
Staff Framework - Tornando Desejos em Metas Verificáveis (SMART Method)

Uma das principais tarefas de um engenheiro que ocupa uma cadeira de Staff ou Especialista é transformar desejos abstratos das camadas executiva e estratégica em dados e tarefas palpáveis, que possam ser direcionados aos times de engenharia de forma tangível e metrificável. Durante meu primeiro ano na cadeira de Staff, enfrentei diversos desafios que foram muito mais árduos do que deveriam ter sido, justamente por não ter essa clareza de visão. Eu sempre considerei direcionamentos como “Precisamos melhorar o login”, “Nosso checkout está lento”, “A experiência do usuário está ruim”, “Precisamos escalar a plataforma”, “Temos que reduzir incidentes” e “A arquitetura precisa ser mais resiliente” sinais de despreparo da liderança. Mas não eram. Era o exercício do meu papel que estava sendo solicitado naquele momento.
O problema dessas frases não é a intenção. A intenção geralmente é legítima. O problema é que elas não dizem exatamente o que precisa mudar, quanto precisa mudar, onde está o problema, em quais condições ele aparece, qual é o estado desejado e como saberemos que houve uma melhora. E é nosso papel traduzir tudo isso. Às vezes, a própria alta liderança não tem as respostas, e cabe a nós levar essa visão até essa camada.
Depois de algum tempo, conheci o método SMART durante meu MBA. Inicialmente, deixei o assunto passar nas primeiras horas de explicação do professor por pura prepotência, motivada por um sentimento de “mais um termo de coach emocionado”. Até que, em um dos slides, o professor abordou a perspectiva de que o método SMART poderia ser um grande aliado na tradução de sentimentos vagos dos clientes e metas abstratas da liderança em compromissos verificáveis e metrificáveis. Isso acendeu uma luz e me levou a reassistir à aula no dia seguinte e a buscar outras perspectivas sobre o método.
Desde então, utilizo o SMART como um modelo mental para trafegar entre boards executivos e técnicos, transportando dados e intenções para ambos os lados e direcionando ações de curto, médio e longo prazo junto aos times de engenharia.
O que é o Método SMART?
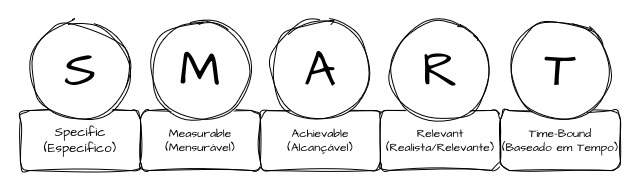
O Método SMART é um acrônimo formado por:
- S — Specific: específico
- M — Measurable: mensurável
- A — Achievable: alcançável
- R — Relevant: relevante
- T — Time-bound: limitado no tempo
A ideia do método é oferecer uma forma simples de transformar intenções em metas e escrevê-las com clareza. Uma boa meta precisa deixar claro qual problema será atacado, qual métrica será utilizada, qual resultado é esperado, por que isso importa e até quando ele deve ser alcançado. É justamente o inverso do que vemos em exemplos como “Nossa home está ruim”, “Nosso login demora muito” ou “O checkout está lento”.
Em ambientes corporativos, especialmente na engenharia de software, muitas demandas chegam como desejos vagos. Esses desejos podem representar dores reais, mas ainda não constituem metas. Eles não indicam qual parte do sistema está ruim, qual métrica está degradada, qual baseline será utilizada, qual impacto precisa ser reduzido, qual trade-off é aceitável ou qual critério indicará que o problema foi resolvido.
É nesse ponto que o SMART se torna um framework tático e estratégico para profissionais Staff+. O método funciona como uma ponte entre a intenção estratégica e a execução técnica. Ele ajuda a converter uma percepção executiva em um contrato de trabalho verificável para os times de engenharia. Em vez de apenas aceitar uma frase como “Precisamos reduzir custos”, o especialista passa a decompor essa intenção em escopo, métrica, impacto, viabilidade, prazo e critério de sucesso.
Framework mental: transformando abstração em dados por meio de perguntas
Precisamos entender o “desejo”. O desejo, por si só, é uma intenção ampla e não diz muita coisa:
“O checkout está lento.”
Uma boa meta nasce de perguntas melhores. Antes de escrever qualquer tarefa, precisamos decompor o desejo inicial. Precisamos, então, convertê-lo em uma dor ou em um problema real. Essa será a primeira camada observável dessa tradução. Caso ela não exista ou esteja expressa com outras palavras, é o momento de construí-la em comum acordo com todos os envolvidos.
Qual é o problema real de o login estar ruim? Qual é o impacto real disso para o produto ou para o cliente?
Primeira pergunta: o que exatamente está ruim? — Delimitando o problema
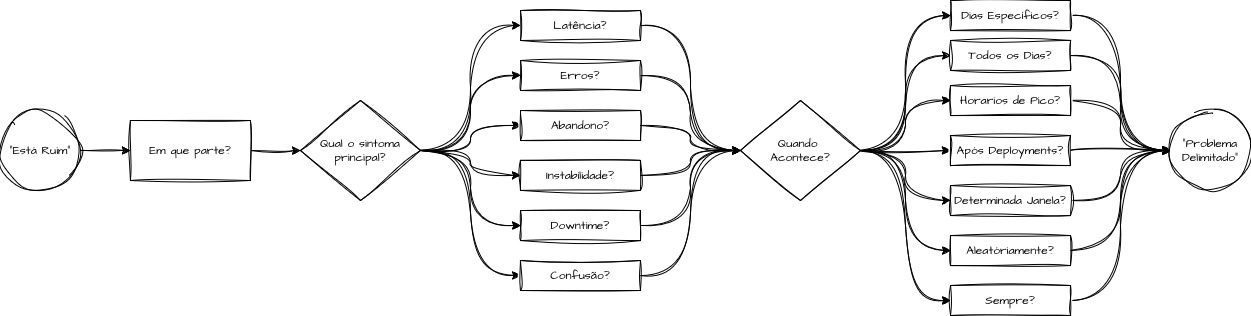
Uma boa meta, independentemente de ser SMART ou não, deve ser sempre auditada por meio de perguntas que a tornem melhor. Para isso, precisamos utilizar perguntas para decompor o desejo inicial. O desejo de “Precisamos melhorar o checkout” não esclarece “o que está ruim”, “o quanto está ruim”, “qual parte está ruim” nem, principalmente, “o que é considerado bom?”.
Para converter esse desejo em tópicos mensuráveis, precisamos trabalhar esses detalhes. Podemos, então, elaborar perguntas como: “Qual parte da jornada apresenta um problema?”, “O problema está relacionado à demora, a erros, à experiência, ao excesso de etapas, à confusão do usuário ou a todas as alternativas anteriores?”, “Quando isso acontece? Existe um padrão?”, “Isso acontece em determinados horários?”, “O problema ocorre após deployments?” e, entrando em aspectos mais técnicos, “O checkout está lento em todas as etapas ou apenas no cálculo do frete, no pagamento ou na confirmação do pedido?”, “Isso ocorre sempre ou apenas em horários específicos? Em caso afirmativo, quais?” e “O problema é técnico, operacional, financeiro ou relacionado à experiência?”.
Respondendo a essas perguntas, podemos começar a transformar:
“O checkout está ruim.”
Em algo mais específico:
“A etapa de pagamento do checkout apresenta saturação durante os horários de pico. Esses períodos ocorrem em dias úteis, entre 12h e 18h, e em datas comemorativas.”
Dessa forma, já temos um alvo técnico claramente delimitado. A etapa de pagamento passa a ser isolada como objeto de análise dentro de uma jornada mais ampla de checkout, que pode envolver uma série de outros componentes e fluxos em uma operação complexa.
Segunda pergunta: o quanto está ruim? — Metrificando o problema
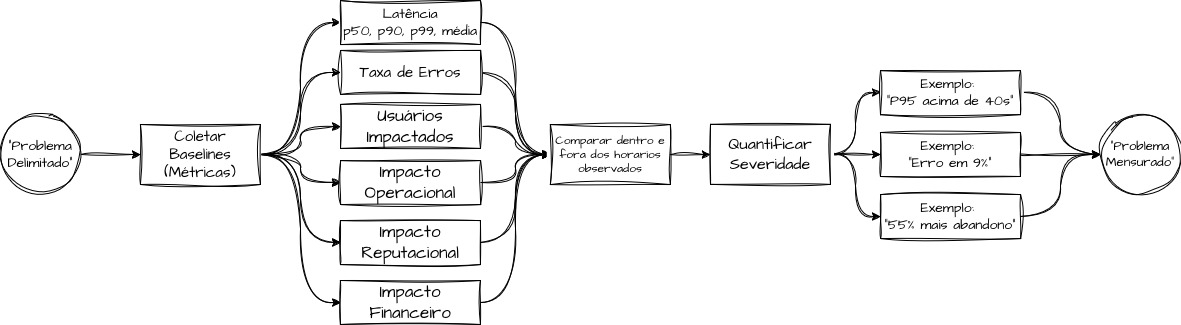
Aqui, saímos da percepção e entramos, de fato, na medição. Para saber o quanto está ruim, precisamos estabelecer baselines do comportamento padrão e responder a perguntas como: “Qual é o valor atual da métrica?”, “Quais são a média, o p95, o p99 e a taxa de erro dentro e fora dos períodos de saturação?”, “Quantos usuários são impactados?” e “Qual é o impacto operacional ou reputacional?”.
Dessa forma, conseguimos elucidar o problema com ainda mais senioridade e precisão.
Perceba que essas perguntas podem transformar o desejo de um “checkout ruim” em algo mais específico:
“A etapa de pagamento do checkout apresenta p95 acima de 40 segundos durante os horários de pico. Nossa taxa de erro sobe para 9% nesses períodos. Essas ocorrências são registradas em dias úteis, entre 12h e 18h, e se estendem por mais horas em datas comemorativas. Nesses intervalos, observamos um aumento de 55% na taxa de abandono do checkout pelos clientes.”
Agora que já pavimentamos o desejo, transformando-o em algo mais próximo de um problema com o qual um time de engenharia deve lidar, precisamos definir os critérios de aceite e as metas relacionadas à sua resolução.
Terceira pergunta: o quanto é bom? — Estabelecendo a meta

Uma meta precisa estar associada a um estado desejado. A definição desses valores ajuda a estabelecer marcos para a resolução do problema elucidado anteriormente. Depois de descobrir “o que está ruim” e “o quanto está ruim”, precisamos definir “o que é bom”.
Após identificarmos o problema e as métricas que traduzem a percepção inicial em uma realidade observável, precisamos responder a perguntas como: “Quais são os valores aceitáveis?”, “Quais são os valores ideais?”, “Existe algum benchmark de mercado para isso?”, “Quais são os SLAs e SLOs esperados?” e “Quanto de degradação é tolerável?”.
Com essas respostas, ou ao menos parte delas, podemos escrever uma meta para o problema. O ideal é que essa meta represente um resultado realmente palpável e compatível com a realidade, o investimento, o custo, o tempo e os recursos disponíveis para sua resolução. Ela precisa ser parecida com:
“Precisamos reduzir o tempo de resposta no p95 para quatro segundos e manter a taxa de erro abaixo de 0,1% durante os períodos de pico, conforme os contratos de nível de serviço. Nossa taxa de abandono do checkout deve permanecer abaixo de 10%, independentemente do período, conforme as metas definidas pelo time de vendas.”
Com essas três primeiras perguntas, já temos os insumos necessários para identificar o problema e os marcos necessários para tratá-lo por meio de uma meta real e mensurável. Agora, precisamos “abrir o capô” e realizar um aprofundamento técnico para entender em quais componentes e camadas devemos atuar para resolver o problema.
Quarta pergunta: como e onde o problema acontece? — Elaborando hipóteses
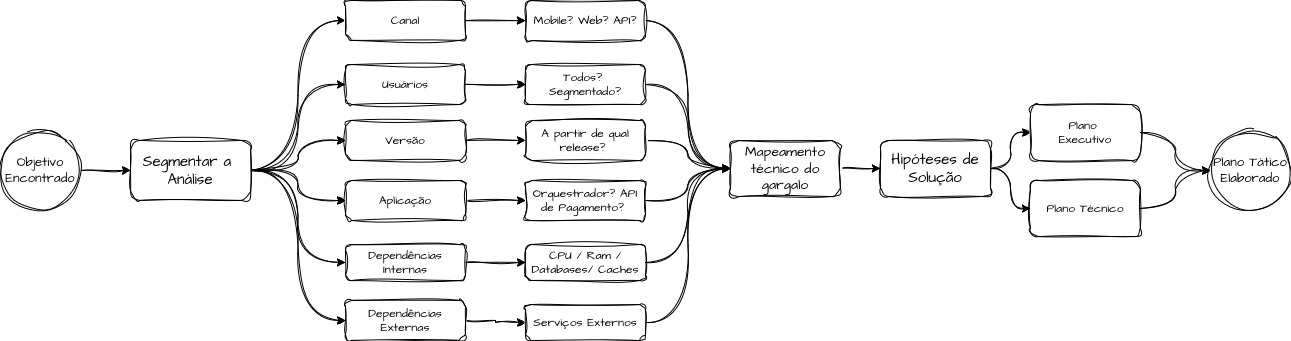
Nem todo problema é global. Muitas vezes, ele está restrito a um segmento específico. Isso é ainda mais comum em arquiteturas em camadas e em sistemas altamente distribuídos. Nessa etapa, precisamos descobrir onde exatamente o problema acontece. Para isso, podemos utilizar o mesmo ferramental empregado nas perguntas anteriores para explorar as diferentes camadas dos sistemas envolvidos e identificar, sob a perspectiva da engenharia, onde está o problema: em quais serviços, componentes, camadas, endpoints, chamadas, comandos ou processos ele se manifesta.
Para isso, precisamos explorar perguntas como: “O problema ocorre no mobile, na web ou na API?”, “Ele afeta todos os clientes ou apenas um segmento?”, “Está concentrado em uma versão específica do aplicativo?”, “Afeta todos os usuários, apenas os antigos ou apenas os novos?”, “Clientes pequenos também são afetados ou somente os grandes?”, “Em qual serviço está concentrada a maior parte do gargalo?”, “Em qual etapa da execução da transação gastamos mais tempo?”, “Em qual etapa ocorre o maior número de erros?” e “Qual processo ou dependência causa ou agrava o cenário?”.
A ideia dessa etapa é coletar datapoints técnicos para formular hipóteses de solução e construir uma visão estratégica e outra tática. São duas perspectivas sobre o mesmo planejamento, cada uma direcionada a um tipo diferente de fórum corporativo: o executivo e o técnico.
“A lentidão no checkout ocorre entre 18h e 22h, quando o volume ultrapassa 2.000 requisições por segundo e aumenta a dependência do serviço de antifraude. Nesse cenário, o p95 do tempo de resposta desse serviço sobe de 20 ms para dois segundos. Quando o tempo de resposta ultrapassa um segundo, são realizadas até 20 tentativas de retry mantidas em memória. Também identificamos um ponto de saturação no serviço responsável por orquestrar os status do pagamento. O banco de dados chega a 98% de utilização de CPU, e as queries executadas nele representam 80% do tempo total da transação.”
Quinta pergunta: até quando precisamos melhorar? — Definindo prazos
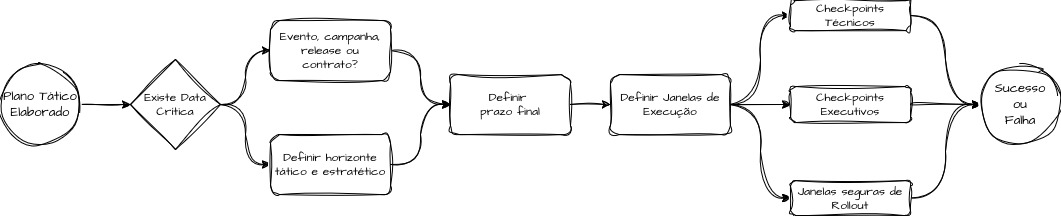
Nesta etapa, precisamos levantar os critérios de urgência e os prazos relacionados ao problema. Precisamos responder a perguntas como: “Qual é o nível de urgência?”, “Existe alguma data importante relacionada a essa melhoria, como um evento, uma release ou uma campanha?”, “Precisamos corrigir o problema até uma janela específica?”, “Quais são as janelas seguras para o rollout?” e “A meta é emergencial, tática ou estratégica?”.
“Precisamos melhorar a experiência do checkout, atingindo os níveis acordados, até o início das campanhas de Black Friday. As campanhas começam no início de novembro. Portanto, temos três semanas para elaborar a proposta e implementar a solução.”
Aplicando o SMART ao framework de perguntas
Depois de transformar o desejo abstrato em um problema observável, conseguimos aplicar o SMART de forma muito mais madura. A metodologia SMART não é mágica, muito menos simples ou automática quando aplicada ao processo de escrita de metas. Ela não deve ser usada como uma fórmula superficial para produzir uma frase bonita, mas como uma camada de consolidação dos dados, depois que já compreendemos minimamente o problema, o impacto, as métricas, o contexto, as restrições e o prazo.
Em nosso exemplo, começamos com um desejo bastante abstrato:
“O checkout está ruim ou lento.”
Agora, podemos consolidar no SMART os dados levantados por meio das perguntas anteriores.
Specific: tornando o objetivo específico
O primeiro passo é tornar a meta específica. Isso significa remover ambiguidades e delimitar claramente o objeto da mudança. Não estamos mais falando em “melhorar o checkout” como um todo. Estamos falando de uma parte específica da jornada, em uma condição específica, com sintomas específicos e impacto mensurável.
Uma meta um pouco mais específica seria:
“Melhorar a performance do checkout.”
Perceba que a frase ainda é fraca, pois não indica qual parte do checkout está ruim. Pode ser o carrinho, o cálculo do frete, a aplicação de cupons, a reserva de estoque, o antifraude, o pagamento, a confirmação do pedido ou a emissão da nota fiscal. Também não esclarece se o problema está relacionado à latência, a erros, à indisponibilidade, à experiência do usuário ou ao abandono. Precisamos tornar essa meta específica um pouco mais orientada por dados:
“Melhorar a performance e a estabilidade da etapa de pagamento do checkout durante os horários de pico, reduzindo a latência, a taxa de erro e o abandono de clientes nessa etapa da jornada.”
Ainda podemos ser mais específicos, caso necessário, evitando, contudo, tornar a meta excessivamente extensa:
“Reduzir a saturação da etapa de pagamento do checkout durante os horários de pico, atuando sobre o serviço de antifraude, o orquestrador dos status de pagamento, a política de retries e as queries responsáveis pela maior parte do tempo da transação.”
Measurable: definindo métricas reais
Depois de tornar o objetivo específico, precisamos definir como a melhoria será medida. Esse é o ponto em que uma meta deixa de ser uma opinião e passa a ser auditável. A partir dos levantamentos realizados, já temos alguns números importantes que traduzem o desejo inicial em evidências:
- A etapa de pagamento do checkout apresenta p95 acima de 40 segundos durante os horários de pico.
- A taxa de erro sobe para 9% durante esses períodos.
- A taxa de abandono do checkout pelos clientes aumenta em 55%.
- O p95 do tempo de resposta do serviço de antifraude sobe de 20 ms para dois segundos.
- O banco de dados utilizado na orquestração dos pagamentos chega a 98% de utilização de CPU.
- As queries executadas no banco de dados representam 80% do tempo total da transação nessa etapa do serviço.
Essas métricas são valiosas porque ajudam a separar percepção de evidência. A frase “O checkout está lento” pode gerar debates subjetivos. Já a afirmação “O p95 está acima de 40 segundos na etapa de pagamento” muda completamente o nível da conversa.
A partir desses dados, podemos definir métricas principais e métricas auxiliares.
As métricas principais são aquelas que indicam se o objetivo final foi atingido:
- Latência p95 da etapa de pagamento.
- Taxa de erro da etapa de pagamento.
- Taxa de abandono do checkout durante o pagamento.
As métricas auxiliares são aquelas que ajudam a explicar as causas do problema ou a validar as hipóteses técnicas:
- Latência p95 do serviço de antifraude.
- Quantidade de retries por transação.
- Utilização de CPU do banco de dados.
- Tempo de execução das queries críticas.
- Tempo gasto no orquestrador dos status de pagamento.
- Throughput, em requisições por segundo, durante os horários de pico.
Com isso, conseguimos transformar a meta em algo mensurável:
“Reduzir a latência p95 da etapa de pagamento do checkout de 40 segundos para, no máximo, quatro segundos durante os horários de pico, mantendo a taxa de erro abaixo de 0,1% e a taxa de abandono do checkout abaixo de 10%.”
Agora, a meta possui números e critérios objetivos. Ela pode ser acompanhada, discutida, contestada e validada em produção.
Achievable: validando se a meta é alcançável
Uma meta precisa ser alcançável dentro da realidade de tempo, custo, arquitetura, equipe, dependências e maturidade operacional e tecnológica. Caso exija uma refatoração complexa, a substituição de tecnologias ou uma rearquitetura, essas mudanças precisam ser viáveis dentro do orçamento e do prazo disponíveis. Temos tempo e pessoas para isso? As pessoas possuem os conhecimentos necessários? Conseguimos priorizar essa iniciativa? Existem atividades e projetos que podem ser despriorizados para que seja possível alocar profissionais nesse movimento?
Em nosso exemplo, reduzir o p95 de 40 segundos para quatro segundos é uma mudança agressiva. Isso pode ser possível, mas precisa ser validado considerando as condições citadas. O time precisa entender se o problema está em pontos sob seu controle ou se a solução depende de fornecedores, contratos, mudanças estruturais ou grandes refatorações.
- Temos controle sobre o serviço de antifraude ou ele é uma dependência externa?
- Conseguimos reduzir a quantidade de retries sem aumentar as falhas percebidas pelo usuário?
- As queries críticas podem ser otimizadas por meio de índices, refatorações ou mudanças no modelo de acesso?
- O orquestrador dos status de pagamento pode ser desacoplado ou otimizado?
- O banco de dados pode ser melhorado por meio de tuning ou exige uma mudança arquitetural?
- O prazo de três semanas permite implementar uma solução definitiva ou apenas uma mitigação segura?
- Existe o risco de piorar a consistência, a segurança ou a experiência do usuário ao otimizar esse fluxo?
Esse ponto é importante porque muitas metas são escritas como se a organização pudesse simplesmente escolher o resultado desejado, ignorando a realidade do sistema. Uma meta inalcançável seria:
“Reduzir imediatamente a latência p95 do checkout de 40 segundos para 500 milissegundos, zerar a taxa de erro e eliminar completamente o abandono do checkout em três semanas.”
Essa meta pode ser ambiciosa e soar bem em discussões executivas, mas ignora possíveis limitações. Em sistemas distribuídos, especialmente em jornadas com dependências externas, como serviços de antifraude, gateways de pagamento, bancos de dados, sistemas de mensageria e serviços legados, nem toda melhoria pode ser entregue em um único ciclo. Muitas vezes, a iniciativa precisa ser dividida e tratada em etapas, distribuídas em diferentes horizontes de tempo e organizadas por prioridade.
Uma meta mais palpável seria:
“Reduzir o p95 do tempo de resposta da etapa de pagamento de 40 segundos para, no máximo, quatro segundos em três semanas, priorizando a otimização das queries, a redução de retries excessivos, a mitigação da saturação do banco de dados e a proteção do fluxo contra a degradação do serviço de antifraude.”
Essa versão ainda é ambiciosa, mas já reconhece o caminho técnico. Ela não promete uma reescrita completa do checkout. Ela propõe atuar sobre os principais gargalos já identificados.
Também podemos trabalhar com metas distribuídas em horizontes diferentes, como o tático, de curto prazo, e o estratégico, de longo prazo.
Meta tática: “Reduzir a latência p95 da etapa de pagamento para, no máximo, quatro segundos em três semanas, antes do início da campanha de Black Friday.”
Meta estratégica: “Redesenhar a arquitetura de pagamento para reduzir o acoplamento com o serviço de antifraude, o banco de dados e o orquestrador dos status de pagamento, garantindo maior resiliência nos próximos ciclos promocionais.”
Relevant: alinhando a meta aos objetivos principais do negócio
Uma meta SMART precisa ser relevante para os interesses e objetivos da instituição. Isso significa que ela deve estar associada a algum impacto real sobre os objetivos da empresa ou da área. Esse alinhamento permite orientar o trabalho de um especialista de forma efetivamente direcionada a resultados. Em engenharia, é comum criarmos metas tecnicamente interessantes, mas desconectadas da principal dor do negócio.
Em nosso exemplo, o checkout é uma etapa diretamente ligada à conversão e à receita. Se o cliente chega até o pagamento e abandona a compra por causa de lentidão, erros ou instabilidade, o impacto não é apenas técnico. Ele também é financeiro, operacional e reputacional. Além disso, existem metas e contratos estabelecidos com clientes, como SLAs relacionados à disponibilidade e ao tempo de resposta das transações.
Precisamos traduzir essa relevância para uma perspectiva executiva:
Esse projeto de otimização do checkout é importante porque:
- Reduz o abandono do carrinho em uma etapa crítica do processo, contribuindo diretamente para as metas de conversão e de redução da taxa de abandono.
- Protege a receita durante os horários de pico, apoiando as metas de crescimento da receita gerada pela API de checkout.
- Melhora a experiência de compra, contribuindo para o alcance das metas de NPS e de satisfação dos usuários.
- Prepara a plataforma para datas comemorativas, períodos nos quais os indicadores mensais e anuais de conversão são pressionados de forma mais agressiva.
- Reduz o risco operacional.
Essa relação precisa estar alinhada e comunicada em nível executivo para demonstrar que o trabalho está orientado a resultados.
Time-bound: definindo prazo e janela de validação
Por fim, a meta precisa estar associada a um prazo. Essa é uma etapa fundamental para evitar que o objetivo permaneça vago sob a perspectiva executiva. Todos os timeboxes precisam ser mapeados e acompanhados.
“Precisamos melhorar a experiência do checkout, atingindo os níveis acordados, até o início das campanhas de Black Friday. As campanhas começam no início de novembro. Portanto, temos três semanas para elaborar a proposta e implementar a solução.”
Timeboxes secundários também podem ser estabelecidos, inclusive para acompanhar o progresso, revisar as propostas ou interromper iniciativas que não estejam produzindo os resultados esperados. Por exemplo:
“O time criado em regime de war room terá checkpoints diários às 10h15 e às 18h15 para apresentar dados e avanços. Nessas reuniões de 15 minutos, serão reportados impedimentos, dúvidas e informações relevantes. O timebox de 15 minutos somente será estendido em situações de urgência.”
“Todas as sextas-feiras, às 15h, as evoluções e os resultados alcançados serão apresentados ao comitê executivo.”
“Caso não seja possível obter datapoints relevantes que demonstrem a efetividade das propostas de redução, o planejamento será reavaliado e novas soluções serão buscadas.”
Também precisamos definir a janela e os critérios de validação. Não basta dizer que a meta precisa ser alcançada “até novembro”. Precisamos estabelecer como e por quanto tempo os resultados serão observados antes que ela seja considerada atingida.
Uma boa janela de validação poderia ser:
“A meta será considerada atingida quando a etapa de pagamento permanecer com p95 abaixo de quatro segundos, taxa de erro inferior a 0,1% e taxa de abandono do checkout abaixo de 10% por sete dias consecutivos. A validação deverá considerar os horários de pico, entre 12h e 18h, em dias úteis, sem que sejam identificadas degradações nos cenários de datas comemorativas simulados por meio de testes de carga.”
Meta SMART consolidada
Depois de aplicar as cinco dimensões do SMART, podemos consolidar a meta em uma frase objetiva:
“Reduzir a latência p95 da etapa de pagamento do checkout de 40 segundos para, no máximo, quatro segundos em até três semanas, antes do início das campanhas de Black Friday, mantendo a taxa de erro abaixo de 0,1% e a taxa de abandono do checkout abaixo de 10% durante os horários de pico, entre 12h e 18h, em dias úteis e em cenários equivalentes aos de datas comemorativas.”
Quebrando a meta em tarefas orientadas por dados
Uma boa meta SMART deve gerar trabalho concreto. Se a meta não puder ser desdobrada em tarefas, provavelmente ainda estará abstrata demais. A partir da meta consolidada, podemos derivar algumas frentes de execução.
Instrumentação e diagnóstico
- Instrumentar cada etapa da jornada de pagamento.
- Segmentar as métricas de latência do checkout por p50, p95 e p99.
- Medir a taxa de erro por dependência: serviço de antifraude, gateway de pagamento, banco de dados e orquestrador dos status de pagamento.
- Criar um dashboard específico para os horários de pico.
- Medir a taxa de abandono do checkout em cada etapa da jornada.
Antifraude e dependências externas
- Analisar a degradação do serviço de antifraude durante os horários de pico.
- Revisar os timeouts configurados para as chamadas externas.
- Reduzir os retries excessivos mantidos em memória.
- Implementar um circuit breaker para permitir a degradação controlada.
- Avaliar um fallback seguro para os cenários de lentidão do serviço de antifraude.
- Assumir a aprovação da análise de fraude para compras inferiores a R$ 200,00 durante os estados Open e Half-Open.
Banco de dados e queries críticas
- Identificar as queries que representam 80% do tempo total da transação.
- Analisar os planos de execução das queries críticas.
- Revisar os índices utilizados na etapa de pagamento.
- Reduzir a contenção e o consumo de CPU no banco de dados.
- Avaliar o uso de cache para dados estáveis utilizados durante o checkout.
- Avaliar a escalabilidade vertical das instâncias caso as demais otimizações não sejam suficientes.
Orquestrador dos status de pagamento
- Mapear o tempo gasto no serviço responsável por orquestrar os status de pagamento.
- Identificar as operações síncronas que podem ser desacopladas.
- Revisar locks, chamadas sequenciais e dependências bloqueantes.
- Reduzir as chamadas redundantes durante a confirmação do pagamento.
Validação e rollout
- Executar testes de carga simulando os horários de pico.
- Validar o comportamento do sistema sob uma carga de 2.000 requisições por segundo.
- Definir métricas de proteção para acionar o rollback.
- Realizar o rollout progressivo das otimizações.
- Monitorar o p95, a taxa de erro e a taxa de abandono durante a janela de validação.
TL;DR — De um desejo a uma meta SMART
Projeto de otimização do checkout
Desejo abstrato: “O checkout está lento.”
Problema observado: A etapa de pagamento do checkout apresenta p95 acima de 40 segundos durante os horários de pico, taxa de erro de 9% e aumento de 55% na taxa de abandono do checkout.
Diagnóstico técnico: A lentidão ocorre principalmente quando o volume ultrapassa 2.000 requisições por segundo. O p95 do tempo de resposta do serviço de antifraude sobe de 20 ms para dois segundos, existem até 20 retries mantidos em memória, o orquestrador dos status de pagamento apresenta saturação e o banco de dados chega a 98% de utilização de CPU, com queries que representam 80% do tempo total da transação.
Meta SMART: Reduzir a latência p95 da etapa de pagamento do checkout de 40 segundos para, no máximo, quatro segundos em até três semanas, antes do início das campanhas de Black Friday, mantendo a taxa de erro abaixo de 0,1% e a taxa de abandono do checkout abaixo de 10% durante os horários de pico, entre 12h e 18h, em dias úteis e em cenários equivalentes aos de datas comemorativas.
Tarefas:
- Instrumentar cada etapa da jornada de pagamento.
- Criar um dashboard com métricas de p50, p95, p99, taxa de erro e abandono.
- Revisar os timeouts e retries do serviço de antifraude.
- Implementar um circuit breaker e um fallback seguro.
- Otimizar as queries críticas do banco de dados.
- Reduzir a saturação do orquestrador dos status de pagamento.
- Executar testes de carga com 2.000 requisições por segundo.
- Realizar um rollout progressivo com métricas de proteção.
Critério de sucesso: A meta será considerada atingida quando os indicadores de latência, erro e abandono permanecerem dentro dos limites definidos por sete dias consecutivos, durante os horários de pico, sem comprometer a consistência, a segurança ou a estabilidade da jornada de pagamento.
Esse é o principal valor do SMART quando aplicado com maturidade: por meio das perguntas certas, ele nos ajuda a transformar uma frase vaga em um contrato claro de execução. O time deixa de perseguir uma percepção genérica de melhoria e passa a trabalhar sobre uma meta verificável, contextualizada e conectada ao impacto real do negócio.
Esse tipo de trabalho é altamente recorrente em posições de Staff+ Engineering. Adotar esse modelo mental abriu muitas portas para mim e me deu acesso a projetos críticos para minha trajetória profissional. Recomendo fortemente o estudo de sua aplicabilidade e sua adaptação ao dia a dia, independentemente de você já ocupar ou não uma posição Staff+.

