
System Design - Padrões de Comunicação Síncronos

Este texto é uma continuação direta do capitulo onde falamos sobre Protocolos e Comunicação de Redes. A ideia é seguir com os conceitos direcionados anteriormente para aplicá-los em diferentes tipos de padrões de comunicação empregados na contrução de software em arquiteturas modernas e distribuídas. Nesse capítulo iremos falar sobre alguns padrões que podemos utilizar para construção de chamadas sincronas entre serviços, aproveitando os conhecimentos ofertados quando abordamos sobre o Protocolo HTTP, TCP/IP e UDP para detalhar conceitualmente com a visão de System Design outras tecnologias e padrões como o Padrão REST, Webhooks, gRPC, Websockets e GraphQL.
Definindo Comunicações Sincronas
Uma comunicação síncrona, de forma bem direta e simples, é um padrão de comunicação utilizados em sistemas distribuídos, ou não, onde o cliente espera por uma resposta do servidor antes de prosseguir a execução de outras tarefas. Por exemplo, em um ambiente de microserviços de um domínio de logística, um sistema que estima o preço de um frete precisa recuperar em um outro sistema responsável pelo cadastro de seus clientes as informações de endereço antes de prosseguir com o calculo de fato.
Este modelo de comunicação é caracterizado por sua natureza “bloqueante”, significando que o processo que inicia a chamada fica “bloqueado” até que a operação e a comunicação com o servidor seja concluída, o que causa uma “espera ativa” entre os dois componentes. Em outras palavras, a comunicação síncrona envolve uma interação direta e imediata entre as partes, facilitando um “diálogo” que precise ser concluído fim-a-fim em tempo de execução de uma tarefa.
Esse padrão é muito bem recebido onde a consistência dos dados é de extrema importância, pois as operações podem ser facilmente feitas em uma sequência específica, além de ser muito mais simples e intuitiva em quesitos de entendimento e implementação.
Em quesito de desvantagens, a implementação de uma comunicação sincrona pode limitar a escalabilidade do sistema, uma vez que o bloqueio durante a espera por respostas pode reduzir a capacidade de processamento paralelo, além de afetar performance em cadeia, onde o mau funcionamento constante ou temporário de uma dependência específica entre uma série de chamadas pode acabar aumentando o tempo de resposta e processamento. O ponto mais crítico é que a indisponibilidade de um serviço que é dependente de um processo bloqueante pode invariávelmente degradar a disponibilidade geral de uma cadeia de processos.
Nesse sentido, por mais simples que sejam a construção e manutenção de chamadas sincronas, é necessário o cuidado com questões de retentativas, timeouts e outras estratégias de resiliência construída de forma pragmática entre cliente-servidor.
API’s REST - Representational State Transfer
O REST, ou Representational State Transfer, é um estilo arquitetônico para sistemas distribuídos que presa pela simplicidade da comunicação entre componentes na internet ou em redes internas de microserviços, sendo a principal abordagem na construção de comunicação sincrona entre serviços. Definido por Roy Fielding em sua tese de doutorado em 2000, REST não é um protocolo ou padrão, mas um conjunto de princípios arquitetônicos usados para projetar sistemas distribuídos escaláveis, confiáveis e de fácil manutenção. Os serviços que seguem os princípios REST são conhecidos como RESTful em API’s.
O REST é construído usando referências e recursos do protocolo HTTP, definindo papeis e responsabilidades de cliente-servidor e busca estabelecer uma interface de um cliente com os dados e ações de um sistema de forma intuitiva.
Ele utiliza métodos HTTP para definir ações, como GET, POST, PUT, DELETE e PATCH, para realizar operações CRUD (Criar, Ler, Atualizar e Deletar) em recursos identificados por URI’s. Esses recursos são representações de entidades ou objetos do domínio da aplicação. Nesse tópico vamos abordar alguns dos principais componentes do estilo arquitetural REST, e detalhar as partes mais importantes conceitualmente.
Componentes de uma requisição REST
Uma requisição REST é composta por vários componentes que trabalham juntos para transmitir a intenção da solicitação do cliente para o servidor. Cada componente tem um papel específico no fornecimento de informações para que o servidor processe a requisição através de recursos expostos de maneira intuitiva. Vamos abordar alguns dos componentes presentes numa requisição HTTP e seu eventual uso dentro do REST:
URI’s e URL’s
Dentro do contexto REST, os conceitos de URI e URL têm papéis específicos quando se tratam de identificar e interagir com recursos expostos por API’s. Em REST, um “recurso” é uma abstração de qualquer informação ou dado que pode ser nomeado e identificado, como documentos, imagens, serviços ou coleções de outros recursos, e assim por diante.
URI - Uniform Resource Identifier
Um URI, ou Uniform Resource Identifier, é uma string de caracteres que identifica um recurso específico. Um recurso pode ser qualquer coisa que seja identificável através de um endereço, como um documento, uma imagem, um serviço de transmissão de vídeo, ou uma coleção de outros recursos como listas de vendas, produtos, dados de usuário e etc. URIs servem como um mecanismo de identificação universal, permitindo que recursos sejam localizados e referenciados de forma única. Dentro do REST, cada recurso é identificado de forma única por um URI. Isso permite que clientes e servidores se refiram a um recurso específico sem ambiguidade. Por exemplo, um URI pode ser usado para identificar um determinado livro em um sistema de biblioteca, um usuário em uma rede social, ou uma transação em um sistema financeiro.
URL - Uniform Resource Locator
No REST, as URLs são o meio mais comum de expressar URIs, de forma direta, as URL’s são um subtipo de URI’s. Elas especificam não apenas a identidade de um recurso, mas também como acessá-lo. Por exemplo, a URL https://api.fidelissauro.dev/livro/1234 não apenas identifica um recurso de livro específico (1234) no domínio api.fidelissauro.dev, mas também indica como o recurso pode ser acessado usando o protocolo HTTPS. Uma vez que conseguimos identificar esses recursos de forma universal e padronizada, as URL’s que representam esses recursos podem ser usadas em conjunto com os métodos HTTP (GET, POST, PUT, DELETE, etc.) para realizar operações sobre os dados que fazemos gestão via API.
Recursos e Paths
Na arquitetura REST, os recursos são componentes que representam qualquer tipo de objeto, dado ou serviço que pode ser acessado pela rede em que o mesmo está disponível. Resumindo, um recurso é identificado por URIs, que são usados para localizar esses recursos na rede de forma explicita.
Os paths, por outro lado, fazem parte da URI, e especificam o endereço exato onde um recurso pode ser encontrado. Eles ajudam a organizar e a endereçar os recursos de forma hierárquica e lógica, facilitando o acesso e a manipulação destes. A estrutura de paths em uma API REST é projetada para ser intuitiva, refletindo a natureza e a relação entre os recursos. Por exemplo, em uma API que gerencia um sistema de blog, você pode ter um path /articles para acessar todos os artigos e /articles/{id} para acessar um artigo específico, e seguir com identificadores específicos para subrecursos como /articles/{id}/comments para comentários de um artigo específico.
Os recursos são planejados para serem acessados utilizando os métodos HTTP padrão (GET, POST, PUT, DELETE, etc.), em cada recurso que possui seu próprio identificador único como veremos a seguir.
Headers
Os Headers, ou cabeçalhos, são componentes do protocolo HTTP e que também são utilizados de forma informativa na arquitetura REST, e são usados tanto nas requisições quanto nas respostas para fornecer informações essenciais sobre a transação que foi realizada. Eles desempenham várias funções, como especificar o formato da mídia dos dados sendo transferidos, autenticar usuários, controlar o cache e etc. Em uma API REST, os headers permitem a comunicação de metadados entre cliente e servidor, facilitando a negociação de conteúdo e a implementação de segurança e outras funcionalidades importantes.
Exemplificamos alguns dos headers mais comuns quando abordamos o protocolo HTTP, a seguir alguns headers que são comuns quando estamos trocando dados entre cliente-servidor utilizando o padrão REST e suas principais funcionalidades:
| Header | Descrição |
|---|---|
Content-Type |
Especifica o tipo de mídia do corpo da requisição/resposta (ex: application/json). |
Accept |
Informa ao servidor os tipos de mídia aceitáveis como resposta. |
Authorization |
Contém as credenciais para autenticar o usuário que faz a requisição. |
Cache-Control |
Direciona o comportamento do cache no cliente e no servidor (ex: no-cache). |
ETag |
Um identificador único para uma versão específica de um recurso, usado para otimizar o cache. |
Location |
Indica a URL de um recurso recém-criado ou a URL para onde o cliente deve redirecionar. |
Content-Length |
Indica o tamanho, em bytes, do corpo da mensagem de requisição ou resposta. |
Date |
O tempo em que a mensagem foi enviada, para sincronização entre cliente e servidor. |
Query Strings
Na arquitetura REST, query strings são mecanismos usados para passar informações adicionais ao servidor durante uma requisição HTTP. Eles permitem a filtragem, a paginação, a ordenação e a personalização de dados, entre outras funcionalidades, tornando as APIs RESTful mais flexíveis, principalmente em recursos que fazem exposição e listagem de dados com o método GET. Elas podem ser usadas para uma variedade de propósitos, como filtragem de dados, ordenação e paginação.
As Query strings são utilizadas para fornecer informações adicionais que afetam a operação do servidor, mas que não fazem parte do path da URL. Elas são adicionadas ao final da URL com um ? e seguidas de pares chave-valor, com cada par separado por &. Por exemplo, /articles?author=fidelissauro&sort=date pode ser usada para solicitar artigos escritos por “fidelissauro”, ordenados pela data. As query strings são extremamente úteis para construção de API’s.
Body e Formatos
Na arquitetura REST, o body da requisição ou da resposta desempenha um papel de transportar dados entre o cliente e o servidor. Ele é usado principalmente em métodos HTTP como POST, PUT e PATCH, onde há a necessidade de enviar informações (como a criação ou atualização de recursos) em um formato estruturado. O conteúdo do body pode variar amplamente dependendo da operação realizada e dos dados sendo transmitidos, respeitando os contratos de request e response de comunicação definidos na API.
Utilização de Métodos HTTP para Representar Ações nos Paths
Os métodos HTTP, também conhecidos como “verbos”, definem ações que podem ser realizadas sobre os recursos representados nos paths. Eles permitem uma interação semântica com os recursos, onde cada método tem um propósito específico. As operações disponíveis para um recurso são definidas, por exemplo, usar o método GET para obter a representação de um recurso, POST para criar um novo recurso, PUT para atualizar um recurso existente, e DELETE para remover um recurso.
Idempotência nas Requisições REST
A idempotência é um conceito aplicado em vários lugares do desenvolvimento de software no geral, inclusive no design de APIs RESTful, e desempenha papeis importantes na construção de interfaces confiáveis e previsíveis.
Este conceito, quando aplicado corretamente, garante que múltiplas chamadas idênticas a um mesmo endpoint resultem sempre no mesmo estado do recurso, sem causar efeitos colaterais adicionais após a primeira aplicação. Isso garante com que tentativas de retry em uma chamada de um serviço, mesmo que por meio de erros, ou execuções parciais, tenha a capacidade de reproduzir os mesmos requests para nosso serviço evitando erros ou duplicidades. No REST alguns métodos HTTP devem ser implementados de forma naturalmente idempotente, outros devem implementar alguma lógica de composição de chaves de idempotência, checagem campos e outras estratégias para permitirem por exemplo, a criação de registros de forma idempotente. A seguir os métodos HTTP e suas possibilidades de idempotência:
| Método | Descrição | Idempotência |
|---|---|---|
| GET | Utilizado para recuperar a representação de um recurso sem modificá-lo. É seguro e idempotente, várias requisições idênticas devem ter o mesmo efeito que uma única requisição. | Sim |
| POST | Empregado para criar um novo recurso. Não é idempotente, pois realizar várias requisições POST pode criar múltiplos recursos. Em caso de necessidade de idempotência, será necessário a implementação de lógicas adicionais. | Não |
| PUT | Utilizado para atualizar um recurso existente ou criar um novo se ele não existir, no URI especificado. É idempotente, então múltiplas requisições idênticas terão o mesmo efeito sobre a entidade. | Sim |
| PATCH | Utilizado para aplicar atualizações parciais a um recurso. Ao contrário do PUT, que substitui o recurso inteiro, o PATCH modifica apenas as partes especificadas. É idempotente, pois a execução sob o mesmo recurso tende a gerar sempre o mesmo efeito e gerar o mesmo resultado. | Sim |
| DELETE | Empregado para remover um recurso. É idempotente, pois deletar um recurso várias vezes tem o mesmo efeito que deletá-lo uma única vez. | Sim |
Métodos HTTP nas URI’s e Recursos
As URIs, como abordamos, são utilizadas para identificar os recursos de forma única. Em uma API RESTful, as URIs são projetadas para serem intuitivas e descritivas, facilitando o entendimento e a navegação pelos recursos disponíveis. A estrutura de uma URI em REST reflete a organização dos recursos e suas relações.
As URIs quando olhadas no modelo REST, devem se referir a recursos e entidades, e não às ações que serão realizadas diretamente sobre eles. Por exemplo, o path /users para acessar recursos do usuário combinado com o método GET, e não um basepath imperativo como /getUsers.
A URI de determinadas entidades devem refletir a estrutura hierárquica dos recursos. Por exemplo, /users/123/articles pode representar os posts do usuário com ID 123.
Devem se utilizar querystrings como parametros de consulta para filtrar recursos ou modificar a saída de uma chamada REST. Por exemplo, /users?active=true para filtrar apenas usuários ativos ou /users/1/articles?tag=system-design para filtrar os posts do usuário com a tag system-design.
Considerando uma API para um portal de notícias ou blog, aqui estão exemplos de como os métodos HTTP e as URIs podem ser utilizados para interagir com os recursos:
| Ação | Método | Endpoint |
|---|---|---|
| Listar todos os posts | GET | /articles |
| Obter um post específico | GET | /articles/1 |
| Criar um novo post | POST | /articles |
| Atualizar um post existente | PUT | /articles/1 |
| Deletar um post | DELETE | /articles/1 |
| Atualizar parte de um post | PATCH | /articles/1 |
Status Codes de Resposta e Padrões do REST
Os códigos de status de resposta são recursos nativos do protocolo HTTP que são utilizados para implementações RESTful, pois são usados como convenção para indicar informações de estado das respostas de uma solicitação. Ele abre o leque das classes dando funcionalidades e representatividade a elas perante uma solicitação.
Os status codes mais utilizados em implementações RESTFul são os seguintes:
| Código | Descrição |
|---|---|
| 200 OK | Solicitação bem-sucedida para GET, PUT ou POST sem criação de recurso. |
| 201 Created | Nova criação de recurso resultante de uma solicitação POST. |
| 202 Accepted | Solicitação aceita para processamento; conclusão pendente. |
| 204 No Content | Solicitação bem-sucedida sem conteúdo para retornar. Comum após DELETE. |
| 400 Bad Request | Erro de cliente devido a sintaxe ou formato inválido. |
| 401 Unauthorized | Falha ou necessidade de autenticação. |
| 403 Forbidden | Servidor recusa a solicitação, apesar de compreendê-la. |
| 404 Not Found | Recurso solicitado não encontrado. |
| 405 Method Not Allowed | Método conhecido pelo servidor, mas desativado. |
| 500 Internal Server Error | Falha genérica do servidor. |
| 503 Service Unavailable | Servidor indisponível, geralmente por manutenção ou sobrecarga. |
| 504 Gateway Timeout | Tempo limite atingido por um servidor gateway ou proxy sem resposta do servidor upstream. |
Principios do REST
Os principios arquiteturais do REST estabelecem uma série de regras e bases de design para que times de engenharia projetem API’s de comunicação distribuida da melhor forma possível, prezando tanto pela experiência de consumo do cliente quanto do ciclo de vida e evolução saudável do projeto a médio e longo prazo. Nesta sessão vamos explorar alguns dos principios que podem ser esperados de implementações RESTFul.
Interface Uniforme
A interface uniforme é o princípio central do REST e diz respeito à consistência na forma como as interfaces são expostas aos clientes. Esse principio preza que cada recurso deve ser identificável de forma única através de URIs e suas respostas sejam representadas por dados padronizados, como JSON ou XML, e enviados ao cliente respeitando esses formatos. Também é importante ressaltar que as requisições e respostas devem conter toda a informação necessária para serem compreendidas, incluindo metadados e hiperlinks de uma forma quase auto-descritiva. De forma resumida, esse princípio garante uma padronização formal na forma como os clientes interagem com o servidor e vice versa.
Garantindo uma interface uniforme, arbitrariamente garantimos a interoperabilidade, ou seja, compatibilidade entre diferentes sistemas e tecnologias, pois independente do ferramental escolhido para construção do cliente e do servidor, a comunicação possa ser respeitada e padronizada entre ambos, sem o conhecimento das necessidades de implementação. Quando trabalhamos em interfaces, é importante também projetá-las para promover cada vez mais um desacoplamento entre sistemas.
Comunicação Stateless
No REST, cada requisição do cliente para o servidor deve conter todas as informações necessárias para entender e completar a requisição. O servidor não armazena nenhum estado da sessão do cliente. A comunicação stateless (sem estado) é um dos princípios que definem como os clientes e servidores interagem entre si. Esse princípio assegura que cada requisição de um cliente para um servidor deve conter todas as informações necessárias para o servidor compreender e responder à requisição. Em outras palavras, o servidor não armazena nenhum estado sobre o cliente entre as requisições. Cada uma delas é tratada como se fosse a primeira, sem qualquer conhecimento prévio ou memória das interações anteriores.
A natureza stateless também aumenta os níveis de confiabilidade do sistema. Se um servidor falhar após processar uma requisição, o cliente pode simplesmente tentar novamente, possivelmente usando outro node de pool de servidores de uma arquitetura distribuída. Como nenhuma informação de estado é mantida entre as requisições, não há perda de continuidade. Esse é um dos principios que garante a escalabilidade horizontal de aplicações REST em ambientes sensíveis em demanda de forma transparente.
Os desafios de uma arquitetura stateless giram principalmente em torno dos tópicos de autenticação. Usar tokens, como JWT (JSON Web Tokens) pode se tornar uma estratégia recomendada, pois os mesmos podem conter informações comuns do cliente que efetua a solicitação junto com meios de validar a integridade e validade dos mesmos sem a nacessidade de manter histórico entre as requisições.
Camadas
A arquitetura em camadas permite que intermediários (como proxies e gateways) facilitem ou melhorem a comunicação entre o cliente e o servidor de forma transparente, promovendo a segurança, o balanceamento de carga e a capacidade de cache. Combinando o conceito de viabilidade de camadas com o padrão stateless, o servidor se torna muito poderoso e escalável.
O princípio de camadas, ou “Layered System”, é uma das restrições arquiteturais mais importantes do REST, pois influencia o design de sistemas distribuídos sensíveis a escala constante, especialmente APIs RESTful. Este princípio estabelece que a arquitetura de uma aplicação deve ser organizada em camadas hierárquicas, cada uma com uma função específica. A comunicação ocorre sequencialmente de uma camada para outra, mas cada camada não precisa conhecer os detalhes das camadas internas ou externas a ela, apenas interagir com as camadas imediatamente adjacentes.
Entre essas camadas podem existir camadas de API gateways, camadas de autenticação e autorização, camadas de cacheamento das requisições e respostas, camadas de balanceadores de carga, camadas de proxy reversos, camada de roteamento, lógicas de negócios, acesso a dados e etc.
Cache
As respostas do servidor devem ser explícitas quanto à sua cacheabilidade para evitar a reutilização de dados obsoletos ou inapropriados, melhorando a eficiência e a escalabilidade. O cache é uma técnica amplamente utilizada no desenvolvimento de software, especialmente em aplicações web e APIs, incluindo aquelas que seguem o estilo arquitetônico REST (Representational State Transfer). O objetivo do cache é melhorar a eficiência e a performance da aplicação, armazenando cópias de recursos ou resultados de operações que são caros para gerar ou buscar, permitindo que esses dados sejam reutilizados em requisições futuras.
No contexto de APIs REST, o cache pode ser implementado tanto no lado do cliente quanto no servidor, além de pontos intermediários na rede, como proxies e gateways de API. Isso ajuda a reduzir a latência, diminuir a carga no servidor e melhorar a experiência geral do usuário ao acessar a aplicação
A dinamica do cache em transações HTTP e API’s RESTful depende de um gerenciamento cuidadoso para garantir que os dados armazenados sejam precisos, úteis e atualizados. Cabeçalhos HTTP, como Cache-Control, Last-Modified, e ETag, são utilizados para controlar o comportamento do cache, incluindo a validade, revalidação e a expiração do cache desses recursos.
Webhooks
Os Webhooks são recursos arquiteturais em que sua implementação se baseia em enviar dados para os clientes, ainda de forma sincrona, conforme determinadas ações acontecerem dentro do sistema. Ao contrário de uma API cliente-servidor em que o cliente notifica o servidor para tomar ações e lidar com determinados dados, os webhooks cumprem o papel inverso, onde através de URL’s previamente informadas, o sistema servidor envia notificações para os clientes sempre que algum dado for modificado, status atualizado ou determinada ação seja necessária da parte dele.
Em cenários onde os clientes precisam de atualizações contínuas sobre o estado de um recurso de interesse no servidor, o polling HTTP síncrono, baseado em solicitações periódicas, aumenta a carga no servidor e no cliente, muitas vezes resultando em atrasos na detecção de mudanças e no desperdício de recursos com requisições desnecessárias. Esse é o principal problema que a implementação de sistemas de webhooks resolvem.
Pooling e a Diferença entre Webhooks e API’s
Para explicar a diferença entre entre o pooling de API’s e Webhooks vamos propor um modelo lúdico: Imagine que você comprou um livro novo em algum e-commerce. Você fez as devidas solicitações, pagamentos e confirmações necessárias para isso e agora precisa esperar o produto ficar pronto. Você está bem ansioso pra chegada desse novo material, e de tempos em tempos você vai até sua caixa de correios para verificar se sua encomenda está lá. Esse modelo é diretamente associado ao padrão de comunicação sincrona, onde a partir do momento em que você espera manter o cliente atualizado com os estados observados do servidor, ele precisa de tempos em tempos checar o recurso através de requisições periódicas até recuperar o estado das informações necessárias.
Agora imagine que você está esperando essa encomenda, mas ao invés de um sistema de caixa de correios a abordagem utilizada é a de um entregador que precisa da sua assinatura e confirmação de recebimento para te entregar o seu pacote. Você pode continuar com todas as suas tarefas normalmente até sua campainha tocar, e receber o seu pacote em mãos, assinando e confirmando o recebimento. Esse é um modelo que pode exemplificar o funcionamento de Webhooks comparado ao pooling de API’s.
Imagine que você possui um e-commerce usa os métodos de pagamento de uma empresa parceira. Essa empresa oferece várias formas de pagamento para você oferecer aos seus clientes em suas compras, como Pix, Cartão de Crédito, Boleto e etc. Imagine que um código Pix é gerado, e você precisa ficar chegando de tempos em tempos na API desse parceiro se o pagamento foi o não concluído para dar sequencia ao processo de compra do cliente. Esse modelo é o pooling não recomendado.
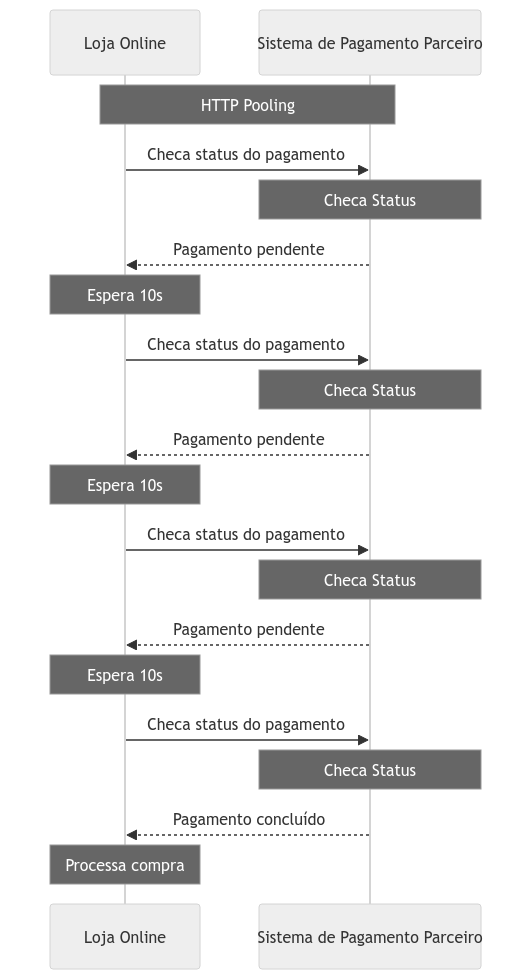
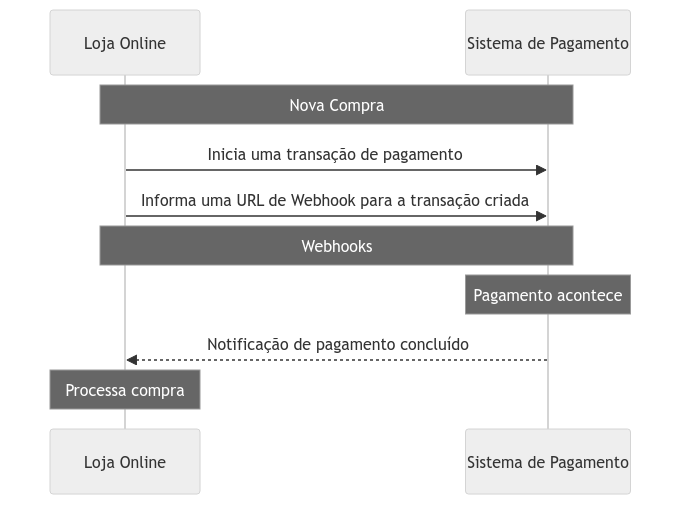
Agora imagine que junto as informações de pagamento, você fornece ao seu parceiro uma URL do seu sistema, onde ele poderá enviar uma requisição com os dados dessa solicitação sempre que houver uma atualização do lado do sistema dele, como por exemplo informando se o processo de pagamento foi concluído, cancelado, expirado ou recusado, evitando que você fique consultando o mesmo de forma desnecessária.
RPC - Remote Procedure Call
O RPC (Remote Procedure Call) é um protocolo utilizado para executar chamadas de procedimento ou métodos em um sistema computacional diferente daquele em que o código está sendo executado. Este protocolo permite que um programa em um dispositivo cliente envie uma solicitação de execução de procedimento para um software em outro dispositivo servidor, que executa o procedimento e retorna o resultado. O RPC abstrai a complexidade da comunicação em rede, permitindo aos desenvolvedores se concentrarem na lógica de negócios, em vez dos detalhes de como os dados são transmitidos e recebidos. Existem vários tipos de protocolos RPC como por exemplo o SOAP, Thrift, CORBA entre outros. Mais a frente, iremos abordar uma alternativa moderna desse tipo de protocolo, o gRPC.
Exemplo de um Servidor RPC
Ao contrário do gRPC que veremos a seguir, chamadas RPC convencionais não precisam necessariamente de um contrato forte, o que pode ser bom no caso de flexibilidade e velocidade de implementação quanto ruim para manter um padrão e consistência dos dados. Nesse exemplo vamos implementar uma chamada para um sistema que calcula a quantidade de ingestão diária de proteína recomendada baseada no peso informado.
A implementação se baseia apenas em criar um método e registrá-lo em um rpc server alocado em uma porta do host, no caso do exemplo, a porta 1234.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
package main
import (
"fmt"
"net"
"net/rpc"
)
type Args struct {
Peso float64
}
// Calculo de Recomendação de Consumo de Proteínas
// Baseado no peso informado
type Proteinas float64
func (p *Proteinas) Recomendacao(args Args, reply *float64) error {
// Calcula o o consumo de proteina recomendado e devolve para o objeto de resposta
*reply = args.Peso * 2
return nil
}
func main() {
// Registrando o serviço RPC na porta 1234
proteina := new(Proteinas)
rpc.Register(proteina)
ln, err := net.Listen("tcp", ":1234")
if err != nil {
fmt.Println("Falha ao ouvir na porta:", err)
return
}
for {
conn, err := ln.Accept()
if err != nil {
fmt.Println("Falha ao aceitar a conexão.:", err)
continue
}
// Servindo a rotina RPC
go rpc.ServeConn(conn)
}
}
Exemplo de um Client RPC
A implementação de um cliente tende a ser bem mais simples. Basta criar uma conexão com a porta onde o servidor e o método RPC foi alocado, informando uma lista de argumentos do formato esperado do lado do servidor. Como ele não exige um contrato forte, os prós e contras tendem a ser os mesmos informados anteriormente, velocidade e flexibilidade em troca de consistência.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
package main
import (
"fmt"
"net/rpc"
)
type Args struct {
Peso float64
}
func main() {
client, err := rpc.Dial("tcp", "0.0.0.0:1234")
if err != nil {
fmt.Println("Falha ao conectar:", err)
return
}
var reply float64
args := Args{Peso: 85.00}
fmt.Println("Iniciando a chamada RPC para o serviço Proteinas.Recomendacao")
err = client.Call("Proteinas.Recomendacao", args, &reply)
if err != nil {
fmt.Println("Erro na chamada:", err)
return
}
fmt.Printf("O consumo de proteínas adequado para o peso de %v kg é de %vg por dia\n", args.Peso, reply)
}
1
2
Iniciando a chamada RPC para o serviço Proteinas.Recomendacao
O consumo de proteínas adequado para o peso de 85 kg é de 170g por dia
gRPC - Google Remote Procedure Call
O gRPC é um framework de chamada de procedimento remoto (RPC) de código aberto desenvolvido pelo Google. Ele permite que os desenvolvedores conectem serviços de maneira performática e escalável, possibilitando a comunicação entre serviços construídos de maneira distribuída. Seu design baseia-se no uso de HTTP/2 como protocolo de transporte, Protocol Buffers (ProtoBuf) como linguagem de interface de descrição de serviço (IDL), e além do conceito das chamadas RPC que já abordamos, ele oferece recursos como autenticação, balanceamento de carga e validações. Essa arquitetura é ideal para construir arquiteturas de microserviços, onde serviços leves e performáticos são críticos para o desempenho e a escalabilidade.
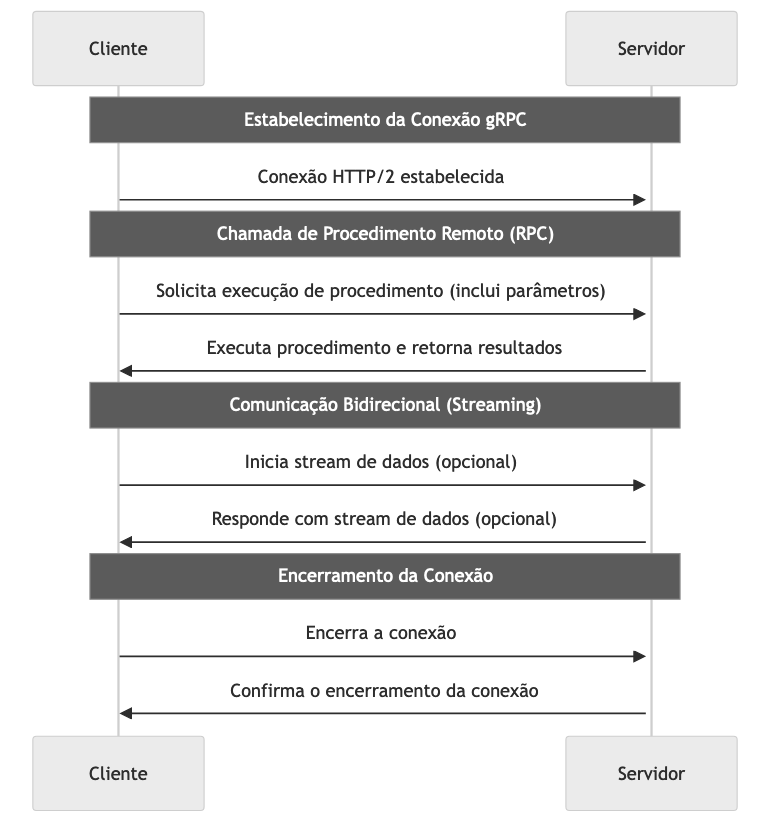
Com o HTTP/2, é possível fazer múltiplas chamadas RPC em paralelo sobre uma única conexão TCP, o que é uma grande melhoria em termos de eficiência de rede e latência.
O gRPC suporta streaming bidirecional, permitindo que tanto o cliente quanto o servidor enviem uma sequência de mensagens para o outro usando uma única conexão. Isso é particularmente útil para casos de uso como chat em tempo real, monitoramento em tempo real e outros cenários que exigem comunicação contínua e persistente.
Implementar e gerenciar um sistema baseado em gRPC pode ser mais complexo do que usar alternativas mais simples como REST, especialmente em projetos menores ou com requisitos menos rigorosos de desempenho. A característica de se utilizar contratos por ProtoBuf para manter um contrato de consistência, encontra-se a necessidade de distribuir e versionar esse contrato entre o cliente e o servidor. Uma vez que esse contrato precise ser mudado para adicionar, modificar ou remover alguma variável do mesmo, pode existir a problemática de garantir a atualização de todos os clientes desse serviço.
ProtoBufs
O Protocol Buffers, ou ProtoBuf, é a linguagem de descrição de interface preferida pelo gRPC, é usada para definir os serviços e a estrutura de dados que serão compartilhados entre cliente e servidor por meio de um contrato forte. ProtoBuf é um sistema de serialização binária que não só é mais eficiente em termos de espaço do que formatos como JSON, mas também fornece uma maneira clara de especificar a interface do serviço de maneira agnóstica a linguagens e frameworks.
Exemplo de Protobuf
Nesse contrato de exemplo escrevemos a assinatura/contrato de comunicação gRPC que deverá acontecer via client-server utilizando a sintaxe proto3. Descrevemos o service chamado IMCService que implementa um método chamado Calcular, que recebe um objeto de mensagem no padrão descrito no IMCRequest e retorna uma mensagem no padrão descrito no IMCResponse. A linguagem superficialmente é descritiva e bem simples.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
syntax = "proto3";
package imc;
option go_package = "service/imc";
// O serviço IMCService oferece a operação de calcular o quadrado de um número.
service IMCService {
// IMC calcula o quadrado de um número.
rpc Calcular (IMCRequest) returns (IMCResponse) {}
}
// IMCRequest contém o a altura e peso para o qual queremos calcular o IMC.
message IMCRequest {
double weight = 1;
double height = 2;
}
// IMCResponse contém o resultado do cálculo do IMC informado.
message IMCResponse {
double result = 1;
}
Após descrever o contrato, precisamos gerar os pacotes .go que implementam esse contrato. Para gerar esses pacotes normalmente usamos o pacote protoc. Quando estamos gerando esses arquivos em golang, dois pacotes devem ser gerados no padrão imc_grpc.pb.go e imc.pb.go. Esses pacotes precisam ser implementados tanto no client quanto no server.
1
protoc --go_out=. --go-grpc_out=. imc.proto
Exemplo de Server gRPC
Tendo os contratos criados pelo protobuf importados, podemos iniciar a implementação de um gRPC Server de forma simplificada. Precisamos respeitar os contratos definidos, implementando um método chamado Calcular que recebe e responde os objetos com a assinatura definida. Após implementar as funções necessárias com as lógicas do serviço, só precisamos alocar uma porta, no caso, 50051 e registrar esse serviço no servidor gRPC.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
package main
import (
"context"
"fmt"
imc "main/service/imc"
"math"
"net"
"google.golang.org/grpc"
)
// Cria um servico baseado no protobuf informado
type service struct {
imc.IMCServiceServer
}
// Método utilizado para calcular o IMC com a altura e peso informados
func (s *service) Calcular(ctx context.Context, in *imc.IMCRequest) (*imc.IMCResponse, error) {
fmt.Println("Iniciando Calculo")
result := (in.Weight / (in.Height * in.Height)) * 1
result = math.Round(result*100) / 100
return &imc.IMCResponse{Result: float64(result)}, nil
}
func main() {
// Alocando a porta 50051 para o servidor
lis, err := net.Listen("tcp", ":50051")
if err != nil {
fmt.Println("Falha ao servir na porta 50051:", err)
return
}
// Instancia um servidor gRPC
s := grpc.NewServer()
// Registra o serviço de calculo no servidor gRPC
fmt.Println("Registrando o serviço de Calculo de IMC no server gRPC")
imc.RegisterIMCServiceServer(s, &service{})
// Instancia o servidor na porta alocada
if err := s.Serve(lis); err != nil {
fmt.Println("Falha criar o servidor gRPC:", err)
return
}
}
Exemplo de Client gRPC
Para implementar o client de um server gRPC, precisamos utilizar o mesmo contrato, criar uma conexão persistente com o endereço/porta do servidor e chamar a o método definido na assinatura Calcular, informando os dados no formato acordado, e recebendo a resposta em seguida.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
package main
import (
"context"
"log"
"time"
imc "main/service/imc"
"google.golang.org/grpc"
)
func main() {
conn, err := grpc.Dial("0.0.0.0:50051", grpc.WithInsecure(), grpc.WithBlock())
if err != nil {
log.Fatalf("Falha ao conectar ao servidor gRPC: %v", err)
}
defer conn.Close()
client := imc.NewIMCServiceClient(conn)
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
defer cancel()
// Executa uma chamada gRPC para o servidor calcular o IMC
peso := 90.5
altura := 1.77
r, err := client.Calcular(ctx, &imc.IMCRequest{
Weight: peso,
Height: altura,
})
if err != nil {
log.Fatalf("Falha ao executar a chamada: %v", err)
}
fmt.Sprintf("O IMC de uma pessoa com %v de peso e %v de altura é de: %v\n", peso, altura, r.GetResult())
}
1
2
Registrando o serviço de Calculo de IMC no server gRPC
Iniciando Calculo...
1
2
❯ go run main.go
2024/03/17 20:18:55 O IMC de uma pessoa com 90.5 de peso e 1.77 de altura é de: 28.89
Websockets
Uma comunicação baseada em Websockets são uma alternativa para solucionar problemas de comunicação em tempo real entre clientes e servidores em tecnologias de desenvolvimento web. Diferentemente do modelo tradicional de requisição e resposta HTTP, que é unidirecional e cria uma nova conexão TCP para cada requisição/resposta, o protocolo WebSocket estabelece uma conexão full-duplex sobre um único socket TCP. Isso permite uma comunicação bidirecional contínua entre o cliente e o servidor, ideal para aplicações web que necessitem de interações em tempo real de atualizações frequentes e instantâneas, como chats online, dashboards dinâmicos, graficos de dados financeiros, sistemas de notificações e jogos online.
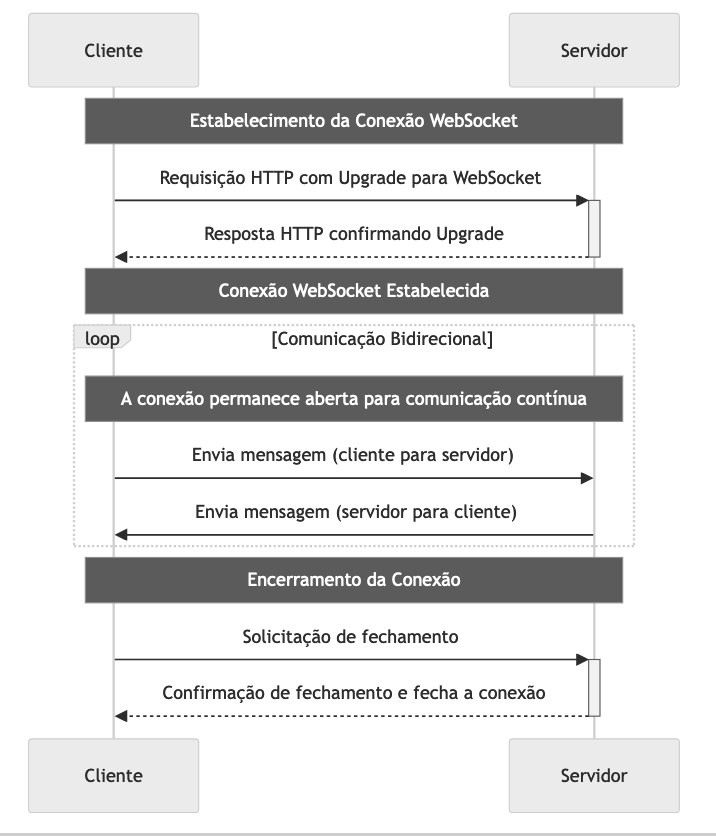
A conexão WebSocket inicia-se como uma requisição HTTP padrão, mas solicita um “upgrade” para WebSockets através do cabeçalho Upgrade. Se o servidor suporta WebSockets, ele responde com uma confirmação do “upgrade” e a conexão HTTP é então elevada a uma conexão WebSocket. Uma vez estabelecida, a conexão WebSocket permanece aberta, permitindo que tanto o cliente quanto o servidor enviem dados a qualquer momento até que a conexão seja fechada por uma das partes. Ao manter uma conexão aberta, WebSockets eliminam a necessidade de estabelecer novas conexões HTTP para cada interação, reduzindo significativamente a latência.
Qualquer uma das partes (cliente ou servidor) pode iniciar o fechamento da conexão WebSocket. A parte que deseja fechar a conexão envia uma solicitação de fechamento, e após a outra parte responder, a conexão é fechada.
Embora a maioria dos navegadores modernos suporte WebSockets, pode haver problemas de compatibilidade com navegadores mais antigos ou em ambientes de rede restritivos que não permitem conexões WebSocket. Além de que gerenciar uma conexão WebSocket persistente e garantir a retransmissão de mensagens perdidas pode ser mais complexo do que usar requisições HTTP simples.
GraphQL
O GraphQL pode ser visto tanto como uma linguagem de consulta para APIs do lado do cliente, quanto como um runtime para execução dessas consultas pelo lado do servidor. Desenvolvido pelo Facebook, o GraphQL oferece uma abordagem diferente para o desenvolvimento de APIs em comparação com a abordagem tradicional REST. Ele permite que os clientes definam a estrutura dos dados que desejam receber, e exatamente esses dados, nada mais, nada menos, são retornados como resposta. Isso não só torna as consultas mais objetivas, mas também resolve o problema de sobrecarga e subutilização de dados frequentemente encontrado em APIs REST. Esse problema em questão, pode ser encontrado em API’s REST que possuam payloads muito grandes, onde o cliente por exemplo, não faz uso de todos os campos. Esse problema em questão de trafegar e lidar com mais dados do que o necessário é conhecido como “ever-fetching”, e seguindo a mesma lógica, se o cliente não tem todos os dados necessários de forma objetiva, e precisa consultar outros vários recursos para compor todas as informações necessárias para prosseguir com seu objetivo é um problema conhecido como “under-fetching”.
Diminuindo a complexidade de lidar com “under-fetching” e “over-fetching” através de um único ponto de consulta, ao invés de ter que implementar vários endpoints para lidar com vários tipos de demanda na API REST, é um cenário em que vale a pena levar em consideração o uso do GraphQL. Porém a falta de padrões pode se tornar um grande problema como consequencia da adoção desse tipo de abordagem.
Componentes do GraphQL
O GraphQL é construído sobre alguns conceitos que precisam ser compreendidos para garantir uma implementação adequada que faça sentido, sendo eles:
Schema
Um schema é definido através da linguagem SDL (Schema Definition Language), que é uma sintaxe simples para definicão de estruturas de dados e é a particularidade mais importante do GraphQL, sendo compartilhado e acessado entre todos os outros componentes. Um schema funciona como um contrato entre o cliente e o servidor e define e limita dos dados que podem ser consultados e modificados através do que for disponibilizado, e principalmente a forma como os clientes podem interagir com esses dados.
O grande motivador da tecnologia é reduzir o over-fetching e under-fetching, pois permite que os clientes solicitem exatamente os dados de que precisam sem a necessidade de lidar com payloads gigantescos.
Um schema é construído para que seja possível definir quais serão as entidades, objetos e suas relações entre si, quais serão seus campos e seus tipos de dados dos mesmos, além de habilitar quais serão as queries, mutations e subscriptions disponibilizadas para o cliente.
Query
Uma Query é um request de aplicação feito pelo cliente do GraphQL usada para ler e recuperar valores do servidor. Essa operação de query precisa respeitar os valores definidos no schema, podendo escolher quais deles ele quer recurperar e definir o formato do payload ideal para responder a solicitação em questão.
Mutations
Enquanto as queries são usadas para buscar dados, as mutations são utilizadas para modificar dados no servidor, incluindo criação, atualização, e deleção de dados. As mutations no GraphQL são explicitamente feitas para operações que causam efeitos colaterais, podendo também escrever em várias fontes de dados se assim for definido no schema e suas integrações.
Resolvers e Data Sources
Como podemos entender, o GraphQL não é de fato um banco de dados, apenas uma interface flexível entre o cliente e as fontes disponíveis, e ele pode recuperar dados de várias fontes de dados simultâneamente, incluindo bancos SQL, NoSQL, API’s REST e servicos RPC se assim for definido, e os resolvers são funções que fornecem as instruções e integrações necessárias para transformar uma operação do GraphQL em dados reais de fato.
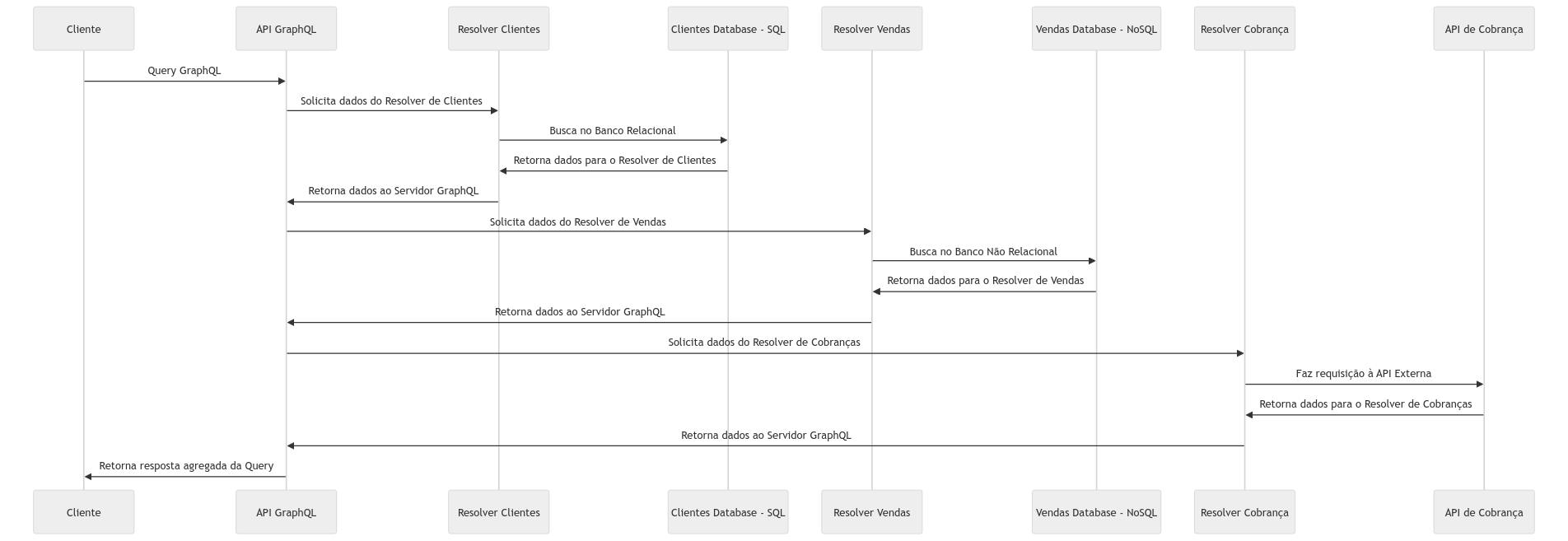
Exemplo da utilização de vários resolvers dentro de uma query
Os resolver são responsáveis em buscar esses dados em suas fontes originais. Cada campo que é definido e configurado dentro de um schema é diretamente associado a um resolver, que é estimulado sempre que aquele campo é solicitado.
Convergência de Arquiteturas gRPC & REST & GraphQL
Expor diretamente endpoints gRPC para clientes em escala pode ser uma tarefa trabalhosa, principalmente em arquiteturas corporativas de grande granularidade. Nesse sentido, se olharmos nossa arquitetura com uma ótica de domínios de software, podemos fazer uso de uma convergência de mais de um protocolo de comunicação dentro de uma malha de serviços.
Uma vez que o problema de distribuir e versionar arquivos de protobufs são uma tarefa complicada, e os contrato REST são mais simples de ser interpretados, podemos pensar em acordos onde o domínio de software pode ser exposto dentro de um contrato REST e a comunicação interna entre os microserviços desse domínio possam falar um protocolo mais leve em comunicação como o gRPC. Essa tarefa pode ser extendida para instâncias de GraphQL da mesma forma.
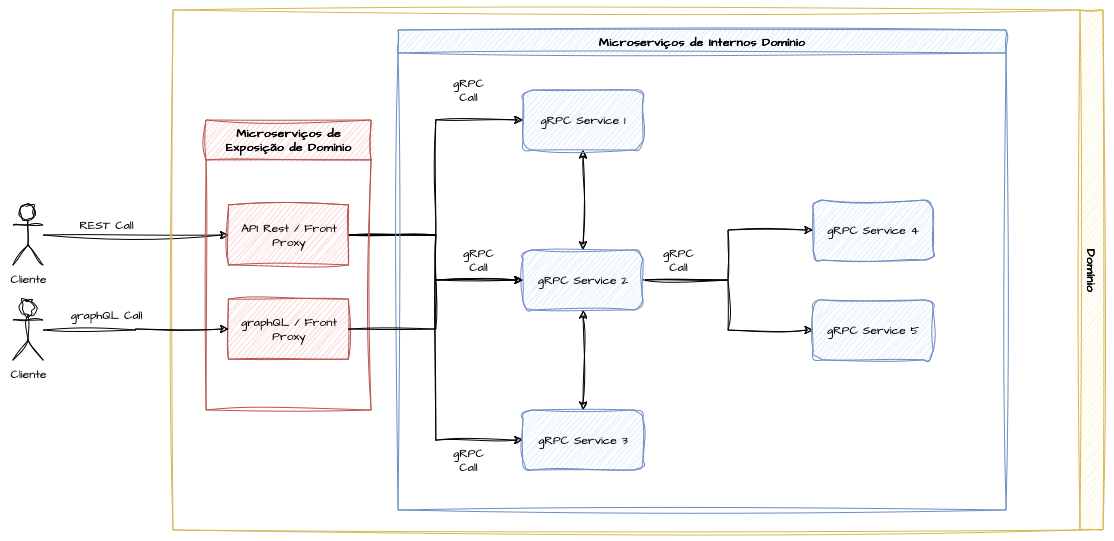
Revisores
Referências
Qual é a diferença entre gRPC e REST?
Integration challenges in microservices architecture with gRPC & REST
REST vs. GraphQL vs. gRPC vs. WebSocket
Protocol Buffers - Google’s data interchange format
Demo: Nutrition Overengineering
REST Architectural Constraints
