
System Design - Replicação de Dados

Neste capítulo da nossa série de System Design, vamos explorar os conceitos de escalabilidade de aplicações críticas, com foco especial na replicação de dados. Este tema está diretamente relacionado ao capítulo anterior sobre Sharding e Particionamento de Dados, já que esses conceitos costumam ser usados em conjunto em diversas abordagens arquiteturais. Nosso objetivo é apresentar diferentes padrões e estratégias de replicação, demonstrando como esses conceitos podem melhorar a disponibilidade, a confiabilidade e a performance de sistemas distribuídos.
Definindo Replicação na Engenharia de Software
Imagine as chaves do seu carro ou da sua casa. Agora, imagine que exista apenas uma cópia delas e que você as carregue o dia todo, acompanhando você na academia, supermercado, trabalho, restaurantes, aniversários, festas, cinema e outros lugares. Agora, imagine que, infelizmente, você tenha perdido essas chaves em algum desses lugares e só percebeu quando precisou delas. O que aconteceria? Você ficaria trancado fora do carro ou de casa, causando um grande problema. Quando pensamos em replicação de dados, é exatamente esse tipo de problema que queremos evitar. Agora, imagine que você tenha cópias de reserva distribuídas com diferentes pessoas, como parceiro(a), pai, mãe ou amigos próximos, ou até mesmo escondidas em locais estratégicos, como debaixo do tapete da garagem ou dentro de um vaso de plantas. Essa é uma analogia para o tipo de estratégia que usamos para lidar com replicação.
Nas disciplinas que compõem a engenharia de software, a replicação se refere ao ato de criar uma ou mais cópias do mesmo dado em locais diferentes. Essa é uma prática recomendada especialmente em sistemas onde a consistência, a disponibilidade e a tolerância a falhas são requisitos mandatórios para o ciclo de vida do produto.
Essas réplicas podem estar localizadas em servidores ou nós distintos, datacenters separados geograficamente ou até mesmo em diferentes regiões de nuvens públicas. O objetivo principal da replicação é garantir que os dados estejam disponíveis em vários locais, o que é essencial para sistemas que exigem alta disponibilidade. Quando falamos de Bancos de Dados, a replicação permite que, mesmo em caso de falhas críticas de hardware ou problemas de rede, os dados continuem acessíveis em outros locais. Ela também garante que o sistema se torne consistente em algum momento, dependendo apenas do tempo necessário para que uma réplica se torne a nova fonte principal de dados.
Em resumo, o objetivo das estratégias de replicação é garantir que os mesmos dados estejam disponíveis em vários locais, permitindo que o sistema continue operando mesmo que uma parte dele falhe.
Modelos de Replicação
Antes de abordarmos as estratégias de replicação, é importante entender alguns modelos pelos quais os sistemas de replicação são construídos. Independentemente da estratégia adotada para garantir a existência de várias cópias do mesmo dado em diferentes locais ou nós, o modelo de replicação geralmente segue um dos dois principais tipos: Primary-Replica ou Primary-Primary, também conhecido como Multi-Master. Vamos entender conceitualmente essas duas abordagens para estabelecer uma base antes de falarmos sobre as implementações práticas.
Replicação Primary-Replica
Na Replicação Primary-Replica, é proposto que um nó primário receba todas as operações de escrita e, em seguida, replique essas operações para um ou mais nós secundários. Esses nós são as denominadas réplicas. As réplicas geralmente são usadas apenas para leitura, enquanto todas as operações de escrita são gerenciadas exclusivamente pelo nó primário desse sistema. Essa arquitetura é útil quando fazemos uso de leituras intensivas, pois nos permite criar uma distribuição de carga entre as réplicas, mas mantendo a simplicidade nas escritas.
Em resumo, nesse tipo de modelo, o nó primário é responsável por garantir a consistência dos dados em todas as réplicas. Essa abordagem é muito bem aceita em cenários de leitura intensiva ou em sistemas que utilizam intensivamente CQRS para criar modelos de leitura otimizados, mas, em contrapartida, cria um ponto único de falha a partir do nó primário. Se esse componente primário falhar, uma das réplicas precisará ser promovida a novo nó primário, o que pode causar um tempo de inatividade e erros até que esse processo seja concluído por completo. O tempo para conclusão varia de acordo com a implementação utilizada e, em muitos casos, pode exigir engenharia manual.
Replicação Primary-Primary - Multi-Master
A Replicação Primary-Primary, também conhecida como Multi-Master Replication, é uma arquitetura em que múltiplos nós podem atuar simultaneamente como primários, recebendo tanto operações de leitura quanto de escrita. Nessa configuração, qualquer nó pode processar atualizações, e as mudanças são replicadas entre todos os nós, permitindo alta disponibilidade e escalabilidade de escrita.
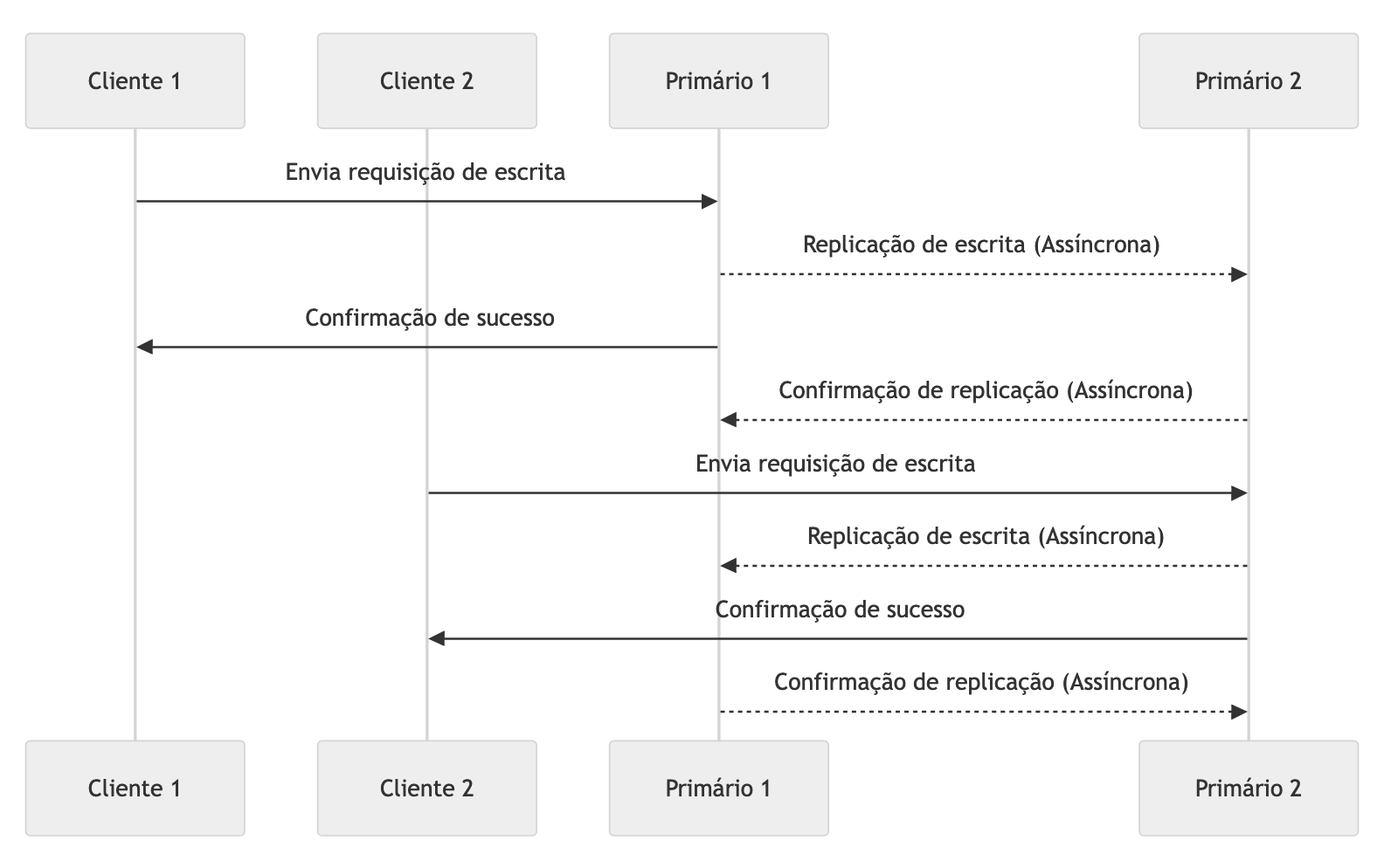
Esse modelo elimina o ponto único de falha presente na replicação Primary-Replica e permite maior flexibilidade na distribuição da carga de trabalho. No entanto, ele também introduz complexidade adicional, especialmente para resolver conflitos de escrita. Quando duas operações de escrita ocorrem em diferentes nós primários simultaneamente, o sistema precisa de uma estratégia para resolver esses conflitos, como o uso de timestamps para ordenar as operações ou a definição de políticas específicas de resolução de conflitos em casos de particionamento temporário por falha de rede.
Estratégias de Replicação
Nas disciplinas de engenharia que vimos até agora, não somente neste texto, encontramos várias estratégias onde a replicação pode auxiliar em conjunto com outras abordagens, principalmente quando estamos olhando para dados — que geralmente são o foco dessas abordagens devido à sua importância e complexidade — quanto para outras áreas menos convencionais, como replicação de cargas de trabalho completas, domínios de software em cache, entre outros. O objetivo deste capítulo é exemplificar alguns dos modelos de replicação mais utilizados e explicar suas diferenças, vantagens e desvantagens para que fique clara a aplicabilidade de cada cenário, e auxilie nas decisões de arquitetura e engenharia.
Replicação Total e Parcial
A Replicação Total se refere à prática de replicar todos os dados em todos os nós de um sistema. Isso significa que cada nó possui uma cópia completa de todos os dados. A vantagem dessa abordagem é que ela adiciona vários níveis de disponibilidade, permitindo que qualquer nó atenda a uma solicitação do cliente a qualquer momento, desde que as operações de escrita sejam deliberadamente permitidas. No entanto, como contraponto, essa estratégia pode aumentar os custos de armazenamento e a latência das escritas, já que cada novo registro ou versão do dado precisa ser replicado e confirmado em todos os nós que compõem o cluster do sistema em questão. Esse modelo também é conhecido como Full-Table Replication em abordagens acadêmicas.
Por outro lado, a Replicação Parcial distribui apenas uma parte dos dados para cada nó. Assim, cada nó contém apenas uma fração dos dados totais. Esse modelo é mais eficiente em termos de armazenamento e reduz a latência nas operações de escrita, mas aumenta a complexidade nas leituras, pois os dados solicitados podem não estar disponíveis localmente e podem exigir comunicação entre nós. Isso pode fazer com que o cliente precise consultar vários nós, ou que o sistema de consultas abstraia essa complexidade. Para localizar os dados entre os nós, é comum implementar algoritmos de Sharding, como o Hashing Consistente.
Replicação Síncrona
Na Replicação Síncrona, presume-se que todas as alterações nos dados devem ser replicadas em todos os nós antes que a operação seja considerada concluída para o solicitante. Isso garante consistência forte entre os nós, pois um valor escrito ou atualizado só estará disponível para leitura após todos os nós confirmarem que escreveram o mesmo com sucesso, ou seja, todos eles responderão com os mesmos dados em qualquer momento, independentemente de qual deles receber a solicitação de leitura.
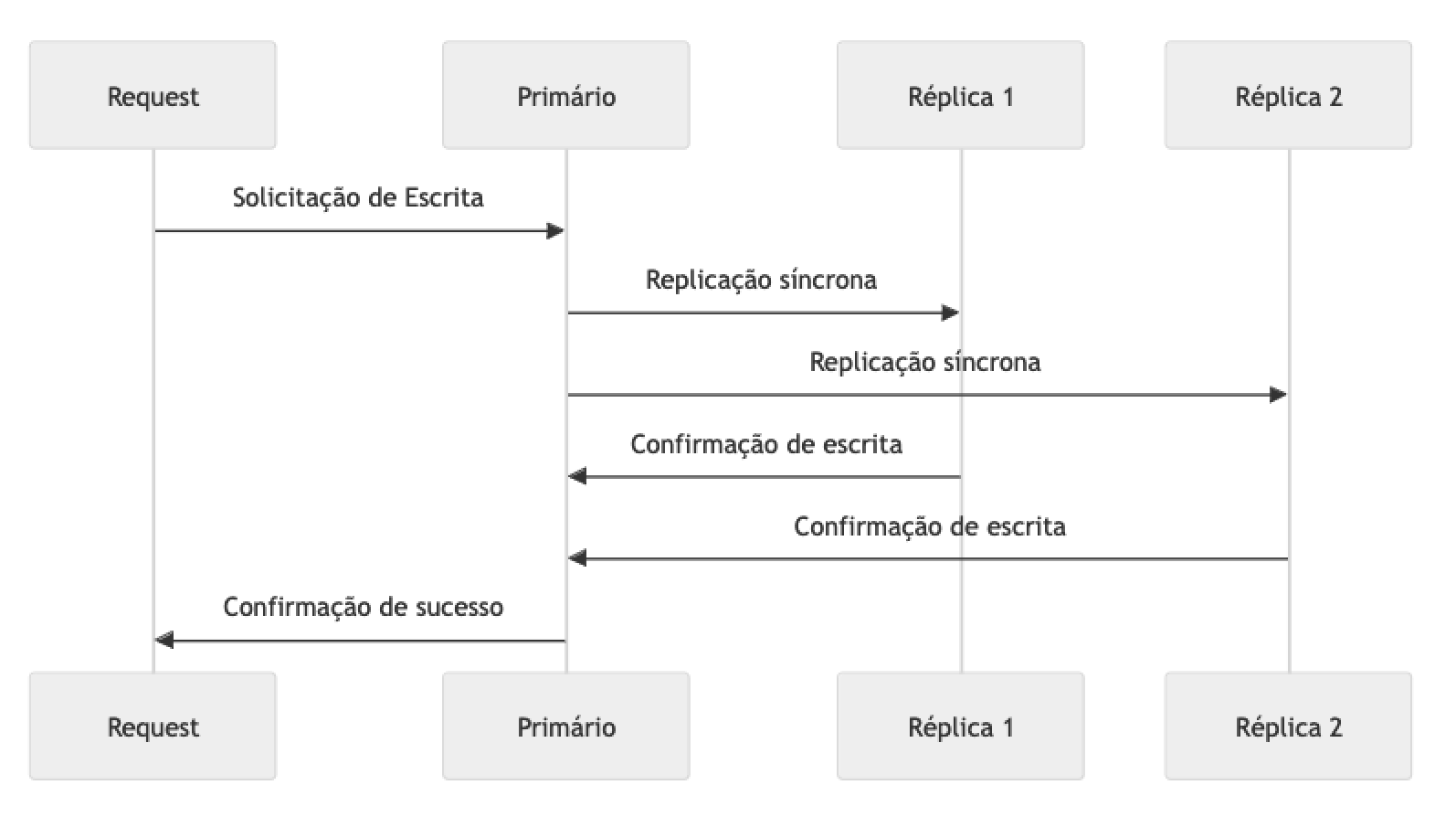
Em um cenário onde um cliente precisa salvar uma informação em um cluster que, por exemplo, oferece funcionalidades de cache, ele envia o dado, em formato de chave e valor, para o endpoint primário do cluster como de costume. Esse endpoint é responsável por distribuir o dado entre todos os nós do cluster. A solicitação só é finalizada e confirmada ao cliente quando essa operação é concluída por completo, ou seja, todos os nós responderam “ok” para a solicitação de salvar o dado. Uma técnica comum para implementação de replicação síncrona é o two-phase commit.
A replicação síncrona tem vantagens em cenários onde a consistência é crítica, como em sistemas de pagamento ou bancos de dados financeiros, onde qualquer discrepância entre os nós pode causar grandes problemas. No entanto, essa abordagem pode aumentar a latência, especialmente quando os nós estão distribuídos geograficamente ou em grande quantidade.
Replicação Assíncrona
Na Replicação Assíncrona, as alterações de dados são enviadas a um dos nós de um cluster e replicadas para os outros nós de forma eventual, o que significa que a operação pode ser considerada bem-sucedida sem que todas as réplicas tenham sido atualizadas. Isso resulta em maior desempenho nas operações de escrita, pois o sistema não precisa esperar pelas confirmações de todos os nós. No entanto, podem ocorrer períodos de inconsistência ou consistência eventual nas consultas subsequentes, já que os dados podem não ter sido totalmente replicados nos demais nós, podendo existir diferentes versões do dado até que a replicação seja concluída.
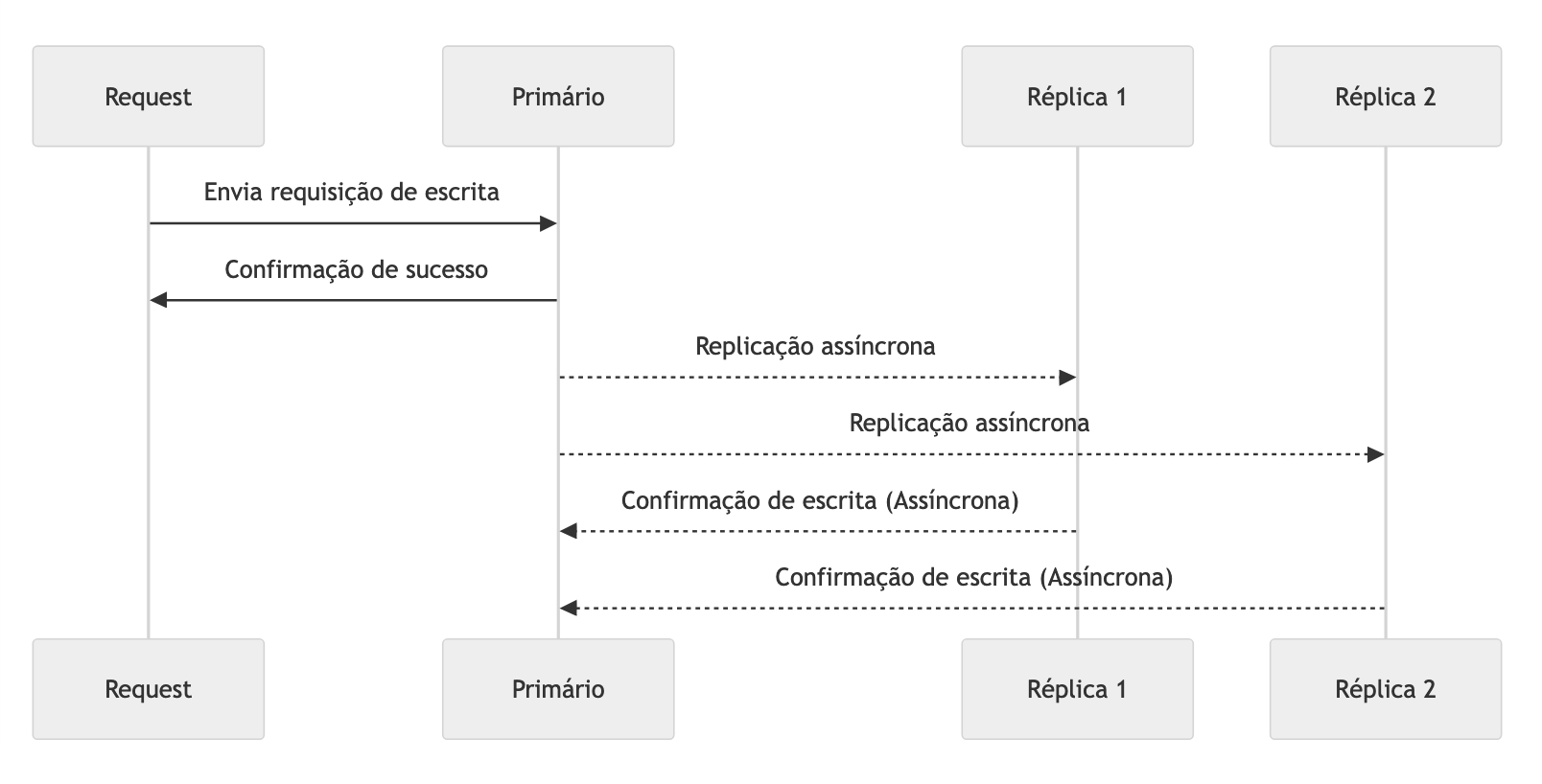
A replicação assíncrona é amplamente utilizada em cenários onde a disponibilidade e o desempenho são mais importantes do que a consistência imediata, como em redes sociais, assets em uma CDN, dados menos críticos usados para reduzir acessos a uma origem, clusters de cache e afins.
Replicação Semi-Síncrona
A Replicação Semi-Síncrona combina aspectos da replicação síncrona e assíncrona. Nesse modelo, pelo menos uma réplica, ou um pequeno subconjunto de réplicas, deve confirmar a gravação dos dados antes que a operação seja considerada bem-sucedida. As demais réplicas podem ser atualizadas de forma assíncrona.
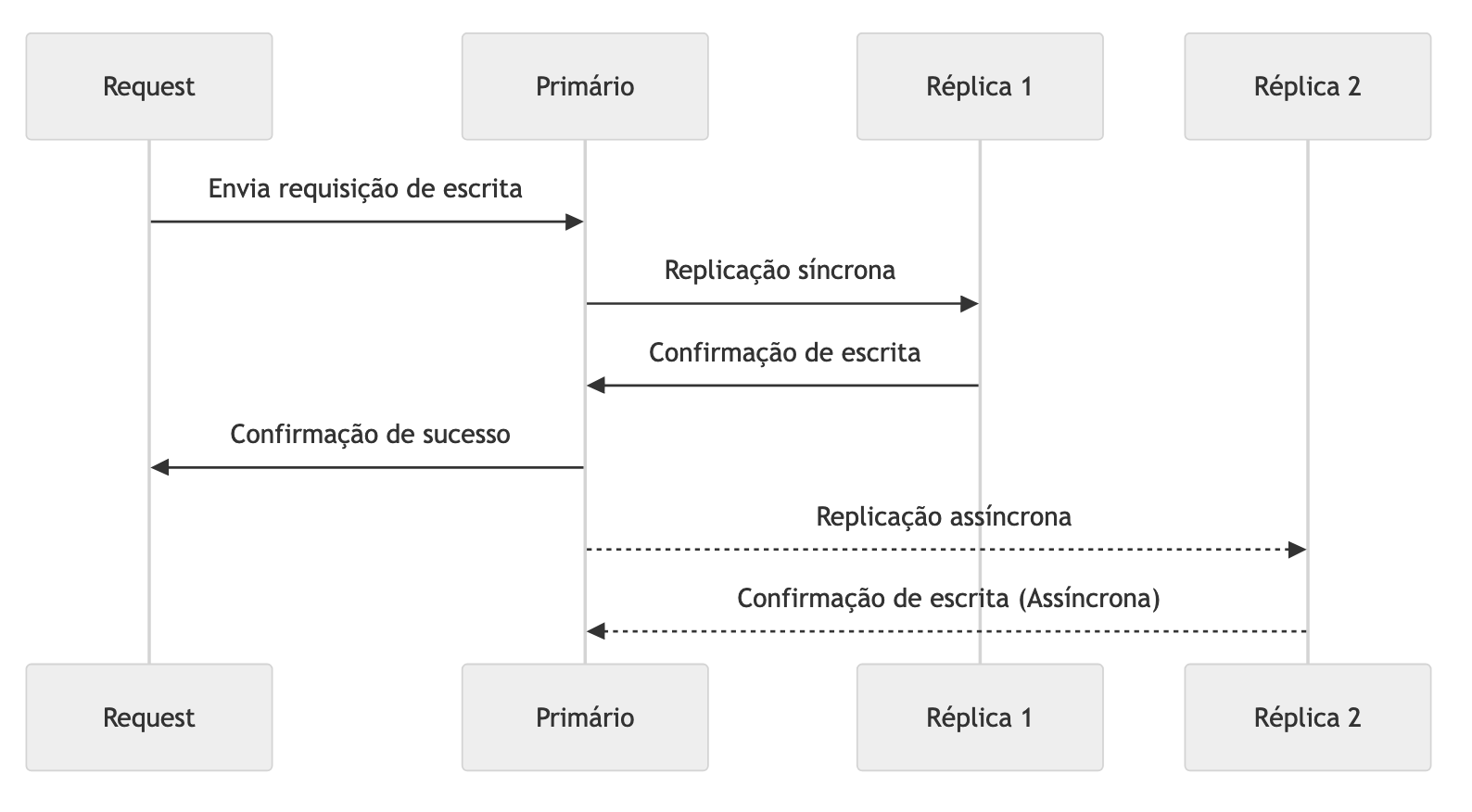
Esse tipo de replicação oferece um equilíbrio entre consistência e desempenho. Ele adiciona níveis extras de resiliência, garantindo que os dados sejam gravados em pelo menos um nó de forma síncrona, enquanto mantém baixa latência ao não exigir que todas as réplicas sejam atualizadas imediatamente. Em alguns bancos de dados, como MySQL e MariaDB, a operação de escrita é confirmada assim que um nó secundário grava os dados. Outros nós podem receber as atualizações posteriormente, de forma assíncrona, oferecendo um grau adicional de consistência sem comprometer totalmente a performance.
Replicação por Logs
A Replicação por Logs é uma abordagem em que todas as operações realizadas em um sistema são registradas em um log de operações sequenciais, e esse log é então replicado para outros nós do cluster, que executam as mesmas operações. Em vez de replicar o estado completo dos dados, o sistema replica as mudanças, permitindo que as réplicas apliquem essas alterações localmente e mantenham seus dados consistentes.
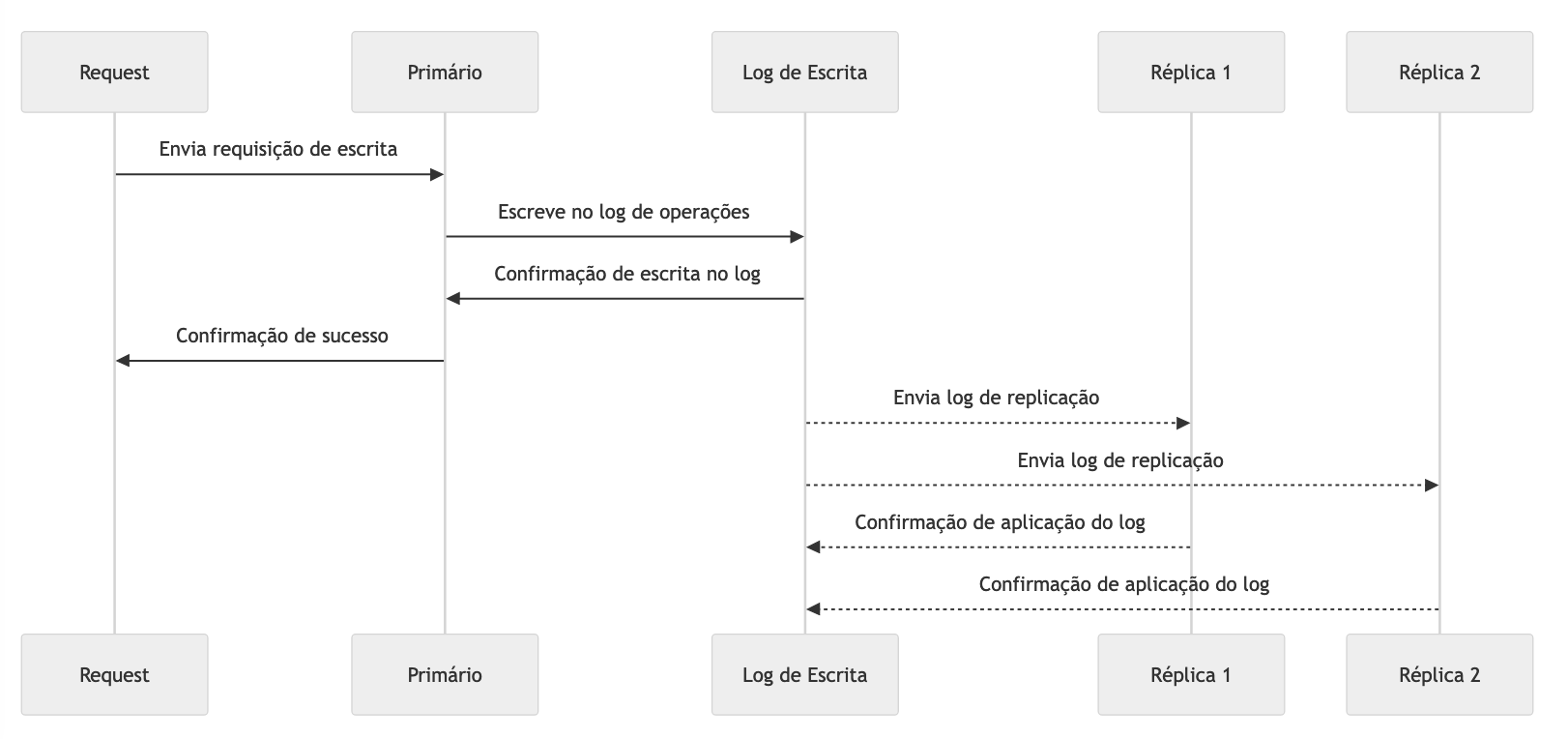
Essa abordagem é vantajosa em cenários onde as alterações são mais frequentes que as leituras ou onde o volume de dados é muito grande, pois apenas as modificações são replicadas, reduzindo a quantidade de dados trafegados entre os nós do cluster. Esse tipo de replicação é comum em tecnologias que permitem interoperabilidade entre múltiplas regiões de nuvens públicas, datacenters ou zonas de recuperação de desastres.
Tecnologias amplamente conhecidas e maduras, como o Apache Kafka e outras plataformas de streaming e eventos, utilizam replicação por logs em sua arquitetura de nós e réplicas. No Kafka, cada tópico é composto por múltiplas partições, e as alterações nessas partições são registradas em logs de transações que são replicados entre os brokers, garantindo durabilidade e resiliência.
A Replicação por Logs também é utilizada em algoritmos essenciais para sistemas distribuídos, como Paxos (utilizado em sistemas como BigTable e Apache Mesos), Raft (usado no etcd, ScyllaDB, Consul e CockroachDB) e Viewstamped Replication (usado no TigerBeetle), além de técnicas como o write-ahead log, que é utilizado para garantir a durabilidade de dados durante a replicação em caso de falhas em nós.
Arquitetura
As estratégias de replicação podem ser aplicadas manualmente na engenharia de software para resolver diversos desafios arquiteturais. Embora a replicação seja frequentemente associada a funcionalidades prontas, como em caches ou bancos de dados, é importante entender que, conceitualmente, ela pode ser usada de forma muito mais ampla. Quando adotada de maneira estratégica, a replicação permite escalar sistemas distribuídos de forma inteligente e eficiente. A seguir, exploraremos algumas abordagens arquiteturais que utilizam replicação, combinada com outras técnicas, para melhorar o desempenho e a escalabilidade de sistemas de grande porte.
Event-Carried State Transfer - Replicação de Estados e Objetos de Domínio
Em grandes sistemas, especialmente em arquiteturas corporativas complexas, uma solução eficaz para lidar com a alta disponibilidade de grandes volumes de dados é o Event-Carried State Transfer.
Esse padrão permite que o estado de um objeto seja transmitido entre serviços ou domínios de software por meio de eventos. Ele combina estratégias de cache, sistemas baseados em eventos e replicação de dados, proporcionando uma maneira custosa, porém poderosa, de lidar com grandes volumes de dados sem aumentar o nível de acoplamento.
A ideia central é que, sempre que houver uma atualização em uma entidade de um domínio, essa mudança seja publicada em tópicos de eventos. Os demais serviços que dependem desse domínio podem consumir esses eventos e atualizar suas próprias bases de dados locais, criando uma cópia em cache do estado. Isso é especialmente útil em sistemas que toleram consistência eventual, pois, em vez de consultar uma fonte centralizada a cada solicitação, os serviços mantêm e utilizam suas próprias versões dos dados, que são atualizadas conforme os eventos são processados. Em sistemas complexos e altamente distribuídos, a relação custo-benefício dessa abordagem pode se tornar viável.
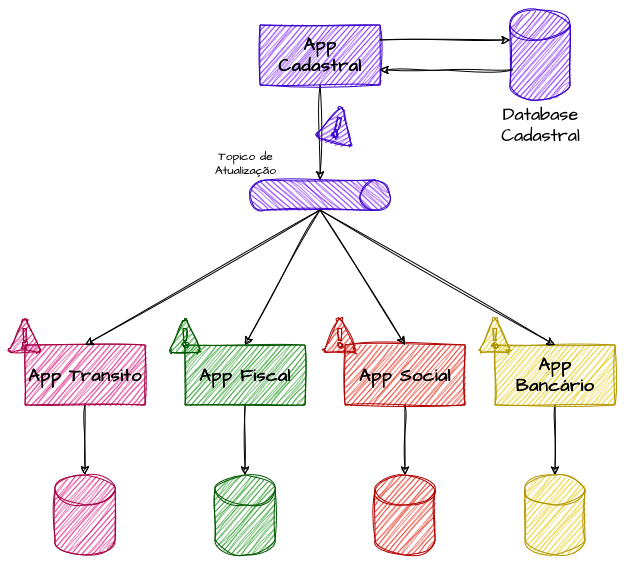
Imagine um sistema governamental que compartilha os dados dos cidadãos entre diferentes sistemas de diversos órgãos, como bancários, fiscais, entidades de segurança, sistemas de trânsito, imobiliários e sociais. Pensando nesse caso orientado a eventos, sempre que o cidadão atualizar seu estado civil, renda, endereço ou telefone de contato em um sistema central de cadastro, essa informação seria notificada por um evento, e cada um desses sistemas de órgãos públicos o consumiria, atualizando sua base cadastral.
Replicação por Change Data Capture - Captura de Alterações em Dados
O Change Data Capture (CDC) é uma técnica que detecta e captura as alterações feitas em uma fonte de dados, como um banco de dados relacional ou não relacional, e as transmite para outros sistemas em tempo real. Isso permite que outros serviços sejam imediatamente atualizados sem a necessidade de consultar diretamente o banco de dados original. Essa abordagem é muito útil para sincronizar dados entre diferentes sistemas, alimentar filas de mensagens ou manter caches atualizados com as informações mais recentes.
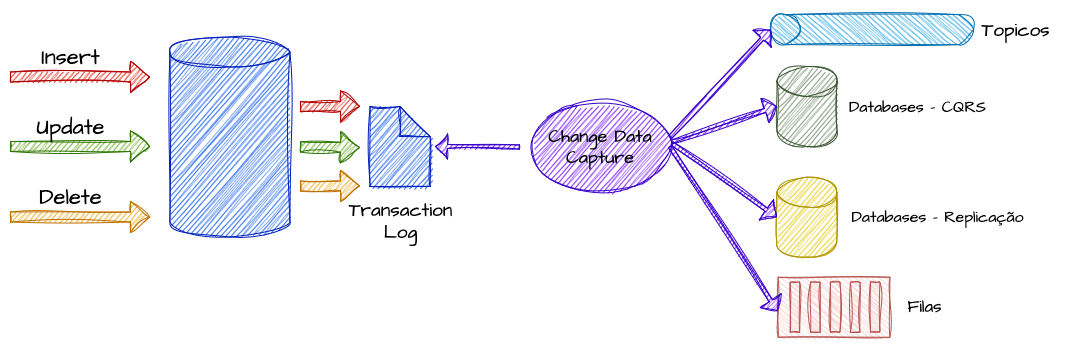
O objetivo desse padrão é oferecer um mecanismo que monitora operações como inserções, atualizações e deleções, capturando essas mudanças à medida que ocorrem. Depois de capturadas, as alterações podem ser enviadas para tópicos de eventos ou diretamente para sistemas que dependem desses dados. Isso possibilita que outros serviços recebam as informações mais recentes sem sobrecarregar o banco de dados principal com consultas constantes.
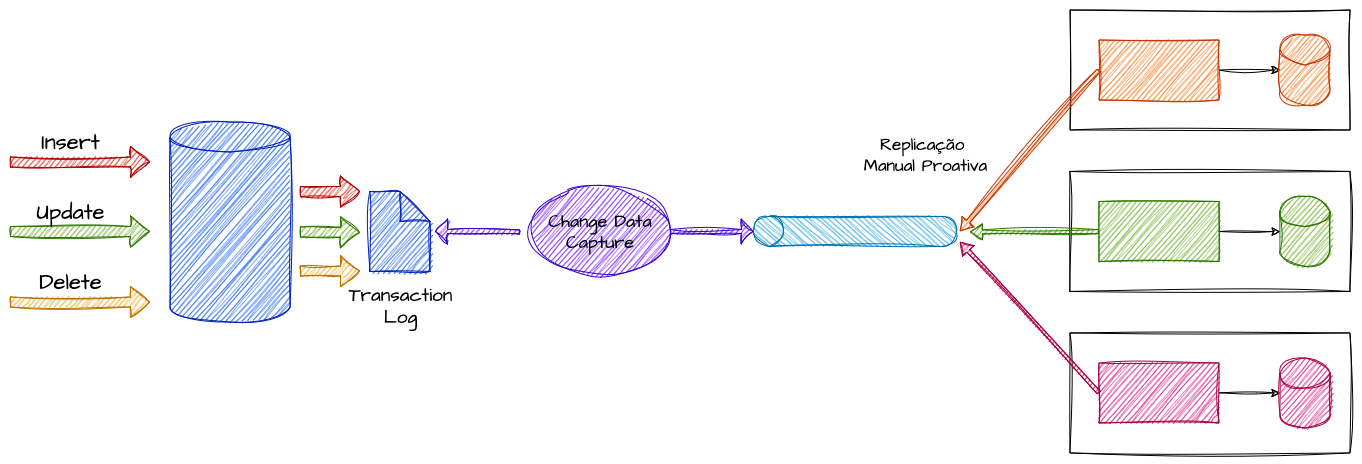
Essa técnica serve como base para outras estratégias, como o Event-Carried State Transfer, que se beneficia da captura de eventos para replicar dados de forma inteligente e proativa. O CDC também viabiliza processos que envolvem streaming de dados para datalakes, cacheamento proativo e CQRS, atuando como uma ponte reativa que facilita a replicação e a integração com outros padrões.
CRDTs - Conflict-Free Replicated Data Types
Em ambientes de replicação distribuída, especialmente em arquiteturas primary-primary ou multi-master, os CRDTs (Conflict-Free Replicated Data Types) são estruturas de dados que resolvem um dos maiores desafios desse modelo de replicação: como lidar com conflitos entre diferentes atualizações de um dado. Esse tipo de situação ocorre quando mais de um nó recebe alterações distintas do mesmo dado, e, durante a propagação dessas versões, surge a necessidade de resolver o conflito para decidir “qual será a versão final e correta” do dado. Os CRDTs garantem que esses conflitos sejam resolvidos automaticamente, sem a necessidade de coordenação ou bloqueio entre os nós.
Pense em um sistema de edição de documentos colaborativo, onde várias pessoas de uma equipe podem editar o mesmo artigo ao mesmo tempo. Se dois usuários, em nós diferentes, editarem a mesma linha do texto simultaneamente, um sistema que utiliza CRDTs pode mesclar as alterações automaticamente, resultando em uma versão final sem exigir intervenção manual ou gerar conflitos.
Os CRDTs são projetados de maneira que, mesmo que múltiplos nós atualizem um dado de forma independente, quando essas atualizações forem sincronizadas, o estado final será consistente. Isso é possível graças a propriedades matemáticas que tornam as operações associativas, comutativas e idempotentes, o que significa que a ordem das operações não importa — o resultado final será sempre o mesmo.
Além disso, os CRDTs garantem consistência eventual, ou seja, todos os nós eventualmente terão uma cópia consistente do dado, mesmo que tenham feito atualizações simultâneas. Como essa abordagem não exige bloqueios ou coordenação entre os nós, cada nó pode operar de forma independente, o que aumenta a disponibilidade do sistema. Isso torna os CRDTs especialmente adequados para ambientes primary-primary, onde todos os nós aceitam escritas de forma simultânea.
Revisores
Referências
SQL-Server: O que é a CDA (captura de dados de alterações)?
Event-Carried State Transfer Pattern
7 Data Replication Strategies & Real World Use Cases 2024
Replication Strategies and Partitioning in Cassandra
Event-Carried State Transfer: A Pattern for Distributed Data Management in Event-Driven Systems
Event-Carried State Transfer: Consistência e isolamento entre microsserviços
Event-Carried State Transfer Pattern
