
System Design - Saga Pattern

O ano de publicação desse texto foi marcado por interessantes experiências profissionais nas quais eu pude resolver problemas muito complexos de sistemas distribuídos utilizando o modelo Saga. Logo, por mais que tenha sido sensacional poder compilar todas as referências bibliográficas e materiais que consumi por todo esse período aqui, também foi extremamente desafiador remover as “exclusividades” que foram trabalhadas e deixar as sugestões sem um excesso de particularidades dos meus cenários.
É sempre maravilhoso poder contemplar um material finalizado sobre o tema de microserviços, arquitetura e sistemas distribuídos, mas esse capítulo em questão foi entregue com extrema felicidade. Espero que seja de bom proveito para todos que estão buscando por referências e experiências com esse tipo de implementação.
O que é o modelo SAGA?
Uma transação Saga é um padrão arquitetural que visa garantir a consistência dos dados em transações distribuídas, especialmente em cenários onde essas transações dependem de execução contínua em múltiplos microserviços ou possuam uma longa duração até serem completamente finalizadas, e onde qualquer execução parcial é indesejável.
O termo Saga vem do sentido literal de Saga, que o conceito remete a uma aventura, uma história, uma jornada do herói, jornada na qual a mesma remonta vários capítulos onde o “herói” precisa cumprir objetivos, enfrentar desafios, superar certos limites e concluir um objetivo predestinado. Dentro de uma implementação do Saga Pattern, uma Saga possui uma característica sequencial, na qual a transação depende de diversos microserviços para ser concluída, com etapas que devem ser executadas uma após a outra de forma ordenada e distribuída.
A implementação dessas etapas pode variar entre abordagens Coreografadas e Orquestradas, as quais serão exploradas mais adiante. Independentemente da abordagem escolhida, o objetivo principal é gerenciar transações que envolvem dados em diferentes microserviços e bancos de dados, ou que são de longa duração, e garantir que todos os passos sejam executados sem perder a consistência e controle, e em caso de falha de algum dos componentes por erros sistemicos ou por entradas de dados inválidas ter a capacidade de notificar todos os participantes da saga a compensarem a transação executando um rollback de todos os passos já executados.
Lembrando que a principal proposta do modelo Saga é garantir confiabilidade e consistência, não performance. Inclusive, suas maiores nuâncias pagam o preço de performance para atingir esses objetivos.
A Origem Histórica do Saga Pattern
Não é costume desta série de textos aprofundar demasiadamente nos detalhes acadêmicos e históricos dos tópicos abordados. Porém, vale destacar as origens do Saga Pattern e o problema que ele foi originalmente concebido para resolver.

O Saga Pattern foi publicado pela primeira vez por Hector Garcia-Molina e Kenneth Salem, em 1987, em um artigo para o Departamento de Ciências da Computação da Universidade de Princeton, intitulado “SAGAS“. O objetivo do artigo é enfrentar a problemática das Long Live Transactions (LLTs) nos computadores da época, quando já se buscava uma forma de lidar com processos que demandavam mais tempo que as operações tradicionais e não podiam simplesmente bloquear os recursos computacionais até sua conclusão.
Como mencionado, o termo “Saga” faz alusão a histórias que se desenrolam em capítulos menores, ou seja, a proposta era quebrar uma Transação de Longa Duração em várias transações menores, cada uma podendo ser confirmada ou desfeita de forma independente. Isso transformava uma operação atômica extensa em pequenas transações atômicas, com um nível de supervisão pragmática.
Portanto, embora o Modelo Saga não tenha sido inicialmente projetado para gerenciar consistência em microserviços, e sim para tratar processos computacionais em bancos de dados, ele foi revisitado ao longo do tempo. À medida que microserviços e sistemas distribuídos se tornaram mais comuns no ambiente corporativo, os princípios do Saga Pattern provarem-se úteis para lidar com falhas e garantir a consistência nessas arquiteturas modernas e distribuídas.
O problema de lidar com transações distribuídas
Uma transação distribuida é aquela que precisa acontecer em multiplos sistemas e bancos de dados para ser concluída. Por definição, entendemos que ela precisa de multiplos participantes escrevendo e commitando seus dados para que ela seja bem sucedida, e reportando o status de escrita para quem está coordenando a transação.
Vamos imaginar o sistema de pedidos de um grande e-commerce. A funcionalidade principal desse sistema é receber uma solicitação de pedido e executar todas as ações necessárias para garantir a efetivação completa desse pedido, desde a solicitação até a entrega. Para isso, é preciso interagir com diversos microserviços pertinentes a esse fluxo hipotético, como Serviço de Pedidos, Serviço de Pagamentos, Serviço de Estoque, Serviço de Entregas e um Serviço de Notificações que notifica o cliente de todas as etapas do pedido.
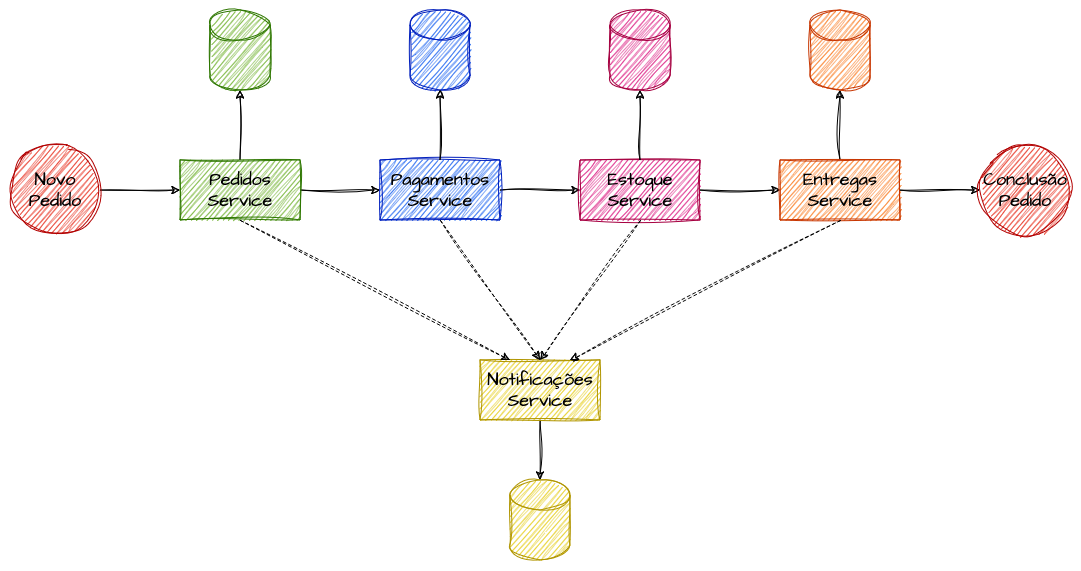
Exemplo de um processo distribuido inicial
Em uma arquitetura complexa com múltiplos serviços interligados, cada domínio isolado precisa garantir uma parte da sequência da execução para que o pedido seja concluído com sucesso. À medida que o número de componentes aumenta, a complexidade também cresce, aumentando a probabilidade de falhas e inconsistências.
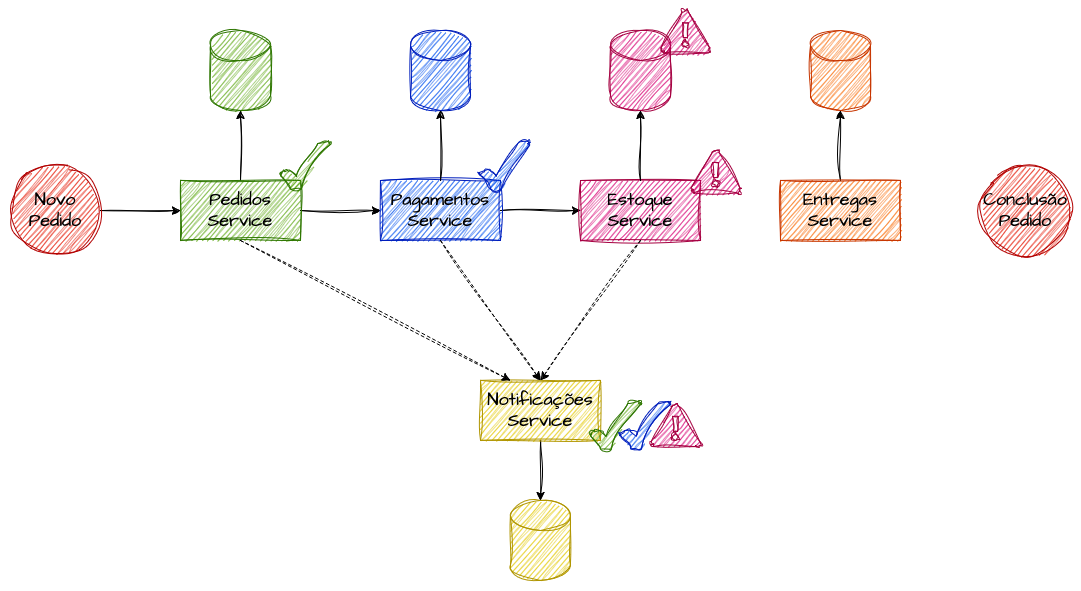
Exemplo de um erro em uma transação distribuída
Imagine que, durante a execução dessas etapas, um dos serviços falhe por algum motivo não sistêmico em termos de resiliência, como a falta de um item no estoque ou a recepção de informações inválidas pelo serviço de estoque. Nessas situações, pode ser impossível continuar as chamadas para os serviços subsequentes, como o serviço de entregas, mesmo que etapas críticas, como o processamento do pagamento, já tenham sido concluídas com sucesso. Nesse caso, conhecer e desfazer os passos anteriores pode se tornar um problema complicado.
Esse cenário representa um grave problema de consistência distribuída. Sem mecanismos adequados, o sistema pode acabar em um estado inconsistente, onde o pagamento foi efetuado, mas o pedido não foi concluído. O Saga Pattern busca solucionar exatamente esse tipo de problema, garantindo que, mesmo em caso de falhas, o sistema mantenha a integridade dos dados e retorne a um estado consistente em todos os serviços que compõe a transação.
O problema de lidar com transações longas
Em diversos cenários, processos complexos exigem um período um pouco mais longo para serem concluídos em sua totalidade. Por exemplo, uma solicitação dentro de um sistema que precisa passar por várias etapas de execução pode levar desde milissegundos até semanas ou meses para ser finalizada completamente.
O tempo de espera entre a execução de um microserviço e o serviço subsequente pode variar intencionalmente devido a fatores como agendamentos, estímulos externos, agrupamento de registros dentro de períodos e outros. Os exemplos disso incluem controle de cobrança de parcelamento, agendamento financeiro, consolidação de franquias de uso de produtos digitais, agrupamento de solicitações para processamento em batch, fechamento de faturas e controle de uso de recursos de um sistema por seus clientes.
Gerenciar o ciclo de vida dessas transações de longo prazo representa um desafio arquitetural significativo, especialmente em termos de consistência e conclusão. É necessário criar mecanismos que permitam controlar transações de ponta a ponta em cenários complexos, monitorar todas as etapas pelas quais a transação passou e determinar e gerenciar o estado atual da transação de forma transparente e duradoura. O Saga Pattern resolve esses problemas ao decompor transações longas em uma série de transações menores e independentes, cada uma gerenciada por um microserviço específico. Isso facilita a garantia de consistência, a recuperação de falhas no quesito de resiliência operacional.
A Proposta de Transações Saga
Concluindo o que foi abordado anteriormente na explicação da problemática, o Saga Pattern é um padrão arquitetural projetado para lidar com transações distribuídas e dependentes da consistência eventual em multiplos microserviços.
A proposta da aplicabilidade do Saga Pattern é decompor uma transação longa e complexa em uma sequência de transações menores e coordenadas, que são gerenciadas para garantir a consistência e sucesso ou erro da execução, e principalmente garantir a consistência dos dados em diferentes serviços que sigam o modelo “One Database Per Service”.
Cada Saga corresponde a uma transação pseudo-atômica dentro do sistema, onde cada solicitação corresponde a execução de uma operação isolada. Essas sagas em questão consistem em um agrupamento de operacões menores que acontecem localmente em cada microserviço da saga. Além de proporcionar meios de garantir que todas as etapas sejam concluídas, caso uma das operações da saga falhe, o Saga Pattern define transações compensatórias para desfazer as operações já executadas, assegurando que o sistema se mantenha consistênte até mesmo durante uma falha.
A proposta da Saga quando aplicado em abordagens assincronas elimina a necessidade de bloqueios síncronos e prolongados, como o caso do Two-Phase Commit (2PC) que são computacionalmente caros e podem se tornar gargalos de desempenho em ambientes distribuídos. Esses tipos de bloqueios longos também são complicados de serem restabelecidos em caso de falhas.
Existem dois modelos principais para implementar o Saga Pattern, o Modelo Orquestrado e o Modelo Coreografado. Cada um deles possui características de coordenação e comunicação das transações Saga diferentes em termos arquiteturais. A escolha entre os modelos depende das necessidades específicas de como o sistema foi projetado, e principalmente deve levar em conta a complexidade das transações.
Modelo Orquestrado
O Modelo Orquestrado propõe a existência de um componente centralizado de orquestração que gerencia a execução das sagas. O Orquestrador é responsável por iniciar a saga, coordenar a sequência de transações, monitorar as respostas e gerenciar o fluxo de compensação em caso de falhas. Ele atua como um control plane que envia comandos para os microserviços participantes e espera pelas respostas para decidir os próximos passos ou continuar a saga.
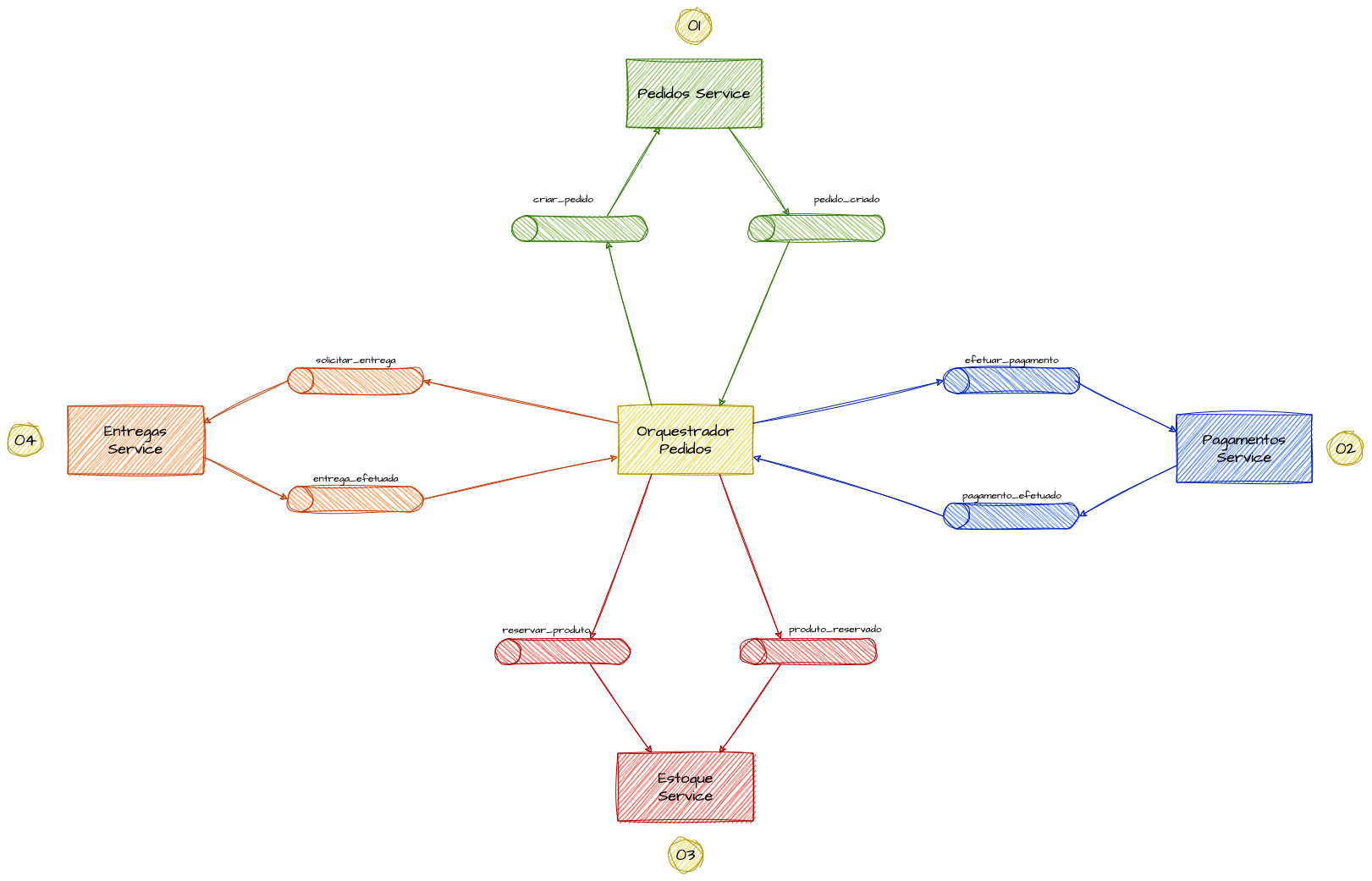
Exemplificação do Modelo Orquestrado
Considere que para concluir uma transação de um pedido de compra, você precisa estimular e esperar a resposta de confirmação de uma série de domínios como pagamentos, estoques, notificações e entregas. São muitos componentes distribuidos, com suas próprias limitações, capacidades de escala, modos de uso, e que possuem seus próprios contratos e precisam ser acionados de forma sequencial e lógica para que a transação seja concluída. Assumindo uma abordagem assíncrona, um orquestrador utiliza-se do pattern de command / response para acionar esses microserviços, e mediante a resposta de cada um deles acionar o próximo microserviço da saga, compensar as operações já realizadas em caso de falha, ou concluir e encerrá-la. Um orquestrador também pode trabalhar de forma síncrona se necessário, porém mecanismos de resiliência que já são “nativos” de mensageria, como backoff, retries e DLQ’s devem ser implementados manualmente para garantir uma resiliência saudável da execução da saga.
Então a função do orquestrador é basicamente montar um “mapa da saga”, com todas as etapas que precisam ser concluídas para a finaliza-la, enviar mensagens e eventos para os respectivos microserviços e, a partir de suas respostas, prosseguir e estimular o próximo passo da Saga até que a mesma esteja totalmente completa ou compensar as operações já realizadas em caso de falha.
O modelo orquestrado é dependente da implementação de um pattern de Máquina de Estado, e o mesmo deve ser capaz de gerenciar o estado atual e, mediante a respostas, mudar esse estado e tomar uma ação mediante ao novo estado. Dessa forma conseguimos controlar a orquestação de forma centralizada e segura, concentrando a complexidade de orquestração de microserviços em um único componente, onde podemos metrificar todos os passos, o início e fim da execução da saga, controle de historico e alteração de estado de forma transacional e etc.
Modelo de Comando / Resposta em Transações Saga
Em implementações modernas de Saga Pattern, principalmente no modelo orquestrado, muitas das interações entre os participantes da Saga ocorrem de forma assíncrona e reativa. Nessa abordagem, o orquestrador da saga (ou um serviço solicitante, fora do saga pattern) envia um comando para outro microserviço realizar uma ação, e aguarda a resposta de forma bloqueante ou semi-bloqueante antes de prosseguir para o próximo passo da Saga.
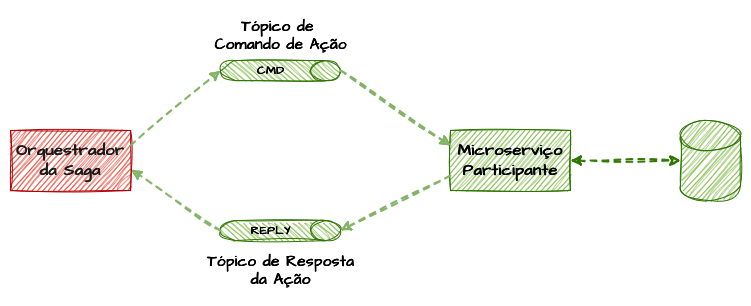
Modelo de Comando e Resposta de Fluxos Assincronos
Isso presume que os serviços expostos precisam expor um tópico de ação, e outro para respostas daquela ação em questão, para que o orquestrador ou serviço solicitante saiba onde enviar o comando e onde aguardar pela resposta de conclusão com sucesso ou falha do mesmo.
Modelo Coreografado
O modelo Coreografado, ao contrário do Orquestrado que propõe um componente centralizado que conhece todos os passos da saga, propõe que os microserviços devem conhecer o serviço seguinte e o anterior. Isso significa que a saga é executada em uma abordagem de malha de serviço, onde, num caso complexo, um microserviço quando é chamado e termina seu processo conhece o microserviço seguinte e o protocolo que o mesmo usa para expor suas funcionalidades. Esse microserviço se encarrega de executar o passo seguinte e assim sucessivamente até a finalização da saga.

A mesma lógica é aplicada em operações de compensação e rollback, onde o serviço que falhou é obrigado a notificar o anterior ou acionar um “botão do pânico” para que toda a malha anterior regrida com os passos já confirmados.

O modelo coreografado, por mais que seja mais simples e com menos garantias que o orquestrado de primeiro momento, também funciona como um viabilizador de fluxos síncronos para arquiteturas sagas.
Adoções Arquiteturais
As abordagens de Saga podem variar e se extender para diversos patterns arquiteturais. Nessa sessão vamos abordar alguns dos padrões e abordagens que eu considerei mais importantes e relevantes para serem considerados quando avaliamos uma arquitetura Saga para algum projeto.
Maquinas de Estado no Modelo Saga
Em arquiteturas distribuídas, manter o estado de todos os passos que uma saga deve efetuar até ser considerada concluída é talvez a preocupação de maior criticidade. Esse tipo de controle nos permite identificar quais sagas ainda estão pendentes ou falharam e em que passo isso aconteceu, permitindo criar mecanismos de monitoramento, retentativas, resumos de saga e compensação em caso de erros e etc.
Transições de Estados da Saga
Uma Maquina de Estado, ou State Machine, tem a função de lidar com o estados, eventos, transições e ações.
Os Estados representam o estado atual da máquina e os estados possíveis do sistema. O estado atual corresponde descritivamente ao status da transação, literalmente como Iniciado, Agendado, Pagamento Concluido, Entrega Programada, Finalizado e etc. Os Eventos correspondem a notificações relevantes do processo que podem ou não alterar o estado atual da máquina. Por exemplo, algum dos passos pode enviar os eventos Pagamento Aprovado ou Item não disponível no estoque, que são eventos que podem alterar o curso planejado da saga. Esses eventos podem ou não gerar uma Transição de Estado. As Transições correspondem a mudança de um estado válido para outro estado válido decorrente de um evento recebido. Por exemplo, se o estado de um registro for Estoque Reservado e o sistema de pagamentos enviar o evento de Pagamento Concluído, isso pode notificar a máquina e transicionar o estado para Agendar Entrega. Caso o evento emitido for Pagamento Recusado, o estado da máquina pode ser transicionado para Pedido Cancelado por exemplo. Ao transacionar de um Estado para outro, a máquina executa uma Ação para prosseguir com a execução. No exemplo anterior, ao entrar no estado Agendar Entrega, a máquina precisa invocar o microserviço de entregas.
E dentro de um modelo saga, entendemos que o estado atual corresponde a saga em si e eventos são as entradas e saídas dos microserviços e passos que são chamados. Uma máquina de estado precisa ser capaz de guardar o estado atual e, mediante a um evento de mudança que ela recebe de alguma forma, determinar se existirá uma nova transição de estado, e em caso positivo, qual ação ele deve tomar com relação a isso.
Ciclo de Vida da Saga
Imagine que a saga seja iniciada, criando um novo registro na máquina de estado que representa o início de uma saga de fechamento de pedido. Esse estado inicial poderia ser considerado NOVO. Dentro do mapeamento da saga, entendemos que, quando o estado é NOVO, é necessário garantir que o domínio de pedidos tenha gravado todos os dados referentes à solicitação para fins analíticos.

Exemplo do Fluxo de Transição e Ações da Saga
Assim que o serviço de pedidos confirmar a gravação do registro, o estado pode transicionar para RESERVANDO, onde o próximo passo da saga se encarregará de reservar o item em estoque. Após receber a confirmação dessa reserva, o estado se tornará RESERVADO, iniciando em seguida o processo de cobrança, alterando o estado para COBRANDO. Nesse momento, o sistema de pagamentos será notificado e poderá levar algum tempo para responder, informando se o pagamento foi efetivado ou não.
Em caso de sucesso, o estado mudará para COBRADO, e o sistema de entregas será notificado sobre quais itens devem ser entregues, bem como o endereço de destino. Assim, o estado transiciona para INICIAR_ENTREGA. A partir daí, poderíamos ter diversos estados intermediários, nos quais ações adicionais, como o envio de notificações por e-mail, seriam realizadas. Exemplos incluem SEPARACAO, SEPARADO, DESPACHADO, EM_ROTA e ENTREGUE. Finalmente, a saga atinge o estado FINALIZADO, sendo considerada concluída em sua totalidade.
Por outro lado, se o sistema de pagamentos, partindo do estado COBRANDO, mudar para um estado de falha como PAGAMENTO_NEGADO ou NAO_PAGO, a saga deverá notificar o sistema de reservas para liberar os itens, possibilitando que sejam novamente disponibilizados para compra, além de atualizar o estado analítico do sistema de pedidos.
De modo geral, a máquina de estado segue uma lógica semelhante a:
- Qual evento acabei de receber? →
COBRADO COM SUCESSO - Qual é o meu estado atual? →
COBRANDO - Se meu estado é
COBRANDOe eu receboCOBRADO COM SUCESSO, para qual estado devo ir? →INICIAR_ENTREGA - Qual ação devo tomar ao entrar no estado
INICIAR_ENTREGA? → Notificar o sistema de entregas.
Basicamente, o controle funciona questionando: “Que evento é esse?”, “Onde estou agora?”, “Para onde vou agora?” e, finalmente, “O que devo fazer aqui?”.
Logs de Saga e Rastreabilidade da Transação
Manter registros de todos os passos da transação pode ser extremamente vantajoso, tanto em sagas mais simples quanto, principalmente, nas mais complexas, porém pode se tornar custoso se mantido por longo prazo. A principal vantagem de manter uma coordenação de estados é possibilitar a rastreabilidade de todas as sagas: as concluídas, as que estão em andamento ou as que foram finalizadas com erro.
Podemos considerar estruturas e modelagens de dados que permitam gerar uma rastreabilidade completa de todos os passos iniciados e finalizados. Dessa forma, o componente centralizado — no caso dos modelos orquestrados — registra e mantém documentados os passos executados, bem como as respectivas respostas, facilitando o controle pragmático ou manual.
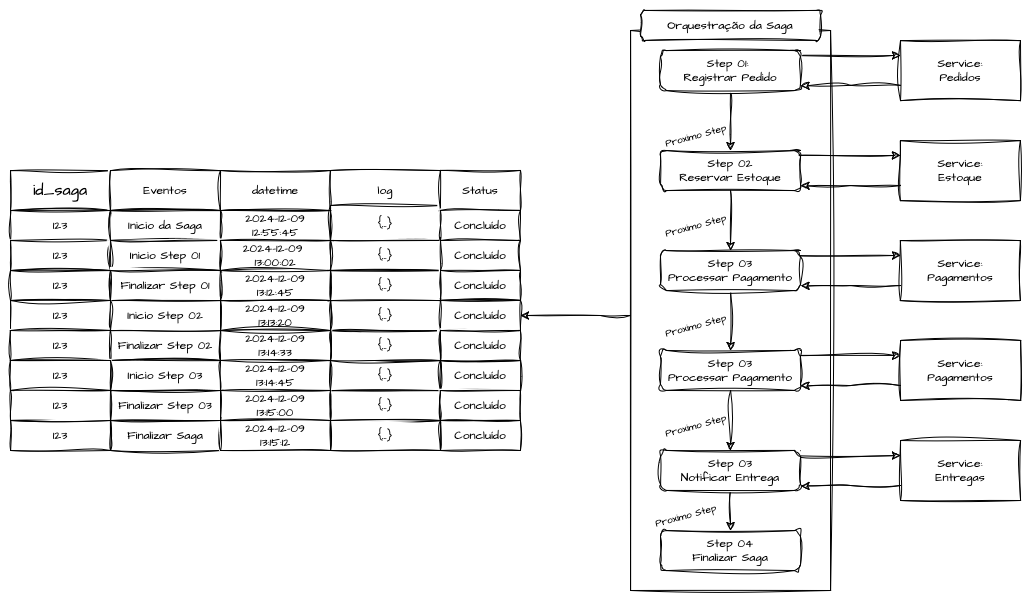
Com isso, é possível verificar de maneira simples quais sagas apresentaram erros, mantendo esses registros na camada de dados. Esses recursos fornecem insumos para criar mecanismos de resiliência inteligentes o suficiente para monitorar, retomar, reiniciar ou tentar novamente os passos que falharam, além de auxiliar na construção de uma visão analítica da execução da jornada de serviço.
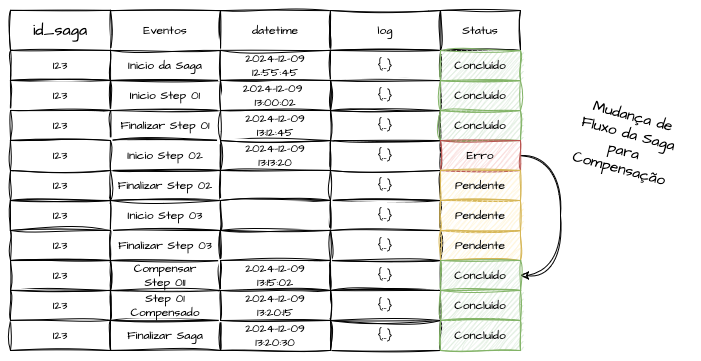
Modelos de Ação e Compensação no Saga Pattern
Projetar sistemas distribuídos é assumir um compromisso no qual reconhecemos que lutaremos constantemente contra problemas de consistência de dados. Os patterns de compensação dentro das transações Saga garantem que todos os passos, executados de forma sequencial, possam ser revertidos em caso de falha.
Assim como o modelo Saga é criado para garantir que todas as transações saudáveis sejam executadas com sucesso, o modelo de compensação assegura que, em caso de falha sistêmica — seja por dados inválidos, problemas de disponibilidade irrecuperáveis dentro do SLA da Saga, problemas de saldo, pagamentos, limites de crédito, disponibilidade de estoque ou dados de entrada inválidos — as ações sejam completamente revertidas, permitindo que o sistema retorne a um estado consistente e evitando que apenas parte da transação seja confirmada enquanto o restante falha.
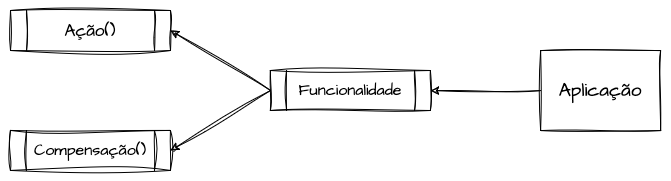
Uma forma eficiente de projetar handlers que recebem estímulos e executam algum passo da saga, seja por meio de endpoints de API ou de listeners de eventos ou mensagens, é expor esses handlers junto aos métodos de reversão. Assim, sempre haverá um handler que execute a ação e outro que desfaça essas ações. Por exemplo, reservaPassagens() e liberaPassagens(), cobrarPedido() e estornarCobranca(), ou incrementarUso() e decrementarUso().
Uma vez que dispomos das ferramentas necessárias para que o modelo de orquestração escolhido possa acionar os microserviços responsáveis pelas ações solicitadas, podemos assegurar o chamado “caminho feliz” da saga.
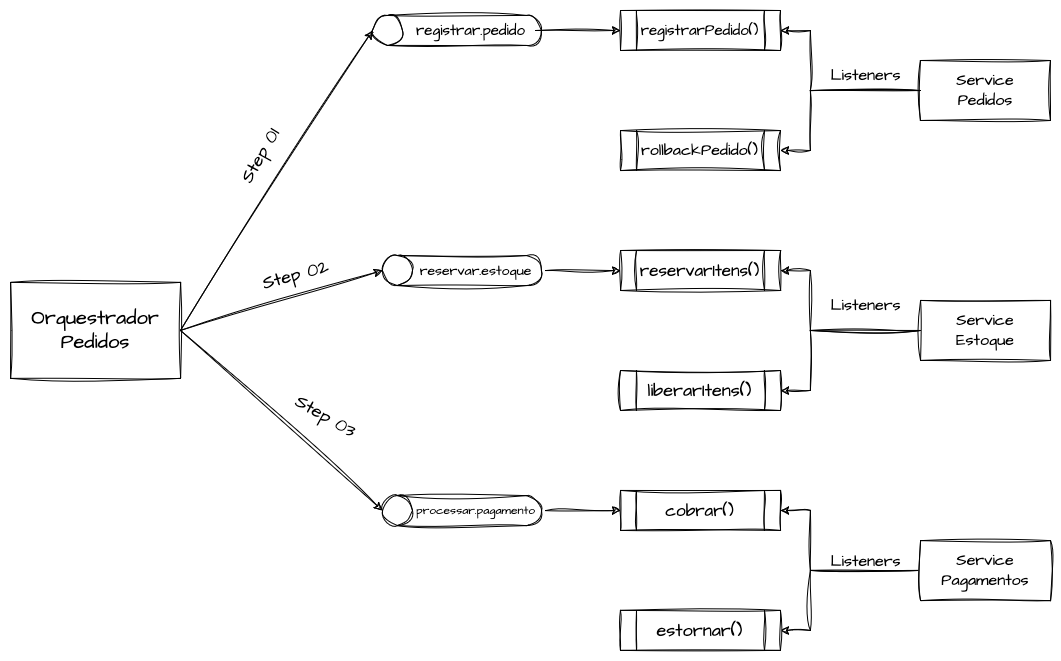
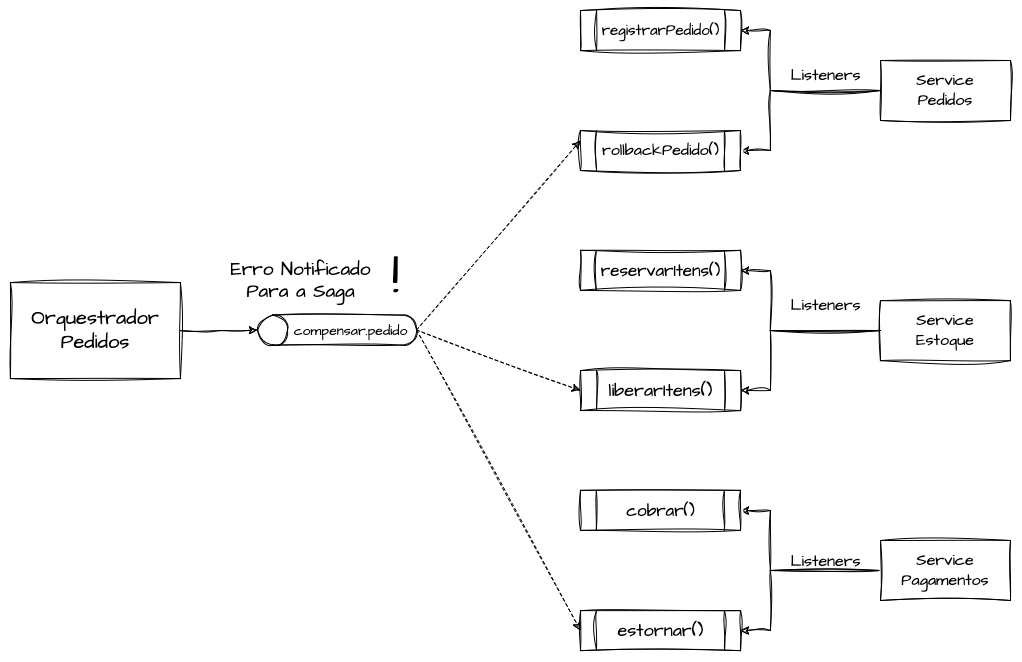
Com o modelo de Ação e Compensação implementado, o orquestrador da saga também pode “apertar o botão do pânico” quando necessário, notificando todos os microserviços participantes para desfazerem as ações que foram confirmadas. Em uma arquitetura orientada a eventos ou mensageria que ofereça suporte a esse tipo de transação, podemos criar um tópico de compensação da saga com múltiplos consumer groups, de modo que cada um receba a mesma mensagem e execute a compensação se a transação já tiver sido confirmada no serviço em questão.
Problemas de Dual Write em Transações Saga
O Dual Write é conhecido tanto como um problema quanto como um pattern clássico em arquiteturas distribuídas. Ele ocorre com frequência em cenários onde determinadas operações precisam gravar dados em dois locais diferentes — seja em um banco de dados e em um cache, em um banco de dados e em uma API externa, em duas APIs distintas ou em um banco de dados e em uma fila ou tópico. Em essência, sempre que for necessário garantir a escrita de forma atômica em múltiplos pontos, estaremos diante desse tipo de desafio.
Para ilustrar o problema na prática em uma aplicação que utiliza o Saga Pattern, consideremos um exemplo em que seja preciso confirmar a operação em um local, mas o outro esteja indisponível. Nesse caso, a confirmação não será atômica, pois as duas escritas deveriam ser consideradas juntas para manter a consistência dos dados.
No modelo coreografado, para que uma operação seja concluída em sua totalidade, cada microserviço executa localmente as ações em seu banco de dados e em seguida publica um evento no broker para o próximo serviço dar continuidade ao fluxo. Esse seria o “caminho feliz” da saga, sem problemas de consistência até aqui.
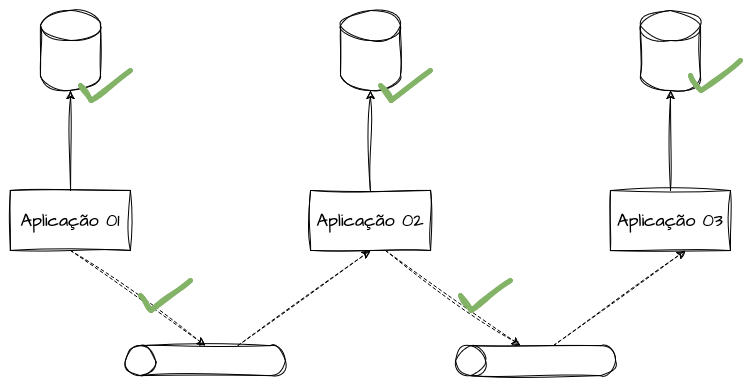
Modelo Coreografado - Exemplo de dual write
Os problemas de consistência aparecem, por exemplo, quando o dado não é salvo no banco de dados, mas o evento é emitido em sequência; ou quando o dado é salvo corretamente, porém, por indisponibilidade do broker de mensagens, o evento não é emitido. Em ambos os casos, o sistema pode se encontrar em um estado inconsistente.
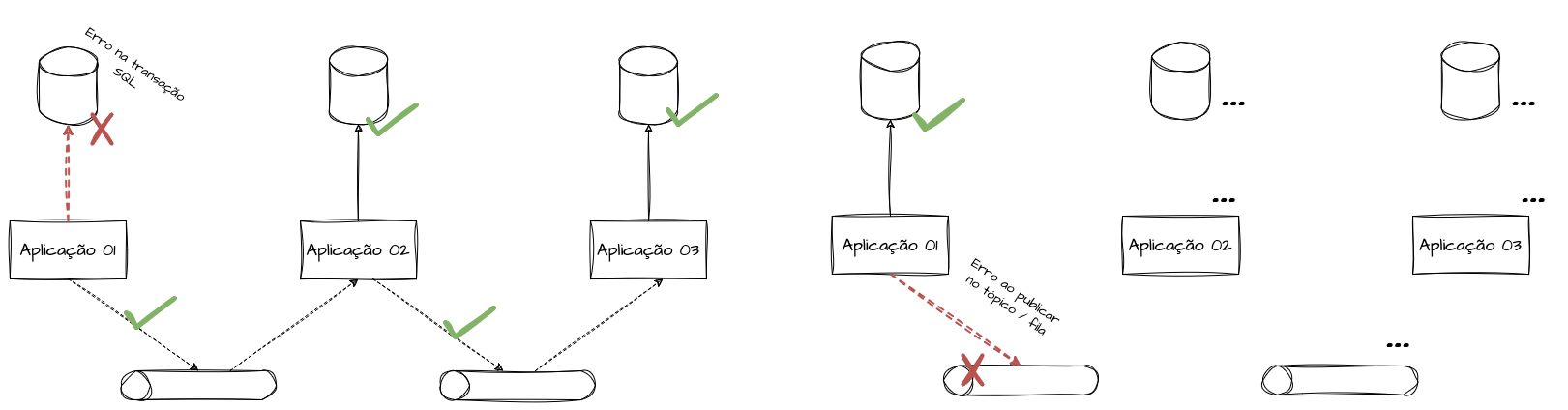
Modelo Coreografado - Exemplo de falha de dual write
No modelo orquestrado, o mesmo problema pode ocorrer, ainda que de forma ligeiramente diferente. Em um cenário de comando e resposta entre orquestrador e microserviços, se um deles falhar ao tentar garantir a escrita dupla (entre suas dependências e o canal de resposta), poderemos ter uma saga perdida, em que etapas intermediárias não são confirmadas e ficam “presas” no meio do processo por falta de resposta ou confirmação.
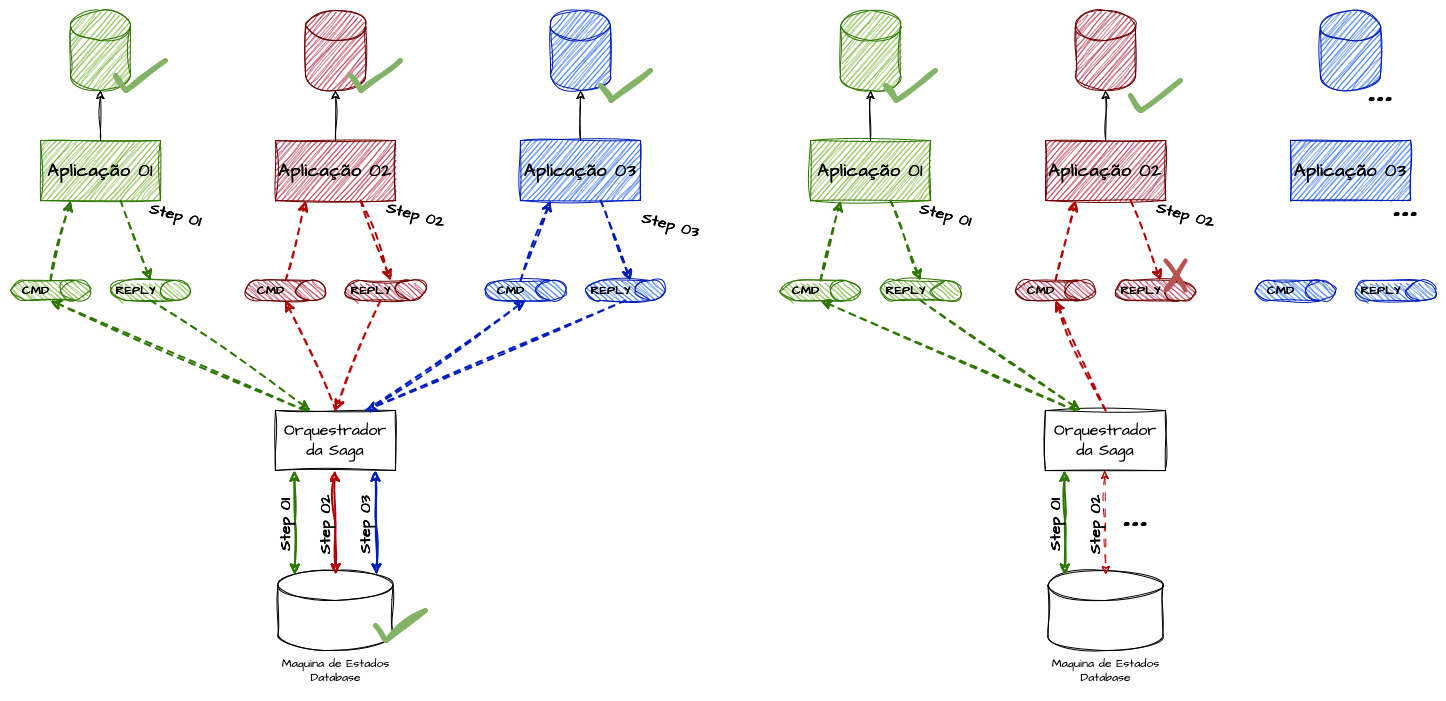
Modelo Orquestrado - Exemplo de falha de dual write
Garantir que todos os passos sejam executados com a devida atomicidade é, talvez, a maior complexidade na implementação de um modelo Saga. Os mecanismos de controle precisam dispor de recursos sistêmicos suficientes para lidar com problemas de falhas, adotando retentativas, processos de supervisão de sagas e formas de identificar aquelas que foram iniciadas há muito tempo e ainda não foram concluídas ou estão em um estado inconsistente. A alternativa mais eficiente dentro de banco de dados ACID por exemplo, é executar a publicação do evento dentro de uma transaction no banco de dados, e só commitar a modificação dos dados quando os processos de comunicação estarem concluídos, garantindo que todos os processos, ou nenhum, sejam efetuados.
Outbox Pattern e Change Data Capture em Transações Saga
O Outbox Pattern já foi mencionado anteriormente algumas vezes, porém resolvendo problemas diferentes. Nesse caso, podemos utilizá-lo para atribuir uma característica transacional a execução e controle de steps da saga. Onde temos um processo de relay adicional em um modelo orquestrado que através de uma fila sincrona do banco, consegue verificar quais steps de quais sagas estão pendentes e somente removê-los dessa “fila” no banco quando todos os processos de execução do step forem devidamente executados.
Essa é uma abordagem interessante para se blindar contra os problemas de Dual Write e ajudar a aplicação a se garantir em questão de resiliência em períodos de indisponibilidades totais e parciais de suas dependências.

Mecanismos de Change Data Capture podem ser empregados para lidar com o transporte do dado para o sistema subsequente. Essa abordagem pode ser implementada em ambas alternativas arquiteturais do Saga Pattern, embora lidar com as transações de forma pragmática, controlando manualmente a execução, os fallbacks e as lógicas de negócio referentes aos steps da saga seja o mais indicado no padrão orquestrado pelo próprio objetivo do orquestrador.
Two-Phase Commit em Transações Saga
Embora os exemplos deste capítulo tenham adotado uma característica de orquestração assíncrona para detalhar as implementações de Saga, é possível explorar tópicos que nos ajudem a manter certos níveis de consistência em um contexto síncrono, típico de uma abordagem cliente/servidor (request/reply).
O Two-Phase Commit (2PC) é um padrão bastante conhecido para tratar sistemas distribuídos. Ele propõe que, em uma transação com vários participantes, exista um coordenador capaz de garantir que todos estejam “pré-confirmados” (prontos para gravar a transação) antes de efetivamente aplicar as mudanças em seus respectivos estados, realizando, portanto, a confirmação em duas fases. Caso algum dos passos não confirme que esté pronto para comitar o estado, nenhum deles recebe o comando de commit. Além de implementações de microserviços, esse pattern é muito bem empregado em estratégias de replicação.
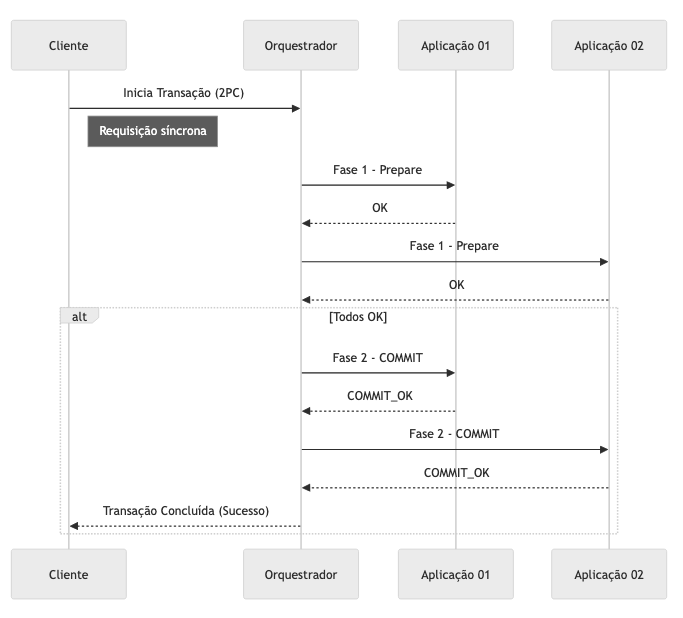
Two-Phase Commit executado com sucesso
Esse protocolo 2PC traz a sensação de atomicidade para serviços distribuídos que compõem uma transação, pois o coordenador envia solicitações de confirmação a cada participante antes de efetivar o commit. Tal abordagem pode ser de grande valor em transações Saga que exijam a validação de todos os passos antes da conclusão total — principalmente em cenários síncronos, nos quais o cliente aguarda uma resposta imediata e, muitas vezes, a operação pode ser abortada repentinamente, sem a possibilidade de compensar etapas já executadas.
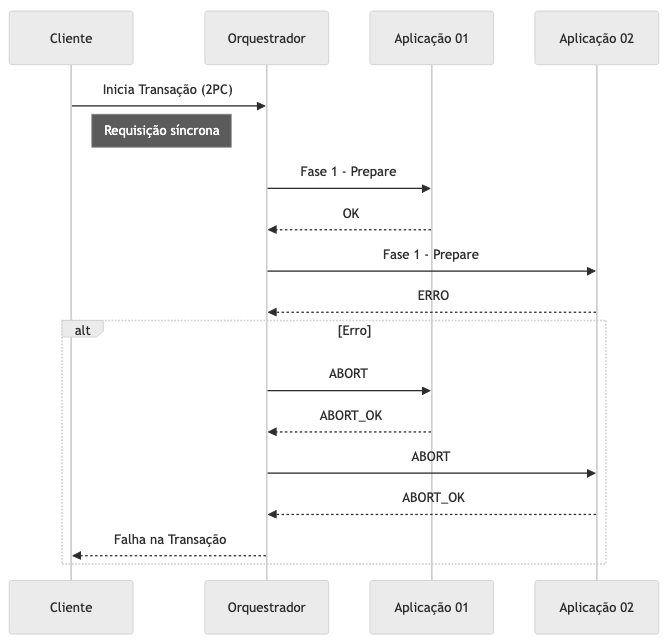
Two-Phase Commit executado com erro
Caso algum dos serviços não responda com sucesso, ou em tempo hábil para o mecanismo de coordenação da transação, o mesmo envia sinal de rollback da transação para que todos os participantes não considerem as transações pendentes.
Esse pattern, por mais que seja muito útil, também pode se tornar um gargalo de performance em ambientes de alta demanda, por precisar gerenciar multiplas conexões abertas a todo momento em diferentes contextos. Uma forma de otimizar esse tipo de abordagem é adotar protocolos de comunicação que facilite a gestão de long-live-connections como o gRPC que pode manter conexões bidirecionais e reaproveitar a conexão para diversas requisições.
Mecanismos de Reinicialização de Saga
Ainda que os mecanismos de coordenação do Saga Pattern forneçam diversos “guard rails” para a execução de transações, imprevistos sistêmicos podem ocorrer, resultando em inconsistências de estado entre os microserviços. Nesse cenário, é preciso tomar decisões de negócio sobre como lidar com falhas significativas entre os participantes da saga: optar por compensações em massa ou por alguma estratégia de reinicialização de saga.
No caso de uma reinicialização de saga, é essencial que todos os microserviços implementem controles de idempotência, de forma a receber o mesmo comando múltiplas vezes sem gerar erros inesperados. Por exemplo, se um serviço de reserva de quartos de hotel receber repetidamente a mesma solicitação de reserva para o mesmo quarto e para o mesmo usuário, deve aceitar a operação sem sobrescrever ou alterar o estado, enviando a devida resposta de sucesso. Isso facilita processos de ressincronização do estado.
Quando o processo de coordenação (seja orquestrado ou coreografado) recebe estímulos para iniciar uma nova saga com identificadores únicos ou chaves de idempotência já existentes para outra saga, ele pode reiniciar a saga por completo ou verificar quais etapas ficaram incompletas, de modo a reinicializa-las a partir do ponto em que não houve resposta, garantindo assim a consistência das transações.
Obrigado aos Revisores
Referências
SAGAS - Department of Computer Science Princeton University
Saga distributed transactions pattern
The Saga Pattern in a Reactive Microservices Environmen
Enhancing Saga Pattern for Distributed Transactions within a Microservices Architecture
SAGA Pattern para microservices
Saga Pattern — Um resumo com Caso de Uso (Pt-Br)
Distributed Sagas: A Protocol for Coordinating Microservices
What is a Saga in Microservices?
Try-Confirm-Cancel (TCC) Protocol
Microservices Patterns: The Saga Pattern
Compensating Actions, Part of a Complete Breakfast with Sagas
Getting started with small-step operational semantics
Microserviços e o problema do Dual Write
Solving the Dual-Write Problem: Effective Strategies for Atomic Updates Across Systems
Outbox Pattern(Saga): Transações distribuídas com microservices
Saga Orchestration for Microservices Using the Outbox Pattern
Martin Kleppmann - Distributed Systems 7.1: Two-phase commit
