
System Design - Cache

Neste capítulo, vamos abordar conceitos de cacheamento, ou caching, sob a ótica de System Design. À medida que exploramos as possibilidades de uso do caching, é fundamental compreender que, embora o conceito seja universal — armazenar dados temporariamente em algum lugar para reduzir o tempo de acesso à fonte original —, a aplicação prática dessa técnica pode variar bastante. Existem várias estratégias e tipos de cache. No início deste capítulo, você vai notar uma constante evolução: vamos começar com definições conceituais e generalistas que podem ser reaproveitadas na maioria dessas possibilidades, até começarmos a abordar essas estratégias de forma mais específica, com suas particularidades e vantagens.
Este é o sexto artigo sobre System Design, e este capítulo, em especial, foi muito divertido de ser produzido. Espero que seja de grande proveito para todos.
Definindo Cache
Cache, de forma simplificada, pode ser descrito como uma técnica de otimização que consiste em criar uma camada intermediária de dados entre dois componentes. Representa técnicas usadas para armazenar temporariamente dados que são custosos ou demorados de serem recuperados de sua origem, funcionando também como camadas temporárias de resiliência.
Normalmente, os dados armazenados em um cache são o resultado de uma operação anterior ou cópias de dados armazenados em outro lugar. Isso significa que o cache pode ser utilizado para evitar a sobrecarga de dependências e diminuir a consulta de dados que não mudam com grande frequência, aproximando esses dados do cliente ou armazenando os dados de um local mais custoso em outro mais acessível.
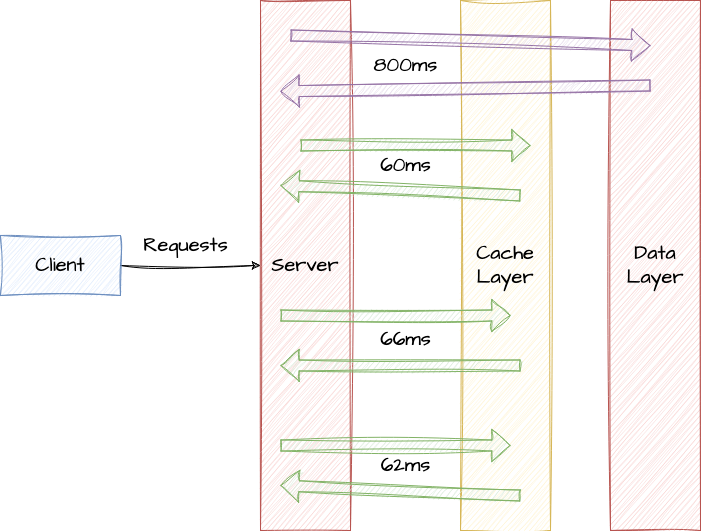
Exemplo de cacheamento em camadas de dados de uma interação entre cliente e servidor
Os dados armazenados no cache podem ser qualquer coisa, desde resultados de consultas de banco de dados, dados solicitados de outros sistemas dependentes até assets e páginas da web completas. O cache é especialmente útil quando os dados não mudam frequentemente, mas são acessados com frequência.
Existem várias formas de implementar estratégias de cache. Erroneamente, associa-se o conceito de cache diretamente a flavors específicos de memory databases, CDNs ou proxies reversos. No entanto, é importante ressaltar que, apesar de serem importantes, essas tecnologias apenas implementam e possibilitam capacidades de cache, não as definem.
Princípios Básicos de Cache
Quando analisamos diferentes estratégias e possibilidades de caching, percebemos que alguns conceitos e desafios são comuns entre elas, independentemente da finalidade para a qual as estratégias foram implementadas. O objetivo desta sessão é detalhar alguns desses conceitos e tópicos interessantes que podem nos ajudar a compreender e projetar soluções de caching de forma mais inteligente e eficiente.
Consistência de Dados
A atenção à consistência entre o cache e o armazenamento de dados principal é um aspecto muito crítico e pode representar um desafio significativo, especialmente se esses dados forem de grande importância em termos de atualização e consistência. Estratégias projetadas para esse cenário devem garantir que o cache reflita as mudanças mais recentes nos dados principais. Em sistemas altamente distribuídos, isso pode representar o maior desafio.
Por exemplo, em cenários hipotéticos onde existe a necessidade de cachear os dados cadastrais de um usuário em um sistema de compras, uma estratégia de cache pode ser benéfica, considerando a pergunta: “Quantas vezes os dados cadastrais de um usuário podem mudar?”, especialmente dentro de determinados períodos de tempo. Agora, imagine o cenário em que um usuário mudou seu endereço residencial ou, em uma situação mais complexa, esse usuário foi desativado, exigindo sistemicamente que nenhuma outra ação por parte dele possa ser executada em qualquer parte do sistema. Para evitar uma inconsistência dessas modificações importantes entre os dados reais e os dados em cache, prevenindo que produtos sejam enviados para o endereço errado ou permitindo que um usuário com atividade suspeita continue operando o sistema, as operações que realizam as escritas nos dados originais têm a obrigação de deletar as chaves de cache que correspondam aos dados em questão ou atualizá-las com o estado mais recente.
Time to Live (TTL)
O Time to Live, ou mais conhecido simplesmente como TTL, é uma configuração ou capacidade que define um período de vida para um item no cache. Após esse período, o item é automaticamente removido ou marcado como inválido, dependendo da implementação. Ambas as abordagens servem para indicar que o item deve ser renovado. O TTL é quase mandatório em sistemas de larga escala, pois previne que dados desatualizados prejudiquem a consistência. Além disso, garante uma reciclagem periódica de informações e ajuda a evitar o consumo desnecessário de recursos, eliminando itens que não são mais necessários ou que não têm sido acessados.
Políticas de Evicção e Substituição
A Evicção ou Política de Substituição refere-se às políticas e mecanismos que um sistema de cache usa para decidir quais itens remover quando a capacidade de alocação de cache atinge seu máximo. Imagine um mecanismo de cache que possua capacidade para alocar 1000 itens e que esteja totalmente utilizado. Esse mecanismo recebe a solicitação de salvar um item novo, porém não há espaço disponível. De acordo com a política estabelecida, a operação irá excluir o item mais antigo, menos acessado e removê-lo para dar espaço a esse novo item. As estratégias de evicção são utilizadas para garantir que os itens mais relevantes e frequentemente acessados sejam mantidos, deletando primeiro os itens que raramente são requisitados. As políticas de evicção incluem:
-
Least Recently Used (
LRU): Neste método, o item que não foi usado há mais tempo é removido primeiro. Baseia-se na suposição de que, se um item não foi usado recentemente, é menos provável que seja usado no futuro próximo. -
Least Frequently Used (
LFU): Faz a evicção pelos itens que são menos frequentemente acessados. Este método remove os itens que foram usados com menos frequência. Pode ser mais eficiente que o LRU em alguns casos, mas é mais difícil de implementar, porque requer o rastreamento da frequência de uso de cada item. -
First In, First Out (
FIFO): Elimina os itens na ordem em que foram adicionados. Este é um método simples, onde o primeiro item a entrar no cache é o primeiro a sair. Embora fácil de implementar, pode não ser o mais eficaz, pois não considera a frequência de uso dos itens. -
Random Replacement (
RR): Neste método, um item aleatório é selecionado para ser removido. Embora seja simples de implementar, não leva em conta a frequência de uso dos itens.
Invalidação de Itens em Cache
A Invalidação de Cache é o processo ou capacidade de remover ou marcar dados no cache como inválidos. Esta operação pode ser realizada de várias maneiras, incluindo, de forma pragmática, pela lógica de execução de um algoritmo, onde itens específicos são excluídos individualmente por não terem mais utilidade para o processo; de forma manual, através de comandos ou operações que permitem invalidar itens individualmente ou em grupo; ou automaticamente, através do TTL, onde a invalidação do item ocorre após um período específico.
Eventos de Hit Rate, Cache Hit e Cache Miss
Em sistemas que fazem uso de estratégias de cache para otimizar o acesso a dados, dois eventos são fundamentais e devem ser monitorados: cache hit e cache miss. Esses eventos contribuem para a avaliação da eficiência de um sistema de cache, fornecendo dados importantes para análise de desempenho, performance e efetividade.
Cache Hit
Um evento de cache hit ocorre quando uma solicitação de dados encontra o conteúdo desejado já armazenado no cache. Isso permite que o sistema entregue o dado solicitado diretamente do cache, sem a necessidade de acessar a fonte de dados original, como um banco de dados ou um sistema de arquivos, o que seria significativamente mais lento. Uma alta taxa de cache hits é geralmente indicativa de um sistema de cache bem otimizado, que efetivamente reduz o número de acessos a fontes de dados mais lentas.
Cache Miss
Um evento de cache miss acontece quando a solicitação de dados não encontra o conteúdo desejado no cache. Isso obriga o sistema a buscar o dado na fonte de dados original, processo que geralmente resulta em maior latência devido ao tempo mais demorado e ao custo mais alto de recuperação em comparação ao acesso via cache. Gerenciar e minimizar cache misses é importante para o design e a otimização de sistemas de cache, e envolve estratégias como a previsão de padrões de acesso aos dados e a otimização das políticas de evicção do cache.
Em situações em que limpezas totais ou parciais do cache podem levar a um pico de cache misses por algum tempo, até que os itens no cache sejam reconstruídos, sistemas com um volume alto e constante de cache misses em relação aos cache hits podem indicar uma ineficiência no uso do cache e representam uma oportunidade de otimização.
Hit Rate - Taxa de Acertos
A eficácia de um sistema de cache é diretamente influenciada pela relação entre cache hits e cache misses. A taxa de acerto, ou hit rate, é calculada pelo número de cache hits dividido pelo número total de solicitações (hits + misses), geralmente expressa em porcentagem. Uma taxa de acerto mais alta indica uma maior eficiência do cache, enquanto uma taxa de acerto baixa sugere que há espaço para otimização ou até mesmo pode justificar a remoção dessa camada de cache.
\begin{equation} \text{Total de Solicitações} = {\text{Cache Hits}} + {\text{Cache Miss}} \end{equation}
\begin{equation} \text{Taxa de Acertos (Hit Rate)} = \left( \frac{\text{Cache Hits}}{\text{Total de Solicitações}} \right) \times 100 \end{equation}
Vamos supor que em um sistema, temos dentro de um período de tempo, 800 cache hits e 200 cache misses. A taxa de acertos seria calculada da seguinte forma:
\begin{equation} \text{Total de Solicitações} = {\text{800}} + {\text{200}} \end{equation}
\begin{equation} \text{Taxa de Acertos (Hit Rate)} = \left( \frac{\text{800}}{\text{1000}} \right) \times 100 \end{equation}
\begin{equation} \text{Taxa de Acertos (Hit Rate)} = \text{80%} \end{equation}
Implementações de Cache
Como já foi mencionado anteriormente, o cache é uma estratégia que visa cumprir uma finalidade específica e não se baseia em uma tecnologia específica. Também observamos que existem diversos tipos de implementação de caching possíveis. O objetivo desta sessão é detalhar alguns dos principais usos e aplicações de caching em vários cenários.
Cache em Memória (Hashmap)
O Cache em Memória é uma estratégia útil para otimizar o desempenho de aplicações em uma escala mais simplificada. Mesmo em condições isoladas a uma única execução ou processo, é eficaz em reduzir o tempo de acesso a dados e diminuir a carga sobre recursos mais lentos. Entre as várias implementações de cache, o uso de estruturas de dados baseadas em hashmap é minha alternativa favorita devido à sua simplicidade, alta performance no tempo de acesso e facilidade em executar operações básicas.
Esta estratégia é comum em estruturas de dados e consiste em criar um mapa de itens baseados em chave-valor dentro de uma estrutura em memória disponível localmente para a aplicação. Com essa estrutura chave-valor, onde cada item salvo em um HashMap pode ser referenciado por uma chave única atrelada a ele para recuperar seu valor, temos uma capacidade local interessante de cache dentro de uma execução ou processo.
Abaixo, temos uma implementação simples do uso de hashmap para criar uma capacidade de cache. É importante lembrar que implementações que vão trabalhar com quantidades significativas de itens por um longo período de tempo devem implementar estratégias de invalidação desses itens para evitar problemas de leaks e saturação de memória disponível.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
package main
// ...
// Define a estrutura para o nosso cache em memória com hashmap
type MemoryCache struct {
items map[string]interface{}
mutex sync.RWMutex // mutex simples para garantir a sincronização durante a leitura/escrita
}
// cacheInstance é uma instância do cache, será usado para implementar o padrão singleton
// Garantindo que a criação do cache seja realizada apenas uma vez, independente de quantas
// Vezes for recuperada pela aplicação
var cacheInstance *MemoryCache
var once sync.Once
// GetCacheInstance retorna a instância única do cache
func GetCacheInstance() *MemoryCache {
once.Do(func() {
cacheInstance = &MemoryCache{
items: make(map[string]interface{}),
}
})
return cacheInstance
}
// Adiciona ou atualiza um valor no cache com a chave fornecida
func (c *MemoryCache) Set(key string, value interface{}) {
c.mutex.Lock()
defer c.mutex.Unlock()
c.items[key] = value
}
// Get retorna um valor do cache se ele existir
func (c *MemoryCache) Get(key string) (interface{}, bool) {
c.mutex.RLock()
defer c.mutex.RUnlock()
value, found := c.items[key]
return value, found
}
// Utilizando o padrão de cache criado
func main() {
// Obtendo a instância do cache
cache := GetCacheInstance()
// Adicionando alguns usuários hipotéticos ao cache
cache.Set("user:1", "Matheus Fidelis")
cache.Set("user:2", "Tarsila Bianca")
// Teste 1: Recuperando valores do cache
if userName, found := cache.Get("user:1"); found {
fmt.Println("Found user:1 ->", userName)
} else {
fmt.Println("user:1 not found in cache")
}
// Teste 2: Recuperando valores do cache
if userName, found := cache.Get("user:2"); found {
fmt.Println("Found user:2 ->", userName)
} else {
fmt.Println("user:2 not found in cache")
}
// Teste 3: Procurando um item que não existe em cache
if userName, found := cache.Get("user:3"); found {
fmt.Println("Found user:3 ->", userName)
} else {
fmt.Println("user:3 não encontrado em cache")
}
}
Caching em Sistemas Distribuídos
Em sistemas distribuídos, o caching é um grande facilitador para a melhoria de performance, redução da latência e escalabilidade eficiente ao servir conteúdo dinâmico ou estático. Diferentemente do cache em memória, que tem escopo limitado a uma execução, thread ou processo, tecnologias de cache como Redis, Memcached, entre outras, permitem a distribuição e paralelização do cache. Isso otimiza o acesso a dados em ambientes altamente distribuídos e de alta demanda, permitindo que várias réplicas e sistemas diferentes acessem os mesmos itens cacheados simultaneamente.
Este tipo de aplicação é especialmente valioso em cargas de trabalho sensíveis à escalabilidade horizontal e que operam com paralelização externa. Assim, independentemente de qual réplica crie o cache, ele estará acessível imediatamente para as demais.
Muitas das tecnologias de caching distribuído nos permitem trabalhar com capacidades de cache de forma pragmática e são projetadas para adicionar mais nós ao cluster de cache para lidar com maiores cargas sem degradar o desempenho. Elas incluem mecanismos para garantir que os dados sejam replicados entre nós, mantendo a consistência dos dados em todo o sistema, e possuem implementações de alta disponibilidade que permitem a continuidade das operações sem interrupções significativas na presença de falhas em um ou mais nós e em condições de particionamento. Introduzindo tecnologias, esse é o caso do Redis, que possui opções de provisionamento em modo cluster.
Cache em Bancos de Dados e Camadas de Dados
Os bancos de dados são frequentemente o maior gargalo em aplicações de software devido ao custo computacional associado à execução de operações de escrita, leitura, concorrência e persistência de dados a longo prazo. Dado que a maioria das opções mais comuns de mercado não é sensível à escalabilidade horizontal, a camada de dados tende a ser uma das partes mais complexas de se lidar em termos de escala. O cache, quando aplicado para resolver problemas de escalabilidade de bancos de dados, ajuda a mitigar esse gargalo, armazenando resultados de consultas inteiras ou registros frequentemente acessados em outra camada, em memória, mais barata e rápida de ser consultada.
Existem algumas estratégias que podemos adotar para resolver esse problema. Vamos abordar algumas delas de forma simplificada a seguir.
Cache-Aside (Lazy Loading)
Uma estratégia de cache-aside é a mais comum quando olhamos para implementações de caching em bancos de dados. A lógica pode ser resumida na própria aplicação, criando o cache sob demanda, conforme os dados são consultados. Quando a execução de algum algoritmo precisa ler dados de um banco de dados, primeiro verifica-se no sistema de cache se os dados buscados estão disponíveis. Caso o dado esteja em cache e seja retornado (cache hit), a resposta é fornecida pela camada de cache e o processamento segue adiante. Caso o dado não esteja disponível (cache miss), o banco de dados principal é consultado, as informações são imediatamente colocadas em cache para futuras consultas, e a execução prossegue para os próximos passos. Invariavelmente, essa ação de criar o cache pela primeira vez tende a demorar um pouco mais.
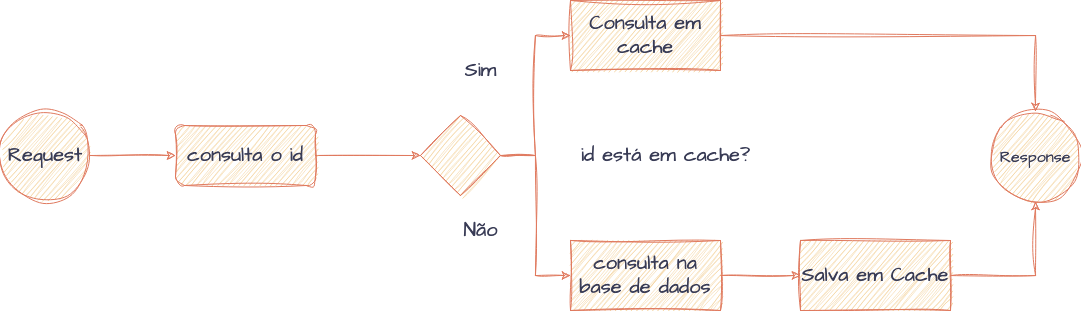
Lógica de consulta e construção de cache em bancos de dados utilizando estratégias de Cache-Aside
Embora essa estratégia de cache ofereça melhorias significativas de desempenho, ela também introduz complexidade na gestão de consistência de dados, como já mencionado anteriormente.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
package main
import (
"context"
"database/sql"
"fmt"
"log"
"github.com/go-redis/redis/v8"
)
var ctx = context.Background()
func main() {
// Conexão com o Redis.
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "",
DB: 0,
})
// Conexão com o Banco de Dados
mysqlDSN := "usuario:senha@tcp(localhost:3306)/pedidos"
db, err := sql.Open("mysql", mysqlDSN)
if err != nil {
log.Fatal(err)
}
defer db.Close()
// ID do pedido que desejamos buscar
pedidoID := "1"
// Busca no cache pela chave criada
valor, err := rdb.Get(ctx, "pedido:"+pedidoID).Result()
// Verifica se o pedido está ou não em cache
if err == rdb.Nil {
fmt.Println("Produto não encontrado no cache")
// Se não estiver em cache, busca no database
query := `SELECT valor FROM pedidos WHERE id = ?`
err := db.QueryRow(query, pedidoID).Scan(&valor)
if err != nil {
log.Fatal(err)
}
// Armazena o resultado no cache Redis para consultas futuras
err = rdb.Set(ctx, "pedido:"+pedidoID, valor, 0).Err()
if err != nil {
log.Fatal(err)
}
// Exibe o valor
fmt.Println("Pedido recuperado do banco de dados e armazenado no cache:", valor)
} else {
fmt.Println("Pedido recuperado do cache:", valor)
}
}
Write-Through (Escrita Dupla)
As abordagens de write-through, ou escrita dupla, tendem a ser aplicadas onde o cache é pensado de forma mais durável e a leitura deve manter um certo padrão de tempo de resposta. Basicamente, essa estratégia consiste em atualizar a versão mais recente do dado simultaneamente entre a base de dados principal e a camada de cache, assim que ele é inserido ou modificado.

O principal objetivo do Write-Through é garantir que os dados no cache estejam sempre atualizados e sincronizados com os dados persistentes, minimizando o risco de inconsistências. Sistemas que implementam essa estratégia devem ter mecanismos robustos de recuperação de falhas para lidar com situações em que a escrita na fonte de dados falha após os dados terem sido escritos no cache. Para fins de consistência, é comum que as abordagens de cache-aside e write-through sejam implementadas de forma complementar.
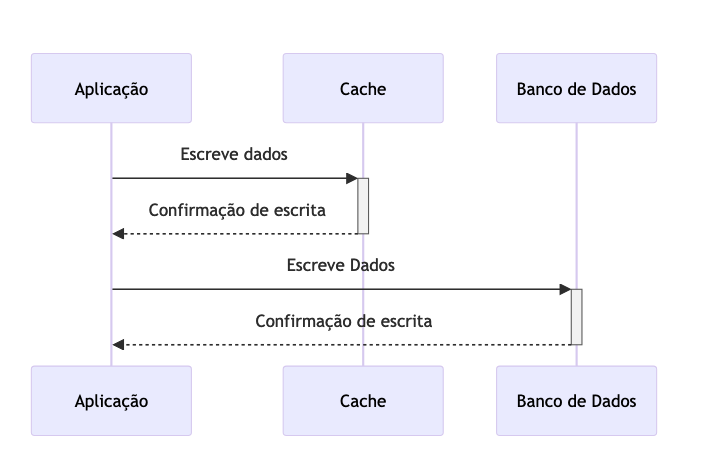
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
package main
import (
"context"
"database/sql"
"fmt"
"log"
_ "github.com/go-sql-driver/mysql"
"github.com/go-redis/redis/v8"
)
func main() {
var ctx = context.Background()
// Simulação da conexão com o Redis
// Substitua estas variáveis pelos seus valores reais para uma conexão funcional
redisClient := redis.NewClient(&redis.Options{
Addr: "localhost:6379", // Endereço do servidor Redis
Password: "", // Senha, se houver
DB: 0, // Banco de dados padrão do Redis
})
// Simulação da conexão com o MySQL
// Substitua estas variáveis pelos seus valores reais para uma conexão funcional
mysqlDSN := "usuario:senha@tcp(localhost:3306)/pedidos"
db, err := sql.Open("mysql", mysqlDSN)
if err != nil {
log.Fatal(err)
}
defer db.Close()
// Tentativa de ping no banco de dados para garantir a conexão
err = db.Ping()
if err != nil {
log.Fatal("Falha ao conectar no banco de dados: ", err)
}
// Aqui começa a lógica de write-through
pedidoID := "1"
value := "20.00"
// Primeiro, insere ou atualiza o valor no banco de dados
query := "INSERT INTO pedidos (id, valor) VALUES (?, ?) ON DUPLICATE KEY UPDATE valor = VALUES(valor)"
_, err = db.Exec(query, "pedido:"+pedidoID, value)
if err != nil {
log.Fatal("Erro ao inserir/atualizar no banco de dados: ", err)
}
// Imediatamente após, atualiza o valor no cache Redis
err = redisClient.Set(ctx, "pedido:"+pedidoID, value, 0).Err()
if err != nil {
log.Fatal("Erro ao atualizar o cache: ", err)
}
fmt.Println("Dado inserido no banco de dados e atualizado no cache com sucesso.")
}
Write-Behind (Lazy Writing)
A estratégia de Write-Behind, também conhecida como Lazy Writing, é uma estratégia de gerenciamento de cache que busca otimizar o desempenho de escrita em aplicações, minimizando a latência e reduzindo a carga sobre a fonte de dados persistente. Diferentemente do Write-Through, onde as operações de escrita são imediatamente refletidas tanto no cache quanto na fonte de dados, o Write-Behind adia a sincronização com a fonte de dados, aproveitando períodos de baixa atividade ou políticas específicas para atualizar os dados persistentes.
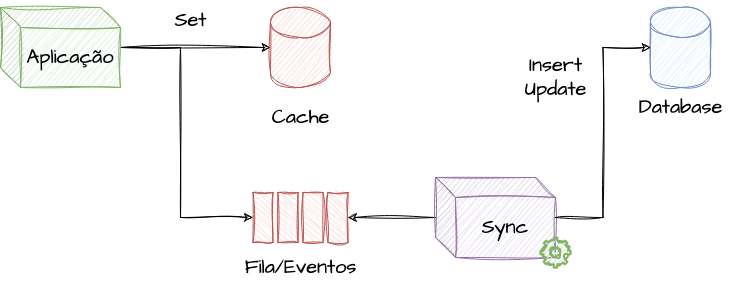
No Write-Behind, as operações de escrita são primeiramente aplicadas ao cache, permitindo que a aplicação continue sua execução sem a necessidade de esperar pela confirmação da fonte de dados persistente. Essas escritas são, de forma assíncrona, propagadas para a fonte de dados em um momento posterior, baseando-se em critérios predefinidos, como intervalos de tempo, quantidade de operações acumuladas, detecção de um período de baixa demanda ou através de componentes intermediários, como filas e event brokers. Essa estratégia necessita de alguma outra aplicação ou processo em paralelo para realizar a escrita.
Cache de Conteúdo Distribuído (CDN Cache)
O Cache de Conteúdo Distribuído, também conhecido como CDN (Content Delivery Network), é uma infraestrutura de rede estrategicamente distribuída com o objetivo de otimizar a entrega de conteúdo. A CDN funciona armazenando cópias de conteúdo estático, como imagens, vídeos, arquivos CSS e JavaScript, em vários servidores localizados em diferentes regiões geográficas.
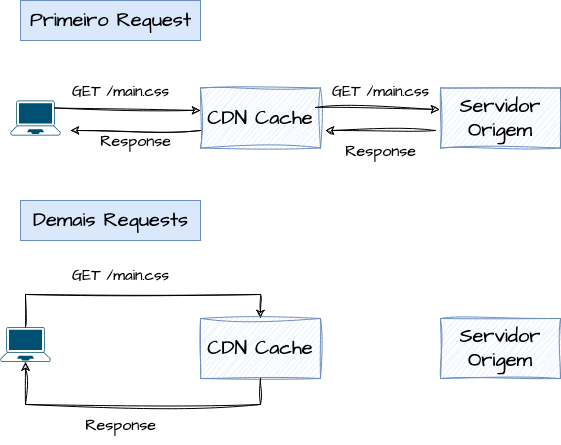
O processo inicia quando um usuário solicita um arquivo hospedado em uma CDN. Em vez de enviar essa solicitação diretamente ao servidor de origem, a CDN redireciona a solicitação para o servidor mais próximo do usuário com o conteúdo em cache, baseando-se em fatores como proximidade geográfica, checagens de saúde e latência da rede.
O funcionamento de grande parte das opções de mercado baseia-se na mesma lógica de cacheamento apresentada até agora, buscando os arquivos estáticos no servidor de origem quando não estão em cache e enviando os arquivos cacheados para economizar requisições que seriam direcionadas ao servidor de origem. Uma exceção é que algumas opções podem implementar a replicação dos arquivos em cache em diferentes pontos geográficos de forma assíncrona.
O objetivo dessa abordagem é reduzir a distância que os dados frequentemente acessados percorrem, diminuindo a latência, a carga no servidor de origem e melhorando a experiência do usuário final. Essa estratégia é particularmente eficaz em aplicações web com muitos recursos estáticos, onde armazenar conteúdo que tem uma periodicidade de mudança relativamente baixa, mas com uma quantidade de solicitações muito alta próxima aos usuários reduz o tempo de resposta das requisições até a origem, resultando em carregamentos de páginas mais rápidos.
Uma função agregada das CDNs é a capacidade de lidar com picos súbitos de tráfego, evitando que o servidor de origem fique sobrecarregado e potencialmente indisponível. Muitos dos produtos desenvolvidos para essa finalidade incluem proteções contra ataques de negação de serviço (DDoS), firewalls, filtros de pacotes e detecção de ameaças como parte da solução.
Para aplicações que possuem um ciclo de desenvolvimento constante e que façam uso de cache distribuído para ganho de performance, é quase indispensável implementar estratégias eficazes de invalidação de cache em suas pipelines e no seu ciclo de entrega de software, para garantir que os usuários finais recebam a versão mais atualizada do conteúdo assim que ela estiver disponível.
Conceitualmente e de forma resumida, o cache baseado em conteúdo baseia-se na estratégia de oferecer uma camada intermediária sistemática entre o cliente e o servidor de origem, como já explicamos. No algoritmo abaixo, criamos um servidor HTTP que faz a intermediação entre o cliente e o site google.com.br. Quando recebemos uma requisição para um recurso, criamos um hash identificador e verificamos se esse arquivo existe em disco. Caso exista, a requisição para a origem não é realizada, retornando o conteúdo diretamente do cache local. Caso contrário, o recurso é solicitado à origem, em seguida identificado e armazenado em cache.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
// ...
const origem = "https://google.com.br"
const cacheDir = "./cache"
const port = 8080
// Função que cria um hash do conteúdo solicitado pela URL
func generateHash(input string) string {
hash := sha1.New()
hash.Write([]byte(input))
return hex.EncodeToString(hash.Sum(nil))
}
func ProxyCacheHandler(w http.ResponseWriter, r *http.Request) {
var body []byte
// Tempo inicial da requisição
startTime := time.Now()
// Define o diretório do cache do recurso calculando a hash da URL
cachePath := filepath.Join(cacheDir, generateHash(r.URL.Path))
// Verifica se o recurso está em cache
_, err := os.Stat(cachePath)
// Caso não esteja, recupera o recurso do servidor
if os.IsNotExist(err) {
fmt.Println("Recurso não está presente em cache, buscando na origem:", r.URL.Path)
// Constroi a URL do recurso
url := fmt.Sprintf("%s%s", origem, r.URL.Path)
// Realiza a requisição para a origem para buscar o recurso
resp, err := http.Get(url)
if err != nil {
http.Error(w, "Server Error", http.StatusInternalServerError)
log.Println("Falha ao buscar o recurso na origem:", err)
return
}
defer resp.Body.Close()
// Lê o conteúdo da resposta
body, err = ioutil.ReadAll(resp.Body)
if err != nil {
http.Error(w, "Server Error", http.StatusInternalServerError)
log.Println("Falha ao ler a resposta do servidor:", err)
return
}
// Salva o arquivo em cache com o conteúdo do recurso
ioutil.WriteFile(cachePath, body, 0644)
} else {
// Caso esteja em cache, lê o arquivo e retorna no response
fmt.Println("Recurso está presente em cache:", r.URL.Path, cachePath)
// Lê o arquivo em cache
body, err = ioutil.ReadFile(cachePath)
if err != nil {
http.Error(w, "Server Error", http.StatusInternalServerError)
log.Println("Falha ao ler o cache:", err)
return
}
}
// Tempo total da requisição
fmt.Println(fmt.Sprintf("Tempo total da requisição para o recurso %v: %v", r.URL.Path, time.Since(startTime)))
// Resposta cacheada da requisição
w.Write(body)
}
func main() {
// Cria o diretório de armazenamento do cache
fmt.Println("Criando diretório de cache:", cacheDir)
if _, err := os.Stat(cacheDir); os.IsNotExist(err) {
os.Mkdir(cacheDir, os.ModePerm)
}
// Cria um server HTTP simples para fazer handling dos requests
fmt.Println("Iniciando Proxy para a origem:", origem)
http.HandleFunc("/", ProxyCacheHandler)
fmt.Println("Proxy iniciado na porta:", port)
log.Fatal(http.ListenAndServe(fmt.Sprintf(":%v", port), nil))
}
Primeiro Acesso
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Criando diretório de cache: ./cache
Iniciando Proxy para a origem: https://google.com.br
Proxy iniciado na porta: 8080
Recurso não está presente em cache, buscando na origem: /
Tempo total da requisição para o recurso /: 795.700625ms
Recurso não está presente em cache, buscando na origem: /client_204
Recurso não está presente em cache, buscando na origem: /images/branding/googlelogo/1x/googlelogo_white_background_color_272x92dp.png
Recurso não está presente em cache, buscando na origem: /textinputassistant/tia.png
Recurso não está presente em cache, buscando na origem: /images/nav_logo229.png
Recurso não está presente em cache, buscando na origem: /xjs/_/js/k=xjs.hp.en.v2grbV-lSNQ.O/am=AAAAAAAAAAAAAAAAAAAAAAAAAAACAAAAAAA4AAAAAiAAAAAABgAAAAAAAAACABxERwAwAEcAAHgB/d=1/ed=1/rs=ACT90oES1zvGValamnA-977V6dGcCu-eaQ/m=sb_he,d
Tempo total da requisição para o recurso /xjs/_/js/k=xjs.hp.en.v2grbV-lSNQ.O/am=AAAAAAAAAAAAAAAAAAAAAAAAAAACAAAAAAA4AAAAAiAAAAAABgAAAAAAAAACABxERwAwAEcAAHgB/d=1/ed=1/rs=ACT90oES1zvGValamnA-977V6dGcCu-eaQ/m=sb_he,d: 107.101708ms
Tempo total da requisição para o recurso /textinputassistant/tia.png: 132.588208ms
Tempo total da requisição para o recurso /images/branding/googlelogo/1x/googlelogo_white_background_color_272x92dp.png: 132.977041ms
Tempo total da requisição para o recurso /images/nav_logo229.png: 130.294708ms
Tempo total da requisição para o recurso /client_204: 211.213916ms
Recurso está presente em cache: /images/nav_logo229.png cache/d99d33e5ee22dee6f248b342095f1382cc3a9580
Tempo total da requisição para o recurso /images/nav_logo229.png: 411.792µs
Recurso não está presente em cache, buscando na origem: /gen_204
Tempo total da requisição para o recurso /gen_204: 179.880792ms
Segundo Acesso
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Recurso está presente em cache: / cache/42099b4af021e53fd8fd4e056c2568d7c2e3ffa8
Tempo total da requisição para o recurso /: 357.791µs
Recurso está presente em cache: /images/branding/googlelogo/1x/googlelogo_white_background_color_272x92dp.png cache/ffa840af19c091b0e9304cae9327510f5c5c6e0d
Tempo total da requisição para o recurso /images/branding/googlelogo/1x/googlelogo_white_background_color_272x92dp.png: 306.625µs
Recurso está presente em cache: /textinputassistant/tia.png cache/d61ec3ad1d7c3687061c89561ac34d4a40659823
Tempo total da requisição para o recurso /textinputassistant/tia.png: 1.7355ms
Recurso está presente em cache: /xjs/_/js/k=xjs.hp.en.v2grbV-lSNQ.O/am=AAAAAAAAAAAAAAAAAAAAAAAAAAACAAAAAAA4AAAAAiAAAAAABgAAAAAAAAACABxERwAwAEcAAHgB/d=1/ed=1/rs=ACT90oES1zvGValamnA-977V6dGcCu-eaQ/m=sb_he,d cache/0590c87359355c9a948ac0829a030a371e46d959
Tempo total da requisição para o recurso /xjs/_/js/k=xjs.hp.en.v2grbV-lSNQ.O/am=AAAAAAAAAAAAAAAAAAAAAAAAAAACAAAAAAA4AAAAAiAAAAAABgAAAAAAAAACABxERwAwAEcAAHgB/d=1/ed=1/rs=ACT90oES1zvGValamnA-977V6dGcCu-eaQ/m=sb_he,d: 676.375µs
Recurso está presente em cache: /images/nav_logo229.png cache/d99d33e5ee22dee6f248b342095f1382cc3a9580
Tempo total da requisição para o recurso /images/nav_logo229.png: 103.5µs
Recurso está presente em cache: /client_204 cache/9036ec3b37560314f1df05b153d3486ae6a8f808
Tempo total da requisição para o recurso /client_204: 87.375µs
Recurso está presente em cache: /images/nav_logo229.png cache/d99d33e5ee22dee6f248b342095f1382cc3a9580
Tempo total da requisição para o recurso /images/nav_logo229.png: 112.833µs
Recurso está presente em cache: /gen_204 cache/b55d8b2989794808c756b64e38355d9a0920bd30
Tempo total da requisição para o recurso /gen_204: 118.541µs
Revisores
Referencias
Introduction to database caching
Cache Eviction Strategies Every Redis Developer Should Know

