
System Design - Scale Cube

Texto extra da série de System Design. Esse texto foi resultado de uma revisão bibliográfica - não cientifica - que fiz para arquivo pessoal.
O Scale Cube, ou Cubo da Escalabilidade, é um modelo conceitual apresentado no livro “The Art of Scalability”, de Martin L. Abbott e Michael T. Fisher, que propõe uma modelagem de microserviços voltada à escalabilidade desde o dia zero. O modelo utiliza a analogia de um “cubo” porque é descrito com três dimensões: os eixos X, Y e Z, também conhecidos como Largura, Altura e Profundidade, onde cada uma corresponde a um princípio de escalabilidade de serviços, permitindo arquitetar soluções para demandas crescentes de uso.
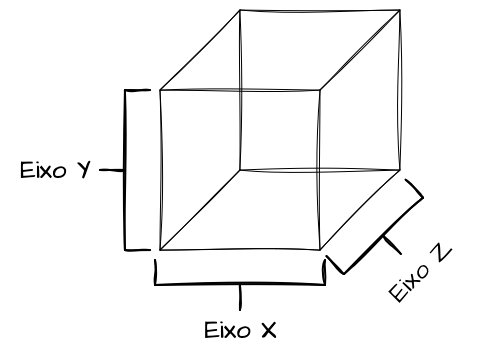
O Scale Cube oferece um modelo mental para pensar e definir o que levar em conta ao projetar ou refatorar sistemas, de forma que eles consigam atingir níveis elevados de escalabilidade. As três dimensões correspondem a Eixo X: Escalabilidade Horizontal, Eixo Y: Decomposição de Funcionalidades e Eixo Z: Sharding e Particionamento de Dados.
Eixo X - Escalabilidade Horizontal
O Eixo X sugere que a aplicação deve ser capaz de escalar horizontalmente à medida que seus níveis de uso e saturação começam a ser impactados, para evitar sobrecarga sob demanda. Ou seja, a solução como um todo, seja por meio de arquiteturas orquestradas de containers ou não, deve ser capaz de adicionar e remover réplicas idênticas da mesma aplicação conforme necessário. Caso essas réplicas sejam acionadas por requisições HTTP, elas devem ser capazes de receber tráfego por meio de componentes intermediários, como Balanceadores de Carga.

Essa dimensão é relativamente fácil de implementar, já que é uma característica intrínseca da maioria das plataformas que permitem a execução de software em produção, sejam elas nativas de nuvens públicas ou orquestradores de containers. Ao considerar a construção de arquiteturas stateless que permitem a realização de requisições sequenciais por servidores distintos e que administrem o estado de entidades e processos de maneira distribuída em vez de local, a implementação da escalabilidade horizontal tende a ser a parte mais simples do modelo.
Eixo Y - Quebra de Funcionalidades
O Eixo Y propõe a divisão das funcionalidades de um sistema. O objetivo é decompor e separar as funcionalidades de um sistema maior em vários microserviços especializados, em contextos isolados e desacoplados. Basicamente, é aqui que ocorre o processo de quebra de um monolito em microserviços. Com isso, torna-se possível que cada uma dessas funcionalidades escale de forma independente e seja otimizada de acordo com suas características específicas. Por exemplo, se um desses serviços tiver características de CPU Bound e outro, de outra funcionalidade, for mais I/O intensivo, cada um pode ser otimizado de forma isolada, sem impactar o outro, utilizando os recursos e especificações ideais para cada cenário.
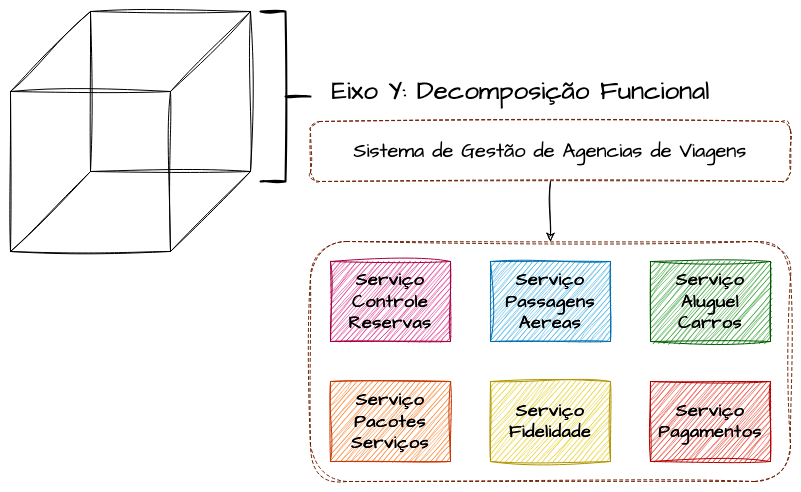
Junto com o Eixo X, o Eixo Y assegura grande parte das características dos microserviços como os conhecemos hoje. Transformar funcionalidades em serviços especializados, que podem ser escalados horizontalmente com base em suas particularidades, proporciona uma experiência realista de um sistema distribuído.
Eixo Z - Sharding de Dados
O Eixo Z é o mais complexo do modelo em termos de funcionalidades e implementação. Ele propõe que todos os dados possam ser particionados e distribuídos entre vários clusters, servidores, bancos de dados e similares. A estratégia de dividir grandes conjuntos de dados em partes menores é chamada de sharding ou particionamento. Cada shard representa uma fração do total de dados.

Como foi abordado conceitualmente no capítulo de Sharding e Particionamento, dividir a quantidade de dados entre vários servidores independentes e rotear a requisição para a partição correta com base em uma chave de partição nos ajuda a escalar a camada mais delicada e complexa de sistemas distribuídos: a camada de persistência. Utilizando uma sharding key fornecida por algum atributo de acesso ao sistema, como iniciais de um cliente, intervalos de identificadores sequenciais, intervalos de datas ou hash de algum valor forte, conseguimos criar segregações e roteamentos inteligentes que reduzem o blast radius em caso de falha e nos permitem escalar a camada de dados de forma quase horizontal.
Essa abordagem é a mais complexa do modelo, pois necessita de camadas adicionais de engenharia, estratégias para a distribuição dos dados e mecanismos que forneçam formas inteligentes para que o roteamento da chamada encontre seu destino correto.
Uso do Scale Cube
Com a utilização adequada de todas as dimensões, podemos adicionar níveis de confiabilidade e escalabilidade em diversos cenários complexos de sistemas distribuídos, simplificando a decomposição, a escalabilidade horizontal e a distribuição controlada de dados entre os serviços que compõem o sistema. Além de garantir escalabilidade sob alta demanda, isso nos permite explorar opções de processos de deployment, facilitando a adoção de estratégias mais personalizadas de release, como Blue/Green Deployments e Canary Releases. Consequentemente, isso aumenta a resiliência e a eficácia operacional.
O modelo do Scale Cube, apesar de ser altamente conceitual e atuar apenas como um mapa mental — não sendo um modelo de governança arquitetônica em si —, contribui para esclarecer as preocupações que devemos considerar ao projetar sistemas críticos. Ele cumpre seu propósito ao aprimorar o senso crítico de arquitetura e engenharia das equipes envolvidas em um projeto de software.
Referências
The Scale Cube - 3 Dimensions to Scale
