
System Design - CQRS (Command Query Responsability Segregation)

Esse capítulo tem o objetivo de adicionar mais algumas estratégias para lidar com dados em sistemas modernos à sua caixa de ferramentas, sendo esses sistemas distribuídos ou não. A necessidade de aumentar o repertório de padrões de projeto para lidar com dados de domínios em larga escala tem se tornado cada vez mais presente no dia a dia de engenheiros e arquitetos de software e representa um importante recorte de senioridade. A longo prazo e em escala, considero os dados como a parte mais crítica e difícil de lidar dentre todas as disciplinas de Engenharia de Software, e a seguir vamos abordar o padrão CQRS e algumas possibilidades de implementação que podem ser adaptadas, combinadas e estendidas conforme a experiência dos times e o conhecimento dos domínios de negócio ganham maturidade.
Definindo CQRS
O CQRS, ou Command Query Responsibility Segregation, é um padrão arquitetural cujo objetivo é separar as responsabilidades de escrita e leitura de um sistema. As operações de escrita no padrão CQRS são denominadas “comandos”, pois entende-se que a implementação de escrita do CQRS seja voltada para efetuar operações imperativas que mudam o estado de uma ou mais entidades do sistema. As operações de leitura são denominadas “queries”, cujo objetivo é apenas fornecer uma capacidade de leitura dos dados desse domínio de forma otimizada.
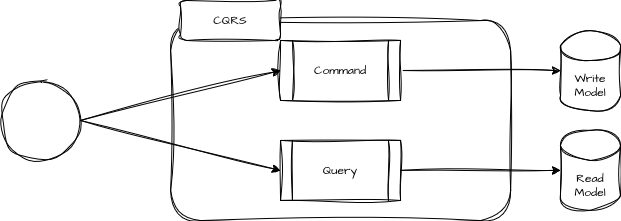
Modelo conceitual de CQRS
O objetivo central do CQRS é aumentar a performance e a escalabilidade de um serviço por meio de modelos de dados que sejam especificamente otimizados para suas respectivas tarefas, partindo do princípio de que, ao separar as operações de comandos e consultas, cada parte do sistema pode ser escalada independentemente, permitindo uma utilização mais eficiente dos recursos computacionais alocados para cada uma dessas tarefas.
Em resumo, o padrão CQRS envolve o uso de dois ou mais bancos de dados que têm seus dados replicados, mas cada um com uma estrutura específica para diferentes necessidades. Vamos explorar essas ideias e outras abordagens mais complexas e poderosas ao longo do capítulo.
Separação de Responsabilidades
O princípio central do CQRS é a separação de responsabilidades entre operações de leitura e operações de escrita, utilizando infraestruturas e modelos de dados diferentes.
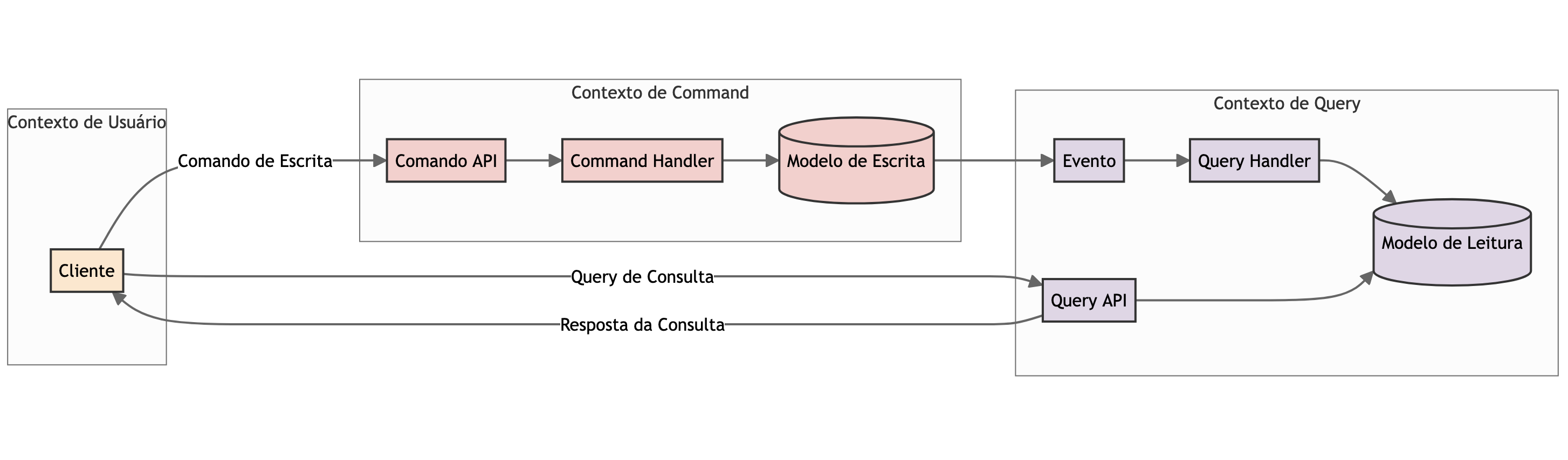
Diagrama conceitual de segregação de responsabilidades do CQRS
Os commands, ou comandos, encapsulam todas as informações necessárias para realizar operações de escrita, como criar, atualizar ou deletar um registro, além de aplicar todas as regras de validação necessárias para garantir a integridade dos dados. Conceitualmente, o comando tende a se referir ao ato de “processar algo”, alterando um estado mediante o estímulo de um comportamento, mas também pode ser aplicado para manipular entidades anêmicas, se necessário. O modelo de escrita deve se focar em garantir a consistência e a integridade dos dados. É comum usar bancos de dados relacionais que suportem transações e garantam ACID (Atomicidade, Consistência, Isolamento, Durabilidade) para assegurar a consistência e executar as transações de forma atômica. Os bancos de dados de escrita que precisam garantir forte consistência contam com processos de normalização para otimizar a integridade e a performance.
As queries são responsáveis por retornar dados sem alterar o estado do sistema. Os bancos de dados são otimizados para recuperação rápida e eficiente de informações, muitas vezes utilizando técnicas como caching, réplicas de leitura ou desnormalização de dados para melhorar o desempenho nesse tipo de cenário. Bancos de dados NoSQL são frequentemente usados nesse contexto, pois oferecem alta performance em consultas e podem escalar horizontalmente de forma eficaz, embora bancos SQL também possam ser usados de forma desnormalizada sem nenhum tipo de problema.
Em resumo, um exemplo mais simples de aplicação do CQRS seria fazer uso de um modelo normalizado dentro de um banco SQL de escrita para garantir toda a consistência e integridade e, a partir dos eventos de comando, uma segunda escrita seja realizada em outra base de dados com uma view materializada e desnormalizada, otimizada para ser recuperada, ou em um banco NoSQL com a estrutura do documento muito próxima do payload de response.
Perspectiva sobre Modelos de Domínio
O modelo de comando é responsável por manipular os dados do sistema e garantir a consistência e a integridade das operações. Este modelo é geralmente mais complexo, pois incorpora todas as regras de negócio, validações e lógicas que precisam ser aplicadas quando o estado do sistema é alterado. O modelo de comando frequentemente segue o padrão Rich Domain Model, no qual a lógica de negócio está embutida nas entidades do domínio e faz uso de transações ACID para garantir mudanças de estado consistentes durante o ciclo de vida dos dados de domínio. Vamos desenhar um cenário em que, em um sistema hospitalar de prontuários médicos hipotético, um médico precisa criar uma nova prescrição para um paciente. A ação de comando deverá verificar se o médico é válido, se o paciente é válido, se o medicamento existe, se o médico está autorizado a prescrever o medicamento de acordo com sua especialidade e, por fim, realizar a persistência no banco de dados. Toda essa lógica será encapsulada dentro do comando.
O modelo de consulta é otimizado para leitura e recuperação rápida de dados. Diferentemente do modelo de comando, ele não precisa incorporar lógica de negócio complexa ou validações, pois sua responsabilidade é exclusivamente fornecer dados para serem exibidos ou utilizados em outras partes do sistema depois que um comando já foi executado. Por exemplo, um modelo desnormalizado das prescrições pode ser criado para agrupar, de forma legível e rápida, as informações do médico, do paciente e dos medicamentos prescritos.
Modelos de Implementação
A aplicação do CQRS pode variar desde as implementações mais simplistas, que respeitam contextos limitados de um domínio ou funcionalidade, até as mais complexas, que agrupam informações de forma incremental a partir de várias fontes e etapas de um processo maior. Aqui veremos algumas alternativas e modelos de implementação que podem ser úteis para a compreensão da extensão das capacidades desse tipo de arquitetura na resolução de problemas de escala e resiliência.
CQRS em bancos SQL e Views Materializadas
Um dos exemplos mais simples de uma implementação de CQRS é transpor um modelo SQL normalizado para outro modelo SQL desnormalizado. A simplicidade dessa abordagem permite que essa nova tabela desnormalizada esteja presente ou não na mesma instância ou no mesmo schema que o restante das tabelas normalizadas dos domínios. A evolução para um banco de dados separado é um passo que pode ocorrer com facilidade, porém necessitaria de processos e infraestruturas adicionais, se necessário.
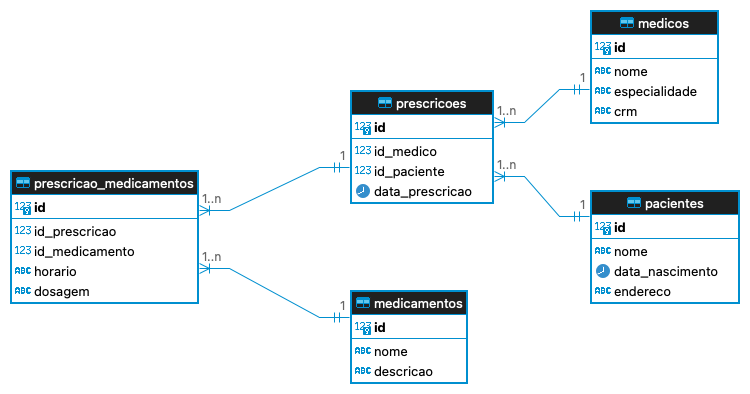
Vamos supor o modelo de uma funcionalidade de prescrição de medicamentos de um sistema hospitalar fictício, onde teremos as tabelas Médicos, Pacientes, Medicamentos, Prescrições e Prescrição_Medicamentos, que fará o vínculo de 1:N entre os medicamentos prescritos. Esse modelo fornece uma consistência forte de relacionamentos, não permitindo que medicamentos não cadastrados sejam prescritos, que pacientes não cadastrados sejam tratados e que médicos não cadastrados operem e prescrevam medicamentos.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
CREATE TABLE IF NOT EXISTS Medicos (
id SERIAL PRIMARY KEY,
nome VARCHAR(255) NOT NULL,
especialidade VARCHAR(255) NOT NULL,
crm VARCHAR(255) NOT NULL UNIQUE
);
CREATE TABLE IF NOT EXISTS Pacientes (
id SERIAL PRIMARY KEY,
nome VARCHAR(255) NOT NULL,
data_nascimento DATE NOT NULL,
endereco VARCHAR(255)
);
CREATE TABLE IF NOT EXISTS Medicamentos (
id SERIAL PRIMARY KEY,
nome VARCHAR(255) NOT NULL,
descricao TEXT
);
CREATE TABLE IF NOT EXISTS Prescricoes (
id SERIAL PRIMARY KEY,
id_medico INT NOT NULL,
id_paciente INT NOT NULL,
data_prescricao TIMESTAMP NOT NULL,
FOREIGN KEY (id_medico) REFERENCES Medicos(id),
FOREIGN KEY (id_paciente) REFERENCES Pacientes(id)
);
CREATE TABLE IF NOT EXISTS Prescricao_Medicamentos (
id SERIAL PRIMARY KEY,
id_prescricao INT NOT NULL,
id_medicamento INT NOT NULL,
horario VARCHAR(50) NOT NULL,
dosagem VARCHAR(50) NOT NULL,
FOREIGN KEY (id_prescricao) REFERENCES Prescricoes(id),
FOREIGN KEY (id_medicamento) REFERENCES Medicamentos(id)
);
Exemplo da modelagem de escrita normalizada para integridade dos relacionamentos
Esse modelo, por mais que seja superficial, garante a integridade dos dados durante sua manipulação. Porém, outra funcionalidade do sistema de prescrição médica é gerar relatórios e ordens de serviço para a farmácia hospitalar, a fim de preparar e controlar a saída do estoque de medicamentos. Essa funcionalidade é crítica, pois os medicamentos precisam de triagem, rastreio, contabilidade e facilidade visual para separação e destinação ao quarto ou enfermaria onde o paciente está. Para montar uma visão como essa em sistemas altamente normalizados, é necessária uma grande quantidade de joins entre as tabelas.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
SELECT
p.id AS id_prescricao,
p.data_prescricao,
m.nome AS nome_medico,
m.especialidade,
pac.nome AS nome_paciente,
pac.data_nascimento,
pac.endereco,
med.nome AS nome_medicamento,
pm.horario,
pm.dosagem
FROM
Prescricoes p
LEFT JOIN Medicos m ON p.id_medico = m.id
LEFT JOIN Pacientes pac ON p.id_paciente = pac.id
LEFT JOIN Prescricao_Medicamentos pm ON p.id = pm.id_prescricao
LEFT JOIN Medicamentos med ON pm.id_medicamento = med.id
WHERE
p.id = 1; -- ID da prescrição específica
Exemplo de Query para recuperar os dados dos medicamentos solicitados por prescrições médicas
Output
1
2
3
1 2023-05-20 14:30:00.000 Dr. João Silva Cardiologia Maria Oliveira 1985-07-10 Rua das Flores, 123 Aspirina 08:00 100mg
1 2023-05-20 14:30:00.000 Dr. João Silva Cardiologia Maria Oliveira 1985-07-10 Rua das Flores, 123 Paracetamol 20:00 500mg
1 2023-05-20 14:30:00.000 Dr. João Silva Cardiologia Maria Oliveira 1985-07-10 Rua das Flores, 123 Aspirina 08:00 100mg
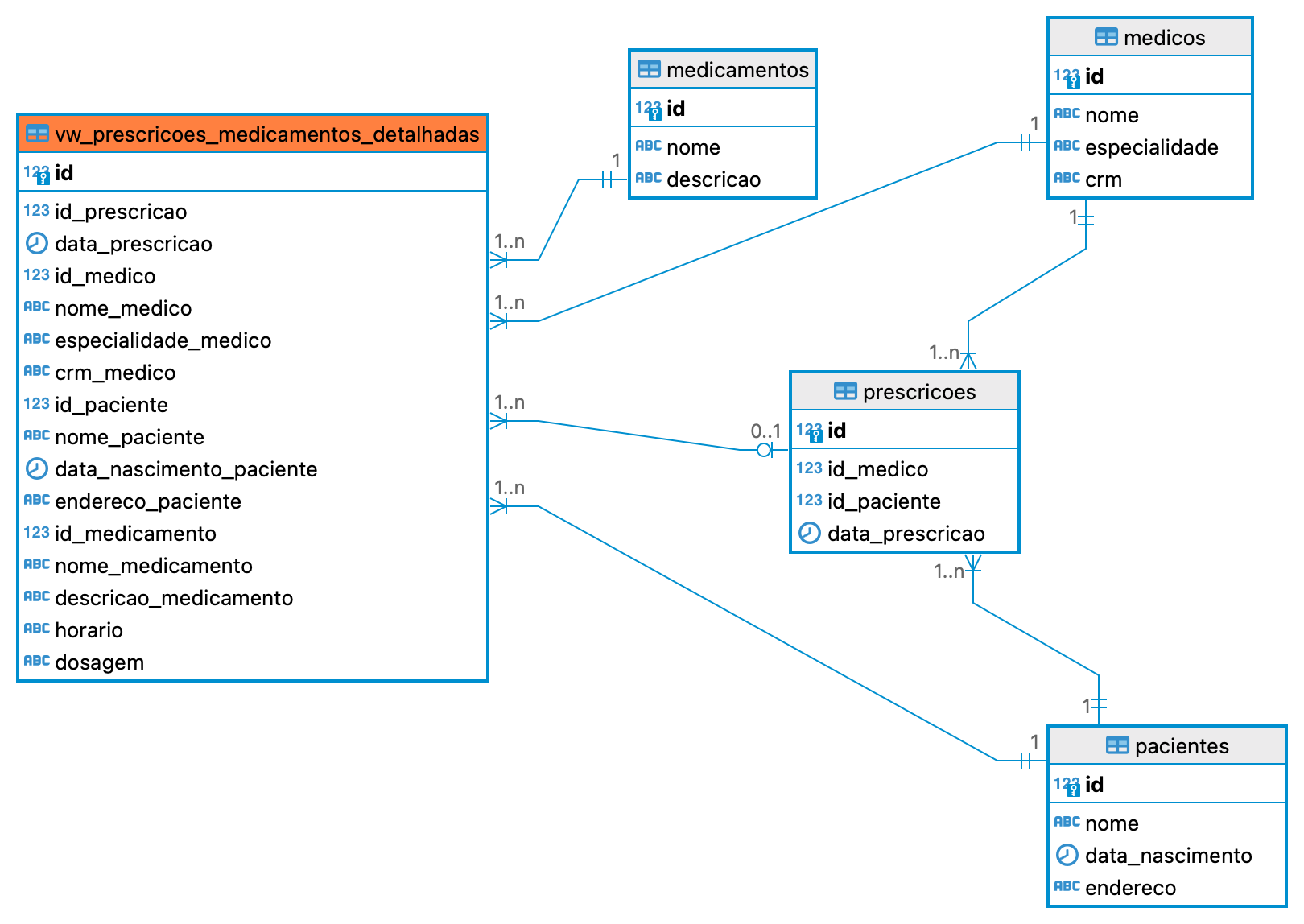
Para externalizar essa consulta para um modelo especializado, a primeira possibilidade seria criar uma segunda tabela semidesnormalizada, mantendo apenas a consistência entre IDs e relacionamentos para evitar corrupção em um nível básico e colocando em linha a prescrição dos medicamentos de forma descritiva. Isso elimina a necessidade de joins entre tabelas constantemente, entregando a view específica para o subsistema de farmácia.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
CREATE TABLE IF NOT EXISTS vw_prescricoes_medicamentos_detalhadas (
id SERIAL PRIMARY KEY,
id_prescricao INT,
data_prescricao TIMESTAMP NOT NULL,
id_medico INT NOT NULL,
nome_medico VARCHAR(255) NOT NULL,
especialidade_medico VARCHAR(255) NOT NULL,
crm_medico VARCHAR(8) NOT NULL,
id_paciente INT NOT NULL,
nome_paciente VARCHAR(255) NOT NULL,
data_nascimento_paciente DATE NOT NULL,
endereco_paciente VARCHAR(255),
id_medicamento INT NOT NULL,
nome_medicamento VARCHAR(255) NOT NULL,
descricao_medicamento TEXT,
horario VARCHAR(50) NOT NULL,
dosagem VARCHAR(50) NOT null,
FOREIGN KEY (id_medico) REFERENCES Medicos(id),
FOREIGN KEY (id_paciente) REFERENCES Pacientes(id),
FOREIGN KEY (id_medicamento) REFERENCES Medicamentos(id),
FOREIGN KEY (id_prescricao) REFERENCES Prescricoes(id)
);
Exemplo de modelagem para um padrão de leitura otimizado para a triagem de farmácia
Para ilustrar inicialmente, supondo que a tabela otimizada para consulta esteja presente no mesmo banco de dados, podemos iniciar uma carga inicial com os dados presentes localmente, utilizando como base a query anterior com todos os joins necessários. Em seguida, conseguiremos simplificar a busca dos dados da prescrição de forma detalhada com apenas um select simples em uma única tabela analítica, onde os dados estão compilados.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
INSERT INTO vw_prescricoes_medicamentos_detalhadas (
id_prescricao,
data_prescricao,
id_medico,
nome_medico,
especialidade_medico,
crm_medico,
id_paciente,
nome_paciente,
data_nascimento_paciente,
endereco_paciente,
id_medicamento,
nome_medicamento,
descricao_medicamento,
horario,
dosagem
)
SELECT
p.id AS id_prescricao,
p.data_prescricao,
m.id AS id_medico,
m.nome AS nome_medico,
m.especialidade AS especialidade_medico,
m.crm as crm_medico,
pac.id AS id_paciente,
pac.nome AS nome_paciente,
pac.data_nascimento AS data_nascimento_paciente,
pac.endereco AS endereco_paciente,
med.id AS id_medicamento,
med.nome AS nome_medicamento,
med.descricao AS descricao_medicamento,
pm.horario,
pm.dosagem
FROM
Prescricoes p
JOIN Medicos m ON p.id_medico = m.id
JOIN Pacientes pac ON p.id_paciente = pac.id
JOIN Prescricao_Medicamentos pm ON p.id = pm.id_prescricao
JOIN Medicamentos med ON pm.id_medicamento = med.id;
Exemplo de carregamento inicial da tabela de view com os dados presentes no modelo normalizado
1
SELECT * FROM vw_prescricoes_medicamentos_detalhadas WHERE id_prescricao = 1;
1
2
3
1 1 2023-05-20 14:30:00.000 1 Dr. João Silva Cardiologia CRM12345 1 Maria Oliveira 1985-07-10 Rua das Flores, 123 1 Aspirina Analgésico e anti-inflamatório 08:00 100mg
2 1 2023-05-20 14:30:00.000 1 Dr. João Silva Cardiologia CRM12345 1 Maria Oliveira 1985-07-10 Rua das Flores, 123 2 Paracetamol Analgésico 20:00 500mg
20 1 2023-05-20 14:30:00.000 1 Dr. João Silva Cardiologia CRM12345 1 Maria Oliveira 1985-07-10 Rua das Flores, 123 1 Aspirina Analgésico e anti-inflamatório 08:00 100mg
Com o exemplo acima, conseguimos otimizar inicialmente uma visualização dentro de um modelo de leitura para a farmácia do hospital, no qual os sistemas conseguem recuperar os dados de forma simplificada. Esse tipo de estratégia é muito comum para criar visualizações especializadas em diversos tipos de sistemas e viabiliza algumas abordagens interessantes de segregação de responsabilidade de escrita e leitura de forma simplificada. No entanto, executar o carregamento de dados como o exemplo ilustrado é inviável em sistemas transacionais com um volume considerável, uma vez que executar o select da base de dados inteira para carregar em uma tabela especializada não resolveria e talvez agravasse problemas de escala de uso desses dados. Para isso, precisamos adicionar responsabilidades adicionais aos modelos de comando e consulta, muitas vezes utilizando a consistência eventual nos modelos de leitura.
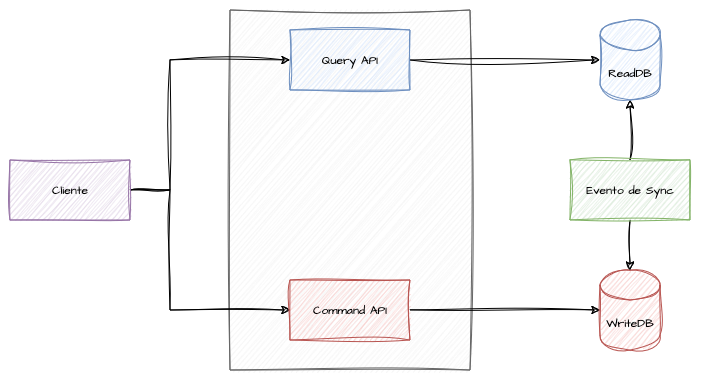
Para realizar a sincronização entre os modelos de escrita e leitura de forma saudável, o uso de mensageria e eventos como intermediários entre ambos pode ajudar a desacoplar as responsabilidades e fazer com que ambos escalem independentemente um do outro. No entanto, a consistência eventual é um efeito colateral que precisa ser considerado no design da arquitetura para viabilizar esse comportamento.
Consistência Eventual no CQRS
No contexto de CQRS, a consistência eventual pode ser de grande valor quando prevista e aceita no design da solução. Diferente de sistemas tradicionais que podem garantir uma consistência imediata entre os modelos de dados, aceitar o comportamento de um sistema eventualmente consistente pressupõe que o sistema pode operar de forma inconsistente por um período de tempo sem grandes problemas e também pressupõe que, com o tempo, o sistema ou entidade se tornará consistente.
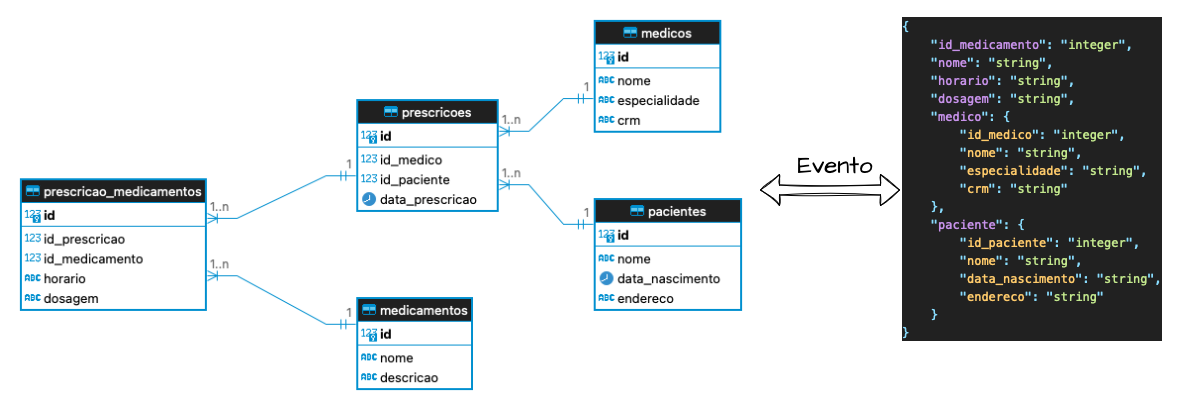
Na prática, olhando para uma implementação de CQRS que suporte esse tipo de cenário, onde os modelos de comando e consulta são separados e controlados por funcionalidades e implementações distintas, as operações de escrita são processadas no modelo de comando e, em seguida, eventos ou mensagens são gerados para atualizar o modelo de consulta de forma assíncrona, o que implica que pode haver um atraso antes que o modelo de consulta reflita as últimas mudanças realizadas no modelo de comando. Durante esse intervalo, o sistema está em um estado de “consistência eventual”.
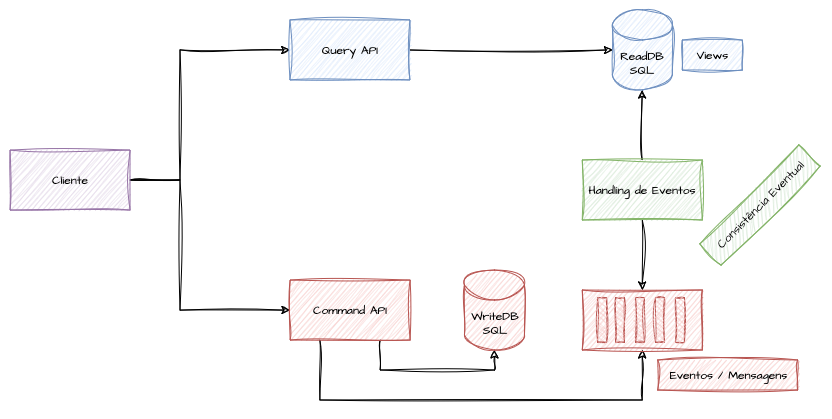
Para realizar a sincronização entre modelos, são necessários esforços computacionais adicionais, sendo eles processos assíncronos de mensageria que trocam dados por meio de tópicos ou filas e realizam a escrita no modelo de consulta, criando views otimizadas para a recuperação. Esse processo pressupõe a existência de um comportamento adicional independente, que não deve impactar agressivamente a performance.
Para ilustrar, podemos entender que após o processamento e persistência dos dados no modelo de escrita, o processo encapsulado no comando envia alguma mensagem ou evento contendo todos os dados necessários para que uma aplicação ou processo de sincronização consiga construir a representação do registro no modelo de consulta.
CQRS e Réplicas de Leitura
À medida que a intensidade de escrita aumenta devido à sincronização dos modelos, o próprio modelo de leitura tende a acabar sendo saturado pela carga de trabalho, pois ainda centraliza uma grande concorrência de escrita e leitura do sistema e dos clientes, por mais que essas operações sejam otimizadas. Olhando para a solução que o CQRS visa implementar, podemos perceber que, com o tempo, apenas trocamos o problema de lugar. No entanto, existem algumas outras abordagens de otimização do modelo de leitura em uma abordagem SQL.
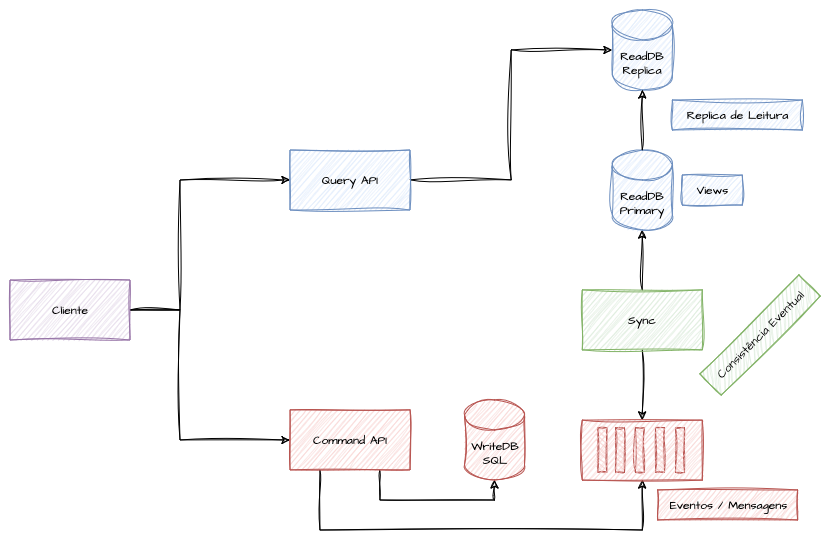
Se aproveitarmos a já aceita consistência eventual entre os modelos, podemos utilizar réplicas de leitura adicionais como banco principal para o modelo de consulta, deixando a instância primária somente para fazer offload da escrita e evitar concorrência com o uso da API. Esse tipo de abordagem aumenta consideravelmente os custos operacionais, mas adiciona uma camada adicional de resiliência de dados. Resumindo de forma prática, se presumirmos que a sincronização entre os modelos ocorre mediante a escrita nas duas bases e que as queries não podem efetuar mudanças no estado das entidades, podemos adicionar instâncias read-only no processo para ganhar níveis de performance.
CQRS e Bancos de Dados NoSQL
A implementação de modelos NoSQL para suprir a responsabilidade de leitura pode ser uma alternativa interessante devido à troca de isolamento, relacionamento e atomicidade por performance, otimizada para escrita e leitura. Uma vez que não precisamos das features ACID nos modelos de leitura, podemos aceitar o trade-off para otimização de consultas com maior segurança.
A implementação desse modelo é exatamente igual, topologicamente falando, à de utilizar ambas as bases no padrão SQL, com exceção de que suas aplicações ou processos do contexto do domínio precisam conhecer os dois dialetos e saber trabalhar a tradução entre eles por meio de processos intermediários.
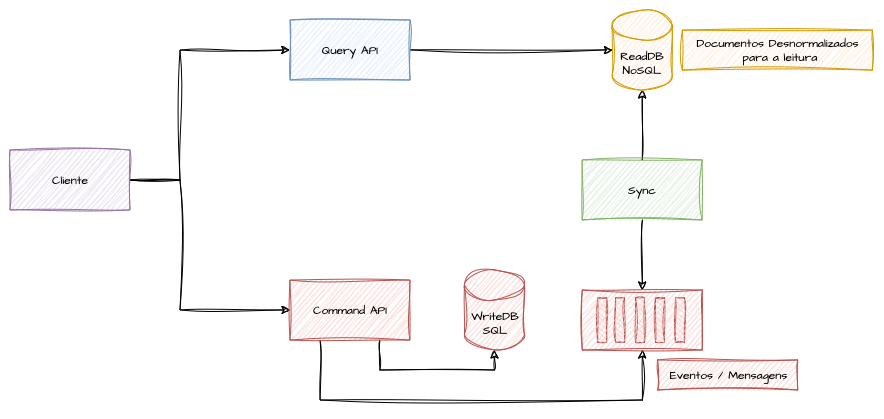
Imagine que precisamos converter os dados de todas as prescrições do cliente para construir prontuários médicos eletrônicos para acompanhamento e gestão interna do hospital e também servir para gerar receitas médicas das consultas e entregá-las diretamente ao paciente. Os dois casos são muito parecidos e podemos criar um query model NoSQL muito próximo do response de um prontuário ou receita.
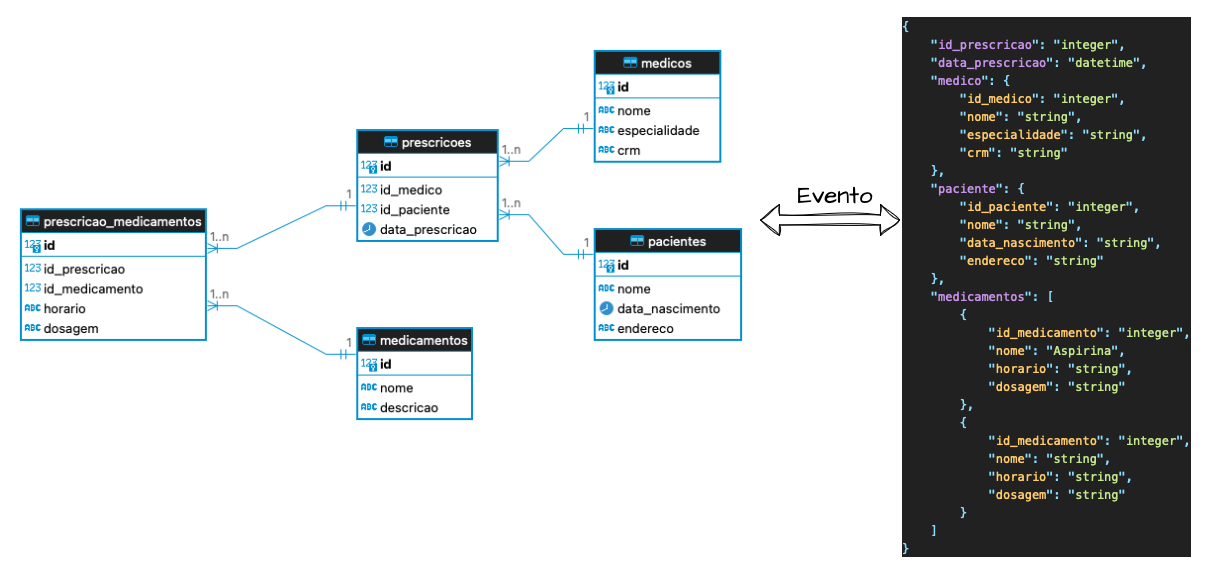
Podemos usar o padrão CQRS para transformar esse modelo de consulta em um padrão NoSQL orientado a documentos. Nesse caso, todas as informações da prescrição são agrupadas em um modelo de prontuário ou receita médica, similar a um response HTTP que seria criado manualmente, juntando as linhas retornadas. Quando comandos de escrita são executados no sistema, eventos ou mensagens com todas as informações do prontuário precisam ser gerados nos brokers para criar uma visualização otimizada.
Para este exemplo, vamos usar o Elasticsearch como base para converter o modelo para NoSQL. Nele, podemos criar um mapeamento para garantir a estrutura mínima dos campos e tipos necessários para construir uma visualização segura. Esse mapeamento pode ser criado de forma semelhante ao evento de entrada e ao payload de resposta, garantindo um formato base otimizado para a resposta esperada da API de consulta do domínio.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
// PUT /prontuarios
{
"mappings": {
"properties": {
"id_prescricao": { "type": "integer" },
"data_prescricao": { "type": "date" },
"medico": {
"properties": {
"id_medico": { "type": "integer" },
"nome": { "type": "text" },
"crm": { "type": "text" },
"especialidade": { "type": "text" }
}
},
"paciente": {
"properties": {
"id_paciente": { "type": "integer" },
"nome": { "type": "text" },
"data_nascimento": { "type": "date" },
"endereco": { "type": "text" }
}
},
"medicamentos": {
"type": "nested",
"properties": {
"id_medicamento": { "type": "integer" },
"nome": { "type": "text" },
"horario": { "type": "text" },
"dosagem": { "type": "text" }
}
}
}
}
}
1
2
3
4
5
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "prontuarios"
}
Após a criação de um mapping, precisamos criar um processo que recebe o evento de domínio decorrente de um comando de escrita e o transforma para o padrão de documento estabelecido. A escolha da tecnologia do banco de dados deve ser levada em conta nesse processo, uma vez que pode ou não haver todos os dados em um único evento para construir a view de leitura de forma íntegra. Caso esse processo seja feito com dados distribuídos que são recebidos, consolidados e disponibilizados de forma assíncrona e incremental, o modelo NoSQL deverá ser capaz de receber incrementos parciais dos registros.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
// POST /prescricoes/_doc/1
{
"id_prescricao": 1,
"data_prescricao": "2023-05-20T14:30:00.000Z",
"medico": {
"id_medico": 1,
"nome": "Dr. João Silva",
"especialidade": "Cardiologia",
"crm": "CRM123123"
},
"paciente": {
"id_paciente": 1,
"nome": "Maria Oliveira",
"data_nascimento": "1985-07-10",
"endereco": "Rua das Flores, 123"
},
"medicamentos": [
{
"id_medicamento": 1,
"nome": "Aspirina",
"horario": "08:00",
"dosagem": "100mg"
},
{
"id_medicamento": 2,
"nome": "Paracetamol",
"horario": "20:00",
"dosagem": "500mg"
}
]
}
Esse modelo de database nos permite uma variedade muito grande de possibilidades de consulta. Caso a chave do índice ou da coleção do seu modelo seja conhecida e mantida pelo modelo original de escrita, a busca pode ser realizada diretamente por ela, o que invariavelmente garante uma performance otimizada para a recuperação desses dados.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
// GET /prescricoes/_doc/1
{
"_index": "prescricoes",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"id_prescricao": 1,
"data_prescricao": "2023-05-20T14:30:00.000Z",
"medico": {
"id_medico": 1,
"nome": "Dr. João Silva",
"especialidade": "Cardiologia",
"crm": "CRM123123"
},
"paciente": {
"id_paciente": 1,
"nome": "Maria Oliveira",
"data_nascimento": "1985-07-10",
"endereco": "Rua das Flores, 123"
},
"medicamentos": [
{
"id_medicamento": 1,
"nome": "Aspirina",
"horario": "08:00",
"dosagem": "100mg"
},
{
"id_medicamento": 2,
"nome": "Paracetamol",
"horario": "20:00",
"dosagem": "500mg"
}
]
}
}
CQRS em Sistemas Distribuídos
A arquitetura CQRS, quando aplicada a sistemas distribuídos e granulares, pode ofertar aumentos significativos de resiliência, performance e facilidade para sumarizar dados de domínio distribuídos entre contextos de múltiplos microserviços. Quando adotamos um modelo de microserviços no qual segregamos databases especialistas para cada tipo de serviço, torna-se mais difícil criar consultas que unam e retornem dados de diferentes serviços. Esse tipo de implementação pode oferecer abordagens de consolidação para otimizar as operações de query e replicação de dados.
A construção de views otimizadas utilizando dados de vários serviços por meio de eventos e mensagens pode facilitar alguns cenários, porém igualmente acarreta um aumento de complexidade e granularidade no ambiente, que pode se tornar um tópico complexo na arquitetura de solução. Esse tipo de abordagem pode ser um pouco controverso em termos mais puristas de domínio, nos quais se limita a separação de comando e query somente dentro da responsabilidade de um domínio específico, mas a capacidade de estender os conceitos desse tipo de abordagem para entregar modelos consolidados com informações de diferentes domínios pode ser uma grande adição à sua caixa de ferramentas de arquitetura de solução.

Consolidação de eventos de diversos event-stores de comandos para compor modelos de dados com dados distribuídos.
O preço da consistência eventual nesse tipo de cenário tende a se tornar cada vez maior, dependendo da quantidade de fontes de eventos que vão ser tratadas e sumarizadas. Vamos estender o exemplo do sistema hospitalar mais uma vez, onde agora precisamos criar uma forma de recuperar todo o histórico do paciente para fins de auditoria, faturamento e treinamento de modelos. Temos serviços espalhados na arquitetura que são responsáveis por tratar da triagem inicial, prescrições médicas, exames laboratoriais e exames de imagem que foram realizados por determinado paciente. Essas informações precisam ser recuperadas de forma consolidada por atendimento médico individual, mas também precisam retornar todo o histórico do paciente durante seus anos de relacionamento como cliente do hospital.
Nesse sistema, temos serviços espalhados pela arquitetura responsáveis pela triagem inicial, prescrições médicas, exames laboratoriais e exames de imagem. Precisamos consolidar essas informações por atendimento médico individual e também recuperar todo o histórico do paciente ao longo dos anos. Esse é um caso interessante para usar uma visualização consolidada entre vários domínios que expõem seus dados por meio de tópicos de consolidação. Podemos criar listeners tanto para eventos de comando quanto para tópicos de resposta que confirmem o sucesso da execução, construindo um modelo de consulta que agrupa os dados.
Esse modelo de leitura deve permitir atualizações incrementais e aceitar uma consistência eventual contínua, já que o tempo de construção do registro pode variar conforme a demanda e o número de fontes de dados. Essa abordagem é útil para recuperar dados em tempo real, mesmo com consistência eventual. É uma alternativa a jobs de ETL que fazem essa agregação por meio de batches programados, ou a padrões como API-Composition, que podem comprometer a disponibilidade do serviço devido ao alto acoplamento entre diferentes serviços para construir a resposta.
Pattern de Dual-Write no Contexto de CQRS
Quando olhamos friamente, sob a ótica da resiliência de sistemas distribuídos para o padrão de comando, pode surgir um alerta de consistência importante, em que, em dois passos (persistir no banco e publicar o evento), o que ocorreria caso um deles falhasse e o outro fosse executado? Imagine que, por indisponibilidade temporária do broker de mensagens, o dado fosse persistido na base de dados durante a execução do comando, porém ocorresse uma falha na publicação da mensagem. Esse cenário levaria a uma inconsistência sistêmica, em que o estado alterado pelo comando não refletiria nas APIs de consulta.
Agora vamos olhar para o cenário inverso, onde, por acaso, a publicação da mensagem ocorresse como previsto, mas uma falha inesperada ocorresse no banco de dados. Nesse caso, teríamos um nível similar de inconsistência, em que dados que não existem na base de escrita transacional estariam disponibilizados nas APIs de consulta como se o comando executado tivesse sido efetivado.
Ambos os cenários são problemáticos para sistemas que precisam de integridade forte, e para isso existem alguns padrões de design que podem nos ajudar a garantir mais níveis de segurança aos processos de comando e leitura. Um deles é o Dual-Write.
O padrão Dual-Write se aplica quando precisamos confirmar a consistência do dado em duas fontes distintas e dependentes, mesmo que de maneira assíncrona. No caso do CQRS, ele é aplicado para manter os modelos de comando e consulta sincronizados. Quando um comando é emitido para alterar o estado do sistema, ele é processado pelo modelo de comando. Isso inclui validações, lógica de negócios e atualização do banco de dados de escrita. Após a operação de escrita ser concluída com sucesso, um evento correspondente é gerado. Esse evento descreve a mudança que ocorreu e deve ser propagado para o modelo de consulta. Para garantir que um ou outro não ocorra isoladamente, o padrão busca assegurar que os dados não sejam alterados em caso de falha de publicação do evento e que o evento não seja publicado em caso de falha na escrita do banco, um garantindo o outro.
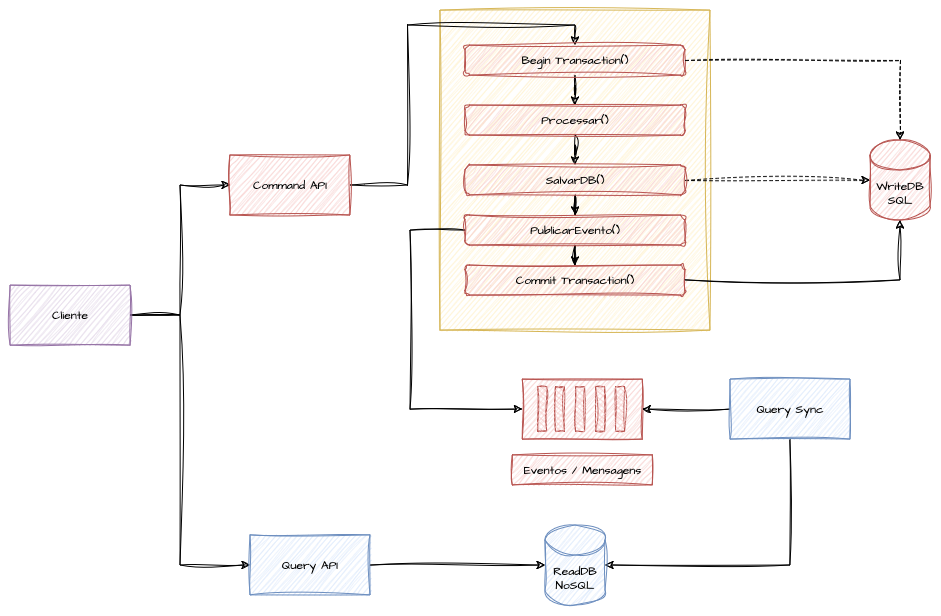
Exemplo de Dual Write implementado para garantir a escrita em banco e a publicação do evento
Para tornar esse nível de confiabilidade possível, é necessário que todas as transações do banco de dados de escrita ocorram dentro de transações atômicas, nas quais todas as modificações de estado estejam dentro de uma atividade única e indivisível. Esse tipo de abordagem só acontece de forma efetiva em bancos de dados transacionais ACID, que dão suporte a transações com commit e rollback. Nesse caso, todas as transações obrigatoriamente precisam iniciar uma transaction antes de efetuar todas as modificações necessárias. Caso tudo ocorra como o esperado, incluindo a publicação do evento, o commit é realizado, efetuando todas as operações de uma única vez.

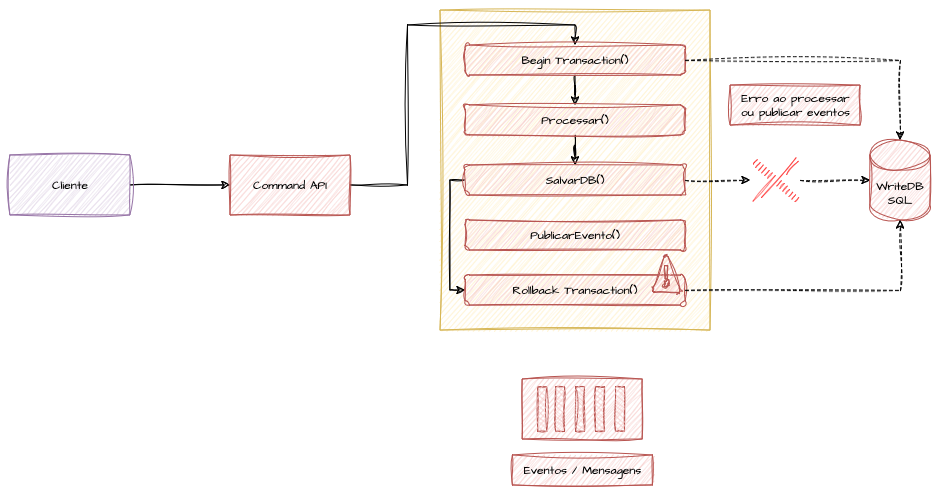
Exemplo de falhas que podem ocorrer em processos e integrações sendo respondidas com um rollback
Em caso de falhas em alguma etapa do processo, o rollback deverá ser iniciado, não efetivando as operações de escrita que foram realizadas dentro da transaction.
Outbox Pattern no Contexto de CQRS
O Transactional Outbox Pattern é uma alternativa ao Dual-Write Pattern, projetado para garantir a consistência entre a escrita no banco de dados e a publicação de eventos em sistemas distribuídos que utilizam bancos de dados SQL. No contexto do CQRS, é de extrema importância que os eventos de mudança de estado sejam corretamente propagados para os modelos de consulta. Garantir que uma alteração de estado no banco de dados e a publicação de um evento correspondente ocorram de maneira atômica significa que ambos devem ser concluídos com sucesso ou nenhum deles deve ser executado.
O Outbox Pattern resolve esses problemas armazenando eventos em uma tabela de outbox dentro do mesmo banco de dados transacional utilizado para persistir o estado. Quando um comando é processado e uma alteração de estado é feita, um evento correspondente é criado em uma tabela de outbox na mesma transação do banco de dados. Um serviço ou processo intermediário assíncrono lê periodicamente os eventos da tabela de outbox de forma sequencial, publica esses eventos no sistema de mensageria e, em seguida, marca-os como publicados ou os remove da tabela.

Esse padrão envolve três componentes principais: a tabela outbox, o processo de publicação, também conhecido como relay de mensagem, e a gestão de erros, obrigatória para tornar o padrão de fato resiliente para o propósito pelo qual foi concebido. A tabela outbox é uma tabela no banco de dados transacional onde os eventos são armazenados temporariamente. Essa tabela deve estar presente na mesma transação que a escrita de dados para garantir a atomicidade. O processo de publicação é um serviço ou processo assíncrono que periodicamente lê eventos da tabela de outbox, publica esses eventos no sistema de mensageria do sistema e, em seguida, marca os eventos como publicados ou os remove da tabela (preferencialmente). A gestão de erros deve incluir mecanismos para lidar com falhas na publicação, como retentativas e monitoramento, para garantir que todos os eventos sejam eventualmente publicados e somente removidos mediante essa confirmação.
Imagine que precisamos criar uma view das prescrições do prontuário médico. Para isso, vamos criar uma tabela outbox para armazenar os eventos de prescrição dentro da transação que salva as prescrições na tabela principal de escrita.
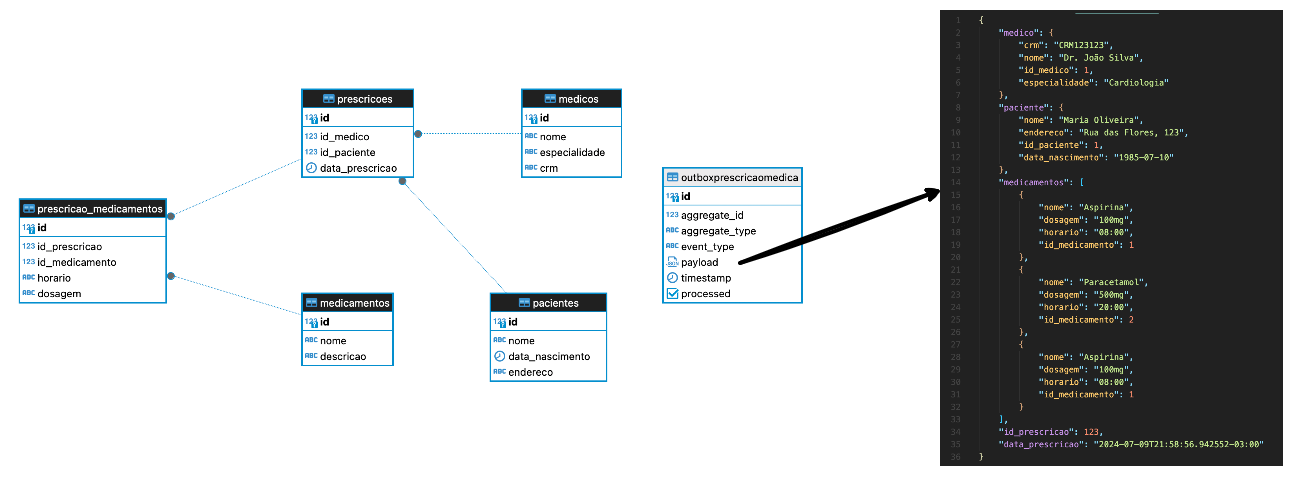
1
2
3
4
5
6
7
8
9
CREATE TABLE IF NOT EXISTS OutboxPrescricaoMedica (
id SERIAL PRIMARY KEY,
aggregate_id INT NOT NULL,
aggregate_type VARCHAR(255) NOT NULL,
event_type VARCHAR(255) NOT NULL,
payload JSONB NOT NULL,
timestamp TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
processed BOOLEAN NOT NULL DEFAULT FALSE
);
Agora vamos olhar abaixo para uma transação SQL que simula um fluxo transacional que agrupa a escrita da prescrição de medicamentos dentro de uma prescrição médica e o evento na tabela de Outbox dentro da mesma transação.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
-- Inicia uma transação SQL
BEGIN
-- Insere as Prescrições de Medicamentos da Prescrição de id 1
INSERT INTO Prescricao_Medicamentos (id_prescricao, id_medicamento, horario, dosagem)
VALUES (1, 1, '08:00', '100mg'),
(1, 2, '20:00', '500mg'),
(1, 1, '20:00', '500mg');
--- Insere os dados na tabela de outbox
INSERT INTO OutboxPrescricaoMedica (aggregate_id, aggregate_type, event_type, payload)
VALUES (
1,
'Prescricao',
'PrescricaoCriada',
jsonb_build_object(
'id_prescricao', 1,
'data_prescricao', NOW(),
'medico', jsonb_build_object(
'id_medico', 1,
'nome', 'Dr. João Silva',
'especialidade', 'Cardiologia',
'crm', 'CRM123123'
),
'paciente', jsonb_build_object(
'id_paciente', 1,
'nome', 'Maria Oliveira',
'data_nascimento', '1985-07-10',
'endereco', 'Rua das Flores, 123'
),
'medicamentos', (
SELECT jsonb_agg(
jsonb_build_object(
'id_medicamento', Medicamentos.id,
'nome', Medicamentos.nome,
'horario', Prescricao_Medicamentos.horario,
'dosagem', Prescricao_Medicamentos.dosagem
)
)
FROM Prescricao_Medicamentos
JOIN Medicamentos ON Medicamentos.id = Prescricao_Medicamentos.id_medicamento
WHERE Prescricao_Medicamentos.id_prescricao = 1
)
)
);
-- Caso tudo dê certo, realiza o commit da transacao
COMMIT;
O processo que ocorre durante a implementação do Outbox leva mais a sério a mediação da publicação do evento dentro da abordagem transacional do que o proposto no Dual-Write, apostando no sucesso da propagação do evento pela simplicidade, mesmo que dependa de um processo adicional para ler e publicar.
Essa abordagem, apesar de oferecer alguns graus de segurança adicionais na garantia de publicação, requer um custo computacional adicional na base de dados devido à leitura e à escrita constantes na tabela de outbox. Esse cenário pode se tornar um gargalo em caso de aumento de escala. Entendemos que as capacidades de leitura e escrita em concorrência podem ser comprometidas e afetar mais facilmente a performance do sistema como um todo nesse tipo de cenário transacional, que tende a ser a parte mais difícil de escalar em sistemas de grande escala.
Revisores
Referencias
Centro de Arquitetura Microsoft - Padrão CQRS
CQRS (Command Query Responsibility Segregation) em uma Arquitetura de Microsserviços
Command Query Responsibility Segregation (CQRS)
Microservices Patterns: API Composition and CQRS Patterns
Pattern: Command Query Responsibility Segregation (CQRS)
CQRS na AWS: Sincronizando os Serviços de Command e Query com o Padrão Transactional Outbox
CQRS na AWS: Sincronizando os Serviços de Command e Query com o Amazon SQS
