
System Design - Cell-Based Architecture

A arquitetura celular é um tema particularmente especial pra mim, olhando para o próximo passo de sistemas distribuídos de ambientes críticos; o tema é particularmente fascinante.
Esse foi o tema da minha pesquisa de mestrado, e depois de bastante tempo tentando consolidar o tema academicamente, decidi que tenho material o suficiente pra compor mais um capítulo dessa série de artigos com o tema.
Fui introduzido ao conceito há pelo menos 4 anos antes da escrita desse texto, através de uma iniciativa interna da empresa na qual trabalho, como uma proposta de alavancar os níveis de alta disponibilidade. Quando fui confrontado por “qual seria o tema da minha pesquisa de mestrado”, tive a ideia de alavancar um conceito emergente de mercado academicamente, e Arquitetura Celular e seus arredores serviram como uma luva. Baita desafio. Precisei consolidar conceitos já firmados em mercado e academia, como replicação, bulkheads, isolamento de falhas e demais tecnologias cloud native, para sustentar o termo.
Esse texto se baseia em uma alternativa mais leve e menos formal de abordar o tema.
Definindo a Arquitetura Celular
O modelo de Arquitetura Celular é um modelo de arquitetura descentralizada onde as capacidades de uma organização são estruturadas em uma rede de células independentes e autocontidas, como uma evolução do que entendemos pelo Bulkhead Pattern. Uma distinção importante que vale reforçar é que a Arquitetura Celular não é simplesmente uma técnica de particionamento horizontal sofisticado; ela é um pattern avançado na forma como modelamos domínios de falha.
O conceito que conecta os bulkheads à Arquitetura Celular em sistemas complexos é a proposta de criar fronteiras de isolamento de falhas, garantindo que o impacto de um erro seja restrito a um número limitado de componentes, sem afetar o restante do ecossistema, com o adicional de componentes de replicação de dados entre células para conter ainda mais o escopo de uma eventual falha isolada.
Unidades Celulares
Uma célula não é apenas um agrupamento técnico de serviços. Ela representa uma segmentação arquitetural explícita. Essa segmentação deve existir em múltiplas dimensões simultaneamente, como segmentação de execução (capacidade computacional e capacidade de escalabilidade horizontal isolada e autocontida), segmentação de persistência, isolando databases independentes, segmentação de observabilidade, isolando métricas, logs e traces segmentados por contextos celulares, segmentação de deploy, possuindo pipelines complexos de deployment para atualizar células sem impacto direto ao seu público, e segmentação de falha, onde temos blast radius mensuráveis e segmentados.
O compartilhamento de componentes globais como filas, tópicos, caches e databases compartilhados invalida esse isolamento. Caso exista a necessidade, por exemplo, tópicos de comando e resposta por domínio e API Gateways centralizados, eles devem ser intermediados por outros componentes celulares de borda.
Dimensão estrutural de uma célula
Uma célula é um compilado de um ou mais componentes (microsserviços, funções, databases, gateways, etc.) agrupados desde o design até a implementação e implantação. Estruturalmente, ela possui as características de isolamento e independência, onde cada célula, ou conjunto de células, é responsável por atender uma parcela determinada do público de forma autocontida, e toda comunicação externa deve ocorrer obrigatoriamente através de um gateway de borda ou proxy, que expõe APIs, eventos ou streams de dados.
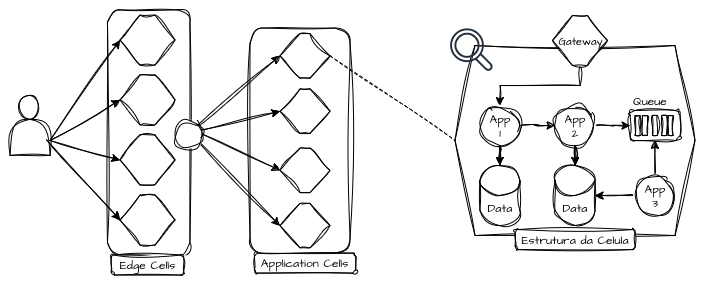
Os componentes internos comunicam-se de forma contínua intra-celular, enquanto dependências externas são mediadas pelo gateway da célula. Os componentes internos da célula só podem conhecer e se comunicar com componentes da própria célula, nunca de outra. Cada célula possui um nome e um identificador de versão único, facilitando o gerenciamento de dependências no ecossistema distribuído e resiliente.
Isolamento de estado
Uma característica determinística da implementação da arquitetura celular é que as células não compartilham estado com outras células de forma primária, apenas por replicação passiva. Em termos de persistência, uma célula pode conter seus próprios clusters de bancos de dados relacionais, sistemas de arquivos locais ou repositórios de dados necessários para cumprir sua função de negócio.
Cada unidade é independente e lida com um subconjunto específico das requisições totais do sistema e pode ter unidades passivas que assumem a liderança dos dados replicados em caso de falha da célula principal. No mais, cada célula deve possuir seus próprios microserviços, seus próprios bancos de dados, camadas de cache, consumidores de filas e eventos e demais componentes, de forma que sejam autocontidas e independentes entre si.
Esse modelo permite inclusive estratégias diferenciadas por célula. Uma célula pode operar com parâmetros de tuning diferentes, versões distintas de runtime ou até estratégias experimentais de feature rollout sem impactar o restante do ecossistema. Podemos isolar clientes de teste, pilotos e públicos sintéticos para experimentação antes de propagar versões para as demais células produtivas.
Estratégias de roteamento e direcionamento para células
O princípio fundamental é que toda requisição deve ser roteada para uma célula específica com base em uma chave estável, como customerId, accountId ou tenantId. Esse roteamento pode ocorrer em múltiplas camadas: DNS, API Gateway, proxies de borda ou service mesh.
É de grande importância para a solução que o algoritmo de roteamento seja determinístico, garantindo que requisições relacionadas ao mesmo estado sempre atinjam a mesma célula ativa. Em cenários de failover, o roteador deve ser capaz de redirecionar para a célula passiva correspondente sem que o cliente perceba a transição. Se um cliente hoje está na célula X, amanhã ele deve continuar na célula X, independentemente de picos de tráfego. Mudanças no algoritmo de hashing ou no número de células devem ser cuidadosamente orquestradas, pois podem causar remapeamento massivo (rehash storm).
Edge Cells - Células de Borda
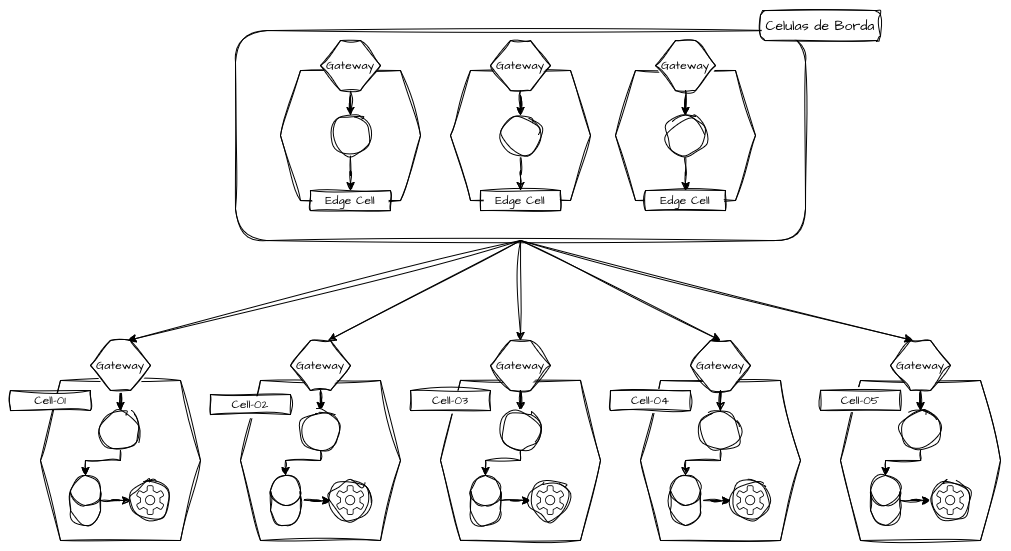
A camada de roteamento que intercepta as comunicações dos clientes e realiza o redirecionamento para a célula, ou grupo de células correto, é conhecida como “Edge Cells”, ou “Células de Borda”, uma camada de roteamento inteligente que deve ser capaz de realizar, da forma mais performática possível, a interceptação das solicitações, sejam elas vindas de qualquer protocolo conhecido, e redirecionar de maneira correta para a célula disponível responsável por atender a solicitação.
É preferível que esta camada seja o mais stateless possível, mas é possível que a mesma mantenha um estado cadastral em alguma camada de dados adicional. Aqui vamos além de um proxy básico como um Nginx, Envoy e Haproxy; é uma aplicação inteligente e agnóstica para uso celular que deve ser capaz de absorver alto tráfego e gerenciar o capacity global das camadas celulares de aplicação. Ela precisa ser extremamente resiliente e, paradoxalmente, altamente distribuída para não se tornar o novo ponto único de falha.
Células e segmentação de carga
A segmentação de carga na Arquitetura Celular é uma decisão estrutural de como os dados serão divididos e replicados entre as células. Já abordamos esse tema profundamente no capítulo de sharding e particionamento. Isso vai muito além de um particionamento horizontal de dispersar throughput entre vários estanques isolados de capacidade. Em arquiteturas tradicionais, o load balancer distribui requisições de maneira estatística através de vários algoritmos como round robin, least connection e afins, mas o estado permanece logicamente compartilhado.
Já em uma arquitetura celular, a segmentação é determinística e vinculada a uma chave de negócio estável, podendo ser tratada de forma cadastral e mapeamento intencional, ou distribuída estatisticamente através de algoritmos de hashing e hashing consistente. Isso significa que cada célula absorve um subconjunto fixo e determinístico da carga total, e essa distribuição não varia dinamicamente conforme a pressão momentânea do sistema; os mesmos clientes sempre serão atendidos pela mesma célula, ou conjunto de células.
Células Síncronas
No contexto síncrono, o roteamento ocorre no caminho crítico da requisição. HTTP, gRPC ou mesmo protocolos binários proprietários são direcionados para uma célula específica antes da execução do fluxo transacional.
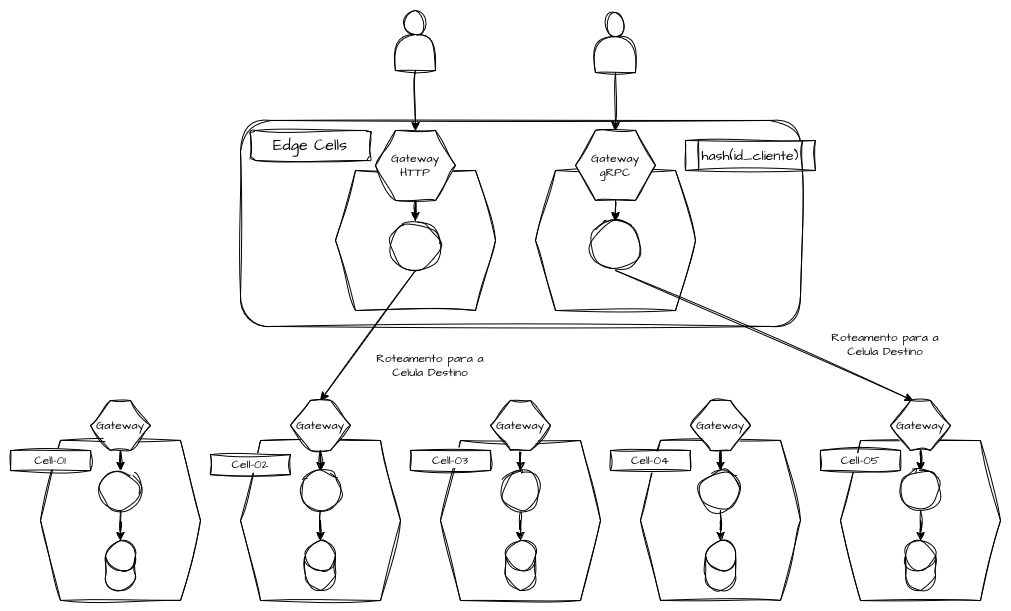
Aqui presumimos um gateway de borda que recebe todas as requisições de domínio. Esse gateway tem a função de atuar como um proxy de encaminhamento inteligente, como um roteador que sabe identificar deterministicamente, através de chaves conhecidas como ids de clientes, tenants, usuários, e direcionar para a célula, ou conjunto de células correspondente. Esse mecanismo de roteamento e proxy pode operar baseado em DNS, Hashing Consistente, roteamento via Service Mesh ou de forma cadastral, consultando fontes externas para determinar onde o cliente será direcionado.
Em cenários síncronos, a latência da célula é diretamente percebida pelo usuário. Portanto, cada célula deve ser dimensionada como unidade autônoma de performance. CPU, memória, conexões de banco, thread pools e limites de rate limiting devem ser configurados por célula, não globalmente. Cada célula precisa ter sua capacity isolada e independente.
Células Assíncronas
Quando entramos no domínio assíncrono, a arquitetura celular assume ainda mais capacidade e estratégia de desacoplamento estrutural. Em cenários de arquitetura celular que são acionadas por eventos em tópicos ou mensagens em filas, cada célula consome apenas as mensagens e eventos pertencentes a seu contexto.
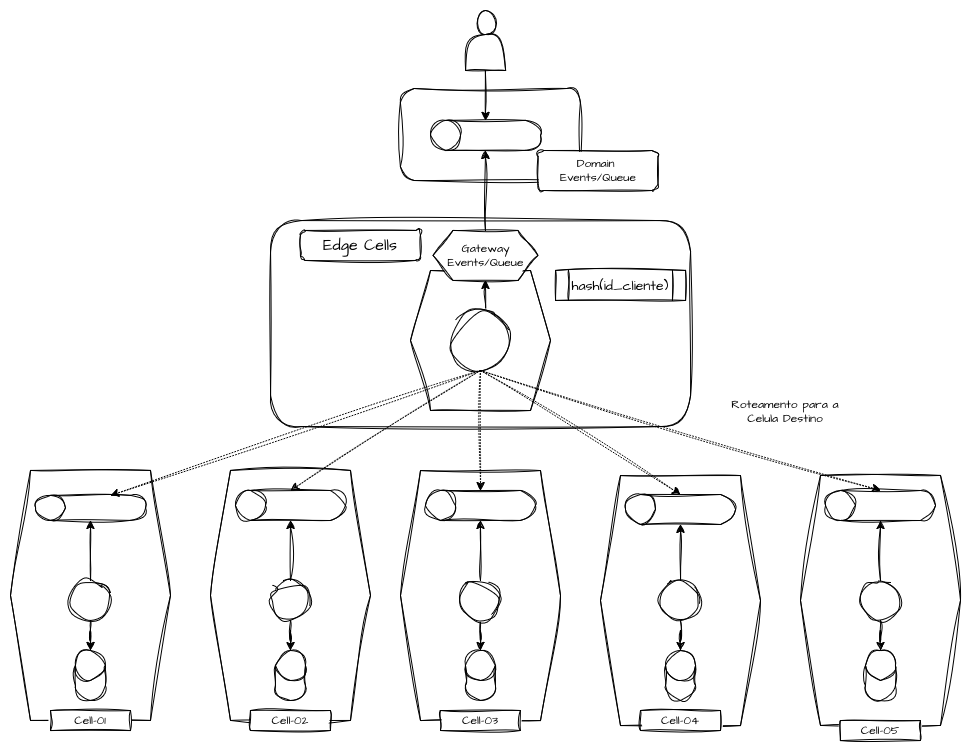
Podemos presumir um consumidor de borda que consome alguma fila ou tópico de domínio e republica as mensagens ou eventos para tópicos e filas segmentados da célula, atuando como um filtro roteador da mensagem em contexto para sua célula específica, que por sua vez só conhece seus próprios mecanismos de mensageria.
A consequência é a eliminação do acoplamento temporal entre células. Uma célula pode atrasar processamento, sofrer backpressure ou mesmo ficar indisponível sem bloquear o restante do sistema. Ao segmentar tópicos e filas por célula, eliminamos o risco de backpressure global. Uma célula pode acumular backlog sem afetar a taxa de processamento das demais.
Replicação Celular
No modelo celular, a replicação é direcionada para a criação de células passivas que atuam como espelhos de células ativas nos requisitos de dados. Cada célula é projetada como uma unidade autocontida, incluindo todos os componentes de execução e armazenamento necessários para sua operação independente; porém, podemos assumir conjuntos de células passivas que recebem os dados de células ativas, prioritariamente com consistência eventual e replicação assíncrona através de componentes adicionais, ou com consistência forte, criando um modelo transacional de “Two-Phase Commit”, garantindo que todas as células participantes da replicação celular irão confirmar a transação ou ela será inteiramente abortada.
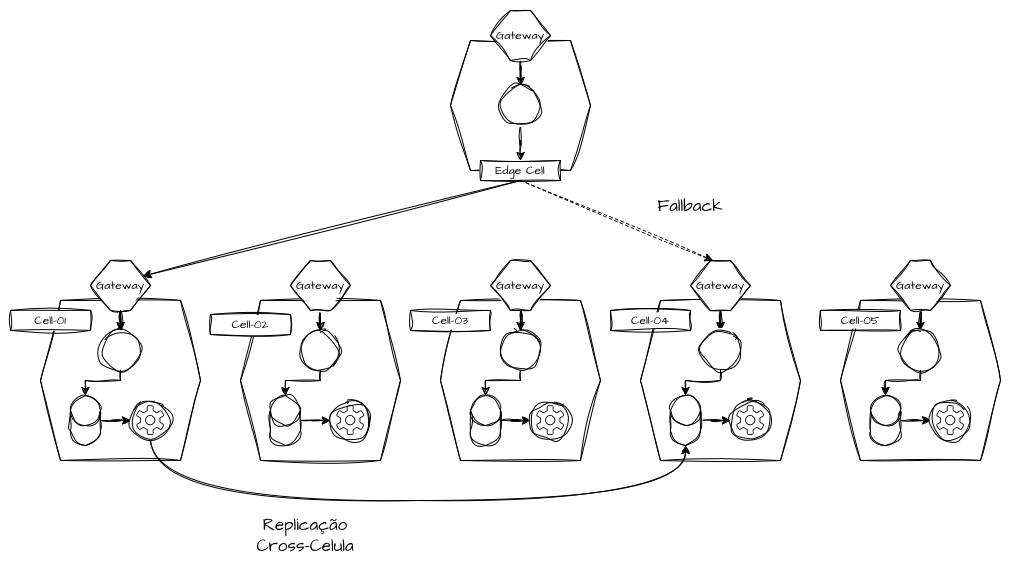
O foco na replicação para células passivas garante que falhas críticas como bugs, erros de deploy ou as chamadas poison pill requests (requisições corrompidas que derrubam o serviço) sejam contidas dentro da fronteira da célula afetada, mas que o cliente seja redirecionado para uma célula passiva para a qual seus dados estejam sendo replicados de forma transparente. Como cada célula atende a apenas um subconjunto das requisições totais, assumindo um roteamento forte por chave de partição, a perda de uma célula principal não resulta em um apagão da experiência do cliente.
Isso muda completamente a forma como modelamos risco sistêmico. Em vez de perguntar: “Qual o impacto da falha de um shard?”, passamos a perguntar: “Qual a probabilidade de um cliente estar alocado exatamente no subconjunto de células que falhou simultaneamente?”.
Replicação Assíncrona entre Células
A replicação assíncrona entre células de uma arquitetura desse tipo é o modelo mais comum dentro de arquiteturas celulares, principalmente quando podemos abrir mão de uma consistência forte nos critérios de alta disponibilidade e tolerância a falhas. Nesse modelo, a célula ativa é a fonte primária de escrita, enquanto células passivas recebem atualizações de estado por meio de streams de eventos, logs de mudança ou filas assíncronas.
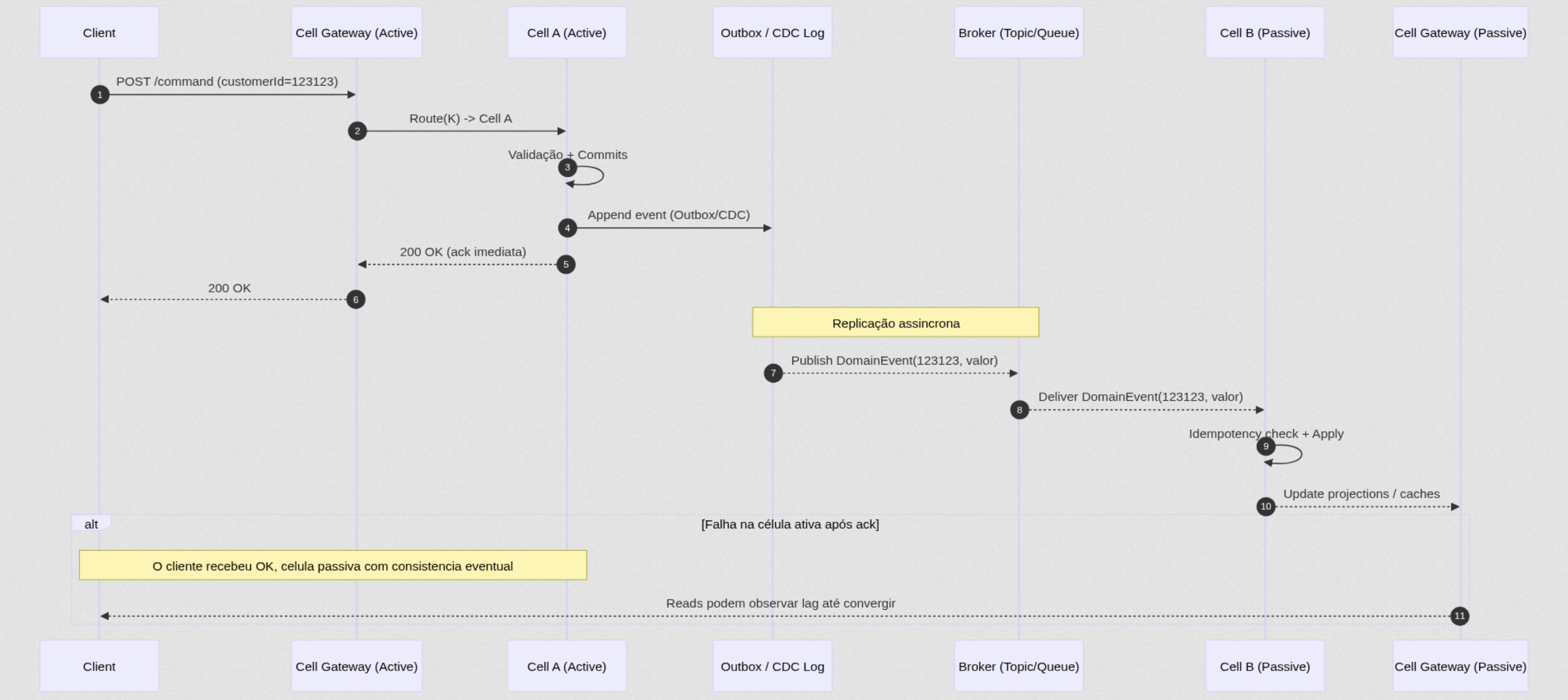
O custo desse modelo é a aceitação da consistência eventual. O objetivo dessa estratégia é a propagação dos dados entre as células ativas e passivas fora do que consideramos o “caminho crítico” transacional do cliente, permitindo que as operações da célula continuem atendendo com baixa latência, mesmo sob carga elevada e saturação da célula. Em uma falha súbita da célula ativa, a célula passiva pode assumir com um pequeno atraso de estado.
Replicação Consistente entre Células
A replicação consistente entre células surge quando o domínio de negócio não tolera divergência de estado, mesmo que temporária, em uma eventual mudança de responsabilidade entre uma célula ativa e passiva. Nesses cenários, a arquitetura celular precisa incorporar mecanismos de coordenação distribuída, como Two-Phase Commit (2PC) ou variações mais modernas de consenso, para garantir um estado transacional em todas as células do conjunto do contexto.
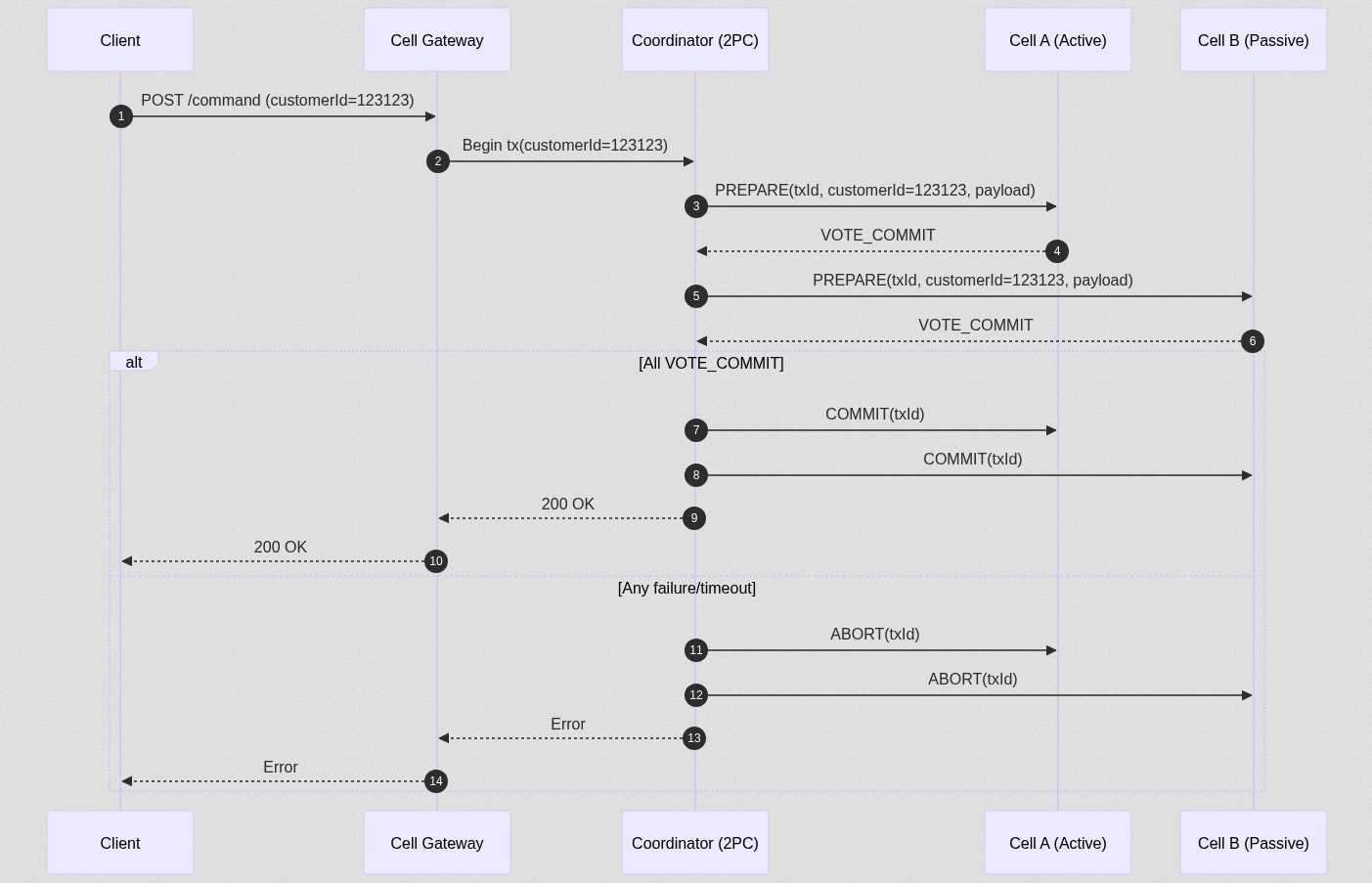
Esse modelo assume mais complexidade e riscos, onde múltiplas células participam de uma transação distribuída, garantindo que o estado só seja considerado confirmado quando todas as células envolvidas reconhecem a operação e, em caso de qualquer participante falhar, a transação inteira é abortada, preservando uma integridade global.
Embora conceitualmente elegante, esse modelo introduz acoplamento temporal entre células, aumenta a latência e reduz a capacidade de isolamento absoluto de falhas. Por isso, sua aplicação deve ser extremamente criteriosa, restrita a fluxos realmente críticos e evitando um volume que possa desencadear uma saturação em cascata em todas as células participantes do conjunto.
Replicação e Shuffle Sharding
A combinação de arquitetura celular com shuffle sharding representa uma das estratégias mais eficientes para reduzir impacto sistêmico em larga escala e aplicar a replicação cross-celular.
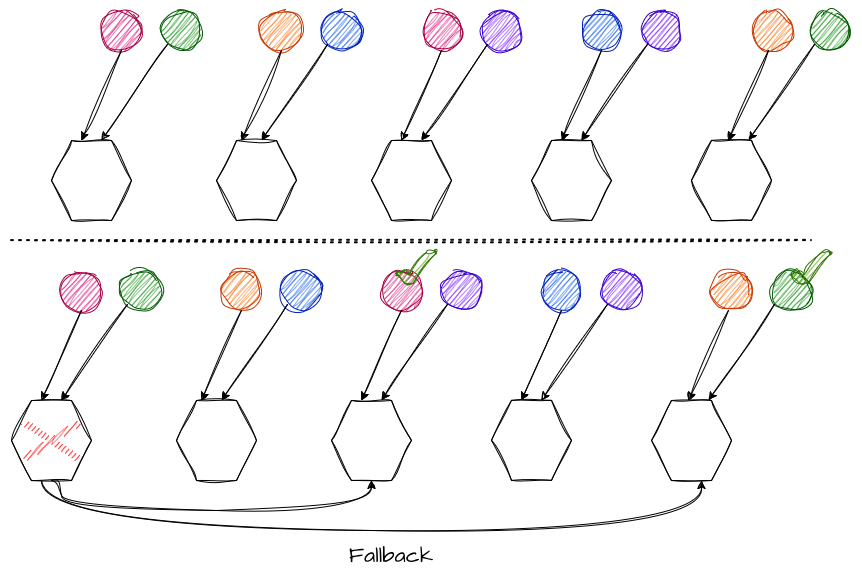
Em vez de associar cada cliente ou tenant a uma única célula fixa, o shuffle sharding mapeia cada entidade a um subconjunto estável de células, calculado por hashing consistente. Assim, um cliente interage apenas com um pequeno grupo de células, e não com o sistema inteiro, assumindo que seus dados estão replicados entre todas elas de forma consistente ou assíncrona.
Quando uma célula falha, apenas os clientes cujo conjunto inclui aquela célula são afetados. Os demais continuam operando normalmente. Isso reduz drasticamente o blast radius estatístico, mesmo em sistemas com milhares ou milhões de clientes. Quando aplicamos o shuffle sharding, os clientes afetados podem ser redirecionados para uma célula ao lado, para a qual seus dados foram replicados; dessa forma, só começamos a calcular o blast radius a partir da falha de duas ou mais células (dependendo da quantidade de replicação cross-celular dos dados), e reduzimos a porcentagem de impacto para a probabilidade de os clientes estarem em todo o conjunto de células indisponíveis.
Replicação e Blast Radius
A principal característica da arquitetura celular, quando combinada com replicação, é a previsibilidade do impacto de falhas. Como vimos no exemplo dos Bulkheads, se uma carga de trabalho é distribuída igualmente entre 10 shards e uma delas falha, 90% dos usuários ou recursos permanecem operacionais e inalterados. Quando confrontamos com a proposta da Arquitetura Celular com replicação, o número de bulkheads ou shards computacionais, se presumirmos uma segmentação uniforme de carga, impacta diretamente a porcentagem de indisponibilidade em caso da falha de uma parcela isolada dessa segmentação.
Do ponto de vista matemático, se temos N células e roteamento uniforme por hashing consistente, cada célula tende a absorver aproximadamente 1/N da carga total. Isso permite modelar blast radius como função direta da cardinalidade de células.
| Bulkheads | Blast Radius | Disponibilidade |
|---|---|---|
| 1 | 100% | 0% |
| 2 | 50% | 50% |
| 3 | 33% | 66% |
| 5 | 20% | 80% |
| 10 | 10% | 90% |
| 20 | 5% | 95% |
| 50 | 2% | 98% |
| 100 | 1% | 99% |
A literatura clássica de sistemas distribuídos mostra que a replicação é um mecanismo-chave para garantir disponibilidade e continuidade operacional, permitindo que o sistema mantenha o serviço mesmo diante de falhas de nós ou partições de rede.
Do ponto de vista conceitual, células podem ser compreendidas como domínios de falha isolados, alinhados ao padrão arquitetural de bulkheads, cujo objetivo é compartimentalizar o impacto de incidentes. Quando trabalhamos com a replicação celular e temos a capacidade de redirecionar nossos clientes para células passivas que contenham seus dados, conseguimos adicionar ainda mais camadas de disponibilidade na experiência do cliente. O impacto de uma partição indisponível deixa de ser a métrica estatística apropriada, pois um shard indisponível pode ser suprido por sua versão passiva. Nesse caso, em níveis de replicação, passamos a estimar o impacto a partir de um conjunto maior de células indisponíveis, trabalhando com a probabilidade de um cliente estar alocado no conjunto todo que falhou.
O cálculo se baseia em células em status de falha (f) dividido pelo número total de células (N), elevado ao número de réplicas virtuais (k) do Shuffle Sharding.
\begin{equation} P(\text{impacto}) \approx \left( \frac{f}{N} \right)^k \end{equation}
Em exemplo, presumindo que trabalhamos com 20 células, 2 réplicas em shuffle, onde o mesmo dado de um cliente é alocado em 2 células, em caso de downtime de 2 células aleatórias, conseguimos calcular a probabilidade de um mesmo cliente estar alocado justamente nessas 2 células. Nesse caso, 1% de probabilidade. Comparado ao exemplo dos bulkheads, onde para ter 1% de impacto determinístico, precisaríamos de 100 bulkheads ou shards computacionais para ter o mesmo resultado de 20 células com fator de replicação de 2.
\begin{equation} P(\text{impacto}) \approx \left( \frac{2}{20} \right)^2 \end{equation}
\begin{equation} P(\text{impacto}) = \text{1%} \end{equation}
Quando ajustamos o número de réplicas em shuffle, diminuímos ainda mais a probabilidade de impacto, pois para existir um downtime total de um cliente, precisaríamos presumir uma quantidade cada vez maior de células inativas.
| Células Totais | Células Indisponíveis | Réplicas em Shuffle | Probabilidade de Impacto do Cliente |
|---|---|---|---|
| 20 | 2 | 2 | 1% |
| 20 | 3 | 3 | 0.33% |
| 20 | 5 | 5 | 0.009% |
Referências
BR AWS re:Invent 2022 - Camada Zero: A real-world architecture framework (PRT268)
A Crash Course on Cell-based Architecture
Mastering Cell-Based Architecture for Modern Enterprises
Cell-Based Architecture Reference
Cloud Native Middleware: Domain-Driven Design, Cell-Based Architecture, Service Mesh, and More
Reference Architecture for Agility, Version-0.9
What is a cell-based architecture?
Guidance for Cell-Based Architecture on AWS