
System Design - Storage, RAID e Sistemas de Arquivos

O formato deste capítulo foi pensado para ser um “dump” de informações relacionadas a storage e armazenamento. Talvez a melhor forma de consumir esse material seja lê-lo duas vezes em sequência, pois muitas das informações presentes nos tópicos se cruzam em algum momento. Entender as capacidades de storage nos sistemas modernos tem se tornado uma preocupação de segundo, até terceiro plano nos projetos de software. Encontrar a solução ideal para o problema relacionado ao armazenamento normalmente é entregue de maneira transparente pelos provedores de nuvem ou plataformas onde provisionamos nossas soluções. Porém, entender os pormenores e detalhes de como, de fato, funciona um processo de armazenamento pode nos ajudar a economizar dinheiro, tempo e algumas noites de sono em cenários críticos e com crescimento expressivo de demanda.
Ele foi estruturado em 3 partes mais importantes: uma delas focando em métricas e dimensões que são pertinentes aos temas de armazenamento e storage em uso produtivo, tipos e modelos de storage e suas implementações arquiteturais e, por fim, os modelos de RAID que são amplamente utilizados e quais seus prós e contras em componentes de persistência.
Definindo Storage e Armazenamento
O termo Storage, ou armazenamento, refere-se à persistência de dados de forma organizada e escalável, de forma que possam ser recuperados e acessados de forma segura e performática. Dentro de um contexto técnico, o armazenamento pode ocorrer em diversos dispositivos físicos, como discos rígidos tradicionais, como os HDDs, unidades de estado sólido, conhecidas como SSDs, e sistemas de armazenamento de rede, como as soluções de NFS.
Dentro da arquitetura de sistemas, as preocupações com Storage vão além da capacidade de armazenar dados por longos períodos de tempo, pois também incluem trade-offs e decisões-chave estratégicas sobre desempenho, segurança, latência e escalabilidade. Dentro das inúmeras opções de storage às quais temos acesso em ambientes modernos, precisamos considerar opções que variam suas ponderações entre Persistência (capacidade de manter dados intactos, mesmo após falhas de hardware), Capacidade de expansão (facilidade de aumentar e diminuir partições de armazenamento sem interrupções de serviços e montagens), Redundância e recuperação (estratégias para evitar perda de dados e garantir a recuperação rápida dos dados em caso de falhas de software e hardware), Desempenho e IOPs (capacidade do storage em questão de atender a demandas específicas em termos de performance e latência das operações de escrita e leitura dos dados).
Quando olhamos sob a ótica de sistemas distribuídos, precisamos buscar abordagens onde os dados são armazenados em diversos pontos, são gerenciados de forma descentralizada e replicados entre diversos nodes em diferentes servidores, evitando ao máximo o forte acoplamento a um único host. Em sistemas modernos, as opções que precisam ser consideradas devem fazer uso intensivo de conceitos de sharding, replicação, resiliência e disponibilidade, sem perdas significativas de performance e segurança, com opções que vamos abordar ao decorrer do texto.
Dimensões em Storage
Antes de considerarmos os conceitos e estratégias importantes dentro das disciplinas de storage e armazenamento, precisamos entender alguns conceitos que servem de base para avaliar essas arquiteturas e dimensionar o seu funcionamento. Dentro de Storage, temos algumas métricas que podem nos ajudar a levantar requisitos e sugerir soluções performáticas na medida em que a solução necessita, sem investimentos desnecessários, superdimensionamento ou perdas de performance e disponibilidade. Veremos as principais métricas a seguir.
Throughput em Storage
O Throughput, como já vimos anteriormente, pode ser descrito como o “número de operações que um sistema consegue realizar dentro de um determinado período de tempo”, mas num contexto de volume de dados por tempo. Em storage, representa a quantidade total de dados que estão sendo transferidos para a unidade de armazenamento dentro de um período, geralmente sendo metrificado como megabytes por segundo (MB/s) ou gigabytes por segundo (GB/s).
Discos que possuam capacidade de throughput alta podem ser utilizados para sistemas com volumes massivos de dados e com grande quantidade de leitura e escrita, possibilitando que os mesmos consigam trabalhar ativamente grandes quantidades de solicitações sem enfileiramento ou latência adicional.
Bandwidth em Storage
O Bandwidth, ou largura de banda, representa, no geral, a quantidade máxima de dados que um canal de comunicação pode trafegar entre um ou mais componentes. Dentro de storage, ele representa o teto de throughput que podemos atingir entre as operações de leitura e escrita, sendo medido da mesma forma que o throughput atual, megabytes por segundo (MB/s) ou gigabytes por segundo (GB/s).
I/O e IOPS em Storage
O I/O, ou Input/Output, representa, de forma isolada, uma operação de escrita ou leitura que esteja sendo realizada entre um sistema e o volume de armazenamento ao qual o mesmo tenha acesso. Todas as vezes em que um sistema precisa persistir arquivos ou linhas de dados para serem tratados em disco, isso caracteriza uma operação de Input. Cada vez que esse sistema precisa recuperar dados no storage para processar ou exibir, o mesmo realiza uma operação de Output.
Para metrificar a capacidade e desempenho dessas operações, utilizamos a medida de IOPS, ou Input/Output Operations Per Second, a qual representa o número dessas solicitações de escrita e leitura que estão sendo executadas dentro de um segundo. Os volumes de armazenamento possuem essa descrição da quantidade máxima de IOPS que conseguem suportar, e recomenda-se metrificar e observar esse volume atual dessas operações para encontrarmos pontos de throttling, saturação ou se o sistema está próximo ou excedendo o volume de IOPS suportado, para realizarmos o dimensionamento adequado.
Tipos e Modelos de Storage
Dentro da arquitetura de software, o sistema de armazenamento de arquivos pode ser estruturado de diversas formas, dependendo das necessidades e requisitos que o produto em questão necessita. Esses requisitos podem levar em conta diferentes níveis de durabilidade, performance, escalabilidade e segurança. Independentemente do tipo escolhido para a solução, alguns conceitos de arquitetura precisam estar afiados para tomarmos a melhor decisão arquitetural sobre a persistência dos dados. O objetivo desta sessão é ilustrar alguns dos conceitos mais importantes que podem ser utilizados para estruturar e compreender a camada de persistência da solução.
DAS - Direct-Attached Storage
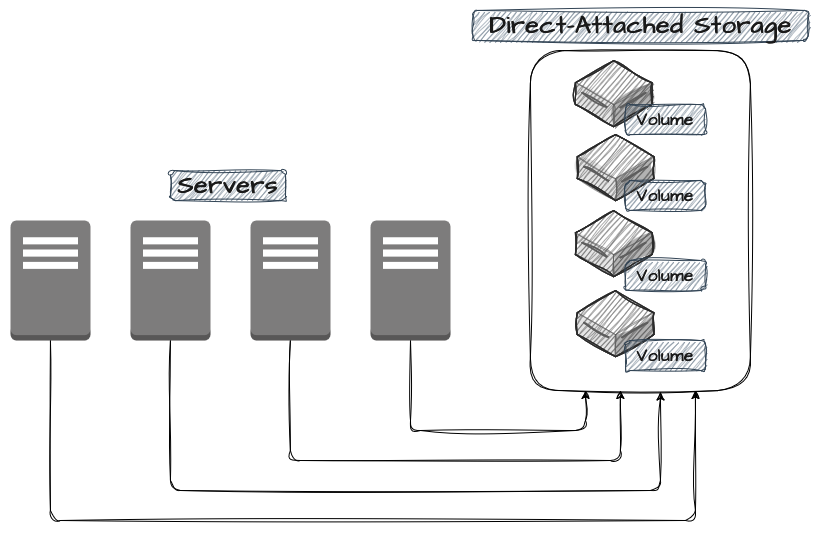
Os DAS, ou Direct-Attached Storages, são o modelo mais tradicional de armazenamento, pois são dispositivos e volumes montados diretamente em um servidor através de interfaces SATA, USB ou NVMe. Essa modalidade é uma das mais simples, sendo utilizada onde o desempenho e o acesso direto são critérios de muita importância na solução.
Nesse modelo, os discos são alocados diretamente no host que será utilizado, sem latência adicional vinda de intermediações de dispositivos de rede ou troca de protocolos complexos, sendo uma solução inteligente para aplicações e componentes que são sensíveis a acessos frequentes e intensos no filesystem.
Apesar das altas vantagens de latência e performance, a arquitetura DAS possui conhecidas dificuldades de escalabilidade horizontal, pois normalmente não possui suporte para montagem em múltiplos servidores e necessita de adições físicas de novos volumes para expandir a capacidade — muitas vezes exigindo a migração manual dos dados —, dificultando a operação e apresentando claras limitações de tamanho e custo.
NAS - Network Attached Storage
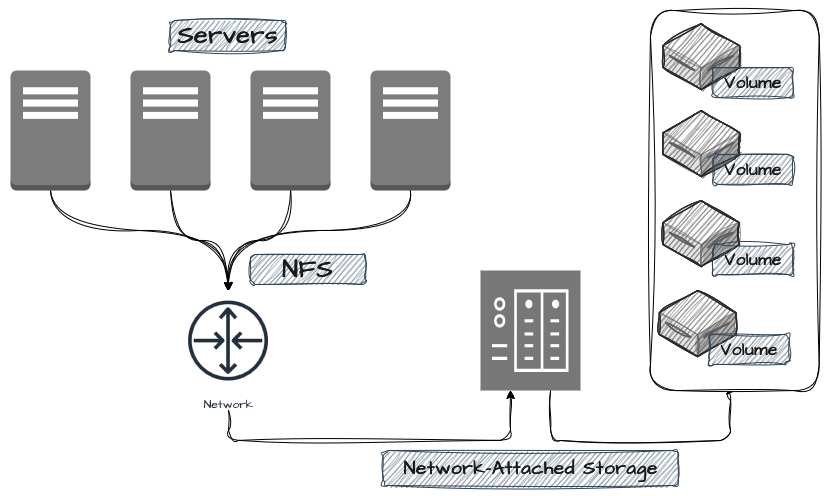
Ao contrário da arquitetura DAS, o NAS, ou Network Attached Storage, refere-se a dispositivos ou sistemas que dispõem de seus dados de forma diretamente conectada à rede local, permitindo, assim, que múltiplos clientes se conectem ao mesmo volume e acessem e modifiquem os mesmos dados de forma simultânea, com o uso de protocolos de rede como o NFS (Network File System) e SMB (Server Message Block). Um NAS pode ser implementado desde redes domésticas e sistemas de compartilhamento de diretórios corporativos até volumes de aplicações produtivas. Em resumo, o NAS é conhecido pela facilidade de implementação, gerenciamento centralizado e facilidade de acesso aos dados, e sendo uma forma de expor File Storages via rede.
Também ao contrário dos DAS, o desempenho e a performance das implementações de NAS são limitados à latência de rede e ao bandwidth disponível, ainda mais se houver demandas previstas de leitura e escrita de forma intensiva. Os NAS normalmente são construídos fazendo uso de arquiteturas de file storage hierárquicas.
Block Storage
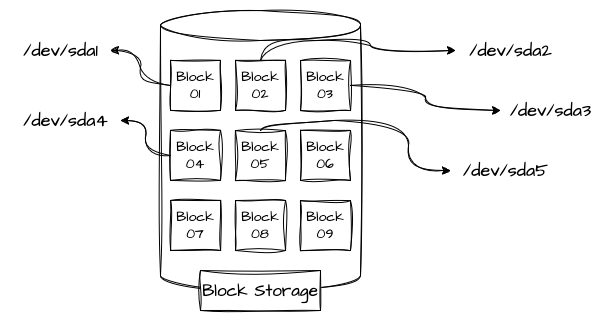
Os Block Storages são sistemas de armazenamento que nos permitem persistir informações dispersas em forma de blocos por todo o volume. Os Block Storages, ou Storage de Blocos, são o que podemos considerar como mais próximo de um modelo tradicional, representando o próprio disco rígido sob gestão de um formato como FAT-32, ExFAT, ext4 etc., onde é possível acessá-los diretamente pelo sistema operacional e montá-los como um drive. Discos rígidos (HDD) ou Solid-State Drives (SSD) diretamente ligados aos servidores também são considerados Block Storages. O servidor responsável por gerenciar os blocos pode formatá-los e utilizá-los como sistemas de arquivos.
Cada um dos blocos dos discos é endereçado de forma única e organizado de forma individual dentro do sistema de arquivos escolhido, como se fosse o próprio disco rígido isolado, porém podendo ser tratado de forma virtual. Isso permite também que o sistema de arquivos aloque dados menores onde for mais conveniente, aproveitando o espaço de forma mais eficiente e performática. Isso abre possibilidade para que um volume muito maior possa ser particionado em dois ou mais sistemas de arquivos virtualmente isolados entre si, porém fisicamente alocados no mesmo dispositivo. Os dados são divididos em blocos de tamanhos fixos, que podem variar entre alguns kilobytes, megabytes ou gigabytes — tamanho determinado na configuração do particionamento, o que pode limitar a escalabilidade horizontal.
File Storage
Os File Storages, também conhecidos como file-level ou file-based storage, são sistemas com estruturas hierárquicas de diretórios e seus respectivos arquivos associados. Os arquivos são associados a pastas, que podem conter uma série de outros arquivos, e essas pastas podem estar dentro de outras pastas, formando uma estrutura em “árvore”. A junção do nome do arquivo com a estrutura hierárquica da pasta forma o identificador único daquele arquivo, impedindo que, dentro do mesmo nível da hierarquia, existam dois ou mais arquivos com o mesmo nome.
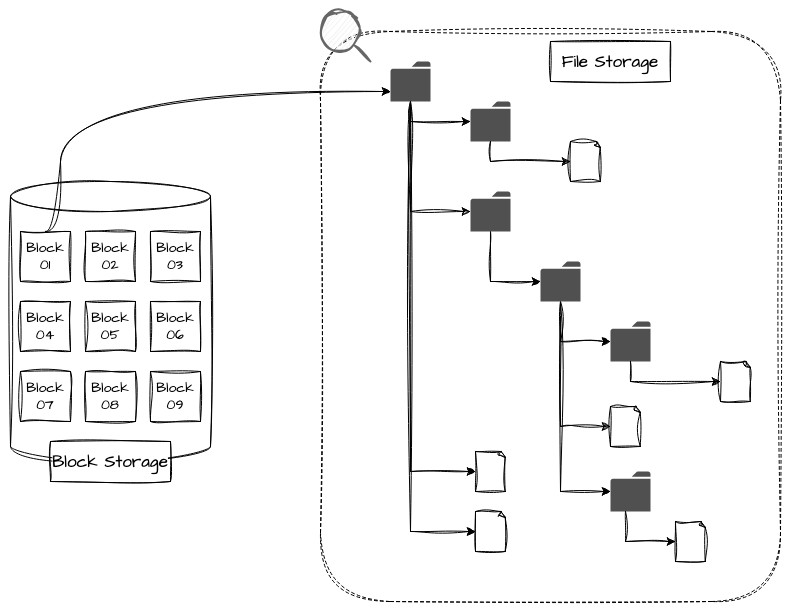
Cada arquivo e pasta dentro de um File Storage possui metadados importantes associados a ele, que permitem uma melhor gestão pelo usuário, possibilitando buscas, ordenações e gestão a partir de informações como nome, tamanho, data de criação, data de modificação, donos e grupos, vindos do próprio sistema operacional ou de sistemas de autenticação corporativos.
Eles, inicialmente, são concebidos para serem desacoplados e fornecer métodos de acesso compartilhado entre diversos clientes por meio de um protocolo específico de rede, como NFS (Network File System) ou SMB (Server Message Block). Esses sistemas são configurados por meio de aplicações de RAID e são anexados a sistemas NAS (Network-Attached Storage). De acordo com a especificação dos mesmos, podem possuir escalabilidade e elasticidade altas e seguras.
Object Storage
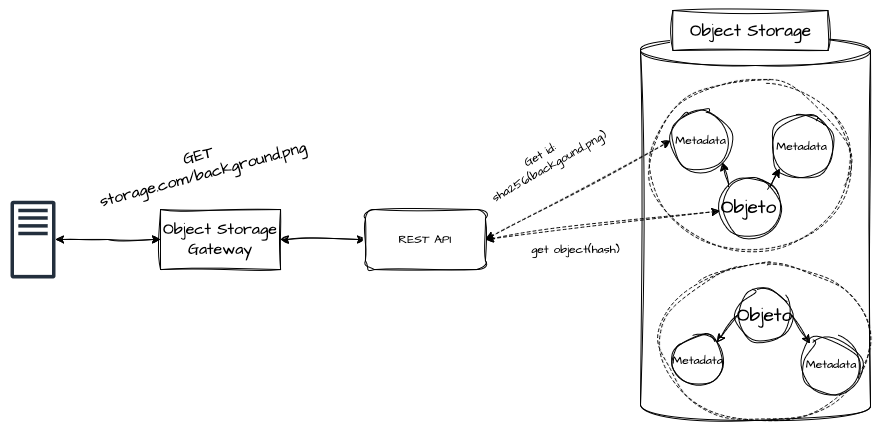
Quando levamos em conta a utilização de nuvens públicas, somos apresentados, com maior frequência, aos Object Storages. O Object Storage, ou Armazenamento de Objetos, é uma abordagem altamente escalável e, muitas vezes, implementada com APIs abertas e escaláveis, que nos permitem armazenar grandes quantidades de dados de forma totalmente desacoplada da aplicação.
Quando comparado a modelos tradicionais que vimos anteriormente — também conhecidos como “file storages” —, e que organizam seus dados em hierarquias de diretórios no sistema de arquivos, o Object Storage trata os dados de forma individual. Cada objeto possui seu conteúdo, mas também uma série de metadados que permitem que sejam organizados, recuperados e manipulados por meio de APIs e comandos claros, utilizando identificadores únicos de cada objeto.
Tarefas de alta demanda de gestão de arquivos, como replicação, particionamento, backups e gestão de ciclo de vida do dado, são realizadas de forma transparente, aumentando de forma exponencial aspectos de escalabilidade, durabilidade e disponibilidade. Exemplos práticos muito utilizados de armazenamento de objetos são o Amazon S3, Azure Blob Storage, Google Cloud Storage e soluções open-source como MinIO e Ceph.
Os Object Storages possuem limitações similares às dos NAS, com a exceção de que as operações de leitura e escrita, do ponto de vista da aplicação, não são realizadas de forma local, mas sim por intermediações entre cliente e servidor do storage, utilizando o mínimo possível de operações de I/O do disco de cada aplicação, tornando-o ideal para arquiteturas cloud native altamente sensíveis à escalabilidade horizontal e com alto desacoplamento.
RAID - Redundant Array of Independent Disks
O termo “RAID” vem de Redundant Array of Independent Disks e refere-se a um conjunto de estratégias para combinar múltiplos volumes de discos físicos em um único sistema lógico de armazenamento. Escrita, leitura e suas estratégias variam o foco em aumentar resiliência, tolerância a falhas, desempenho e integridade dos dados. Temos vários tipos de implementações de RAID; vamos tratar algumas delas a seguir.
RAID 0 (Striping)
O RAID 0 aplica uma arquitetura denominada como “striping”, onde os dados são distribuídos igualmente entre dois ou mais discos ou volumes. A principal característica do RAID 0 é a extrema otimização em termos de escrita e leitura, já que as mesmas ocorrem paralelamente entre todos os discos envolvidos, somando toda a taxa de transferência de todos os volumes. Em contrapartida, se um único disco do RAID falhar, todos os dados são perdidos, o que torna o mesmo inadequado para cenários onde temos dados críticos de longa duração.
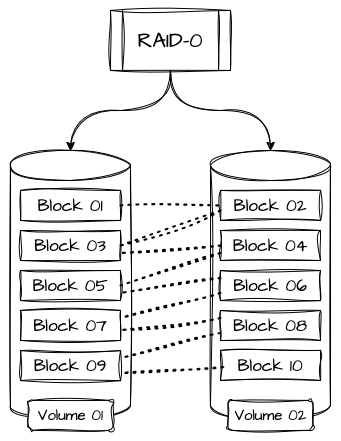
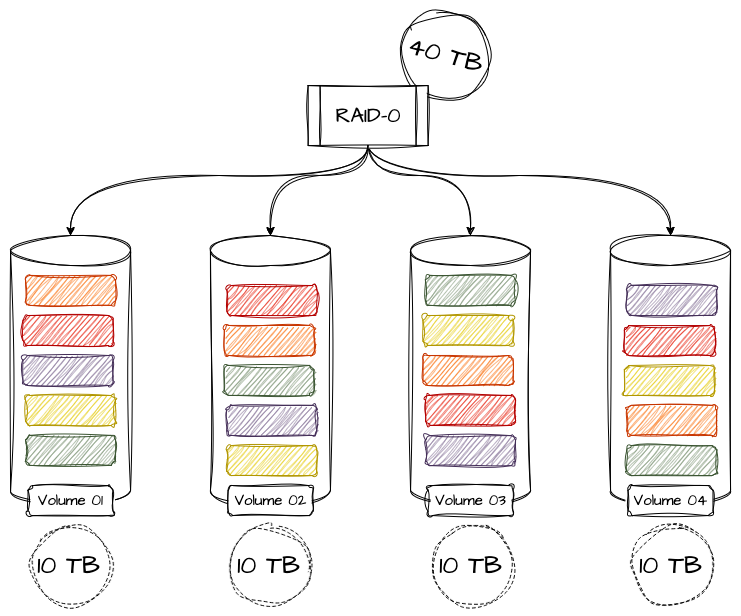
A extensão do RAID 0 é contínua e expansível para o número de volumes anexados a ele. Por exemplo, se temos 4 discos de 10 terabytes cada, significa que o volume total do nosso RAID será de 40 terabytes de armazenamento, que será distribuído igualmente entre todos os participantes do volume.
RAID 1 (Mirroring)
Enquanto o RAID 0 foca sua arquitetura na diminuição de latência e aumento de performance a custo de disponibilidade, o RAID 1 aplica o conceito de “Mirroring”, ou espelhamento, onde cada disco participante possui um espelho exato de todos os seus dados em outro disco. Essa replicação é realizada de forma contínua para fornecer proteção e disponibilidade em caso de falha de algum dos volumes. Caso um dos discos apresente problemas, o outro assume imediatamente, sem nenhum tipo de interrupção ou perda.
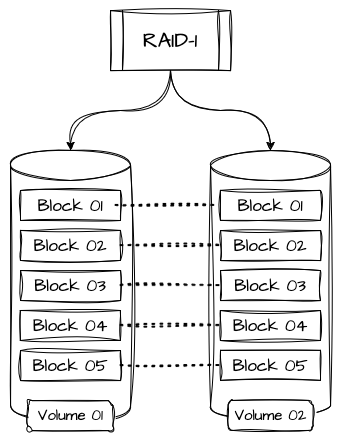
O RAID 1 tem trade-offs conhecidos de performance, mas, em contraponto, oferece maior confiabilidade, sendo ideal para volumes que comportem sistemas operacionais, bancos de dados ou outros tipos de aplicações críticas, já que o mesmo dado é replicado e armazenado mais de uma vez.
RAID 5 (Striping com Paridade Distribuída)
O RAID 5 oferece uma melhor solução contra os trade-offs do RAID 0 e RAID 1, entregando melhor desempenho de escrita e leitura sem sacrificar disponibilidade e segurança. Assim como o RAID 0, ele atua realizando suas escritas de forma distribuída entre os volumes, mas, em compensação, mantém metadados de paridade distribuídos entre todos os volumes para que, em caso de falha de um deles, a informação possa ser rapidamente reconstituída e restaurada.
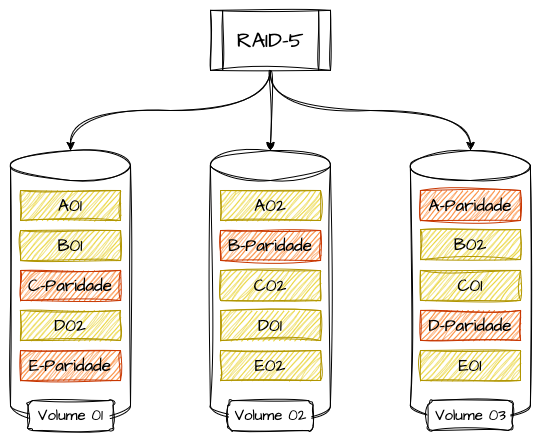
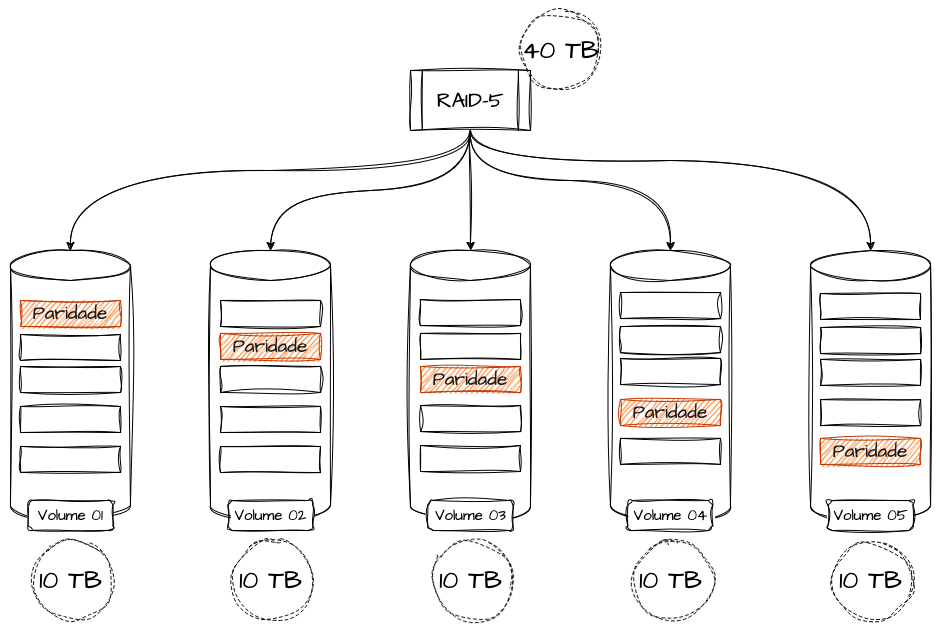
Importante ressaltar que a construção de storages em RAID 5 necessita de no mínimo 3 discos, e seu volume total se constitui na soma de todos os volumes, menos a capacidade de um disco, pois a proporcionalidade do mesmo é utilizada para armazenamento das referências de paridade, mesmo que a mesma seja distribuída entre todos os discos.
Por exemplo, se seu storage tiver 5 discos de 10 terabytes, a capacidade total será de 40 terabytes. Isso também significa que o mesmo só pode tolerar a perda de uma unidade de disco por vez. Em caso de perda de um disco, a paridade pode ser utilizada para reconstituir os dados; porém, a performance é reduzida até a reconstrução do dado e a reposição do disco.
RAID 6 (Striping com Dupla Paridade)
O RAID 6 trabalha com distribuição de paridade semelhante ao RAID 5, porém possui uma camada adicional de paridade distribuída. Essa paridade permite que, ao invés de um, dois discos possam falhar simultaneamente sem perda de dados. Os critérios de desempenho são razoavelmente reduzidos no RAID 6 devido a essa camada extra de disponibilidade, porém é extremamente recomendado para sistemas críticos e com grande volume de dados a longo prazo.
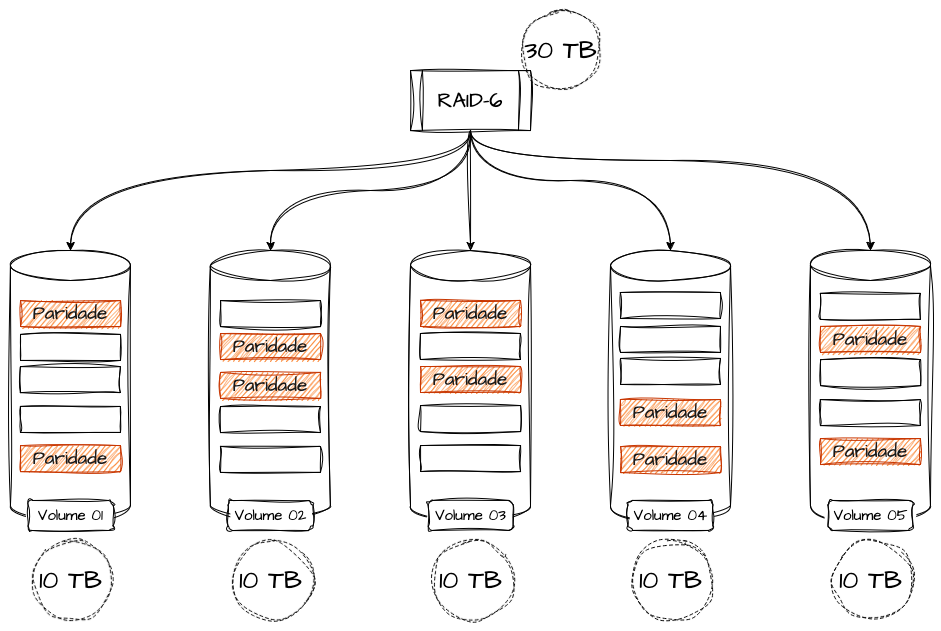
O cálculo total do storage funciona de forma parecida com o RAID 5 também, porém o RAID 6 precisa, ao invés de um, de dois volumes adicionais, e o seu volume total se constitui da soma de todos os volumes, menos a capacidade de dois discos.
Seguindo o mesmo exemplo, se o storage tiver 5 discos de 10 terabytes, a capacidade total será de 30 terabytes, podendo tolerar a falha de até 2 volumes sem perdas ou corrupção de dados.
RAID 10 (Combinação de RAID 1 com RAID 0)
O RAID 10, ou RAID 1+0, é uma combinação dos algoritmos de mirroring do RAID 1 e da arquitetura de striping do RAID 0. Primeiramente, os dados são distribuídos em blocos entre vários discos, como realizado pelo RAID 0, e, em seguida, os mesmos são replicados para o disco espelho, tal qual proposto pelo RAID 1.
Esse método acrescenta alta disponibilidade e resiliência contra falhas simultâneas de disco, desde que não sejam ambos da mesma faixa de espelhamento. A desvantagem principal é o alto custo, visto que a capacidade total é reduzida pela metade, pois 50% dos volumes são utilizados para redundância.
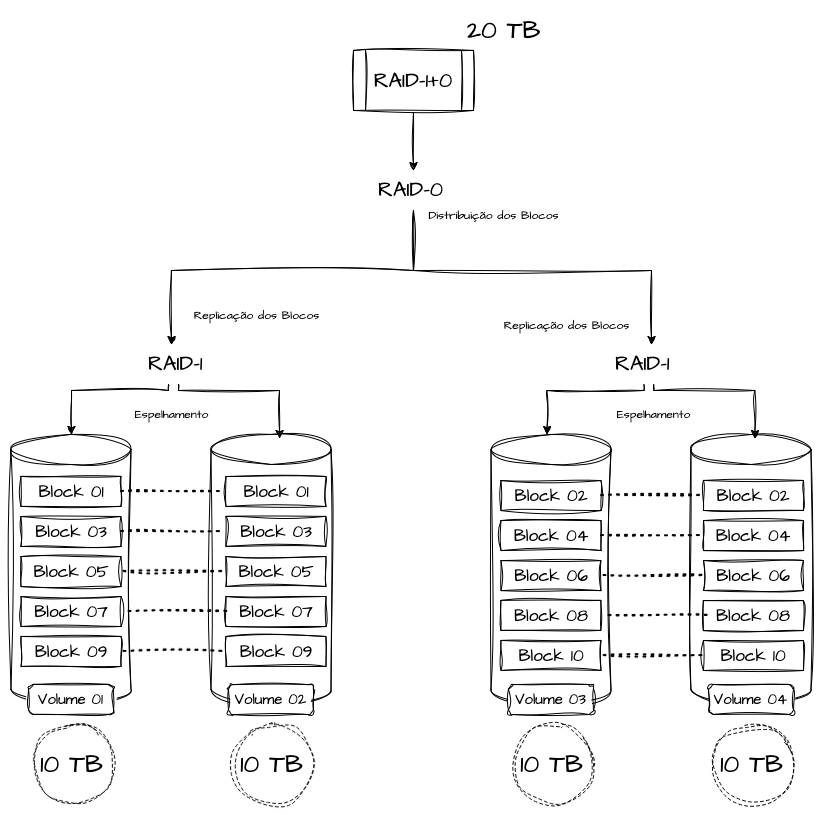
O RAID 10 é extremamente aconselhável para sistemas financeiros, hospitalares e cargas transacionais críticas.
Referências
What is RAID and what are the different RAID modes?
Classic SysAdmin: The Linux Filesystem Explained
Linux Filesystem Performance Tests
File System Comparison: NTFS, FAT32, exFAT, and EXT, Which File System Should I Use
O que é e para que serve o Storage DAS ou Direct Attached Storage
RAID 0, Discos rígidos agrupados e funcionando simultaneamente
What is RAID 0 (disk striping)?
RAID 5: entenda como funciona o arranjo de disco
O QUE É RAID? Conheça essa tecnologia e os principais TIPOS DE RAID (YouTube)
What Is Object Storage: Definition, How It Works, and Use Cases
Understanding key storage systems.. (Block, File and Object storage)
What’s the Difference Between Block, Object, and File Storage?
