
System Design - Sharding e Particionamento de Dados

Esse é mais um capítulo da nossa série de System Design, e novamente vamos abordar assuntos delicados relacionados à escalabilidade, focando em assuntos críticos como dados. Dessa vez, iremos nos aprofundar em algumas das estratégias mais efetivas e interessantes na arquitetura de sistemas, que são o particionamento, ou sharding. O objetivo deste trabalho será apresentar estratégias, prós e contras entre algumas das possibilidades arquiteturais de segregação de dados, clientes e esforço computacional para aumentarmos alguns graus de escalabilidade horizontal em diversas cargas de trabalho.
Definindo Sharding
Sharding, ou particionamento, é uma técnica de design de sistemas distribuídos utilizada para dividir grandes conjuntos de dados em várias partes menores, chamadas de shards ou partições. Cada shard representa uma fração do todo, permitindo que o sistema gerencie grandes volumes de dados de forma mais eficiente e segura. Essa técnica é amplamente empregada para melhorar a escalabilidade, performance e disponibilidade dos sistemas, especialmente em ambientes onde a quantidade de dados é tão grande que não pode ser gerenciada eficientemente por um único local, servidor, banco de dados ou carga de trabalho.
O conceito de sharding não se limita apenas a databases. Embora seu uso mais comum seja a distribuição de dados, o particionamento pode ser aplicado em várias áreas da engenharia de software, como a distribuição de cargas de trabalho em microserviços, cache distribuído e até mesmo na segmentação de tráfego de rede.

No contexto de bancos de dados, cada shard é um subconjunto do banco de dados original, que pode ser armazenado em diferentes servidores ou nós de um sistema distribuído. Essa divisão permite que o sistema distribua e gerencie dados de maneira eficaz, evitando os gargalos e pontos únicos de falha que podem ocorrer quando todos os dados são centralizados em um único ponto. Além disso, o sharding facilita a escalabilidade horizontal, onde novos servidores podem ser adicionados para armazenar shards adicionais conforme a quantidade de dados cresce, sem comprometer o desempenho.
Essa técnica também traz a complexidade de manutenção e balanceamento dos shards, além da necessidade de garantir a consistência dos dados entre diferentes shards em escala.
Topologia de Sharding
No contexto de sharding, existem várias topologias que podem ser aplicadas para suprir as necessidades específicas de sistemas. Se olharmos o conceito fora da caixa, podemos encontrar várias abordagens diferentes para distribuir cargas e aumentar a performance e resiliência de um sistema.
Sharding para Segregação de Dados
O sharding para segregação de dados é a técnica mais conhecida quando pensamos em sharding. É essencialmente utilizada para distribuir diferentes conjuntos de dados entre shards distintos, sendo esses shards conhecidos como diferentes tabelas ou instâncias de bancos de dados, sendo roteados com base em algum critério. Esta abordagem é frequentemente aplicada em sistemas onde há necessidade de isolar certos tipos de dados por motivos de segurança, compliance ou simplesmente para facilitar a gestão e o desempenho.

Uma aplicação multi-tenant, onde os dados de cada um dos clientes principais podem ser segregados em diferentes shards, não só melhora a segurança, garantindo que os dados de um cliente não sejam acessíveis por outro, ou diminuindo a superfície de acesso, mas também permite otimizar a performance ao adaptar a infraestrutura de cada shard às necessidades específicas de cada cliente.
Outro caso comum de sharding para segregação de dados ocorre em sistemas que armazenam dados sensíveis e não sensíveis. Dados altamente confidenciais ou que sejam inerentes a alguma regulamentação externa podem ser segregados em shards com maior segurança ou com capacidades adicionais de auditoria, enquanto dados menos críticos podem ser armazenados em shards com configurações mais leves, reduzindo custos e complexidade para um público geral.
Sharding para Segregação Computacional
O sharding para segregação computacional é uma abordagem focada na distribuição das cargas de trabalho computacionais entre diferentes shards. Em vez de apenas distribuir dados, essa técnica visa isolar operações computacionais intensivas em shards dedicados, elevando algumas camadas a mais de otimização.
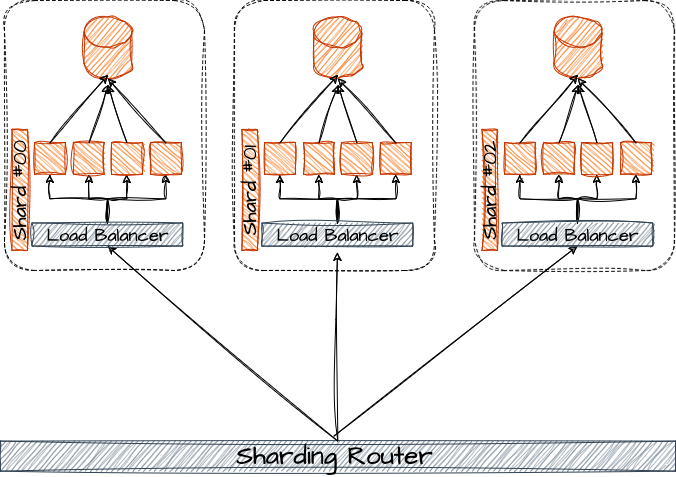
Em sistemas que realizam operações computacionais pesadas, como cálculos em tempo real, processamento de grandes volumes de dados ou execução de algoritmos de machine learning, a segregação computacional permite que essas tarefas sejam isoladas em shards específicos, enquanto operações menos intensivas são alocadas em outros shards. Isso evita que as operações mais leves sejam afetadas pelo consumo de recursos das operações mais pesadas, garantindo uma performance mais consistente em todo o sistema.
Essa abordagem também é útil em ambientes onde diferentes tipos de operações exigem configurações de hardware específicas. Shards voltados para operações de I/O intensivo podem ser otimizados com discos rápidos e maior largura de banda, enquanto shards que realizam processamento de CPU intensivo podem ser configurados com mais núcleos de processamento.
Escalabilidade e Performance
A importância do sharding em sistemas distribuídos reside principalmente na necessidade de lidar com grandes volumes de dados e garantir que o sistema possa escalar horizontalmente. Um dos pontos mais críticos de escala em sistemas distribuídos é o banco de dados, e o sharding desempenha um papel fundamental nessa área.
Ao dividir os dados em múltiplos shards, cada shard pode ser armazenado e gerenciado em servidores diferentes. Isso permite que mais capacidade seja adicionada ao sistema sem a necessidade de reestruturar a base de dados original por completo, facilitando a expansão da infraestrutura à medida que a demanda aumenta. Essa capacidade de escalabilidade horizontal é importante para sistemas que precisam crescer continuamente sem comprometer o desempenho ou a integridade dos dados como um todo.
Com os dados divididos em shards menores, as operações de leitura e escrita podem ser distribuídas entre diferentes recursos computacionais. Essa distribuição reduz a carga em qualquer servidor individual, resultando em tempos de resposta mais rápidos e uma performance geral melhorada. Além disso, o particionamento dos dados ajuda a evitar gargalos, permitindo que o sistema mantenha um desempenho consistente mesmo sob altas cargas.
Outro benefício significativo do sharding é a contribuição para a alta disponibilidade. Se um nó de um sistema que contém um shard específico falhar, os outros shards ainda estarão disponíveis, permitindo que o sistema continue a operar com funcionalidades reduzidas, em vez de enfrentar uma falha total. Essa resiliência é crítica em ambientes de produção, onde a disponibilidade contínua é essencial para a experiência do usuário e a integridade dos serviços.
Sharding Keys e Hot Partitions
Antes de explorarmos algumas possibilidades existentes para implementações de sharding, precisamos explorar dois conceitos muito importantes e complementares dentro da teoria de particionamento. Precisaremos entender o que são as sharding keys e o fenômeno das hot partitions.
Sharding Keys
Quando pensamos em uma estratégia de particionamento de dados para resolver problemas de escalabilidade, a primeira pergunta que devemos fazer é: “Particionar baseado em quê?”. Definir como vamos dividir os dados em um determinado contexto é o passo mais importante, antes de qualquer escolha de tecnologia. Ao definir uma dimensão de corte para o particionamento, encontramos nossa sharding key.
A sharding key, ou chave de partição, é o critério utilizado para determinar como e em qual partição os dados serão armazenados. A escolha dessa chave deve ser pensada para garantir uma distribuição eficiente e balanceada dos dados entre os shards. Uma sharding key ideal deve ter alta cardinalidade, o que significa que ela deve ser capaz de gerar um grande número de valores únicos para garantir uma distribuição uniforme dos dados. Além disso, a sharding key deve ser baseada em campos que são frequentemente acessados nas consultas, como datas, identificadores, categorias, entre outros.
Sharding keys comuns podem incluir as iniciais de um identificador de cliente, o ID de uma entidade, o hash de um valor comum ou categorias específicas. Por exemplo, em um sistema financeiro, é comum dividir a base de clientes entre Pessoas Físicas e Pessoas Jurídicas. Instituições bancárias podem realizar sharding baseado em ranges de agências. Em sistemas de vendas ou logística, uma abordagem comum é dividir a base por intervalos de datas em que as transações ocorreram, utilizando sharding keys como meses ou anos. Em sistemas multi-tenant, é possível particionar com base no hash de um identificador do tenant, garantindo que os dados de cada tenant sejam armazenados de forma isolada e eficiente.
Existem várias estratégias e aplicações para definir quais sharding keys escolher para a distribuição de dados. A escolha da estratégia correta depende do contexto e das características específicas do sistema. Nos próximos tópicos, exploraremos algumas dessas estratégias em mais detalhes.
Hot Partitions
As hot partitions são problemas que ocorrem devido à má distribuição de dados e alocações entre as partições de um sistema. Esse fenômeno ocorre quando uma ou mais partições recebem uma carga de trabalho desproporcionalmente alta em comparação com as outras, resultando em um desempenho degradado.
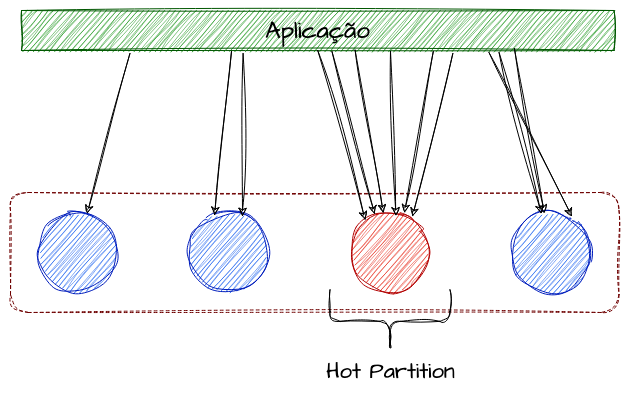
Vamos elaborar um caso hipotético de um sistema multi-tenant, onde comportamos, em média, 300 clientes distribuídos entre 10 partições. Idealmente, cada partição comportaria cerca de 30 clientes, representando aproximadamente 10% do uso total do sistema, assumindo uma distribuição equilibrada. No entanto, suponha que três desses 300 clientes principais representem juntos 50% de todo o uso do sistema. Agora, imagine que, devido a um cálculo de hash, esses três clientes sejam alocados na mesma partição. Isso faria com que uma única partição representasse mais de 50% do uso total, enquanto as outras nove partições ficariam subutilizadas. Esse cenário ilustra o problema de uma hot partition.
Como a distribuição dos dados entre as partições geralmente é realizada por meio de operações lógicas e matemáticas efetuadas sobre a chave de partição, e não diretamente com base no tamanho ou padrão de uso dos dados, pode ocorrer o fenômeno em que uma ou mais partições recebem uma quantidade desproporcional de tráfego ou carga de trabalho. Essas partições sobrecarregadas podem causar lentidão nas operações e, em casos extremos, levar a falhas graves no sistema. Enquanto isso, as outras partições, estando subutilizadas, resultam em uma utilização ineficiente dos recursos disponíveis.
Para mitigar o problema de hot partitions, algumas técnicas podem ser aplicadas, como o uso de chaves de particionamento aleatórias, que ajudam a distribuir a carga de forma mais uniforme. Outra abordagem é o pré-particionamento, onde a distribuição dos dados é planejada antecipadamente com base em padrões de uso conhecidos. Adicionalmente, a capacidade de isolar sharding keys específicas em partições dedicadas pode ser útil em cenários onde certos clientes ou dados geram tráfego significativamente maior. Por fim, o uso de caching inteligente pode aliviar a carga sobre as partições mais utilizadas, redistribuindo as operações de leitura e melhorando o desempenho geral do sistema.
Estratégias e Aplicações de Sharding
O objetivo desta sessão é explicar algumas das muitas possibilidades de aplicação de sharding em sistemas distribuídos. Aqui iremos explorar técnicas de como realizar o particionamento utilizando diversos modelos de sharding keys.
Sharding por ranges de iniciais
Uma estratégia, embora não tão eficaz, mas útil para ilustrar o conceito de sharding, é a distribuição de uma base de usuários, clientes ou tenants baseada nas iniciais de um identificador. Podemos definir a distribuição dos dados entre intervalos de iniciais das sharding keys, como, por exemplo, utilizando intervalos de A-E para um shard, F-J para outro, K-N, O-R, S-V e W-Z consecutivamente.
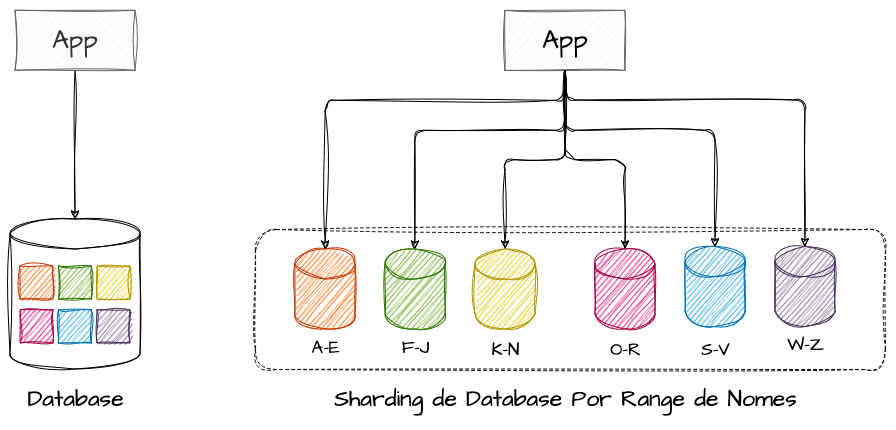
Embora este seja um exemplo simples e fácil de compreender para ilustrar a distribuição de dados entre partições, ele também revela um dos problemas que o sharding busca evitar: as hot partitions ou partições quentes. Esse problema ocorre quando há um uso desproporcional entre os shards, resultando em um desequilíbrio de carga.
Para complementar o exemplo, em um cenário de distribuição baseada nas iniciais dos nomes dos clientes, podemos inferir que existem mais Anas, Brunos, Carlos e Danielas do que Wesleys, Yasmins e Ziraldos. Nesse caso, a partição responsável por armazenar os dados de clientes com iniciais de A-E (partição 1) seria muito mais utilizada em comparação com a partição responsável por W-Z (partição 6). Isso resultaria em um desbalanceamento de performance significativo, onde a partição 1 estaria sobrecarregada perante uma hot partition, enquanto a partição 6 estaria quase completamente subutilizada.
Este exemplo demonstra a importância de escolher uma sharding key que promova uma distribuição equilibrada dos dados, para evitar gargalos e garantir o desempenho eficiente do sistema.
Sharding por Ranges de Identificadores
Estabelecer uma estratégia de distribuição onde os dados são divididos com base em intervalos contínuos de valores da sharding key é uma abordagem comum no mercado. Uma distribuição sequencial requer um controle maior de governança, pois pode resultar em um fenômeno de “transbordo”, onde alguns shards podem ficar “cheios” enquanto outros permanecem “vazios” ou subutilizados.
Essa estratégia consiste na ideia de que cada shard contém um intervalo específico de valores, e as consultas são direcionadas ao shard apropriado com base na sharding key. Esta abordagem é particularmente útil quando os dados podem ser ordenados de forma natural e as consultas frequentemente envolvem intervalos de valores.
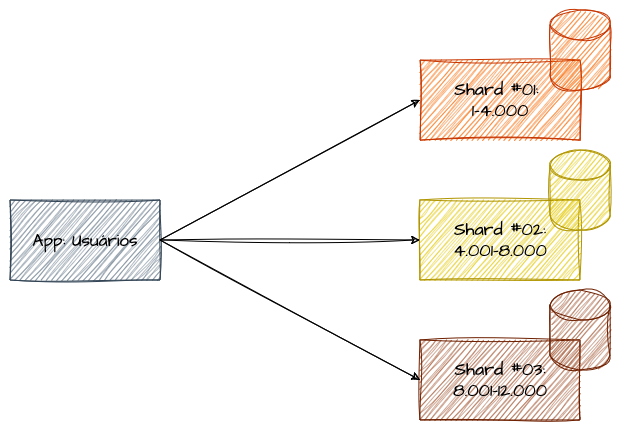
Imagine que temos uma base de 10.000 usuários que foram ordenados de forma sequencial durante a sua criação. Após análises, foi determinado que essa base de dados poderia ser particionada em 3 shards, cada um contendo um intervalo específico de identificadores de usuários. Além disso, essa estratégia deveria suportar a criação de novos usuários. Se levarmos o aspecto sequencial ao pé da letra, poderíamos acabar com dois shards “cheios” e um com capacidade ociosa suficiente para suportar o crescimento futuro da base de usuários.
No entanto, esse tipo de particionamento pode levar a problemas de balanceamento de carga. Se a distribuição dos valores não for uniforme, alguns shards podem atingir sua capacidade máxima enquanto outros permanecem subutilizados, criando ineficiências e possíveis gargalos no sistema. Portanto, ao utilizar sharding por ranges de identificadores, é necessário monitorar e ajustar a distribuição conforme o sistema cresce para evitar esses ocasionais problemas e garantir uma performance consistente entre todos os shards.
Sharding por Ranges de Datas e Tiers de Storage
Utilizar atributos sequenciais é uma das possibilidades ao definir distribuições baseadas em ranges de valores das sharding keys. Esse aspecto pode ser aproveitado, por exemplo, em sharding por intervalos de tempo. Dentro de um hipotético sistema de vendas, poderíamos definir o sharding com base em intervalos de datas. Em um exemplo mais direto, imagine que temos uma base de dados projetada para armazenar as transações que ocorreram dentro de cada ano. A longo prazo, isso resultaria em uma base de dados responsável por agrupar todas as transações de um determinado ano.
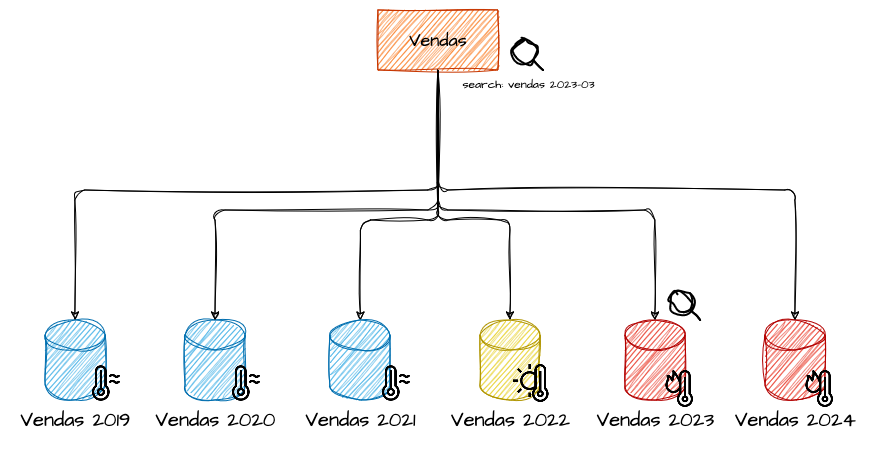
Nessa abordagem, poderíamos aplicar outra estratégia comum em sharding: a utilização de diferentes “tiers” de armazenamento para os dados. Essa estratégia envolve categorizar os dados em camadas de armazenamento com diferentes níveis de desempenho e custo. Por exemplo, os dados do ano corrente e do ano anterior poderiam ser armazenados em um tier “hot”, utilizando opções de armazenamento mais caras e performáticas, para garantir acesso rápido e eficiente. Para os anos que ainda têm acesso frequente, mas sem a mesma intensidade dos anos mais recentes, um tier intermediário “warm” poderia ser utilizado. Finalmente, para os dados de vendas de anos muito anteriores, que são acessados esporadicamente, poderíamos utilizar um tier “cold”, que oferece uma opção de armazenamento mais barata e menos performática.
Essa combinação de sharding por intervalos de datas com tiers de armazenamento permite não apenas uma distribuição eficiente dos dados, mas também uma otimização de custos e desempenho, adaptando os recursos de acordo com a frequência de acesso e a importância dos dados ao longo do tempo.
Sharding por Hashing
O sharding por hashing é uma técnica de particionamento de dados ou computação em que uma função hash é aplicada sobre a shard key para decidir onde cada dado será armazenado ou para onde o cliente será roteado. Essa função converte o valor do atributo, ou sharding key, em um valor de hash, que é então mapeado para um dos shards disponíveis utilizando uma operação de módulo (mod), que retorna o resto da divisão de um número por outro.
Por exemplo, se o valor de hash for 15 e houver 3 shards, a operação 15 % 3 resultará em 0, indicando que o registro deve ser armazenado no shard 0. Caso o valor do hash seja 10, a operação 10 % 3 retornará 1, o que significa que o cliente será alocado no shard 1.
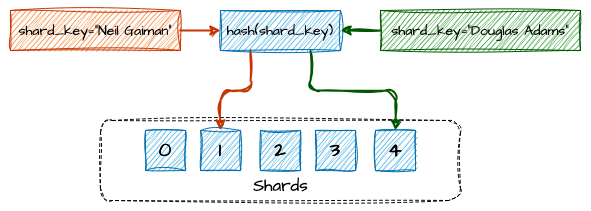
Exemplo de Balanceamento por Hash Functions
Vamos imaginar um sistema multi-tenant que atende a vários cenários de negócio. Foi identificado que o identificador do tenant seria a melhor shard key para distribuir os clientes de forma equitativa entre os shards. Nesse caso, para determinar em qual shard o cliente será alocado, podemos aplicar o algoritmo SHA-256 para gerar um hash do valor do identificador. Em seguida, o hash é convertido para um número inteiro. Com base nesse inteiro, aplicamos a operação de módulo pelo número de shards disponíveis, e o resultado indicará o shard no qual o tenant será alocado.
Essa abordagem de sharding por hashing é especialmente útil para evitar hot partitions, uma vez que a função hash tende a distribuir os dados de forma uniforme entre os shards. Além disso, a simplicidade da operação de módulo torna esse método eficiente e fácil de implementar, mesmo em sistemas de grande escala.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
package main
import (
"crypto/sha256"
"encoding/binary"
"fmt"
"strings"
)
// Calcula o hash SHA-256 do valor do tenant e o converte para um inteiro
func hashTenant(tenant string) int {
// Converte o valor do tenant para minúsculas
tenant = strings.ToLower(tenant)
// Converte a string tenant para um byte slice e calcula o hash.
hash := sha256.New()
hash.Write([]byte(tenant))
hashBytes := hash.Sum(nil)
// Converte o hash para um número inteiro
hashInt := binary.BigEndian.Uint64(hashBytes)
// Converte o valor para um valor positivo caso o hashint venha a ser negativo
if int(hashInt) < 0 {
return -int(hashInt)
}
return int(hashInt)
}
// Recebe uma string do tenant e o número de shards, retornando o número do shard correspondente
func getShardByTenant(tenant string) int {
// Número disponível de Shards
numShards := 3
// Calcula o mod do hash baseado no numero de shards
hashValue := hashTenant(tenant)
shard := hashValue % numShards
return shard
}
func main() {
// Lista de tenants
tenants := []string{
"Petshops-Souza",
"Pizzarias-Carvalho",
"Mecanica-Dois-Irmaos",
"Padaria-Estrela-Filial-1",
"Padaria-Estrela-Filial-2",
"Padaria-Estrela-Filial-3",
"Hortifruti-Oba",
"Acougue-Zona-Leste",
"Acougue-Zona-Oeste",
"Acougue-Zona-Norte",
}
// Verifica a distribuição dos tenants entre os shards
for _, tenant := range tenants {
shard := getShardByTenant(tenant)
fmt.Printf("Tenant: %s, Shard: %d\n", tenant, shard)
}
}
Output
1
2
3
4
5
6
7
8
9
10
Tenant: Petshops-Souza, Shard: 1
Tenant: Pizzarias-Carvalho, Shard: 2
Tenant: Mecanica-Dois-Irmaos, Shard: 1
Tenant: Padaria-Estrela-Filial-1, Shard: 0
Tenant: Padaria-Estrela-Filial-2, Shard: 2
Tenant: Padaria-Estrela-Filial-3, Shard: 1
Tenant: Hortifruti-Oba, Shard: 2
Tenant: Acougue-Zona-Leste, Shard: 2
Tenant: Acougue-Zona-Oeste, Shard: 0
Tenant: Acougue-Zona-Norte, Shard: 1
Este esquema de distribuição é simples, intuitivo e funciona bem. Ou seja, até que o número de servidores mude. O que acontece se um dos servidores falhar ou ficar indisponível? As chaves precisam ser redistribuídas para compensar a ausência do servidor, naturalmente. O mesmo se aplica se um ou mais servidores novos forem adicionados ao pool. Resumindo, sempre que o número de servidores mudar, o resultado da operação de módulo também mudará, o que acarretará uma perda de referências na distribuição dos dados.
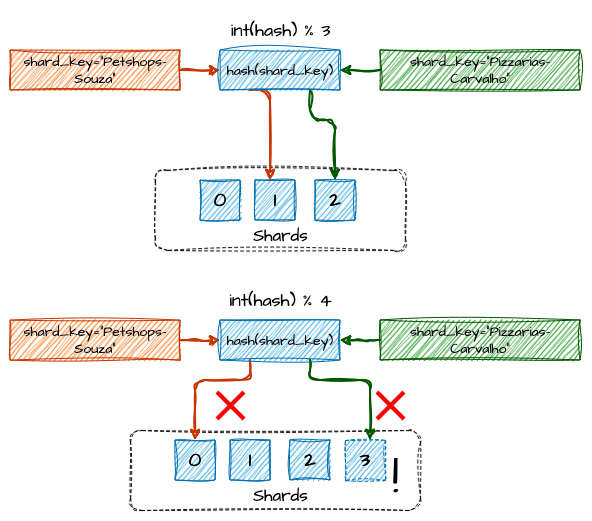
Exemplo de perda de referências entre shards devido à mudança no resultado do módulo
Em recursos stateless, como, por exemplo, um shardeamento de recursos computacionais, como servidores de aplicação, essa dificuldade é fácil de superar. Da mesma forma, em aplicações que mantêm dados em estado, mas que podem ser facilmente recriados e reconstituídos, como camadas de cache, o impacto é menor. No entanto, em particionamentos que envolvem dados persistentes, essa estratégia começa a apresentar sérios desafios com a mudança de servidores, perdendo totalmente o roteamento para o armazenamento de dados original e potencialmente criando inconsistências instantâneas.
Nesse cenário, é necessário um árduo trabalho de redistribuição de dados entre os shards, que deve ocorrer imediatamente após qualquer alteração na escalabilidade horizontal. Para mitigar esse problema em cenários onde os nodes podem mudar, a estratégia de Hashing Consistente é frequentemente adotada.
Distribuição e os Algoritmos de Hashing
A escolha correta de um algoritmo de hashing para basear a distribuição de dados é um ponto de tuning fino que pode mudar completamente o resultado da solução. Após uma escolha inteligente da sharding key, é recomendado aplicar diversos tipos de algoritmo de hashing sobre uma amostra das chaves, de forma comparativa, para chegar a uma conclusão sobre qual implementação garantirá a melhor distribuição.
Dependendo do algoritmo selecionado, os dados podem ser distribuídos de forma mais ou menos uniforme entre os shards, impactando diretamente a performance e a resiliência do sistema.
O código a seguir implementa cinco funções de hash: SHA-256, SHA-512, MD5, FNV-1a e uma função de hash simples. Cada função de hash converte o identificador de um tenant em um valor de hash, que é então utilizado para determinar em qual shard o tenant será alocado.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
package main
import (
"crypto/md5"
"crypto/sha256"
"crypto/sha512"
"encoding/binary"
"fmt"
"hash/fnv"
"strings"
)
// Função de hash utilizando SHA-256
func hashSHA256(tenant string) int {
tenant = strings.ToLower(tenant)
hash := sha256.New()
hash.Write([]byte(tenant))
hashBytes := hash.Sum(nil)
hashInt := binary.BigEndian.Uint64(hashBytes)
return int(hashInt)
}
// Função de hash utilizando SHA-512
func hashSHA512(tenant string) int {
tenant = strings.ToLower(tenant)
hash := sha512.New()
hash.Write([]byte(tenant))
hashBytes := hash.Sum(nil)
hashInt := binary.BigEndian.Uint64(hashBytes)
return int(hashInt)
}
// Função de hash utilizando MD5
func hashMD5(tenant string) int {
tenant = strings.ToLower(tenant)
hash := md5.New()
hash.Write([]byte(tenant))
hashBytes := hash.Sum(nil)
hashInt := binary.BigEndian.Uint64(hashBytes)
return int(hashInt)
}
// Função de hash utilizando FNV-1a
func hashFNV1a(tenant string) int {
tenant = strings.ToLower(tenant)
hash := fnv.New64a()
hash.Write([]byte(tenant))
hashInt := hash.Sum64()
return int(hashInt)
}
// Função de hash simples
func hashSimple(tenant string) int {
tenant = strings.ToLower(tenant)
var hash int
for _, char := range tenant {
hash += int(char)
}
return hash
}
// Função para obter o shard utilizando o hash escolhido
func getShardByTenant(tenant string, hashFunc func(string) int, numShards int) int {
hashValue := hashFunc(tenant)
shard := hashValue % numShards
if int(shard) < 0 {
return -int(shard)
}
return shard
}
func main() {
// Lista de tenants
tenants := []string{
"Petshops-Souza",
"Pizzarias-Carvalho",
"Mecanica-Dois-Irmaos",
"Padaria-Estrela-Filial-1",
"Padaria-Estrela-Filial-2",
"Salão-Beleza-Filial-1",
"Salão-Beleza-Filial-2",
"Auto-Peças-Sul",
"Academia-BoaForma",
"Escola-Livre",
// ...
}
// Número de shards
numShards := 5
// Hash functions
hashFuncs := map[string]func(string) int{
"SHA-256": hashSHA256,
"SHA-512": hashSHA512,
"MD5": hashMD5,
"FNV-1a": hashFNV1a,
"Hash Simples": hashSimple,
}
// Resultado das distribuições
distributions := make(map[string][]int)
// Inicializa as distribuições
for name := range hashFuncs {
distributions[name] = make([]int, numShards)
}
// Calcula a distribuição dos tenants entre os shards para cada algoritmo de hash
for _, tenant := range tenants {
for name, hashFunc := range hashFuncs {
shard := getShardByTenant(tenant, hashFunc, numShards)
distributions[name][shard]++
}
}
// Exibe os resultados
for name, dist := range distributions {
fmt.Printf("Distribuição para %s:\n", name)
for i, count := range dist {
fmt.Printf("Shard %d: %d tenants\n", i, count)
}
fmt.Println()
}
}
Output
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
go run main.go
Distribuição para SHA-512:
Shard 0: 8 tenants
Shard 1: 9 tenants
Shard 2: 12 tenants
Shard 3: 7 tenants
Shard 4: 5 tenants
Distribuição para MD5:
Shard 0: 13 tenants
Shard 1: 9 tenants
Shard 2: 4 tenants
Shard 3: 5 tenants
Shard 4: 10 tenants
Distribuição para FNV-1a:
Shard 0: 6 tenants
Shard 1: 6 tenants
Shard 2: 6 tenants
Shard 3: 14 tenants
Shard 4: 9 tenants
Distribuição para Hash Simples:
Shard 0: 5 tenants
Shard 1: 7 tenants
Shard 2: 9 tenants
Shard 3: 10 tenants
Shard 4: 10 tenants
Distribuição para SHA-256:
Shard 0: 9 tenants
Shard 1: 7 tenants
Shard 2: 6 tenants
Shard 3: 8 tenants
Shard 4: 11 tenants
É de extrema importância ressaltar que o resultado desse experimento somente tem valor para os critérios das sharding keys do exemplo. Em caso de outro tipo de valor, os resultados podem ser completamente diferentes. O exemplo é apenas para ilustrar a diferença de resultado na distribuição.
Sharding e Distribuição por MurmurHash
O MurmurHash, ou simplesmente Murmur, é uma função de hash rápida, eficiente e não criptográfica, comumente utilizada para gerar identificadores de hash a partir de strings ou outros tipos de dados. O MurmurHash transforma esses dados em números inteiros, proporcionando a capacidade nativa de lidar com ranges e intervalos de valores, o que é especialmente útil para a distribuição de dados e aplicações de hashing consistente.

O MurmurHash se destaca nessa tarefa de evitar hot partitions por distribuição desbalanceada, pois espalha os valores de hash de maneira próxima ao uniforme.
Quando você aplica o MurmurHash a uma string, que serve como sua sharding key, o algoritmo gera um valor de hash numérico. Esse valor de hash é um número inteiro de 32 ou 64 bits, dependendo da versão do MurmurHash utilizada, sem a necessidade de operações adicionais para essa conversão. A simplicidade do MurmurHash, junto com seu baixo consumo de recursos computacionais, o tornam ideal para sistemas que precisam processar grandes volumes de dados rapidamente.
A seguir, é apresentada a implementação do MurmurHash como algoritmo de hashing para a distribuição de tenants entre 5 shards.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
package main
import (
"fmt"
"github.com/spaolacci/murmur3"
)
// Função para calcular o hash utilizando MurmurHash3
func murmurHash(tenant string) uint32 {
return murmur3.Sum32([]byte(tenant))
}
// Função para determinar o shard a partir do valor de hash
func getShardByMurmurHash(tenant string, numShards int) int {
hashValue := murmurHash(tenant)
shard := hashValue % uint32(numShards)
return int(shard)
}
func main() {
// Lista de tenants
tenants := []string{
"Petshops-Souza",
"Pizzarias-Carvalho",
"Mecanica-Dois-Irmaos",
"Padaria-Estrela-Filial-1",
"Padaria-Estrela-Filial-2",
"Padaria-Estrela-Filial-3",
"Padaria-Estrela-Filial-3",
"Hortifruti-Oba",
"Acougue-Zona-Leste",
"Acougue-Zona-Oeste",
"Acougue-Zona-Norte",
"Livraria-Cultura",
// ...
}
// Número de shards
numShards := 5
// Criação de um mapa para contar a distribuição dos tenants pelos shards
shardDistribution := make(map[int]int)
// Exibe a distribuição final dos shards
fmt.Println("\nDistribuição Final dos Shards:")
for i := 0; i < numShards; i++ {
fmt.Printf("Shard %d: %d tenants\n", i, shardDistribution[i])
}
}
Output
1
2
3
4
5
6
Distribuição Final dos Shards:
Shard 0: 7 tenants
Shard 1: 8 tenants
Shard 2: 9 tenants
Shard 3: 8 tenants
Shard 4: 7 tenants
Sharding por Hashing Consistente
O Hashing Consistente é uma técnica de sharding em sistemas distribuídos muito útil, onde a adição ou remoção de servidores, ou shards, é uma tarefa comum. Diferentemente do sharding por hashing simples, onde a adição ou remoção de um shard pode exigir a redistribuição de muitos, senão de todos os dados, o hashing consistente minimiza a quantidade de dados que precisam ser realocados, proporcionando mais escalabilidade à solução. É importante ressaltar que, embora a redistribuição seja minimizada, ela ainda ocorre, porém em uma escala muito menor.
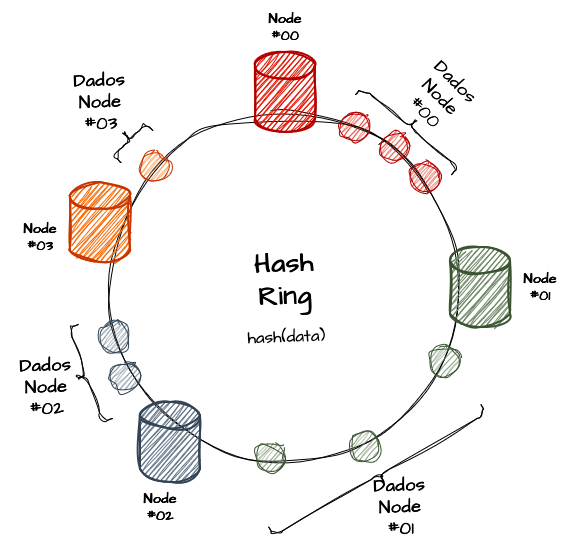
As representações visuais de hashing consistente são geralmente ilustradas de forma cíclica, e a estrutura de dados central para a distribuição das chaves entre os nós é conceituada como um anel, conhecido como “hash ring”. A distribuição de um hash em um nó ocorre, na verdade, por um intervalo de valores dentro do anel, e não diretamente pelo valor do hash da chave. Isso permite que, ao alterar a quantidade de nós, os valores resultantes do cálculo de módulo mudem muito pouco, reduzindo a necessidade de redistribuição de dados.
Se utilizássemos uma abordagem tradicional de hashing para distribuir os dados dos tenants entre os servidores, toda vez que adicionássemos ou removêssemos um servidor, muitos dados precisariam ser redistribuídos, o que pode ser caro e demorado.
Voltamos ao exemplo hipotético de um sistema de sharding multi-tenant. Imagine um círculo que representa todos os possíveis valores de hash. Cada nó de servidor é mapeado para um ponto nesse círculo, e cada tenant também é mapeado para um ponto no círculo usando a mesma função hash. Tanto a alocação de nodes quanto de dados é efetuada no mesmo anel, da mesma forma. Os dados de um tenant são armazenados no servidor que aparece primeiro no sentido horário a partir do ponto onde o tenant foi mapeado. Caso o anel seja composto de números incrementais, se o valor do hash exceder o limite, a posição retorna para o marco 0 do círculo, “dando uma volta” no hash ring.
Nesse caso, quando um novo nó é adicionado, ele também é mapeado para um ponto específico desse círculo. Somente os dados que estão entre o novo nó e o próximo nó no sentido horário precisam ser redistribuídos, enquanto o restante pode permanecer onde estava. O mesmo ocorre com a remoção de um nó: seus dados devem ser transferidos para o próximo nó no sentido horário no círculo, minimizando a redistribuição e mantendo a integridade dos dados de forma eficiente.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
package main
import (
"crypto/sha256"
"encoding/binary"
"fmt"
"sort"
"strconv"
"strings"
)
// Representa um nó no anel de hash.
type Node struct {
ID string
Hash uint64
}
// Representa o hash ring que contém vários nós.
type ConsistentHashRing struct {
Nodes []Node
NumReplicas int
}
// Cria um novo anel de hash ring.
func NewConsistentHashRing(numReplicas int) *ConsistentHashRing {
return &ConsistentHashRing{
Nodes: []Node{},
NumReplicas: numReplicas,
}
}
// Adiciona um novo node ao Hash Ring
func (ring *ConsistentHashRing) AddNode(nodeID string) {
for i := 0; i < ring.NumReplicas; i++ {
replicaID := nodeID + strconv.Itoa(i)
hash := hashTenant(replicaID)
ring.Nodes = append(ring.Nodes, Node{ID: nodeID, Hash: hash})
}
sort.Slice(ring.Nodes, func(i, j int) bool {
return ring.Nodes[i].Hash < ring.Nodes[j].Hash
})
}
// Remove um node existente do Hash Ring
func (ring *ConsistentHashRing) RemoveNode(nodeID string) {
var newNodes []Node
for _, node := range ring.Nodes {
if node.ID != nodeID {
newNodes = append(newNodes, node)
}
}
ring.Nodes = newNodes
sort.Slice(ring.Nodes, func(i, j int) bool {
return ring.Nodes[i].Hash < ring.Nodes[j].Hash
})
}
// Retorna o node onde o Tenant deverá estar alocado
func (ring *ConsistentHashRing) GetTenantNode(key string) string {
hash := hashTenant(key)
idx := sort.Search(len(ring.Nodes), func(i int) bool {
return ring.Nodes[i].Hash >= hash
})
// Se o índice estiver fora dos limites, retorna ao primeiro nó
if idx == len(ring.Nodes) {
idx = 0
}
return ring.Nodes[idx].ID
}
// Calcula o hash do tenant e a converte para uint64.
func hashTenant(s string) uint64 {
s = strings.ToLower(s)
hash := sha256.New()
hash.Write([]byte(s))
hashBytes := hash.Sum(nil)
return binary.BigEndian.Uint64(hashBytes[:8])
}
func main() {
// Cria um novo anel de hash consistente com 3 réplicas por nó.
ring := NewConsistentHashRing(3)
// Adiciona pseudo-nodes ao hash ring
ring.AddNode("Shard-00")
ring.AddNode("Shard-01")
ring.AddNode("Shard-02")
ring.AddNode("Shard-03")
// Lista de Tenants
keys := []string{
"Petshops-Souza",
"Pizzarias-Carvalho",
"Mecanica-Dois-Irmaos",
"Padaria-Estrela-Filial-1",
"Padaria-Estrela-Filial-2",
"Padaria-Estrela-Filial-3",
"Hortifruti-Oba",
"Acougue-Zona-Leste",
"Acougue-Zona-Oeste",
"Acougue-Zona-Norte",
}
// Distribuição Inicial dos Tenants pelos Nodes
for _, key := range keys {
node := ring.GetTenantNode(key)
fmt.Printf("Tenant: %s, Node: %s\n", key, node)
}
// Remove um nó e exibe a nova distribuição de chaves.
ring.RemoveNode("Shard-02")
fmt.Println("\nRemovendo Shard-02:\n")
for _, key := range keys {
node := ring.GetTenantNode(key)
fmt.Printf("Tenant: %s, Shard: %s\n", key, node)
}
ring.AddNode("Shard-04")
fmt.Println("\nAdicionando Shard-04:\n")
for _, key := range keys {
node := ring.GetTenantNode(key)
fmt.Printf("Tenant: %s, Shard: %s\n", key, node)
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
❯ go run main.go
Tenant: Petshops-Souza, Node: Shard-03
Tenant: Pizzarias-Carvalho, Node: Shard-01
Tenant: Mecanica-Dois-Irmaos, Node: Shard-02
Tenant: Padaria-Estrela-Filial-1, Node: Shard-01
Tenant: Padaria-Estrela-Filial-2, Node: Shard-03
Tenant: Padaria-Estrela-Filial-3, Node: Shard-02
Tenant: Hortifruti-Oba, Node: Shard-01
Tenant: Acougue-Zona-Leste, Node: Shard-02
Tenant: Acougue-Zona-Oeste, Node: Shard-03
Tenant: Acougue-Zona-Norte, Node: Shard-01
Removendo Shard-02:
Tenant: Petshops-Souza, Shard: Shard-03
Tenant: Pizzarias-Carvalho, Shard: Shard-01
Tenant: Mecanica-Dois-Irmaos, Shard: Shard-00 // Nova movimentação
Tenant: Padaria-Estrela-Filial-1, Shard: Shard-01
Tenant: Padaria-Estrela-Filial-2, Shard: Shard-03
Tenant: Padaria-Estrela-Filial-3, Shard: Shard-00 // Nova movimentação
Tenant: Hortifruti-Oba, Shard: Shard-01
Tenant: Acougue-Zona-Leste, Shard: Shard-00 // Nova movimentação
Tenant: Acougue-Zona-Oeste, Shard: Shard-03
Tenant: Acougue-Zona-Norte, Shard: Shard-01
Adicionando Shard-04:
Tenant: Petshops-Souza, Shard: Shard-03
Tenant: Pizzarias-Carvalho, Shard: Shard-01
Tenant: Mecanica-Dois-Irmaos, Shard: Shard-00
Tenant: Padaria-Estrela-Filial-1, Shard: Shard-01
Tenant: Padaria-Estrela-Filial-2, Shard: Shard-03
Tenant: Padaria-Estrela-Filial-3, Shard: Shard-00
Tenant: Hortifruti-Oba, Shard: Shard-04 // Nova movimentação
Tenant: Acougue-Zona-Leste, Shard: Shard-00
Tenant: Acougue-Zona-Oeste, Shard: Shard-03
Tenant: Acougue-Zona-Norte, Shard: Shard-01
Esse tipo de abordagem possibilita a implementação de diversos tipos de algoritmos de hashing. O ideal é testar o balancemanto como foi apresentado anteriormente para encontrar qual abordagem é mais eficiente para sua amostragem de sharding keys.
Sharding por Hashing e Gestão de Chaves
Uma forma de implementar um sharding baseado em hashing é tratar a distribuição e identificação da partição de forma cadastral, o que requer implementações adicionais na arquitetura do sistema. A principal vantagem de um algoritmo de hashing para distribuição de carga é que o cálculo é geralmente muito barato em termos computacionais. No entanto, em caso de redistribuição, o processo pode se tornar extremamente custoso.
Podemos imaginar uma arquitetura baseada em hashing onde a distribuição é executada apenas no momento da criação de uma nova sharding key, e as consultas subsequentes são realizadas por meio de uma API de consulta específica que exponha essas chaves de distribuição por meio de algum protocolo. Podemos presumir que um componente ou processo adicional de balanceamento e roteamento inteligente necessitaria ser implementado para garantir o encaminhamento correto da requisição para seu sharding específico.
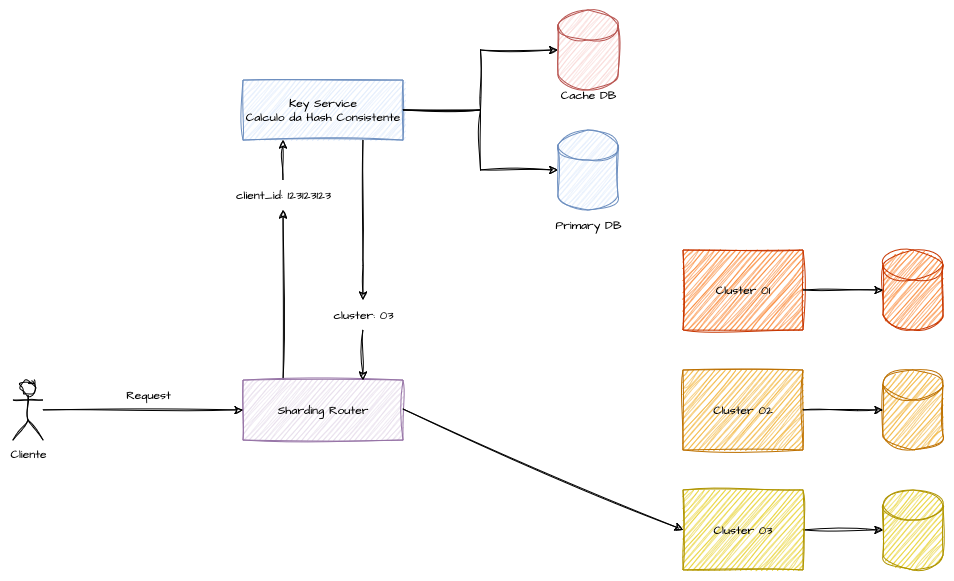
Esse tipo de estratégia, embora exija um maior esforço de engenharia, permite um gerenciamento mais manual e controlado da distribuição de clientes e usuários entre as partições. Além disso, ela possibilita o isolamento de clientes que geram hot partitions, alocando-os em shards segregados. Dessa forma, usuários que consomem muitos recursos podem ser isolados em infraestruturas dedicadas, prevenindo que seu impacto afete o desempenho geral do sistema.
Essa arquitetura, por exigir uma abordagem mais manual, também permite a implementação de demais técnicas de design, como implementação de caching, balanceamento de carga, replicação etc.
Segregação Avançada com Shuffle Sharding
O Shuffle Sharding é uma técnica de sharding avançado que combina sharding tradicional com replicação distribuída. O objetivo é criar subconjuntos embaralhados de shards para cada cliente, operação ou partição do sistema. O objetivo é reduzir drasticamente o blast radius pela falha eventual de um ou de um pequeno conjunto de shards, salvando os dados do cliente em mais de um shard, facilitando o isolamento de falhas, picos de carga e comportamentos maliciosos a um grupo mínimo de recursos, evitando que um único cliente afete toda a infraestrutura ou todos os clientes de um shard.
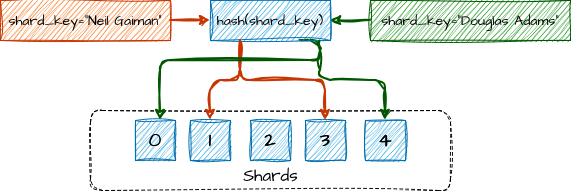
O modelo funciona como uma técnica híbrida de replicação e sharding. Cada operação é roteada para um shard primário, que equivale à golden source de dados do cliente, mas também é escrita em um ou mais shards secundários escolhidos pelo algoritmo de embaralhamento. Esse embaralhamento define o “shuffle-shard virtual” do cliente. No plano de consistência, o sistema pode operar em dois modos: consistência forte, quando o dado é confirmado apenas após escrita bem-sucedida em N shards desse conjunto (por exemplo, primário + réplicas), garantindo durabilidade imediata; consistência eventual, quando réplicas em shards secundários são atualizadas de forma assíncrona, priorizando latência baixa e throughput elevado.
Essa estratégia permite um equilíbrio entre resiliência, isolamento lógico e escalabilidade. Como cada cliente escreve em múltiplos shards embaralhados, qualquer falha fica restrita aos shards específicos que aquele cliente utiliza, e não ao cluster inteiro. Uma vez que um shard dedicado, ou compartilhado entre uma gama de clientes, falha, seus devidos fallbacks assumem a responsabilidade como primário, permitindo que os clientes segregados naquela partição sejam redirecionados para um shard de fallback com seus dados completos, ou muito próximos disso. Em resumo, o sistema pode tolerar mais falhas parciais, já que, ao envolver mais de um shard primário/secundário, a redundância garante leitura e escrita mesmo durante incidentes.
Obrigado aos Revisores
Referencias
Database Sharding for System Design Interview
Database Sharding Pattern for Scaling Microservices Database Architecture
Everything You Need to Know About Consistent Hashing
System Design Case Study - How Discord solved the Hot partition problem ?
System Design - Hashing Example
System Design - Hashing Murmur3
System Design - Distribuição de Hashing
System Design - Hashing Consistente
Sharding: Architecture Pattern
Shuffle Sharding: Massive and Magical Fault Isolation
System Design — Consistent Hashing
A Crash Course in Database Sharding
Murmur3 Hashing for Memcached Client
AWS - Partições e Distribuições de Dados
Sharding Distributed Databases: A Critical Review
