Blueprint - Golang SQS Consumer Performance Tunning
Blueprints são pequenas documentações que eu estruturo em forma de um breve estudo a respeito de algum tema ou ideia específica. Não tem objetivo de ser um artigo estruturado, somente uma breve documentação com exemplos para consultas futuras.
O objetivo deste blueprint é documentar uma evolução incremental de um consumidor SQS em termos de performance.
Cenário
- Objetivo: Otimizar gradualmente um consumidor SQS em Golang.
- Documentar o TPS (Transações por segundo) de cada alternativa
- Documentar os tempos de processamento
- Restrições: o objetivo dos exemplos é apenas metrificar a dinâmica do SQS, sem processamentos adicionais além de
RecebereDeletarda fila.
Produtor de Exemplo
Documentando o exemplo do produtor. Ferramenta usada apenas para gerar massa de testes.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
package main
import (
"context"
"fmt"
"log"
"os"
"sync"
"sync/atomic"
"time"
"github.com/aws/aws-sdk-go-v2/config"
"github.com/aws/aws-sdk-go-v2/service/sqs"
"github.com/aws/aws-sdk-go-v2/service/sqs/types"
"github.com/aws/aws-sdk-go/aws"
)
const (
queueURL = "https://sqs.us-east-1.amazonaws.com/181560427716/nutrition-mock"
// totalMessages = 100_000
totalMessages = 10_000
batchSize = 10
workerCount = 20
)
func main() {
ctx := context.Background()
cfg, err := config.LoadDefaultConfig(ctx)
if err != nil {
log.Fatalf("falha ao carregar AWS config: %v", err)
}
client := sqs.NewFromConfig(cfg)
start := time.Now()
var sentBatches int64
var sentMessages int64
var errBatches int64
jobs := make(chan []types.SendMessageBatchRequestEntry, workerCount)
var wg sync.WaitGroup
for w := 0; w < workerCount; w++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
for batch := range jobs {
input := &sqs.SendMessageBatchInput{
QueueUrl: aws.String(queueURL),
Entries: batch,
}
resp, err := client.SendMessageBatch(ctx, input)
if err != nil || len(resp.Failed) > 0 {
atomic.AddInt64(&errBatches, 1)
log.Printf("[worker %d] erro em batch: %v – falhas: %d", id, err, len(resp.Failed))
} else {
atomic.AddInt64(&sentBatches, 1)
atomic.AddInt64(&sentMessages, int64(len(batch)))
if sentBatches%100 == 0 {
log.Printf("✔ %d batches enviados (%d mensagens)", sentBatches, sentMessages)
}
}
}
}(w)
}
go func() {
defer close(jobs)
var batch []types.SendMessageBatchRequestEntry
for i := 1; i <= totalMessages; i++ {
msg := types.SendMessageBatchRequestEntry{
Id: aws.String(fmt.Sprintf("msg-%d", i)),
MessageBody: aws.String(fmt.Sprintf(`{"index":%d}`, i)),
}
batch = append(batch, msg)
if len(batch) == batchSize {
jobs <- batch
batch = nil
}
}
if len(batch) > 0 {
jobs <- batch
}
}()
wg.Wait()
elapsed := time.Since(start)
log.Println("================================================")
log.Printf("Mensagens enviadas: %d", sentMessages)
log.Printf("Batches enviados: %d", sentBatches)
log.Printf("Batches falhados: %d", errBatches)
log.Printf("Tempo total: %s", elapsed)
log.Println("================================================")
os.Exit(0)
}
Output
1
2
3
4
5
6
2025/05/16 16:18:39 ================================================
2025/05/16 16:18:39 Mensagens enviadas: 100000
2025/05/16 16:18:39 Batches enviados: 10000
2025/05/16 16:18:39 Batches falhados: 0
2025/05/16 16:18:39 Tempo total: 1m24.708619542s
2025/05/16 16:18:39 ================================================
SQS Consumer Simples
O objetivo é experimentar a performance da implementação de um consumidor SQS padrão, o exemplo inicial da documentação. A dinâmica estruturada apenas em receber e deletar a mensagem de forma unitária. Esse exemplo tem o objetivo apenas de fornecer um comparativo para as implementações subsequentes.
Na versão mais básica do consumidor, optou-se pelo fluxo unitário: em um único loop, a aplicação faz chamadas de long-polling ao SQS solicitando apenas uma mensagem por vez (MaxNumberOfMessages=1). Quando uma mensagem é recebida, ela é imediatamente apagada (DeleteMessage) e um contador incrementa o número de mensagens processadas para controle, sem necessidade de atomicidade para manipular o contador em memória. Esse exemplo serve como baseline para comparação, expondo o custo elevado de múltiplas chamadas HTTP unitárias ao SQS.

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
package main
import (
"context"
"log"
"time"
"github.com/aws/aws-sdk-go-v2/aws"
"github.com/aws/aws-sdk-go-v2/config"
"github.com/aws/aws-sdk-go-v2/service/sqs"
)
const (
queueURL = "https://sqs.us-east-1.amazonaws.com/181560427716/nutrition-mock"
totalMessages = 1_000
progressPeriod = 100 // log a cada 100 mensagens
)
func main() {
ctx := context.Background()
// Carrega credenciais e região
cfg, err := config.LoadDefaultConfig(ctx)
if err != nil {
log.Fatalf("falha ao carregar config AWS: %v", err)
}
client := sqs.NewFromConfig(cfg)
var count int
start := time.Now()
for count < totalMessages {
resp, err := client.ReceiveMessage(ctx, &sqs.ReceiveMessageInput{
QueueUrl: aws.String(queueURL),
MaxNumberOfMessages: 1,
WaitTimeSeconds: 10,
})
if err != nil {
log.Printf("erro no ReceiveMessage: %v", err)
continue
}
if len(resp.Messages) == 0 {
continue
}
_, err = client.DeleteMessage(ctx, &sqs.DeleteMessageInput{
QueueUrl: aws.String(queueURL),
ReceiptHandle: resp.Messages[0].ReceiptHandle,
})
if err != nil {
log.Printf("falha ao deletar msg %s: %v", aws.ToString(resp.Messages[0].MessageId), err)
}
// Incrementa o contador de controle
count++
if count%progressPeriod == 0 {
log.Printf("progresso: %d/%d msgs", count, totalMessages)
}
}
elapsed := time.Since(start)
log.Printf("Total de mensagens: %d", count)
log.Printf("Tempo total: %s", elapsed)
log.Printf("TPS Médio: %d", int(count)/int(elapsed.Seconds()))
}
Esse exemplo serve como baseline para comparação, expondo o custo elevado de múltiplas chamadas HTTP unitárias ao SQS.
Outputs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
❯ go run consumer.go
2025/05/16 19:28:24 progresso: 100/1000 msgs
2025/05/16 19:28:58 progresso: 200/1000 msgs
2025/05/16 19:29:31 progresso: 300/1000 msgs
2025/05/16 19:30:05 progresso: 400/1000 msgs
2025/05/16 19:30:39 progresso: 500/1000 msgs
2025/05/16 19:31:13 progresso: 600/1000 msgs
2025/05/16 19:31:47 progresso: 700/1000 msgs
2025/05/16 19:32:21 progresso: 800/1000 msgs
2025/05/16 19:32:56 progresso: 900/1000 msgs
2025/05/16 19:33:31 progresso: 1000/1000 msgs
2025/05/16 19:33:31 Total de mensagens: 1000
2025/05/16 19:33:31 Tempo total: 5m40.611940792s
2025/05/16 19:33:31 TPS Médio: 2
- 1_000 mensagens
- Tempo total: 340s
- TPS Médio: 2 rps por répica do consumidor
Batch Consumer
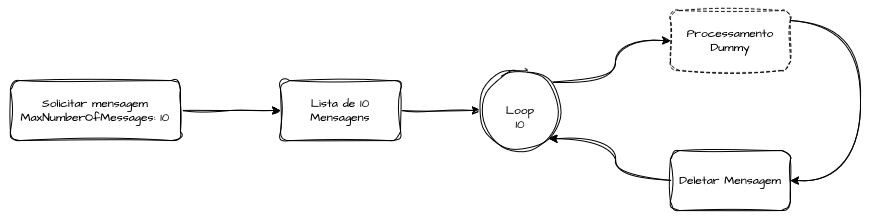
Para reduzir o número de requisições de polling, a segunda versão aumenta MaxNumberOfMessages para 10, fazendo long-polling de até 10 mensagens por chamada. Apesar de reduzirmos em até dez vezes as operações de leitura, o delete ainda ocorre individualmente para cada mensagem dentro do batch. Esse ajuste diminui de forma significativa a latência total de consulta, mas mantém o overhead de confirmações unitárias. Os resultados mostram um ganho consistente de throughput (TPS) em relação ao consumidor simples, comprovando o benefício imediato do batch receive.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
// ...
for count < totalMessages {
resp, err := client.ReceiveMessage(ctx, &sqs.ReceiveMessageInput{
QueueUrl: aws.String(queueURL),
MaxNumberOfMessages: 10, // Batch Size de 10 mensagens
WaitTimeSeconds: 10,
})
if err != nil {
log.Printf("erro no ReceiveMessage: %v", err)
continue
}
if len(resp.Messages) == 0 {
continue
}
for _, message := range resp.Messages {
_, err = client.DeleteMessage(ctx, &sqs.DeleteMessageInput{
QueueUrl: aws.String(queueURL),
ReceiptHandle: message.ReceiptHandle,
})
if err != nil {
log.Printf("falha ao deletar msg %s: %v", aws.ToString(message.MessageId), err)
}
// Incrementa o contador de controle
count++
if count%progressPeriod == 0 {
log.Printf("progresso: %d/%d msgs", count, totalMessages)
}
}
}
// ...
Outputs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
❯ go run consumer_batch.go
2025/05/16 19:55:07 progresso: 100/1000 msgs
2025/05/16 19:55:25 progresso: 200/1000 msgs
2025/05/16 19:55:43 progresso: 300/1000 msgs
2025/05/16 19:56:01 progresso: 400/1000 msgs
2025/05/16 19:56:21 progresso: 500/1000 msgs
2025/05/16 19:56:41 progresso: 600/1000 msgs
2025/05/16 19:57:00 progresso: 700/1000 msgs
2025/05/16 19:57:21 progresso: 800/1000 msgs
2025/05/16 19:57:40 progresso: 900/1000 msgs
2025/05/16 19:57:59 progresso: 1000/1000 msgs
2025/05/16 19:57:59 Total de mensagens: 1000
2025/05/16 19:57:59 Tempo total: 3m10.4659665s
2025/05/16 19:57:59 TPS Médio: 5
- 1_000 mensagens
- Tempo total: 180s
- TPS Médio: 5rps
Worker Pool + Batch Consumer
No terceiro passo, demos um salto de desempenho ao paralelizar todo o processo em múltiplas goroutines. Cada worker roda de forma independente, repetindo o ciclo de ReceiveMessage em batch e deleção unitária até que o contador atômico alcance a meta. Essa abordagem explora a concorrência no cliente Go e distribui as chamadas HTTP simultaneamente, aumentando ainda mais o throughput, mas ainda engargalando na deleção unitária de cada um dos registros processados. Essa estratégia também permite fine tunning, fazendo com que seja possível ajustar o numero de workers concorrentes que cada instância da aplicação irá criar. Foram testados 3 cenários ajustando o critério de workerCount, com 3, 5 e 10 workers, onde conseguimos em cada um deles aumentar ainda mais a vazão de consumo em cada réplica da aplicação, chegando até 47 mensagens por segundo processadas em cada pod.

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
package main
import (
"context"
"log"
"sync"
"sync/atomic"
"time"
"github.com/aws/aws-sdk-go-v2/aws"
"github.com/aws/aws-sdk-go-v2/config"
"github.com/aws/aws-sdk-go-v2/service/sqs"
)
const (
queueURL = "https://sqs.us-east-1.amazonaws.com/181560427716/nutrition-mock"
totalMessages = 1_000
batchSize = 10
workerCount = 10
progressPeriod = 100 // log a cada 100 mensagens
)
func main() {
ctx := context.Background()
cfg, err := config.LoadDefaultConfig(ctx)
if err != nil {
log.Fatalf("falha ao carregar config AWS: %v", err)
}
client := sqs.NewFromConfig(cfg)
var processed int64
var wg sync.WaitGroup
start := time.Now()
// lança os workers
for i := 1; i <= workerCount; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
for {
// Checa se o total de mensagens processadas já atingiu o limite - POC
cur := atomic.LoadInt64(&processed)
if cur >= totalMessages {
return
}
resp, err := client.ReceiveMessage(ctx, &sqs.ReceiveMessageInput{
QueueUrl: aws.String(queueURL),
MaxNumberOfMessages: batchSize,
WaitTimeSeconds: 1,
VisibilityTimeout: 30,
})
if err != nil {
log.Printf("[worker %d] ReceiveMessage erro: %v", id, err)
continue
}
if len(resp.Messages) == 0 {
continue
}
for _, msg := range resp.Messages {
_, err := client.DeleteMessage(ctx, &sqs.DeleteMessageInput{
QueueUrl: aws.String(queueURL),
ReceiptHandle: msg.ReceiptHandle,
})
if err != nil {
log.Printf("[worker %d] falha ao deletar msg %s: %v", id, aws.ToString(msg.MessageId), err)
continue
}
// incrementa contador
newCount := atomic.AddInt64(&processed, 1)
if newCount%progressPeriod == 0 {
log.Printf("progresso: %d/%d mensagens", newCount, totalMessages)
}
if newCount >= totalMessages {
return
}
}
}
}(i)
}
// espera os workers terminarem
wg.Wait()
elapsed := time.Since(start)
log.Printf("Total de mensagens: %d", processed)
log.Printf("Tempo total: %s", elapsed)
log.Printf("TPS Médio: %d", int(processed)/int(elapsed.Seconds()))
}
Outputs - Worker Pool: 3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
❯ go run consumer_worker_pool.go
2025/05/16 20:08:45 progresso: 100/1000 mensagens
2025/05/16 20:08:51 progresso: 200/1000 mensagens
2025/05/16 20:08:57 progresso: 300/1000 mensagens
2025/05/16 20:09:03 progresso: 400/1000 mensagens
2025/05/16 20:09:09 progresso: 500/1000 mensagens
2025/05/16 20:09:15 progresso: 600/1000 mensagens
2025/05/16 20:09:21 progresso: 700/1000 mensagens
2025/05/16 20:09:27 progresso: 800/1000 mensagens
2025/05/16 20:09:33 progresso: 900/1000 mensagens
2025/05/16 20:09:39 progresso: 1000/1000 mensagens
2025/05/16 20:09:40 Total de mensagens: 1000
2025/05/16 20:09:40 Tempo total: 1m2.079631791s
2025/05/16 20:09:40 TPS Médio: 16
Outputs - Worker Pool: 5
1
2
3
4
5
6
7
8
9
10
11
12
13
14
❯ go run consumer_worker_pool.go
2025/05/16 20:10:15 progresso: 100/1000 mensagens
2025/05/16 20:10:18 progresso: 200/1000 mensagens
2025/05/16 20:10:21 progresso: 300/1000 mensagens
2025/05/16 20:10:25 progresso: 400/1000 mensagens
2025/05/16 20:10:29 progresso: 500/1000 mensagens
2025/05/16 20:10:32 progresso: 600/1000 mensagens
2025/05/16 20:10:36 progresso: 700/1000 mensagens
2025/05/16 20:10:40 progresso: 800/1000 mensagens
2025/05/16 20:10:43 progresso: 900/1000 mensagens
2025/05/16 20:10:47 progresso: 1000/1000 mensagens
2025/05/16 20:10:48 Total de mensagens: 1000
2025/05/16 20:10:48 Tempo total: 38.013904167s
2025/05/16 20:10:48 TPS Médio: 26
Outputs - Worker Pool: 10
1
2
3
4
5
6
7
8
9
10
11
12
13
14
❯ go run consumer_worker_pool.go
2025/05/16 20:11:14 progresso: 100/1000 mensagens
2025/05/16 20:11:16 progresso: 200/1000 mensagens
2025/05/16 20:11:18 progresso: 300/1000 mensagens
2025/05/16 20:11:19 progresso: 400/1000 mensagens
2025/05/16 20:11:22 progresso: 500/1000 mensagens
2025/05/16 20:11:23 progresso: 600/1000 mensagens
2025/05/16 20:11:25 progresso: 700/1000 mensagens
2025/05/16 20:11:28 progresso: 800/1000 mensagens
2025/05/16 20:11:30 progresso: 900/1000 mensagens
2025/05/16 20:11:32 progresso: 1000/1000 mensagens
2025/05/16 20:11:34 Total de mensagens: 1000
2025/05/16 20:11:34 Tempo total: 21.779013417s
2025/05/16 20:11:34 TPS Médio: 47
Worker Pool + Batch Consumer + Batch Delete
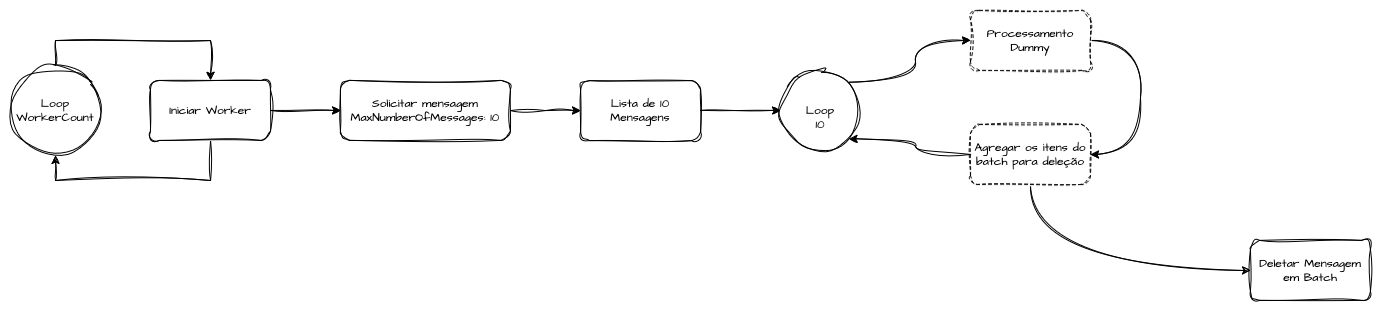
A otimização seguinte combina paralelismo e deleção em lote. Cada worker continua fazendo ReceiveMessage em batches de até 10 mensagens, mas passa a apagar todo o lote de uma só vez com DeleteMessageBatch. Dessa forma, reduzimos drasticamente tanto o número de chamadas de leitura quanto o de confirmações de processamento. Essa versão alcançou o maior throughput comparado a paralelização apenas do consumo, comprovando que o padrão “batch receive + batch delete” é o mais eficiente para cenários de alto volume no SQS.
Outputs - Worker Pool: 5
1
2
3
4
5
6
7
8
9
10
11
12
13
❯ go run consumer_batch_delete.go
2025/05/16 20:13:25 progresso: 100/1000 msgs
2025/05/16 20:13:25 progresso: 200/1000 msgs
2025/05/16 20:13:26 progresso: 300/1000 msgs
2025/05/16 20:13:27 progresso: 400/1000 msgs
2025/05/16 20:13:27 progresso: 500/1000 msgs
2025/05/16 20:13:28 progresso: 600/1000 msgs
2025/05/16 20:13:29 progresso: 700/1000 msgs
2025/05/16 20:13:29 progresso: 800/1000 msgs
2025/05/16 20:13:31 progresso: 1000/1000 msgs
2025/05/16 20:13:32 Total de mensagens: 1000
2025/05/16 20:13:32 Tempo total: 8.328690625s
2025/05/16 20:13:32 TPS Médio: 125
Channels e GoRoutines + Batch Consumer + Batch Delete
A estratégia final para essa PoC se baseia em implementar um channel que receba as mensagens em batch e as processem em paralelo ao consumo de mensagens. Dessa forma conseguimos aumentar o throughput de interações de solicitação de mensagens para o SQS e realizar a tratativa dos batchs com paralelismo e concorrência. Ainda aplicamos o split de workpools para otimizar ainda mais o uso de recursos para dar vazão as mensagens na Queue, e utilizando o delete em batch para diminuir as solicitações de confirmação de processamento também.

Por fim, a estratégia mais sofisticada desacopla totalmente a etapa de fetching da de processamento, usando dois pipelines de goroutines interligados por um canal de batches. No primeiro estágio, um conjunto de fetchers realiza ReceiveMessage em batch* de 10 mensagens e empurra cada slice para o canal para ser consumido de forma assincrona, aumentando ainda mais a vazão do consumo. No segundo estágio, outro conjunto de deleters consome esses batches, apaga em lote e incrementa de forma atômica um contador compartilhado. Um canal de sinalização fecha o pipeline assim que a meta de mensagens é atingida, garantindo parada imediata sem perda de dados, processando 200 TPS por replica, consumindo 1000 mensagens em 5s Esse modelo apresentou o maior TPS nos testes de longa duração, onde foram inseridas 100.000 mensagens que foram processadas em 2m57s, atingindo 564 tps de processamento por unidade computacional, validando que a combinação de paralelismo, batching e pipelines desacoplados é a abordagem ideal para tuning de consumidores SQS em Go.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
package main
import (
"context"
"log"
"sync"
"sync/atomic"
"time"
"github.com/aws/aws-sdk-go-v2/aws"
"github.com/aws/aws-sdk-go-v2/config"
"github.com/aws/aws-sdk-go-v2/service/sqs"
"github.com/aws/aws-sdk-go-v2/service/sqs/types"
)
const (
queueURL = "https://sqs.us-east-1.amazonaws.com/181560427716/nutrition-mock"
totalMessages = 100_000 // meta de consumo
batchSize = 10 // até 10 mensagens por ReceiveMessage
workerCount = 10 // paralelismo
progressPeriod = 1000 // log a cada 100 mensagens
)
func main() {
ctx := context.Background()
cfg, err := config.LoadDefaultConfig(ctx)
if err != nil {
log.Fatalf("falha ao carregar AWS config: %v", err)
}
client := sqs.NewFromConfig(cfg)
// canal de batches e sinal de término
batchCh := make(chan []types.Message)
doneCh := make(chan struct{})
var once sync.Once
signalDone := func() { once.Do(func() { close(doneCh) }) }
var processed int64
start := time.Now()
var fetchWg, deleteWg sync.WaitGroup
for i := 1; i <= workerCount; i++ {
fetchWg.Add(1)
go func(id int) {
defer fetchWg.Done()
for {
// Trava do teste
if atomic.LoadInt64(&processed) >= totalMessages {
return
}
resp, err := client.ReceiveMessage(ctx, &sqs.ReceiveMessageInput{
QueueUrl: aws.String(queueURL),
MaxNumberOfMessages: batchSize,
WaitTimeSeconds: 1,
VisibilityTimeout: 60,
})
if err != nil {
log.Printf("[%d] Receive erro: %v", id, err)
time.Sleep(time.Second)
continue
}
if len(resp.Messages) == 0 {
continue
}
// envia batch para o channel de processamento
select {
case batchCh <- resp.Messages:
case <-doneCh:
return
}
}
}(i)
}
// quando todos os fetchers terminarem, fechamos batchCh
go func() {
fetchWg.Wait()
close(batchCh)
}()
// Inicia os Workers de Processamento
for i := 1; i <= workerCount; i++ {
deleteWg.Add(1)
go func(id int) {
defer deleteWg.Done()
// Consome as mensagens do SQS através do Channel de forma assincrona
for batch := range batchCh {
entries := make([]types.DeleteMessageBatchRequestEntry, 0, len(batch))
for _, msg := range batch {
entries = append(entries, types.DeleteMessageBatchRequestEntry{
Id: msg.MessageId,
ReceiptHandle: msg.ReceiptHandle,
})
}
if _, err := client.DeleteMessageBatch(ctx, &sqs.DeleteMessageBatchInput{
QueueUrl: aws.String(queueURL),
Entries: entries,
}); err != nil {
log.Printf("[%d] DeleteBatch erro: %v", id, err)
}
newCount := atomic.AddInt64(&processed, int64(len(entries)))
if newCount >= totalMessages {
signalDone()
}
if newCount%progressPeriod == 0 || newCount >= totalMessages {
log.Printf("progresso: %d/%d msgs", newCount, totalMessages)
}
}
}(i)
}
deleteWg.Wait()
elapsed := time.Since(start)
final := atomic.LoadInt64(&processed)
log.Printf("Total de mensagens: %d", final)
log.Printf("Tempo total: %s", elapsed)
log.Printf("TPS Médio: %d", int(final)/int(elapsed.Seconds()))
}
Outputs - Worker Pool: 5
1
2
3
4
5
6
7
8
9
10
11
12
❯ go run consumer_channels.go
2025/05/16 20:15:08 progresso: 100/1000 msgs
2025/05/16 20:15:08 progresso: 200/1000 msgs
2025/05/16 20:15:08 progresso: 300/1000 msgs
2025/05/16 20:15:09 progresso: 400/1000 msgs
2025/05/16 20:15:09 progresso: 500/1000 msgs
2025/05/16 20:15:09 progresso: 600/1000 msgs
2025/05/16 20:15:10 progresso: 900/1000 msgs
2025/05/16 20:15:11 progresso: 1000/1000 msgs
2025/05/16 20:15:12 Total de mensagens: 1000
2025/05/16 20:15:12 Tempo total: 5.310673458s
2025/05/16 20:15:12 TPS Médio: 200
Outputs - Worker Pool: 10
1
2
3
4
5
6
7
8
9
10
11
12
13
❯ go run consumer_channels.go
2025/05/16 20:15:47 progresso: 100/1000 msgs
2025/05/16 20:15:47 progresso: 200/1000 msgs
2025/05/16 20:15:47 progresso: 300/1000 msgs
2025/05/16 20:15:47 progresso: 400/1000 msgs
2025/05/16 20:15:48 progresso: 500/1000 msgs
2025/05/16 20:15:48 progresso: 600/1000 msgs
2025/05/16 20:15:48 progresso: 700/1000 msgs
2025/05/16 20:15:49 progresso: 800/1000 msgs
2025/05/16 20:15:49 progresso: 1000/1000 msgs
2025/05/16 20:15:50 Total de mensagens: 1000
2025/05/16 20:15:50 Tempo total: 4.201653667s
2025/05/16 20:15:50 TPS Médio: 250
Para fazer um teste mais longo, realizei um teste com 100.000 mensagens na fila para validar uma execução mais prolongada.
Outputs - Worker Pool: 10 e 100.000 mensagens
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
❯ go run consumer_channels.go
2025/05/16 20:19:42 progresso: 1000/100000 msgs
2025/05/16 20:19:43 progresso: 2000/100000 msgs
2025/05/16 20:19:45 progresso: 3000/100000 msgs
2025/05/16 20:19:47 progresso: 4000/100000 msgs
2025/05/16 20:19:49 progresso: 5000/100000 msgs
2025/05/16 20:19:51 progresso: 6000/100000 msgs
2025/05/16 20:19:52 progresso: 7000/100000 msgs
2025/05/16 20:19:54 progresso: 8000/100000 msgs
// ...
2025/05/16 20:22:24 progresso: 94000/100000 msgs
2025/05/16 20:22:26 progresso: 95000/100000 msgs
2025/05/16 20:22:28 progresso: 96000/100000 msgs
2025/05/16 20:22:30 progresso: 97000/100000 msgs
2025/05/16 20:22:31 progresso: 98000/100000 msgs
2025/05/16 20:22:35 progresso: 100000/100000 msgs
2025/05/16 20:22:36 Total de mensagens: 100000
2025/05/16 20:22:36 Tempo total: 2m57.05202975s
2025/05/16 20:22:36 TPS Médio: 564
Resultados e Comparações
Aqui está a tabela resumindo os resultados de todas as variações testadas:
| Implementação | Workers | Mensagens | Tempo Total | TPS Médio |
|---|---|---|---|---|
| Consumidor Simples | 1 | 1 000 | 5m40.612s | 2 |
| Batch Consumer | 1 | 1 000 | 3m10.466s | 5 |
| Worker Pool + Batch Consumer | 3 | 1 000 | 1m2.080s | 16 |
| Worker Pool + Batch Consumer | 5 | 1 000 | 0m38.014s | 26 |
| Worker Pool + Batch Consumer | 10 | 1 000 | 0m21.779s | 47 |
| Worker Pool + Batch Consumer + Batch Delete | 5 | 1 000 | 0m8.329s | 125 |
| Channels & Goroutines + Batch Consumer + Batch Delete | 5 | 1 000 | 0m5.311s | 200 |
| Channels & Goroutines + Batch Consumer + Batch Delete | 10 | 1 000 | 0m4.202s | 250 |
| Channels & Goroutines + Batch Consumer + Batch Delete (long run) | 10 | 100 000 | 2m57.052s | 564 |
Referências
Simplifying Message Queueing with Golang and Amazon SQS
Boas Práticas de Uso de Channels e Go Routines
SQS Consumer Design: Achieving High Scalability while managing concurrency in Go
