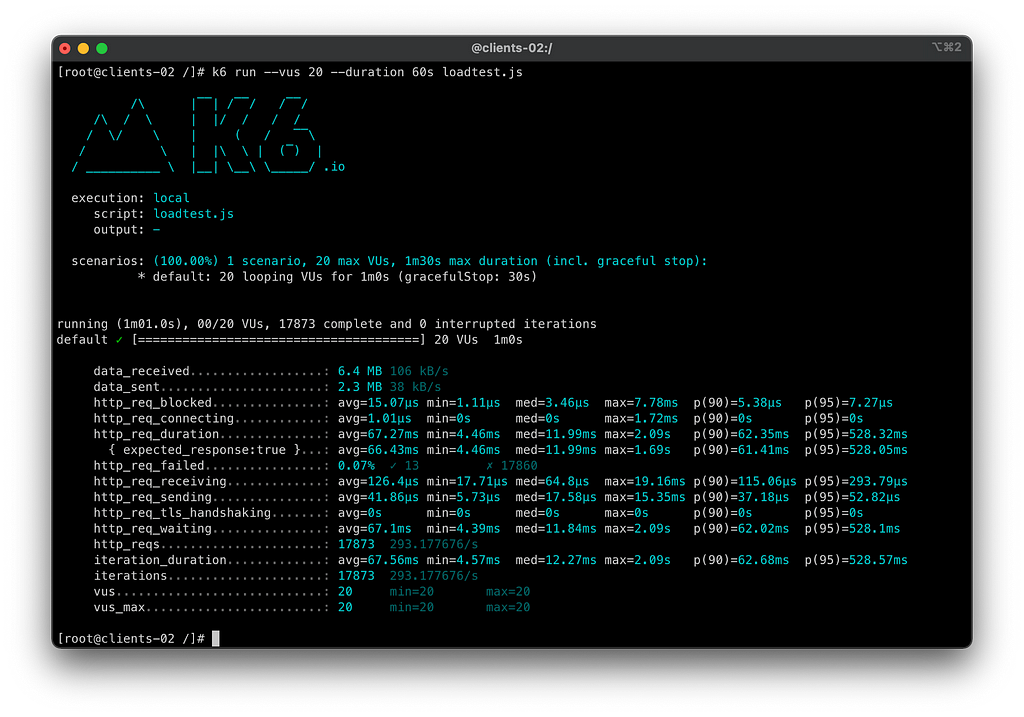
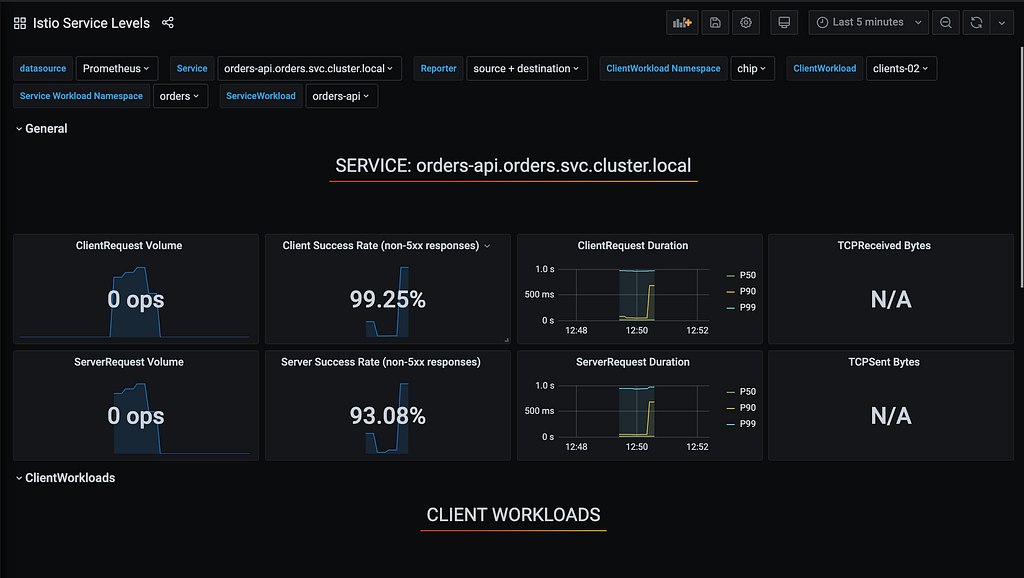
Conseguimos uma melhoria de mais de 6% de disponibilidade entre o que o serviço degradado respondeu com o que o cliente recebeu, utilizando apenas 3 tentativas de retry entre todos os serviços. Tivemos já um grande saving de disponibilidade para o cliente final, porém ainda ofendemos nosso SLO, batendo 99,25% de disponibilidade.
Sumário do teste 1.2 — Retry para falhas HTTP:
- Tempo do teste: 60s
- Total de requisições: 17873
- Requests por segundo: 293.17/s
- Taxa de erros a partir do cliente: 0.07%
- Taxa real de sucesso do serviço principal orders-api: 93.08%
- Taxa de sucesso dos consumidores do orders-api: 99.25%
- SLO Cumprido: Não
- Yaml dos testes executados no cenário
Cenário 1.3 — Ajustando a quantidade de retries para suprir o cenário
Para resolver o problema, aumentei o número de retries de 3 para 5 e repeti os testes nos mesmos cenários. Em ambientes reais, esse tipo de ajuste pode ser derivado de um número “mágico”, encontrado após várias repetições do mesmo teste. Executei mais algumas vezes até atingir 0% de erros consistentemente.
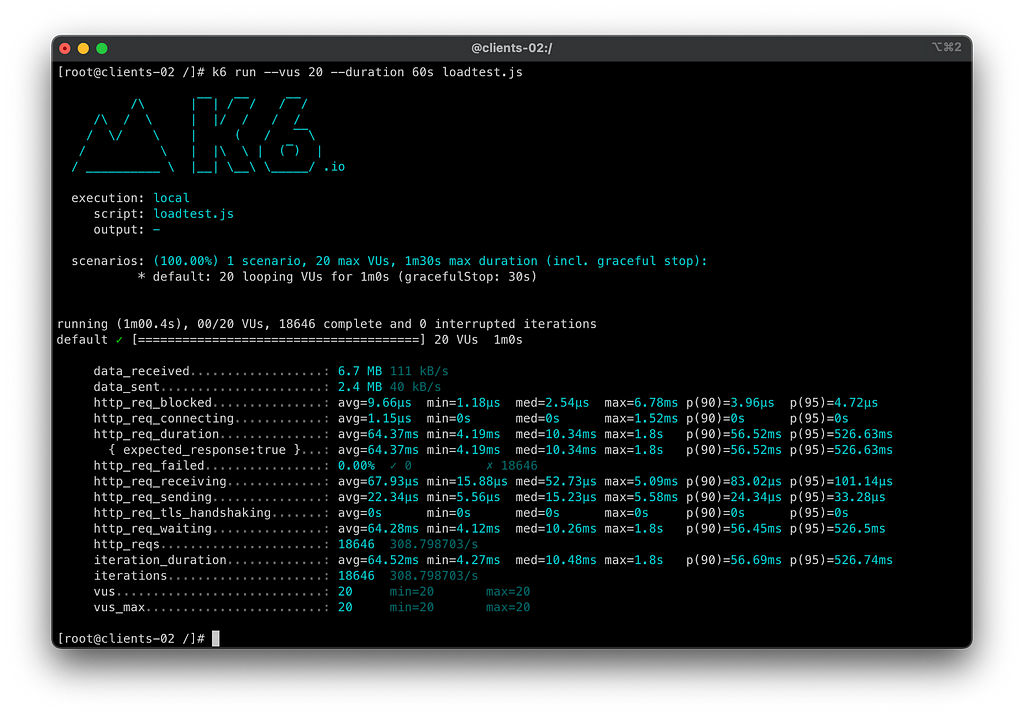
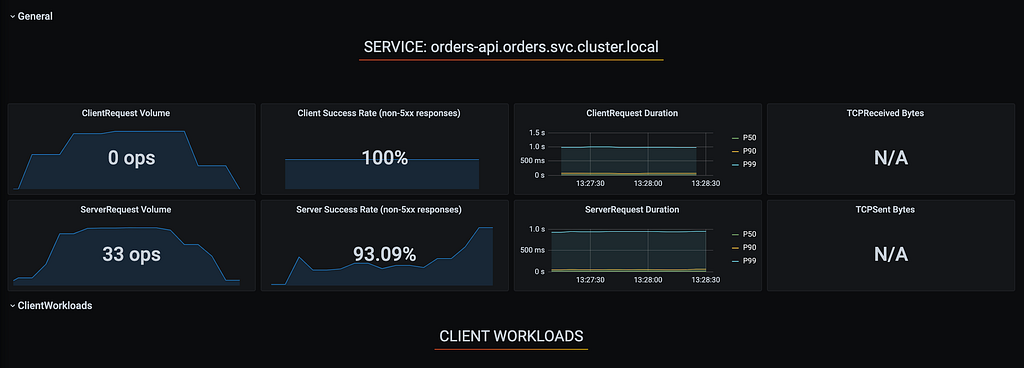
Neste cenário, conseguimos superar os 93.09% de disponibilidade fornecidos pelos upstreams, garantindo 100% de disponibilidade para o cliente com os cenários de retry. Mesmo com falhas aleatórias sendo injetadas, a disponibilidade final para o cliente foi assegurada.
Sumário do teste 1.3 — Ajustes na quantidade de retries para a hipótese:
- Tempo do teste: 60s
- Total de requisições: 18646
- Requests por segundo: 308.79/s
- Taxa de erros a partir do cliente: 0.00%
- Taxa real de sucesso do serviço principal orders-api: 93.09%
- Taxa de sucesso dos consumidores do orders-api: 100.00%
- SLO Cumprido: Sim
- Yaml dos testes executados no cenário
Hipótese concluída com sucesso!
Hipótese 2: Resiliência em falhas dos Pods
Para realizar os testes de infraestrutura nos pods, utilizaremos o Chaos Mesh como ferramenta para injetar falhas nos componentes do nosso fluxo, e desligaremos o chaos-monkey no runtime das aplicações. A partir deste ponto, não injetaremos mais falhas intencionais a partir da aplicação para testar puramente falhas a nível de plataforma. O objetivo é analisar como o nosso fluxo síncrono se comporta diante da perda brusca de unidades computacionais em diversos cenários, e como nosso processo de melhoria contínua com retries pode nos ajudar e agregar ainda mais valor como plataforma.
Portanto, a hipótese é:
“Posso perder pods e unidades computacionais de várias maneiras, mas minha aplicação continuará resiliente para o cliente final.”
Cenário 2.1 — Injetando falhas de healthcheck nos componentes do workload
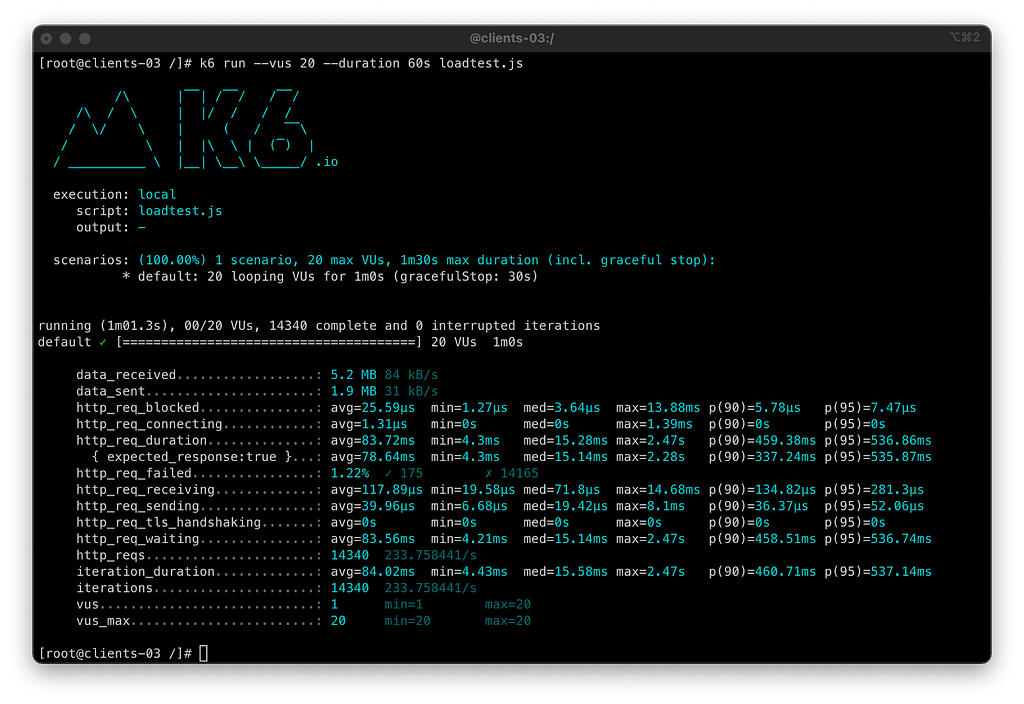
Neste primeiro cenário, vamos injetar o mesmo volume de requisições e, durante o processo, aplicar o cenário de pod-failure em nosso fluxo. Em todas as aplicações, realizaremos um teste de 30 segundos no qual perderemos 90% dos nossos pods repentinamente devido a falhas de healthcheck. Este é um teste bastante agressivo, com o propósito de verificar como as estratégias que implementamos até o momento agregam valor nesse cenário.
Vamos iniciar o teste nos mesmos cenários e, no meio do processo, aplicar os cenários de PodFailure do Chaos Mesh em todas as aplicações.
1
2
3
4
5
6
kubectl apply -f chaos-mesh/01-pod-failture/
podchaos.chaos-mesh.org/cc-pod-failure created
podchaos.chaos-mesh.org/clients-pod-failure created
podchaos.chaos-mesh.org/orders-pod-failure created
podchaos.chaos-mesh.org/payment-pod-failure created
Vamos conferir o status dos pods:
1
2
3
4
5
6
7
8
9
10
11
❯ kubectl get pods -n orders
NAME READY STATUS RESTARTS AGE
orders-api-fb5c94987-225zp 0/2 Running 2 100s
orders-api-fb5c94987-8rpjb 0/2 Running 2 14m
orders-api-fb5c94987-bmnqm 0/2 Running 2 85s
orders-api-fb5c94987-d9c4f 0/2 Running 2 14m
orders-api-fb5c94987-gd745 0/2 Running 2 14m
orders-api-fb5c94987-htbcn 2/2 Running 0 100s
orders-api-fb5c94987-rzqkg 0/2 Running 2 100s
orders-api-fb5c94987-st8l2 0/2 Running 2 85s
1
2
3
4
5
6
❯ kubectl get pods -n cc
NAME READY STATUS RESTARTS AGE
cc-api-548bb458-78p77 2/2 Running 0 14m
cc-api-548bb458-nkjmj 0/2 Running 2 14m
cc-api-548bb458-sgfrb 0/2 Running 2 14m
1
2
3
4
5
6
❯ kubectl get pods -n clients
NAME READY STATUS RESTARTS AGE
clients-api-5c8d89b4d-8nvsd 2/2 Running 0 14m
clients-api-5c8d89b4d-wd8rq 0/2 Running 4 14m
clients-api-5c8d89b4d-xm4ln 0/2 Running 4 14m
Vamos analisar os resultados:
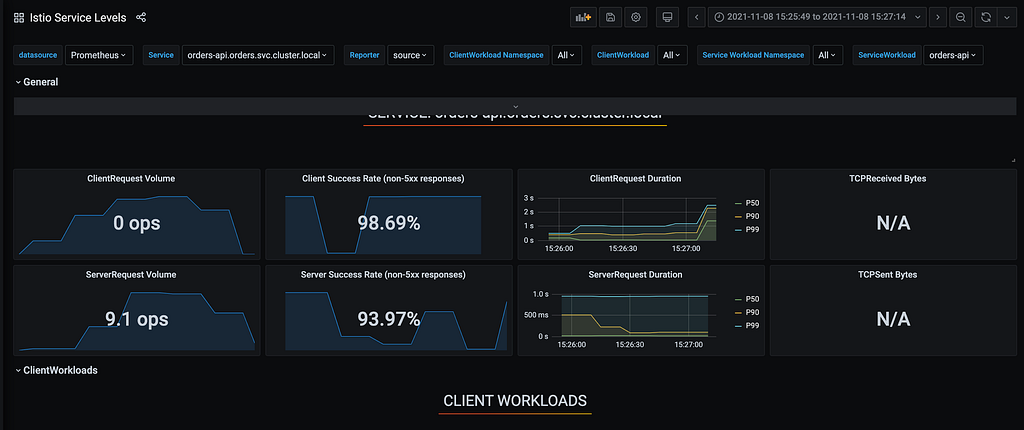
Neste teste, 90% de todos os pods do nosso fluxo de trabalho pararam de responder aos healthchecks repentinamente por 30 segundos durante o nosso teste de 60 segundos. Mesmo com nosso cenário de retries entre os VirtualServices, ainda registramos 1.22% de erros retornados ao cliente. Conseguimos reduzir em quase 5% os erros, mas ainda assim não atendemos ao nosso SLO de 99,99%.
Sumário do Teste 2.1 — Injetando falhas de Healthcheck nas aplicações:
- Tempo do teste: 60s
- Total de requisições: 14340
- Requests por segundo: 233.75/s
- Taxa de erros a partir do client: 1.22%
- Taxa real de sucesso do serviço principal orders-api: 93.97%
- Taxa de sucesso dos consumidores do orders-api: 98.69%
- SLO Cumprido: Não
Cenário 2.2 — Adicionando retry por conexões perdidas / abortadas
No teste anterior, mesmo com a perda repentina de 90% dos recursos computacionais e a implementação de políticas de retentativas, não alcançamos o SLO de disponibilidade desejado. Portanto, implementamos políticas adicionais de retentativas para casos de falhas em cascata, incluindo os códigos 5xx, gateway-error, connect-failure, refused-stream, reset, unavailable, cancelled no nosso retryOn. O objetivo é mitigar erros causados por perda de conexões em quedas bruscas de pods.
As opções de retentativas são, de acordo com a documentação para HTTP:
- reset : Será feita uma tentativa de retry em caso de disconnect/reset/read timeout vindo do upstream
Caso você esteja utilizando algum backend gRPC, tomei a liberdade de adicionar as outras opções no exemplo, caso seu backend seja exclusivamente HTTP, as mesmas não serão necessárias, mas fica como estudo:
- resource-exhausted: retry em chamadas gRPC em caso de headers contendo o termo “resource-exhausted”
- unavailable: retry em chamadas gRPC em caso de headers contendo o termo “unavailable”
- cancelled: retry em chamadas gRPC em caso de headers contendo o termo “cancelled”
Executar novamente os testes para avaliar o quanto de melhoria temos colocando o retry por disconnect/reset/timeout adicionais
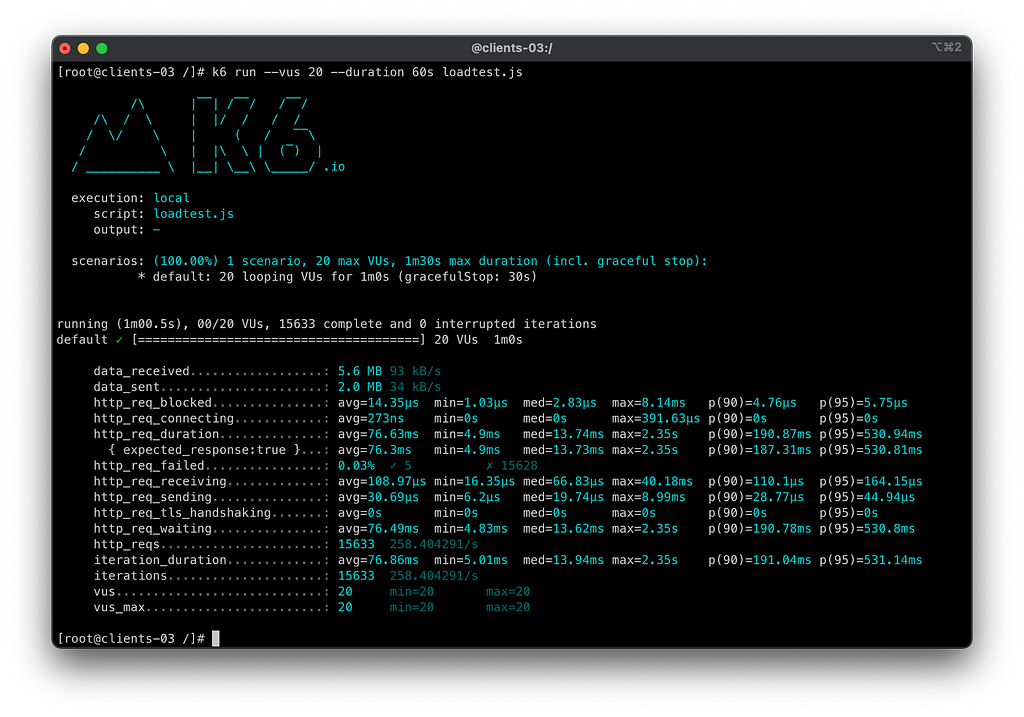
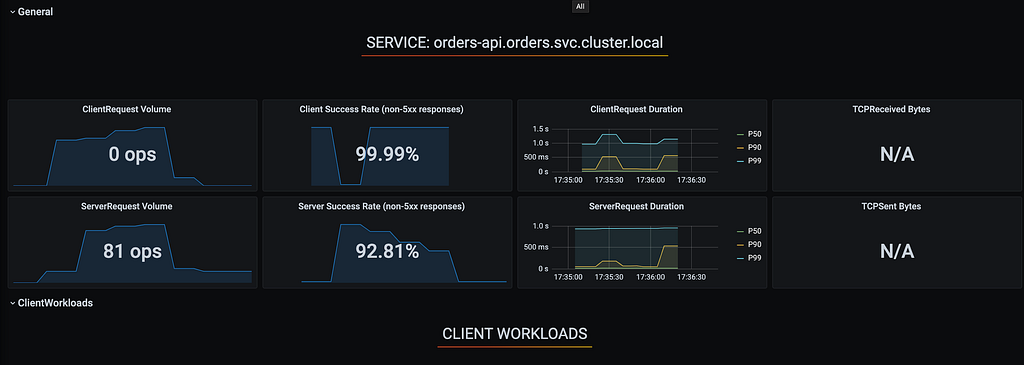
Neste cenário, com as novas políticas de retentativa, tivemos um saving significativo de disponibilidade, com apenas 0.03% de erros contabilizados no cliente, correspondendo a 5 erros em 15633 requisições.
Caso você esteja utilizando algum backend gRPC, tomei a liberdade de adicionar as outras opções no exemplo, caso seu backend seja exclusivamente HTTP, as mesmas não serão necessárias, mas fica como estudo:
Sumário do teste 2.2 — Adicionando Retry por Conexões Abortadas:
- Tempo do teste: 60s
- Total de requisições: 15633
- Requests por segundo: 258.4/s
- Taxa de erros a partir do client: 0.03%
- Taxa real de sucesso do serviço principal orders-api: 92.81%
- Taxa de sucesso dos consumidores do orders-api: 99.99%
- SLO Cumprido: Não
- Yaml dos testes executados no cenário
- Yaml dos testes do Chaos Mesh
Cenário 2.3 — Adicionando Circuit Breakers nos upstreams
Para a cereja do bolo pro assunto de resiliência em service-mesh, nesse caso o istio, são os circuit breakers. É um conceito muito legal que não é tão fácil de compreender como os retry. Circuit breakers nos ajudam a sinalizar pros clientes que um determinado serviço está fora, poupando esforço para consumi-lo e junto com as retentativas estar sempre validando se os mesmos estão de volta “a ativa” ou não. Isso vai nos ajudar a “não tentar” mais requisições nos hosts que atenderem aos requisitos de circuito quebrado. Além de poder limitar a quantidade de requisições ativas que nosso backend consegue atender, para evitar uma degradação maior ou gerar uma falha não prevista. Para isso vamos adicionar um recurso chamado DestinationRule em todas as aplicações da malha de serviço.
As coisas mais importantes desse novo objeto são consecutive5xxErrors e baseEjectionTime.
Os consecutive5xxErrors é o numero de erros que um upstream pode retornar para que o mesmo seja considerado com o circuito aberto.
Já o baseEjectionTime é o tempo que o host ficará com o circuito aberto antes de retornar para a lista de upstreams.
Peguei essas duas imagens deste post excelente a respeito de circuit-breaking do Istio mais conceitual, e de como ele funciona em conjunto com os retries que já implementamos.
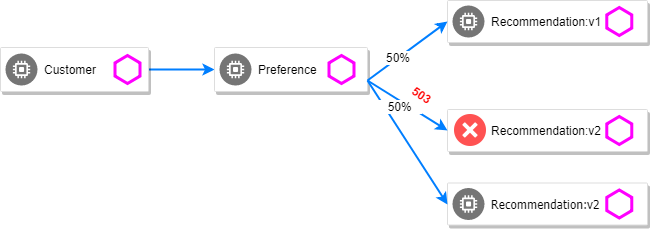
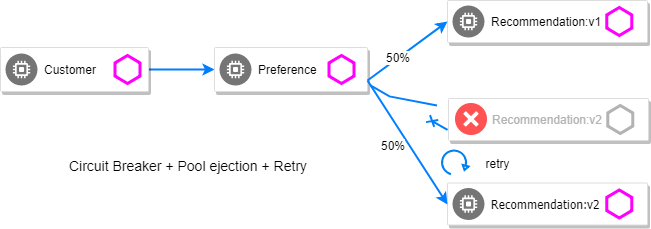
A partir do momento que o baseline de erros de um upstream ativa a quebra de circuito, o upstream fica inativa na lista pelo período recomendado pelo Pool Ejection, e com as considerações de retry, podemos iterar na lista até encontrar um host saudável para aquela requisição em específico.
Seguindo essa lógica, vamos aos testes:
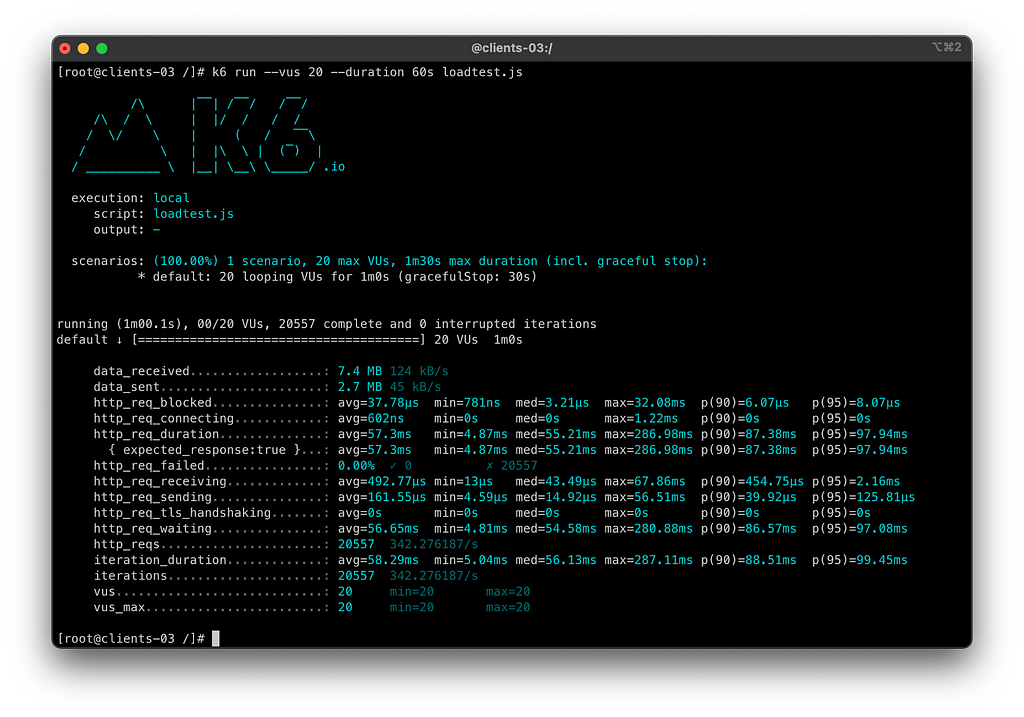
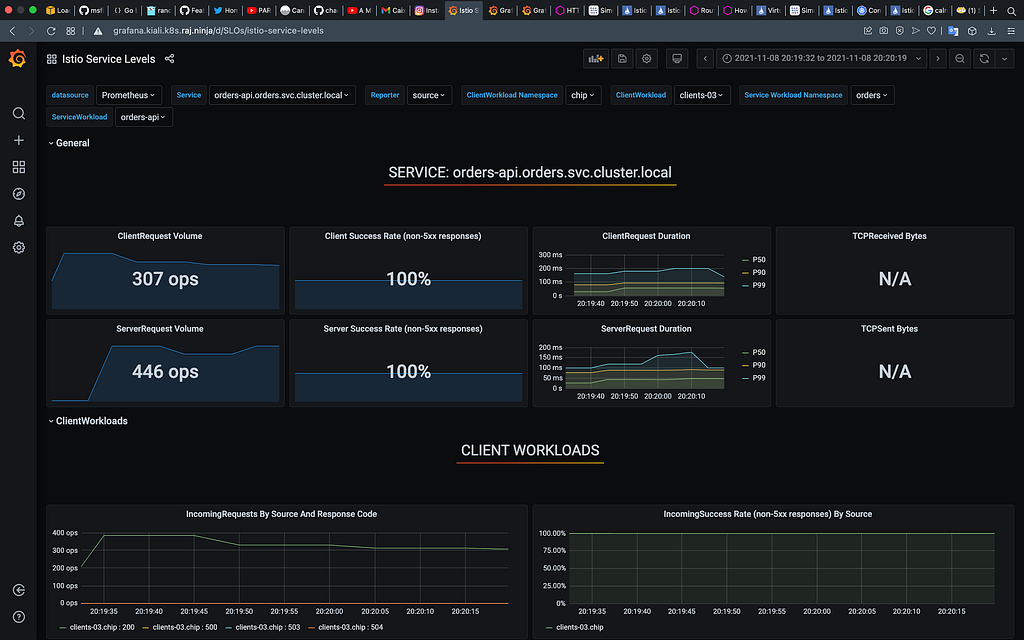
Neste teste finalmente conseguimos atingir os 100% de disponibilidade com falha temporária e repentina de 90% do healthcheck das aplicações da malha. No Kiali, podemos ver que o circuit breaker foi implementado em todas as pontas do workflow.
Sumário do teste 2.3 — Adicionando Circuit Breaker com os Retry:
- Tempo do teste: 60s
- Total de requisições: 20557
- Requests por segundo: 342/s
- Taxa de erros a partir do client: 0.00%
- Taxa real de sucesso do serviço principal orders-api: 100 %
- Taxa de sucesso dos consumidores do orders-api: 100 %
- SLO Cumprido: SIM
- Yaml dos testes executados no cenário
- Yaml dos testes do Chaos Mesh
Cenário 2.3 — Morte instantânea de 90% dos pods
Vamos avaliar um outro cenário, parecido mas não igual. No cenário anterior validamos a action pod-failure, que injeta uma falha de healthcheck nos pods mas não os mata definitivamente. Nesta vamos executar a action pod-kill, onde 90% dos pods vão sofrer um force terminate.
Vamos iniciar o teste de carga e no meio dela vamos injetar a falha no workload. Link do meio
1
2
3
4
5
6
kubectl apply -f chaos-mesh/02-pod-kill
podchaos.chaos-mesh.org/cc-pod-kill created
podchaos.chaos-mesh.org/clients-pod-kill created
podchaos.chaos-mesh.org/orders-pod-kill created
podchaos.chaos-mesh.org/payment-pod-kill created
1
2
3
4
5
6
7
8
9
❯ kubectl get pods -n payment
NAME READY STATUS RESTARTS AGE
payment-api-645c7958cd-c25nf 2/2 Running 0 2m40s
payment-api-645c7958cd-clbpg 1/2 Running 0 6s
payment-api-645c7958cd-h6fgh 0/2 Running 0 6s
payment-api-645c7958cd-lt5bp 0/2 PodInitializing 0 6s
payment-api-645c7958cd-s2gzx 0/2 Running 0 6s
payment-api-645c7958cd-v6c8w 0/2 Running 0 6s
1
2
3
4
5
6
❯ kubectl get pods -n orders
NAME READY STATUS RESTARTS AGE
orders-api-86b4c65f9b-6wdg5 1/2 Running 0 18s
orders-api-86b4c65f9b-pvqv4 1/2 Running 0 18s
orders-api-86b4c65f9b-wbkt2 2/2 Running 0 4m13s
1
2
3
4
5
6
❯ kubectl get pods -n cc
NAME READY STATUS RESTARTS AGE
cc-api-58b558fc8f-6dqlh 2/2 Running 0 15m
cc-api-58b558fc8f-7zz8t 1/2 Running 0 30s
cc-api-58b558fc8f-wnjcs 1/2 Running 0 30s
1
2
3
4
5
6
7
8
❯ kubectl get pods -n clients
NAME READY STATUS RESTARTS AGE
clients-api-59b5cf8bc-46cws 1/2 Running 0 47s
clients-api-59b5cf8bc-4rkvp 1/2 Running 0 47s
clients-api-59b5cf8bc-hdngf 1/2 Running 0 47s
clients-api-59b5cf8bc-txcb4 2/2 Running 0 16m
clients-api-59b5cf8bc-vb8lh 1/2 Running 0 47s
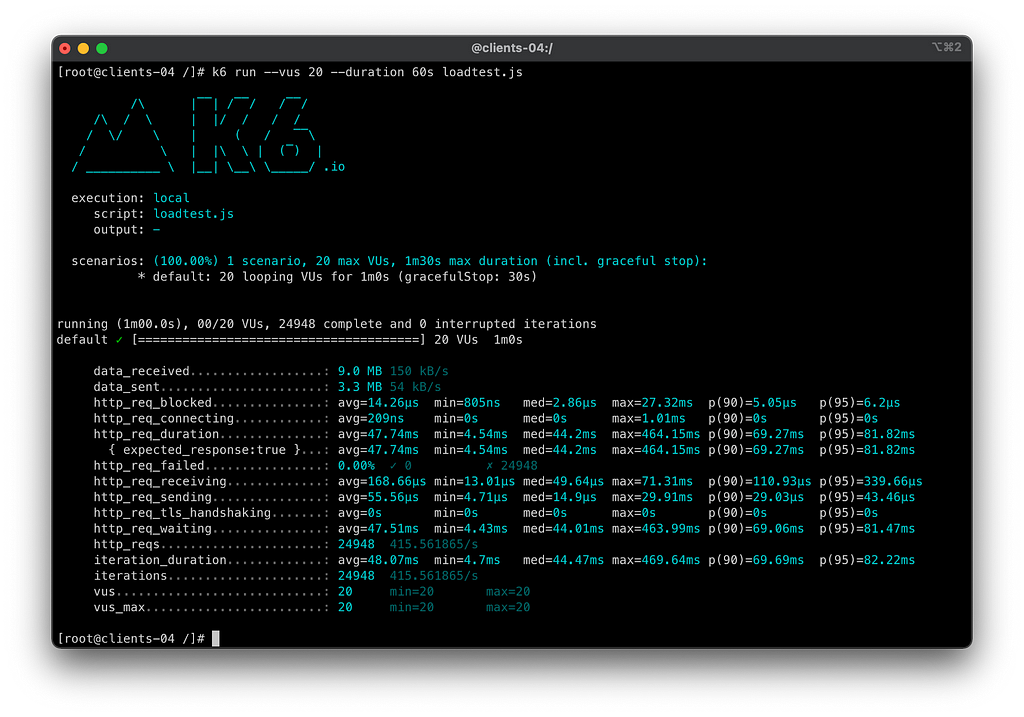
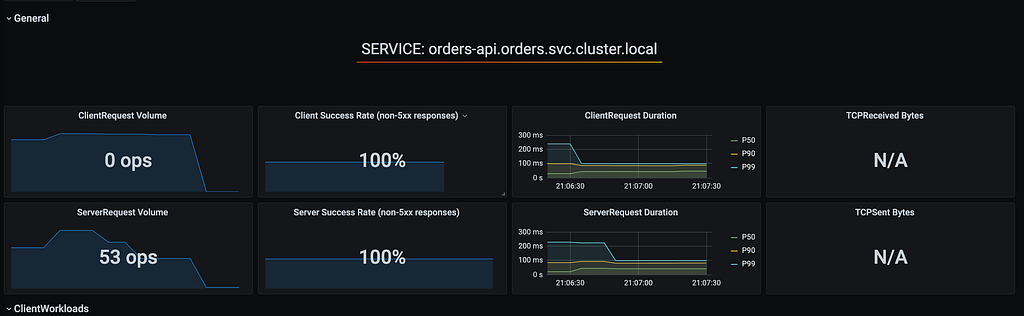
Desta vez passamos de primeira no teste de uma queda brusca de pods com carga quente. Os retries com circuit breaker dos pods agiram muito rápido evitando uma quantidade significativa de retries, melhorando muito até o response time e tput.
Sumário do teste 2.3 — Morte repentina dos pods das aplicações:
- Tempo do teste: 60s
- Total de requisições: 24948
- Requests por segundo: 415,56/s
- Taxa de erros a partir do client: 0.00%
- Taxa real de sucesso do serviço principal orders-api: 100 %
- Taxa de sucesso dos consumidores do orders-api: 100 %
- SLO Cumprido: SIM
- Yaml dos testes executados no cenário
- Yaml dos testes do Chaos Mesh
Hipótese validada com sucesso!
Hipótese 3: Queda de Uma Zona de Disponibilidade no EKS
Neste laboratório estamos rodando o EKS com 3 AZ’s na região de us-east-1, sendo us-east-1a, us-east-1b, us-east-1c rodando com 2 EC2 em cada uma delas.
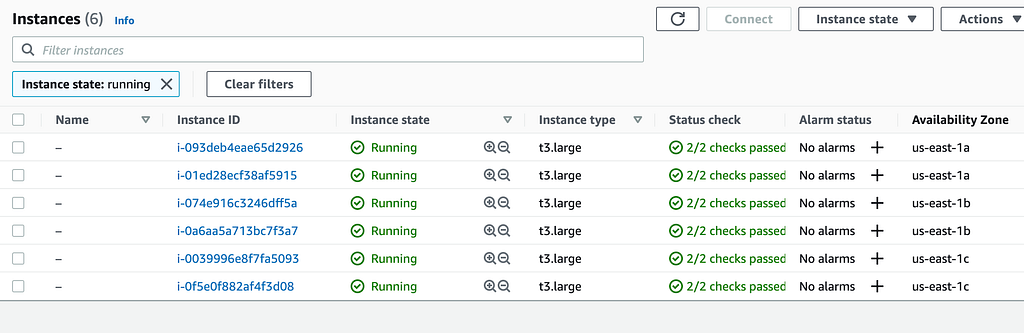
A ideia é matar todas as instâncias de uma determinada zona de disponibilidade especifica para validar se a quantidade de retries e circuit breaker que implementamos até o momento são capazes de suprir esse cenário em disponibilidade.
Logo a hipótese é:
Os recursos computacionais de uma zona de disponibilidade especifica podem cair a qualquer momento que estarei resiliente para meus clientes finais
Cenário 3.1 — Morte de uma zona de disponibilidade da AWS
Antes de mais nada, vamos utilizar o recurso do PodAffinity / PodAntiAffinity para criar uma sugestão de regra para o scheduler: “divida-se igualmente entre os hosts utilizando a referência à label failure-domain.beta.kubernetes.io/zone”, na qual é preenchida nos nodes do EKS com a zona de disponibilidade que aquele node está rodando, o que irá acarretar em garantir um Multi-AZ do workload.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
❯ kubectl describe node ip-10-0-89-102.ec2.internal
Name: ip-10-0-89-102.ec2.internal
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/instance-type=t3.large
beta.kubernetes.io/os=linux
eks.amazonaws.com/capacityType=ON_DEMAND
eks.amazonaws.com/nodegroup=eks-cluster-node-group
eks.amazonaws.com/nodegroup-image=ami-0ee7f482baec5230f
failure-domain.beta.kubernetes.io/region=us-east-1
failure-domain.beta.kubernetes.io/zone=us-east-1c
ingress/ready=true
kubernetes.io/arch=amd64
kubernetes.io/hostname=ip-10-0-89-102.ec2.internal
kubernetes.io/os=linux
node.kubernetes.io/instance-type=t3.large
topology.kubernetes.io/region=us-east-1
topology.kubernetes.io/zone=us-east-1c <----------- AQUI
Annotations: node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
Então, em todos os nossos arquivos de deployment vamos adicionar as notações de affinity
Vamos olhar os pods de uma aplicação especifica para encontrar os IPs que eles assumiram na VPC para identificar a distribuição via console.
1
2
3
4
5
6
❯ kubectl get pods -n orders -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
orders-api-56f8bf5b7c-7wbz4 2/2 Running 0 2m10s 10.0.54.38 ip-10-0-58-137.ec2.internal <none> <none></none>
orders-api-56f8bf5b7c-pcqtd 2/2 Running 0 2m10s 10.0.89.56 ip-10-0-81-235.ec2.internal <none> <none></none>
orders-api-56f8bf5b7c-zlwgd 2/2 Running 0 2m10s 10.0.78.253 ip-10-0-76-14.ec2.internal <none> <none></none>
Levando os IP’s dos pods para o painel, podemos ver se a sugestão está funcionando entre as 3 zonas de disponibilidade.
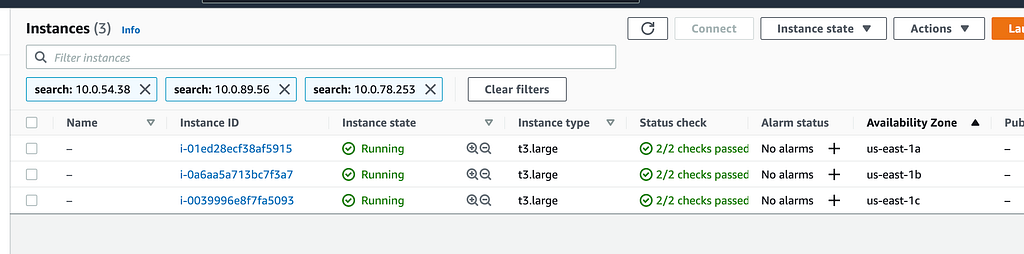
Este teste não será tão inteligente. Vou selecionar todos os nodes da zona us-east-1a e dar um halt via SSM enquanto nosso teste roda.
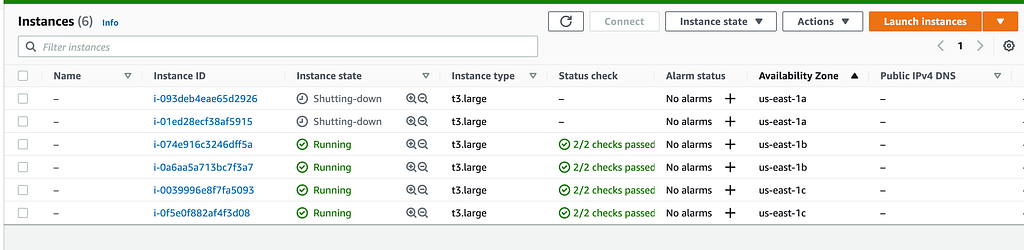
Vamos aos resultados do teste
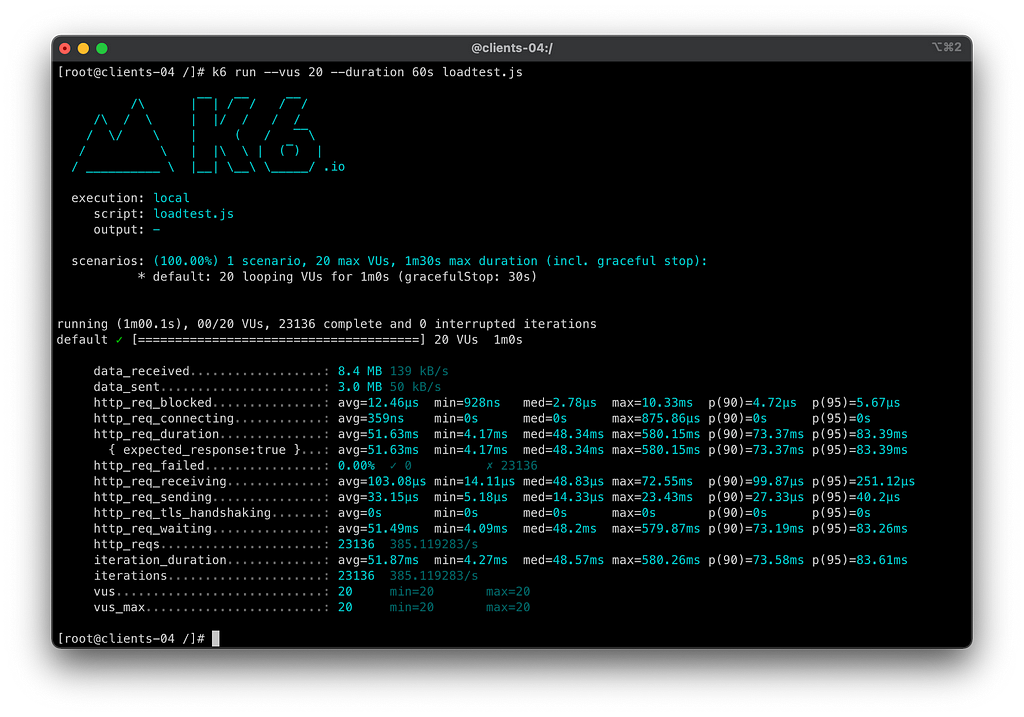

Sumário dos testes 3.1 — Perda de uma AZ:
- Tempo do teste: 60s
- Total de requisições: 23136
- Requests por segundo: 385.11/s
- Taxa de erros a partir do client: 0.00%
- Taxa real de sucesso do serviço principal orders-api: 100 %
- Taxa de sucesso dos consumidores do orders-api: 100 %
- SLO Cumprido: SIM
- Yaml dos testes executados no cenário
Hipótese validada com sucesso!
Considerações finais, e importantes:
- Mecanismo de resiliência é igual itaipava que seu tio trouxe em dia de churrasco: Todo mundo fica bravo de ter que dar espaço na geladeira, no fim todo mundo vai acabar bebendo e sempre vai faltar.
- A resiliência a nível de plataforma é uma parte da composição da resiliência de uma aplicação, não a solução completa pra ela.
- O fluxo de retry deve ser implementado somente se as aplicações atrás delas tiverem mecanismos de idempotência para evitar duplicidades de registros, principalmente, falando em HTTP, de requests que são naturalmente não idempotentes como POST por exemplo.
- Os retry e circuit breaker dos meshs em geral não devem ser tratados como mecanismo de resiliência principal da solução. Não substitui a resiliência pragmática.
- Não substitui a resiliência a nível de código / aplicação. Repetindo algumas vezes pra fixar.
- Os circuit breakers e retentivas devem ser implementados a nível de código independente da plataforma suportar isso. Procure por soluções como Resilience4J, Hystrix, GoBreaker. Só pra constar.
- A busca por circuit breakers pragmáticos tende a prioridade em caso de downtime total de uma dependência, principalmente para buscar fluxos alternativos como fallback, não apenas para serem usados para “dar erro mais rápido”. Pense em “posso ter um SQS como fallback para fazer temporariamente offload para os eventos que eu iria produzir no meu kafka que está com falha?”, “tenho um sistema de apoio para enfileirar as requisições que estão dando falha para processamento tardio”?, “eu posso reprocessar tudo que falhou quando minhas dependências voltarem?” antes de qualquer coisa, beleza?
Fico por aqui, espero ter ajudado! Lembrando que todos os arquivos e aplicações estão neste repositório do Github.
Referencias / Material de Apoio:
- Istio Traffic Management (https://istio.io/latest/docs/concepts/traffic-management/)
- Istio Traffic Management — Circuit Breaker (https://istio.io/latest/docs/tasks/traffic-management/circuit-breaking/)
- Envoy — Retry Policy — https://www.envoyproxy.io/docs/envoy/latest/configuration/http/http_filters/router_filter#x-envoy-retry-on
- Chaos Mesh — Quickstart https://chaos-mesh.org/docs/quick-start/
- K6 Loading Testing — https://k6.io/docs/getting-started/running-k6/
- Setup do EKS com Istio e Terraform — https://github.com/msfidelis/eks-with-istio
Obrigado aos revisores:
- Rebeca Maia (@rebecamaia_p)
- Bruno Padilha (@brunopadz)
- Leandro Grillo (@leandrocgrillo)
Me sigam no Twitter para acompanhar as paradinhas que eu compartilho por lá!
Te ajudei de alguma forma? Me pague um café
Chave Pix: fe60fe92-ecba-4165-be5a-3dccf8a06bfc

