
System Design - Padrões de Resiliência

Nesse capítulo, iremos revisitar praticamente tudo o que já foi visto e dar pequenos spoilers de capítulos que ainda virão, porém com algumas óticas adicionais. A maioria, ou praticamente todos os tópicos, já foram tratados em capítulos anteriores, o que mudará aqui será somente a perspectiva. Então, caso você tenha sentido falta de uma maior profundidade conceitual, recomendo fortemente voltar alguns passos atrás e reler os materiais.
Este material talvez seja um dos mais importantes desta série, porque, além de tratar de um dos temas centrais em sistemas distribuídos, apresenta minha proposta principal, que é entender conceitualmente algo e ser capaz de remoldar esse conceito para diferentes pontos de vista. Veremos que, a partir dessa linha, tudo o que veremos será abordado sob a ótica da resiliência, mas, mesmo assim, não perderá em nada seu propósito original de implementação.
Esta talvez seja a lição mais valiosa pela qual estou me esforçando para transmitir neste livro: um grande exercício para mim, como escritor, e para você, como leitor.
Definindo Resiliência
Resiliência é um termo muito comum em arquitetura e engenharia de software, que refere-se à capacidade de sistemas, processos e componentes de suportar uma ampla variedade de cenários de falhas e manter sua operação, seja de forma total ou parcial. Esse conceito está diretamente relacionado a diversas disciplinas e tópicos de engenharia, sempre com o objetivo de elevar os níveis de eficiência e segurança operacional das funcionalidades das aplicações e das jornadas dos clientes dentro dos sistemas. Se olharmos com muito critério, tudo desenvolvido e implementado com a devida qualidade pode ser uma prática de resiliência.
A preocupação com resiliência é recorrente no dia a dia dos times de desenvolvimento e de operações responsáveis por funcionalidades críticas, e a maneira mais simples de explicá-la, de forma rotineira, é dizendo que, quando algum serviço ou ponto específico do sistema falhar, ele deve possuir mecanismos para contornar a situação e minimizar o impacto no funcionamento geral.
Resiliência e Disponibilidade
Embora os termos resiliência e disponibilidade sejam muito próximos e frequentemente caminhem juntos, seus conceitos possuem diferenças fundamentais e não devem ser confundidos. A disponibilidade pode ser descrita em dois cenários principais: o primeiro mede quantas solicitações enviadas ao sistema foram processadas com sucesso, enquanto o segundo mede o tempo em que o sistema permaneceu indisponível em determinados períodos.
A resiliência, por sua vez, é o conjunto de estratégias que usamos para manter essa disponibilidade.
Resumindo, quanto mais robustos forem os mecanismos de resiliência, mais tolerante a falhas será o sistema e, consequentemente, maior será sua disponibilidade para os usuários.
Neste capítulo, abordaremos diversos cenários e mecanismos de resiliência e, principalmente, revisitaremos outros padrões e conceitos já discutidos, agora com foco em garantir maior resiliência e disponibilidade.
Métricas de Resiliência e Disponibilidade
Uma grande variedade de métricas pode ser utilizada para avaliar a disponibilidade e resiliência de aplicações. Muitas delas já foram discutidas em capítulos anteriores, como em Performance, Capacidade e Escalabilidade.
Métrica de Disponibilidade de Uso
A forma mais comum de medir a disponibilidade de sistemas é tomando como régua seu uso. Podemos calcular essa disponibilidade usando como base a taxa de erros dos mesmos. Isso basicamente consiste em dividir dois contadores: um referente à quantidade de erros ocorridos dentro do período e outro representando a soma total das requisições que ocorreram, independentemente do resultado (sucesso ou falha). Isso nos diz, de maneira clara e simples, qual a porcentagem de vezes que aquele sistema foi requisitado e não respondeu de acordo.
\begin{equation} \text{Taxa de Erros} = \left( \frac{\text{Número de Erros}}{\text{Número Total de Tentativas ou Eventos}} \right) \times 100 \end{equation}
Por exemplo, em uma API monitorada, podemos observar que, dentro de 1 hora, houve um total de 1000 requisições, das quais 40 resultaram em erros causados pelo servidor. Dividimos o número de erros pelo total de requisições e multiplicamos por 100 para gerar uma porcentagem mais intuitiva. Nesse caso, a taxa de erros foi de 4% durante o período.
\begin{equation} \text{Taxa de Erros} = \left( \frac{\text{40}}{\text{1000}} \right) \times 100 \end{equation}
\begin{equation} \text{Taxa de Erros} = {\text{4%}} \end{equation}
A partir da taxa de erros, a disponibilidade pode ser calculada subtraindo esse valor de 100%. Como no exemplo obtivemos 4% de erros, a disponibilidade da aplicação foi de 96%.
\begin{equation} \text{Disponibilidade} = \left( \text{100} - {\text{Taxa de Erros}} \right) \end{equation}
\begin{equation} \text{Disponibilidade} = \left( \text{100} - {\text{4}} \right) \end{equation}
\begin{equation} \text{Disponibilidade} = {\text{96%}} \end{equation}
Esse método é utilizado para medir a disponibilidade com base no uso. Ele é especialmente adequado para indicar quantas chamadas resultaram em sucesso ou falha. Essa é uma estratégia simples e faz sentido para sistemas com um modelo de uso inconstante ou muito variado, onde não é prático medir a disponibilidade baseada em tempo.
Métrica de Disponibilidade de Uptime
O modelo mais tradicional para medir a disponibilidade considera o tempo que o sistema permaneceu disponível, conhecido como Uptime ou Tempo de Atividade. O tempo de “indisponibilidade” pode ser total ou parcial, dependendo da duração de um incidente. Assim, se o sistema estiver sujeito a um alarme crítico ou incidente operacional, esse tempo até a resolução é desconsiderado no cálculo da disponibilidade.
A equação para calcular o uptime, ou tempo de atividade, é simples: basta dividir o tempo operacional pelo tempo total de atividade esperado. O tempo operacional é calculado subtraindo-se o tempo total de atividade pela soma de todos os períodos de downtime, incidentes e afins.
\begin{equation} \text{Tempo Operacional} = \left( \text{Tempo Total} - (\text{Incidente 1} + \text{Incidente 2} + \text{…}) \right) \end{equation}
\begin{equation} \text{Uptime} = \frac{\text{Tempo Operacional}}{\text{Tempo Total}} \times 100\% \end{equation}
Por exemplo, suponha que em um mês, com uma média de 43.200 minutos, houve um total de 3 horas de downtime, correspondendo a 180 minutos. Subtraímos o tempo de downtime do tempo total do período para obter o Tempo Operacional, resultando em 43.020 minutos de atividade.
\begin{equation} \text{Tempo Operacional} = \text{43.200} - \text{180} \end{equation}
\begin{equation} \text{Tempo Operacional} = \text{43.020} \end{equation}
Sabendo o Tempo Operacional do sistema, dividimos esse valor pelo tempo total para obter a porcentagem de disponibilidade no período, resultando em 99,58% de Uptime.
\begin{equation} \text{Uptime} = \frac{\text{Tempo Operacional}}{\text{Tempo Total}} \times 100\% \end{equation}
\begin{equation} \text{Uptime} = \frac{\text{43.020}}{\text{43.200}} \times 100\% \end{equation}
\begin{equation} \text{Uptime} = {\text{99,58%}} \end{equation}
Essa é a abordagem mais tradicional para metrificar a disponibilidade, especialmente em sistemas onde não é viável medir diretamente pelo uso. Essa abordagem é comumente utilizada em Status Pages de sistemas abertos, serviços de data centers de clouds públicas e privadas, entre outros.
Blast Radius
O Blast Radius é um conceito originalmente bélico que descreve, de forma estimativa, as zonas afetadas pelo impacto de uma explosão em uma determinada região. Esse conceito propõe estimar, em mapas do mundo real, quais áreas dentro do raio de detonação de certos tipos de explosivos seriam afetadas pelo fogo direto, deslocamento de ar, radiação térmica, entre outros fatores.
Embora tenha origens militares e aparente contradição, o conceito também é utilizado em discussões de arquitetura de sistemas e engenharia de confiabilidade para estimar o impacto da falha de um componente em um sistema distribuído. Esse termo é aplicado para identificar pontos críticos e oportunidades de melhoria na resiliência e sugere, por meio de exercícios de simulação de falhas ou “perguntas provocativas” em revisões arquiteturais, estimar os impactos das falhas nesses pontos críticos. A partir dessas estimativas, busca-se discutir como minimizar os danos nesses cenários por meio de fallbacks, aplicação de estratégias e implementação de padrões de resiliência, entre outros.
Os questionamentos utilizados para estimar esses danos podem vir na forma de “Se o componente X parar, o que acontece?”, avançar para “Se esse componente ficar indisponível, outro continuará funcionando?” e até perguntas como “Se essa API cair, o que deixa de funcionar? O que continua funcionando parcialmente? O que permanece funcionando normalmente? Em quanto tempo me recupero se ela voltar? Gero inconsistências em alguma parte do meu processo?”. O ponto que destaco é que essas “perguntas provocativas” devem ser feitas sempre que possível. É essencial criar um ambiente seguro e aberto para que esses questionamentos ocorram sem barreiras ou cerimônias. Considero essa prática uma das mais dinâmicas e eficientes para partir do zero a algo concreto em uma revisão arquitetural de resiliência e recomendo sua experimentação a todos.
Estratégias e Patterns de Resiliência
A seguir, catalogaremos não todas, mas as principais estratégias e padrões de engenharia que ajudam a contornar falhas e adicionar diversos níveis de resiliência em diferentes cenários conhecidos. O objetivo é expandir nossa “caixa de ferramentas” com opções arquiteturais inteligentes e aplicáveis. Muitos desses conceitos já foram apresentados anteriormente; a ideia é reaproveitá-los agora com foco em características de resiliência e disponibilidade.
Replicação de Serviços, Balanceamento de Carga e Healthchecks
A principal e mais simples estratégia de resiliência é revisitar os conceitos de Distribuição e Balanceamento de Carga e Escalabilidade Horizontal. Escalar e distribuir a carga é, talvez, a estratégia que mais reflete resiliência e desempenho a curto prazo. Mecanismos de balanceamento devem operar em conjunto com mecanismos de auto scaling, para que seja possível adicionar e remover réplicas sob demanda com a máxima segurança e disponibilidade, permitindo que as aplicações se adaptem a cargas variáveis.
As aplicações, independentemente de seu protocolo principal, devem expor URLs de healthcheck que reflitam seu estado e, caso ocorra alguma falha ou mau funcionamento, essa URL deve indicar o status por meio de códigos de resposta que possam ser monitorados periodicamente.
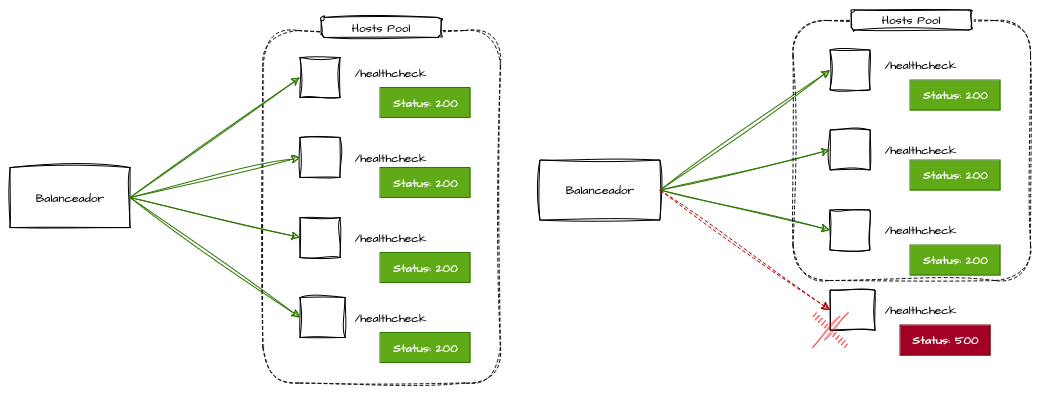
Os balanceadores também devem verificar essas URLs regularmente para liberar ou restringir o tráfego às réplicas do pool, de acordo com as respostas obtidas nos healthchecks. Ou seja, se uma réplica começar a responder com erros ou não responder dentro do tempo limite, o balanceador deve considerá-la inativa ou incapaz de receber tráfego.
Os balanceadores são responsáveis por garantir o paralelismo externo de requisições síncronas, a fim de dispersar o tráfego das chamadas e maximizar o aproveitamento de recursos, aumentando, assim, a resiliência e reduzindo a probabilidade de falhas graves decorrentes da indisponibilidade de um único host do pool.
Idempotência
Idempotência é, talvez, o passo mais importante para criar sistemas resilientes em ambientes distribuídos. A implementação de padrões de idempotência permite que várias outras estratégias sejam implementadas com segurança. Como abordado anteriormente ao detalhar as possibilidades de comunicação síncrona, como APIs REST, o conceito deve funcionar bem independentemente do modelo e do protocolo utilizados. O objetivo é permitir que a mesma operação seja executada várias vezes, sempre produzindo o mesmo resultado, sem gerar efeitos indesejados, como duplicidades.
Essa capacidade possibilita que, durante falhas ocasionais de rede, quedas de réplicas, manutenções programadas ou intermitências inesperadas, a solicitação possa ser repetida a qualquer momento para sincronizar domínios, receber respostas não retornadas, recuperar-se de erros, entre outras situações.
Chaves de Idempotência
O processo de idempotência precisa se apoiar em dados específicos da requisição para garantir que ela não seja duplicada ou cause efeitos indesejados. Normalmente, escolhem-se chaves de idempotência que identifiquem a requisição, o comando ou a intenção de domínio, permitindo verificar se a operação já foi executada. Esse controle é conhecido como chave de idempotência.
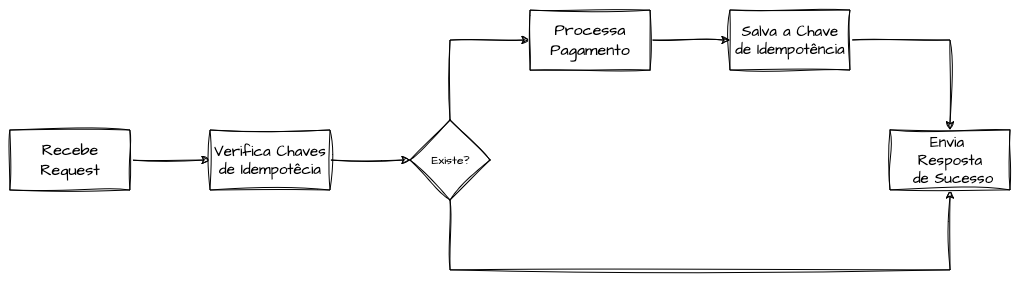
Vamos ilustrar com uma API de pagamentos, em que o cliente realiza uma solicitação de cobrança por diferentes métodos de pagamento. Se o cliente reenviar a solicitação devido a uma falha — no cliente ou no servidor —, a operação idempotente garante que o valor seja cobrado apenas uma vez. Para isso, o cliente envia, via cabeçalhos HTTP ou parâmetros, uma chave de idempotência única, que é verificada e armazenada antes do processamento. Essa chave pode ser gerada no cliente ou derivada de valores presentes na requisição.
Esse padrão assegura que a mesma solicitação seja repetida diversas vezes de forma segura. Sem idempotência, o cliente poderia ser cobrado múltiplas vezes, gerando inconsistências e falhas financeiras graves.
Timeouts
Os timeouts definem um tempo limite para determinadas operações, atuando como método preventivo para evitar que o sistema fique preso em chamadas de longa duração. Eles podem interromper processos tanto no cliente quanto no servidor. Os timeouts permitem que os sistemas detectem e contornem erros de forma rápida e dinâmica, evitando que, durante uma degradação de desempenho em dependências, múltiplas conexões permaneçam abertas aguardando indefinidamente, o que poderia resultar em falhas em cascata por sobrecarga.
Ao projetar sistemas resilientes, é desejável que eles sejam performáticos, lidem com falhas de forma eficiente e acionem mecanismos de fallback o mais rapidamente possível. Quando configurados de forma inteligente e adequada ao contexto, os timeouts tornam isso viável, geralmente por meio de parametrizações simples em bibliotecas e componentes.
Um exemplo importante é o Timeout de Conexão, ou Connection Timeout, que define o tempo máximo para estabelecer uma conexão entre cliente e servidor, independentemente do protocolo. Esse timeout evita que o cliente aguarde indefinidamente por uma conexão que pode jamais ser estabelecida, problema comum ao tentar conexões TCP com bancos de dados sobrecarregados ou servidores HTTP degradados.
Outro padrão comum é o Timeout de Leitura e Escrita, que determina limites de espera para receber ou enviar dados a um serviço específico. Esses timeouts entram em ação quando a conexão já foi estabelecida, mas o sistema enfrenta demora excessiva para obter uma resposta.
Além disso, existe o Idle Timeout, que especifica o tempo máximo que uma conexão pode permanecer ociosa antes de ser encerrada. Esse timeout evita que clientes mantenham conexões de longa duração sem atividade, liberando recursos do sistema.
Estratégias de Retry (Retentativas)
As estratégias de retry, ou retentativas, referem-se ao ato de refazer uma requisição diante de uma falha em uma dependência. Assim como o balanceamento de carga, trata-se de uma estratégia simples, com benefícios de curto prazo. Existem diferentes modelos de retentativas, mas todos compartilham o princípio de superar indisponibilidades temporárias, falhas ocasionais e intermitências em dependências ou na rede.
Independentemente da estratégia escolhida, é fundamental que os retries sejam implementados de forma criteriosa e responsável e que os sistemas que recebem essas retentativas adotem mecanismos sólidos de idempotência, permitindo repetir a requisição sem gerar efeitos adversos ou duplicidades.
Retries Imediatos em Memória
Os retries imediatos são executados em memória, geralmente na mesma thread da tentativa original. Esse é o tipo mais simples de retentativa, comum em clientes HTTP configuráveis e em bibliotecas de consumo de serviços específicos.
Imagine uma aplicação que dependa diretamente de outra, comunicando-se via gRPC. Se ocorrerem intermitências de disponibilidade no endpoint do servidor durante a chamada, podemos definir uma lógica de retentativa que estabelece um número máximo de tentativas sequenciais, reenviando a requisição até obter uma resposta válida.
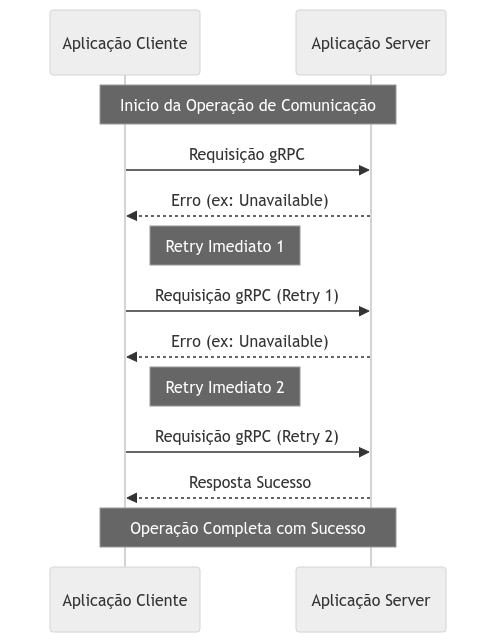
É extremamente importante que o número máximo de tentativas seja adequado ao cenário, pois tentativas excessivas podem agravar ainda mais a indisponibilidade da dependência. Nos próximos tópicos, abordaremos estratégias derivadas que ajudam a contornar esses casos.
Essa é a estratégia mais simples de retentativas síncronas. Apesar de apresentar limitações — como operar em memória (e, se o runtime for encerrado, as tentativas não serão completadas) ou executar-se de forma sequencial e imediata (o que pode gerar ou agravar gargalos momentâneos de capacidade) —, essa abordagem continua extremamente útil e resolve a maior parte dos casos.
Retries Assíncronos
Uma das formas mais conhecidas e eficientes de implementar retentativas é por meio de processos assíncronos. Essa estratégia pode assumir diversas variações. A comunicação assíncrona, por si só, já oferece níveis adicionais de resiliência ao permitir um desacoplamento facilitado. Quando combinada com técnicas de retentativa, torna-se uma solução poderosa e extensível.
Um exemplo é o uso de retentativas em cenários em que as requisições começam de forma síncrona, mas são concluídas de forma assíncrona. Nesse caso, o sistema pode trocar o status code definitivo — por exemplo, substituir 201 Created por 202 Accepted — para indicar que a solicitação não foi concluída imediatamente, mas será processada e retentada sem que o cliente precise aguardar.
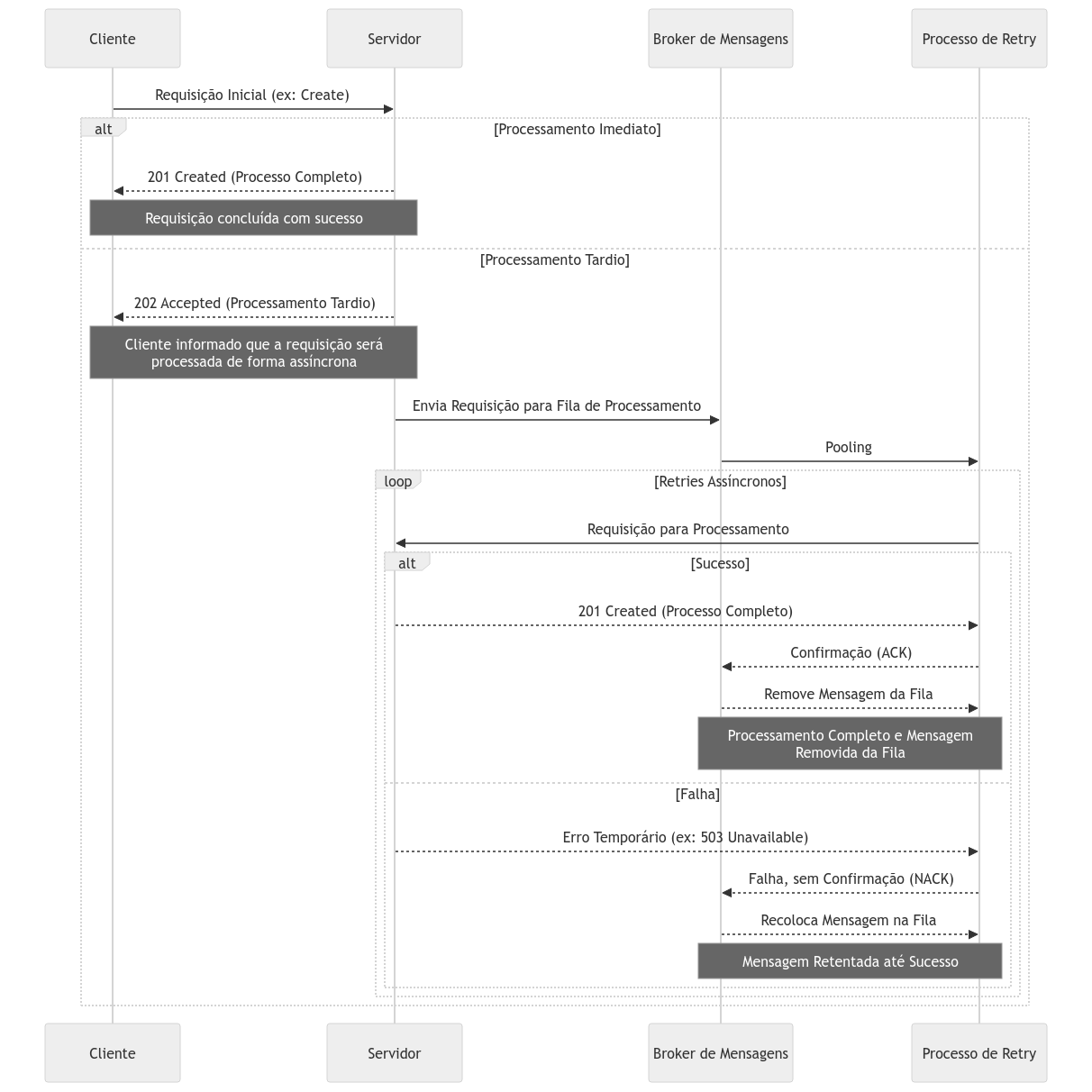
Quando possível, essa abordagem é uma ótima alternativa de fallback para o fluxo principal, permitindo armazenar requisições que falharam durante um período de indisponibilidade e completá-las posteriormente.
Outra variação é aplicada a processos que já são naturalmente assíncronos, ou seja, aqueles que começam e terminam dentro de brokers de mensagens ou eventos. Nesse modelo, o produtor publica a mensagem e conta com mecanismos de retentativa; ele receberá a resposta apenas após a conclusão do processamento.
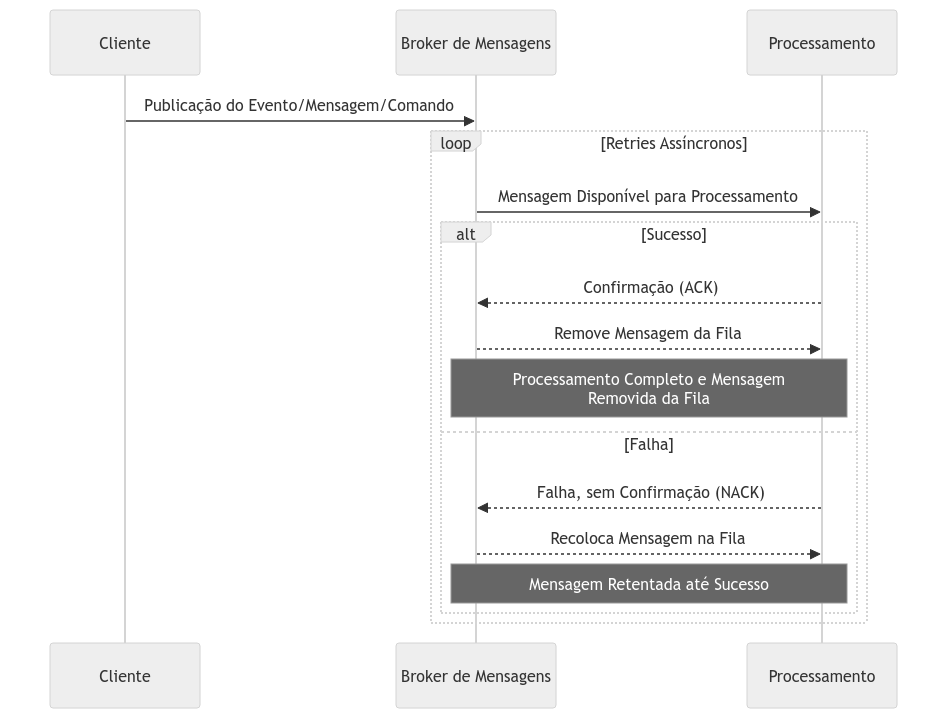
Nessa implementação, as requisições são enfileiradas em uma fila ou tópico de processamento, que será consumido por um componente especializado em realizar a retentativa e retomar o fluxo. Normalmente, brokers de mensagens já oferecem retentativas nativas: se não recebem um ack de confirmação do consumidor, reencaminham a mensagem para a fila. Isso torna a abordagem de retentativa um mecanismo extremamente robusto, apesar de sua complexidade e dos componentes adicionais envolvidos.
Retries com Backoff Exponencial
Em vez de realizar retentativas consecutivas em intervalos fixos, existe a estratégia de backoff exponencial para retentativas. Nessa abordagem, o tempo de espera entre as tentativas aumenta de forma exponencial (por exemplo: 1 s, 2 s, 4 s, 8 s, 16 s etc.), ajudando a aliviar a pressão no sistema alvo da retentativa e a reduzir o risco de sobrecarga, que poderia ser agravada ou até causada pelo grande número de tentativas.
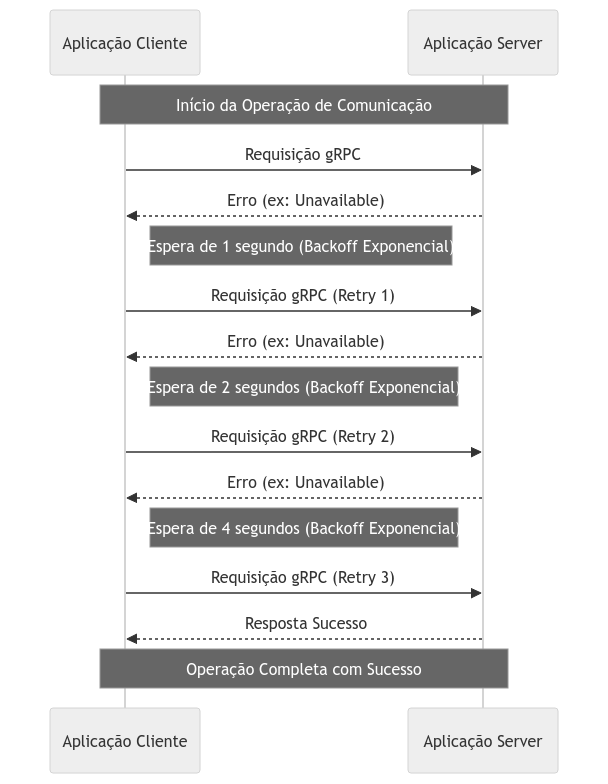
O backoff exponencial pode ser aplicado tanto em fluxos síncronos quanto assíncronos. Implementar essa lógica em clientes de comunicação entre serviços é simples e costuma ser extremamente valioso em cenários de sistemas distribuídos. Muitos brokers de mensagens oferecem suporte nativo a backoff exponencial ou fornecem mecanismos que facilitam sua adoção. Essa técnica é uma evolução natural das estratégias de retentativas e é altamente recomendada sempre que possível.
Retries com Estratégias de Jitter
A estratégia de jitter é uma alternativa avançada ao backoff exponencial. A ideia do jitter é introduzir intervalos de tempo aleatórios entre as retentativas, dispersando-as e reduzindo ainda mais o risco de gargalos e sobrecarga. Esse método é especialmente útil em cenários com alto volume de tráfego, nos quais muitas retentativas podem ser iniciadas simultaneamente durante uma falha.
Existem várias formas de aplicar jitter. Uma abordagem simples atribui a cada retentativa um valor aleatório entre 0 e o tempo máximo definido para o backoff. Também é possível configurar jitter incremental, em que os intervalos aumentam a cada retentativa: por exemplo, a primeira pode variar entre 0 e 4 segundos; a segunda, entre 2 e 6 segundos; a terceira, entre 6 e 10 segundos; e assim por diante.
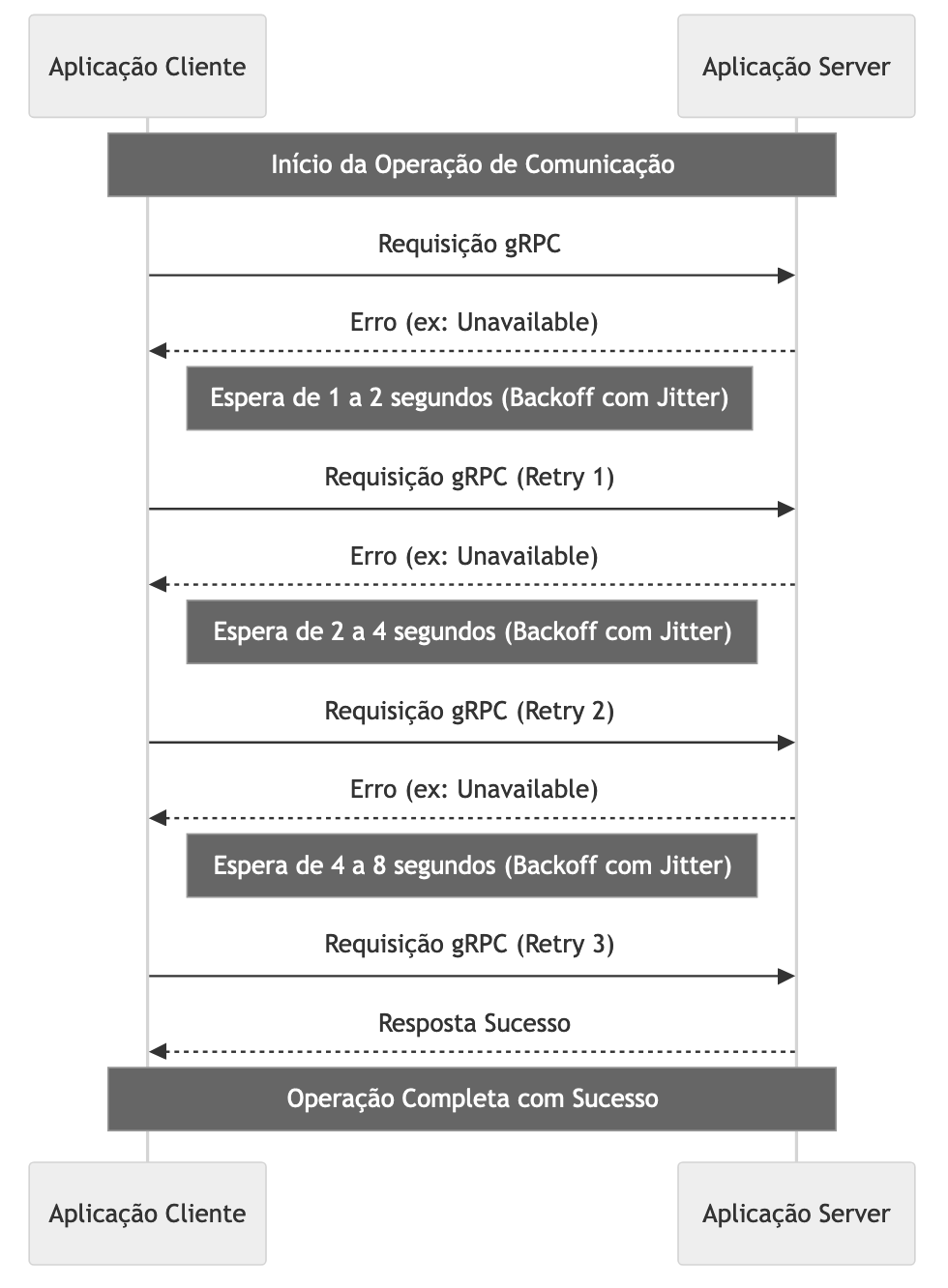
Independentemente do modelo, o objetivo do jitter é dispersar o volume de retentativas, evitando que elas agravem problemas existentes.
Circuit Breakers
O pattern de Circuit Breaker é uma estratégia de resiliência projetada para proteger serviços e componentes de sobrecarga e impedir que falhas isoladas se agravem em cascata.
A metáfora do Circuit Breaker é semelhante a um disjuntor elétrico, que “desarma” e interrompe o fluxo de chamadas para um serviço ou componente quando detecta um alto número de falhas, evitando a propagação de problemas.
A implementação de um Circuit Breaker normalmente envolve três estados: fechado, aberto e semiaberto. No estado inicial (fechado), todas as requisições são encaminhadas normalmente e o circuito monitora continuamente as respostas.
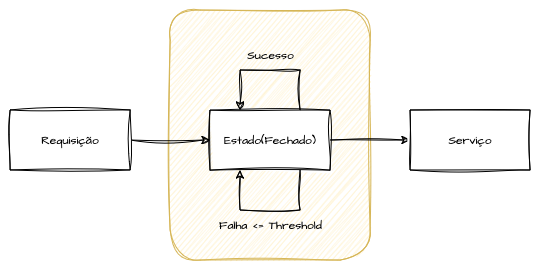
Se limites configurados de tempo de espera ou de erros forem ultrapassados, o circuito muda para o estado aberto. Nesse estado, o disjuntor “desarma”, bloqueando todas as comunicações com o serviço ou dependência e evitando que novas requisições sobrecarreguem recursos já comprometidos.
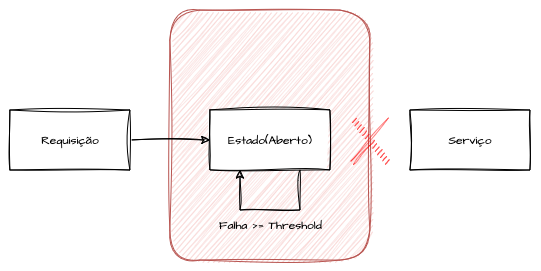
O circuito permanece aberto por um período configurado (período de resfriamento), dando tempo para que o serviço se recupere. Terminada essa pausa, o circuito transita para o estado semiaberto, no qual um número limitado de requisições é direcionado de forma controlada. Se essas requisições forem bem-sucedidas, o circuito retorna ao estado fechado, retomando o fluxo normal; caso contrário, volta ao estado aberto até o próximo ciclo de verificação.
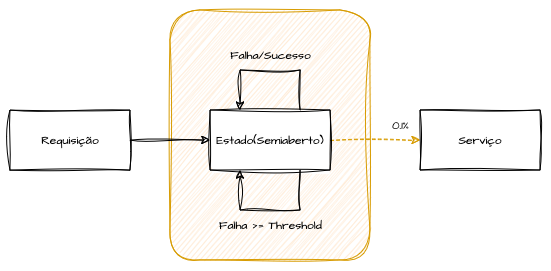
Essa estratégia é de extrema importância em sistemas distribuídos, pois mantém a estabilidade ao controlar o impacto de falhas temporárias, evitando que uma dependência instável degrade ainda mais o desempenho ou a disponibilidade. Há quem relacione Circuit Breakers a um mecanismo de “erro rápido”, mas podemos implementar verificações proativas dos estados para acionar fallbacks sem depender de exceções, redirecionando automaticamente as requisições para fluxos alternativos. Essa abordagem avançada estende o padrão, ativando fallbacks em vez de simplesmente permitir ou negar chamadas, e pode enriquecer significativamente a arquitetura de resiliência.
Throttling e Rate Limiting
Os conceitos de throttling e rate limiting são abordados em profundidade no capítulo de API Gateways. Quando aplicados sob a ótica da resiliência, ambos podem controlar o fluxo de requisições e o consumo de recursos de um sistema, seja em gateways de API ou em outros componentes. O objetivo é evitar sobrecarga e garantir que a infraestrutura suporte as requisições sem comprometer o desempenho.
O rate limiting especifica o número máximo de requisições permitidas em um dado intervalo de tempo, por exemplo, 100 requisições por minuto, 10 transações por segundo ou 1 milhão de transações por mês. Quando esse limite é ultrapassado, as políticas de throttling entram em ação e as requisições adicionais são rejeitadas ou atrasadas, retornando uma resposta que indica que o limite foi atingido.
Essas técnicas podem ser aplicadas isoladamente ou em conjunto para garantir que os limites conhecidos dos sistemas não sejam excedidos, evitando problemas maiores. Uma boa implementação desses padrões exige que as equipes de engenharia compreendam bem os pontos de limitação dos sistemas envolvidos. Normalmente, esses limites são definidos com base em testes práticos de carga e estresse.
Padrões de Fallback
Os fallbacks são padrões de resiliência variados que permitem que, em cenários de falha, as aplicações continuem operando de forma completa, parcial ou degradada. A ideia dos fallbacks é fornecer rotas alternativas para atingir o mesmo objetivo, ainda que esses caminhos sacrifiquem desempenho, tempo de processamento, consistência, custo ou funcionalidades.
Quase todos os conceitos discutidos neste capítulo podem acionar ou atuar como fallback. A seguir, apresentamos alguns cenários ilustrativos, mas é importante não se limitar a esses exemplos na definição de fluxos de fallback.
Exemplo: Fallback Sistêmico por Redundância
O fallback sistêmico é o modelo mais básico de fallback. Essencialmente, consiste em acionar um fluxo secundário de forma pragmática quando o fluxo principal falha.
Para ilustrar, considere um e-commerce que se conecta a gateways de pagamento. Mantemos uma opção primária de gateway e um gateway secundário pronto para ser acionado em caso de falha do principal. Em situações de indisponibilidade temporária ou programada do primeiro gateway, redirecionamos os pagamentos para o secundário até o serviço principal ser restabelecido.
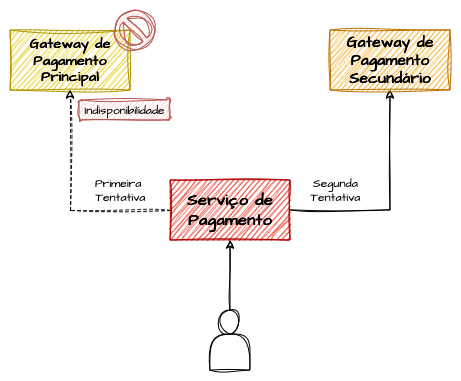
Embora simples, esse exemplo demonstra o funcionamento de um mecanismo de fallback. Com essa base, as diversas combinações dos padrões apresentados permitem construir soluções de alta disponibilidade de forma criativa e eficaz.
Exemplo: Fallback com Snapshot de Dados
Teremos um tópico específico para explorar estratégias de fallback na camada de dados neste capítulo, mas, para ilustrar o conceito, vamos imaginar um cenário em que é necessário consultar um dado quase em tempo real, como o limite de crédito de um cartão fornecido por uma instituição financeira. Tanto as operações de débito quanto as de crédito precisam estar sempre atualizadas para evitar permitir compras sem saldo suficiente ou aprovar compras a crédito sem limites. Em caso de falhas, a instituição pode optar por aprovar compras com o risco de alguma negativação pontual ou bloquear todas as transações até que o serviço seja restabelecido.
Para ilustrar, abordaremos a solução do primeiro cenário: diante da indisponibilidade do dado “quente”, podemos usar snapshots atualizados periodicamente em cache ou em um banco de dados mais acessível, permitindo verificações básicas.
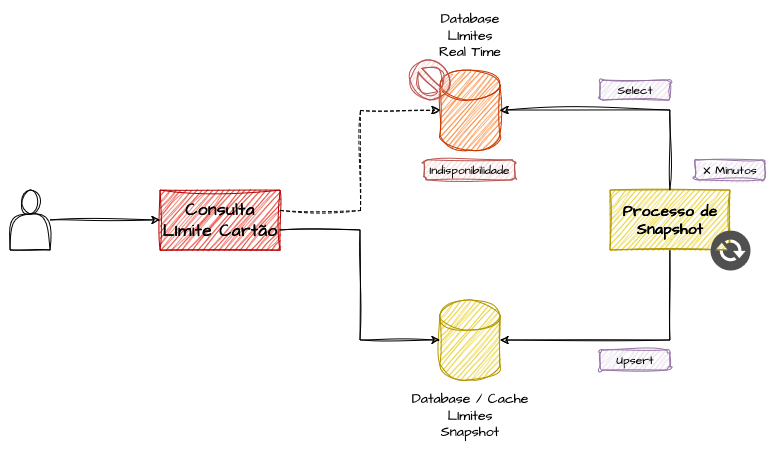
Se nossa aplicação utiliza bancos de dados transacionais e o serviço estiver indisponível, podemos criar uma camada de snapshot atualizada periodicamente e realizar checagens simplificadas, sacrificando consistência forte por consistência eventual, mas, ainda assim, evitando que compras ultrapassem muito os limites durante o período de indisponibilidade. Nesse cenário, aceitamos um risco calculado de aprovar algumas transações além do limite permitido, em troca de manter o sistema em operação.
Exemplo: Fallback com Fluxos Assíncronos
Um fallback também pode incluir uma alternativa de mensageria para fluxos que normalmente requerem resposta imediata, substituindo consistência forte por consistência eventual em caso de falha ou indisponibilidade temporária. Esse tipo de fallback é muito útil em cenários em que a confirmação imediata das operações é importante, mas há flexibilidade para aceitar atrasos temporários. A ideia central é ter a capacidade de transformar fluxos síncronos em assíncronos quando necessário.
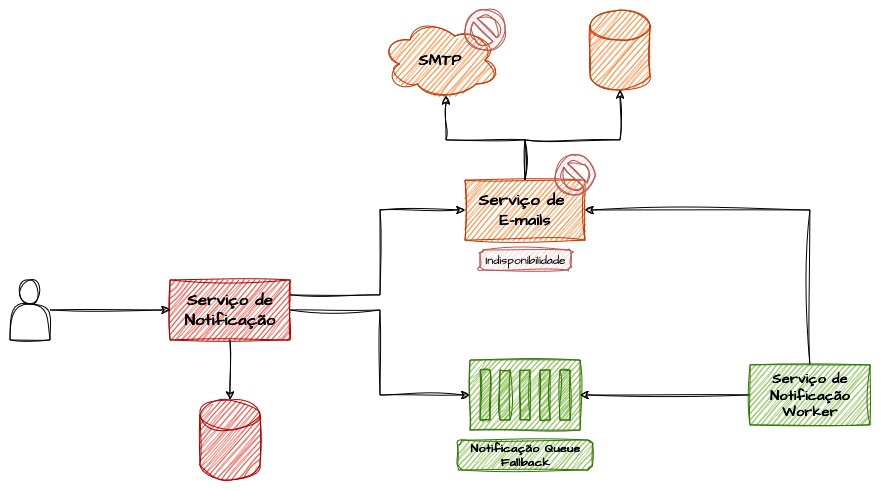
Fallback Sync/Async
Por exemplo, considere uma API interna que aciona diversos serviços de notificação, como o envio de e-mails aos clientes. Embora as notificações devam, na maior parte do tempo, ser executadas de forma sequencial, atrasos ocasionais não representem problema significativo. Em caso de falha de componentes — como bancos de dados ou servidores SMTP —, em vez de retornar um erro ao cliente da API, o fluxo secundário é acionado, enviando a solicitação de e-mail para uma fila de mensageria. Essa mensagem será reprocessada diversas vezes até que o serviço seja restabelecido, permitindo que as operações sejam concluídas assim que a disponibilidade for retomada.
Exemplo: Fallback Contratual
Imagine que, em sua solução hipotética, exista um sistema parceiro que oferece serviços de consulta de endereço ou CEP, calculando diversas opções de frete e estimativas de entrega com várias transportadoras. Esse parceiro cobra R$ 0,03 por consulta e oferece um preço diferenciado por contrato, sendo nossa primeira opção devido ao melhor custo-benefício e desempenho. No entanto, você tem um segundo parceiro que fornece as mesmas funcionalidades, porém com algumas limitações e a um custo mais elevado, cerca de R$ 0,10 por consulta.
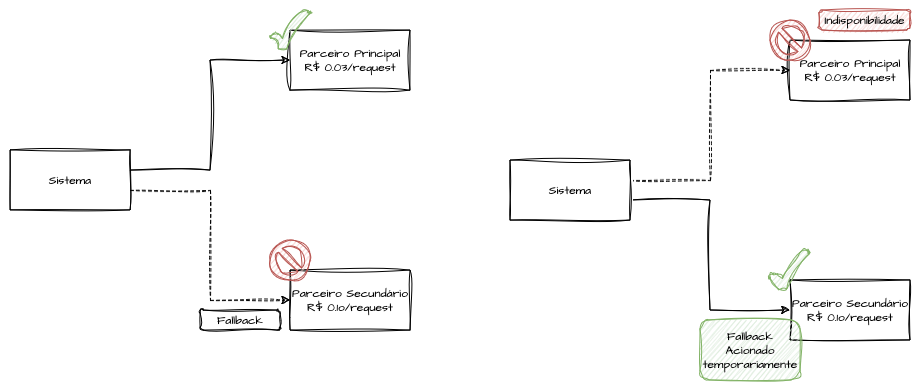
Esse segundo parceiro, embora não seja a opção mais viável financeiramente, representa um fallback contratual válido. Em caso de falha no sistema principal, a integração pode ser redirecionada temporariamente para essa segunda opção. Mesmo sendo mais caro, ele garante que o serviço continue disponível até que a funcionalidade principal seja restabelecida.
Acionamento de Fallback Proativo
A estratégia de acionar um fallback de forma reativa — em resposta a erros e indisponibilidades — já é bastante valiosa para sistemas tolerantes a falhas. No entanto, podemos ir além e garantir que a qualidade e a estabilidade do fallback sejam validadas regularmente, não apenas em cenários adversos do fluxo principal.
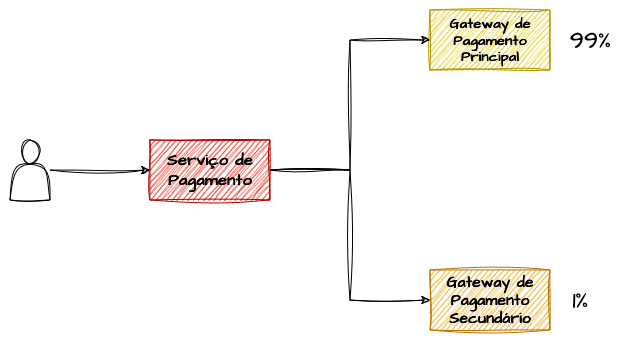
Não é incomum que fallbacks acionados raramente se tornem pontos de falha quando ativados de forma repentina. Para mitigar esse risco, podemos acionar proativamente os fluxos de fallback alternativos, direcionando uma porcentagem mínima de tráfego a eles — seja por meio de injeção de falhas, seja por roteamento intencional, conforme definido pelo algoritmo. Dessa forma, asseguramos que nossos fallbacks permaneçam saudáveis e prontos para atuar quando necessário.
Graceful Degradation
Graceful Degradation refere-se à capacidade de um sistema continuar operando com suas funcionalidades essenciais de forma preventiva, mesmo quando partes significativas estejam degradadas, sob alta carga ou indisponíveis. Embora esse conceito esteja diretamente relacionado ao fallback, Graceful Degradation pode ser ativado de forma pragmática ou por meio de feature toggles.
Em outras palavras, diante de um pico de tráfego, o sistema prioriza suas funcionalidades principais, desativando as demais e operando apenas com o necessário. Essa redução pode ocorrer automaticamente ou ser acionada manualmente para ajudar a lidar com sobrecarga.
Diferentemente dos fallbacks, que entram em ação após a ocorrência de falhas, Graceful Degradation é uma medida preventiva e intencional. Quando o sistema detecta condições adversas — como falhas em um serviço externo com acoplamento forte, indisponibilidade de um microserviço crítico ou sobrecarga de tráfego —, ele reduz automaticamente suas funcionalidades a um nível que ainda permita operação mínima, concentrando-se nos fluxos prioritários.
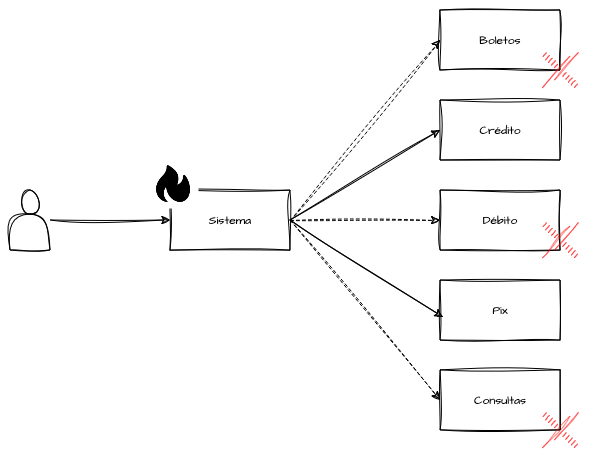
Para ilustrar, considere um gateway de pagamento que oferece PIX, crédito, débito, boletos e consulta de transações. Embora todas sejam importantes, o time de negócios define PIX e crédito como prioritários, pois representam o maior volume de uso dos clientes. Com Graceful Degradation, em momentos de alta demanda, débito, boletos e consulta podem ser temporariamente desativados, permitindo que o sistema direcione recursos aos métodos de pagamento prioritários.
Backpressure como Resiliência
Ao adotar fluxos assíncronos em nossa arquitetura, presumimos lidar com um throughput muito alto de requisições. Embora não seja uma regra absoluta, escalamos o processamento de grandes volumes de dados e transações com paralelismo externo de forma muito mais eficiente do que usando apenas métodos síncronos e bloqueantes, como chamadas de APIs REST ou implementações de gRPC. O ciclo de vida dessas transações pode ser híbrido, incluindo chamadas HTTP mesmo em fluxos assíncronos para lidar com dependências externas ou produzindo mensagens para outros sistemas que finalizam a transação iniciada de forma assíncrona. Porém, fluxos de alto volume com uso intensivo de I/O podem causar indisponibilidade repentina em sistemas downstream.
Quando abordamos backpressure pela primeira vez, entendemos esse conceito como uma “força contrária” que gera um gargalo no fluxo de transações. Em termos de resiliência, o backpressure ativo e intencional permite desacelerar a produção ou a integração com outros serviços, diminuindo o ritmo de consumo ou enfileirando o processamento em memória para proteger componentes downstream de sobrecargas. Em resumo, implementações de backpressure permitem que o sistema envie sinais ativos de degradação e desaceleração, preservando a integridade dos componentes posteriores e evitando picos de latência ou falhas em cascata.
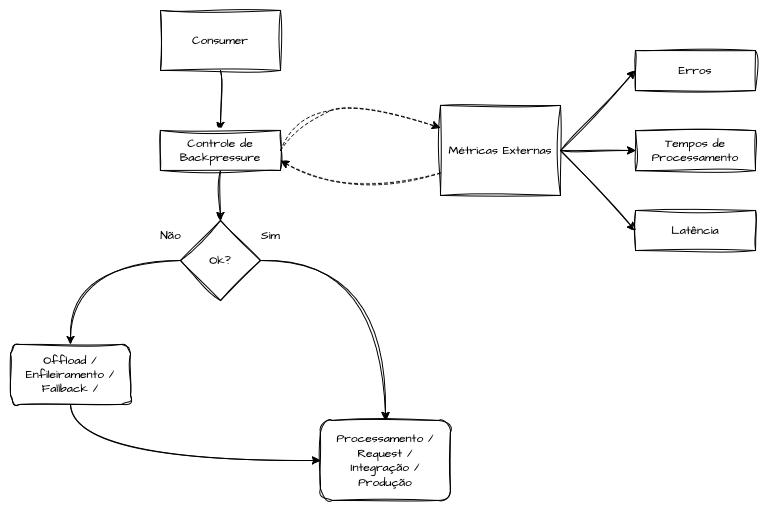
As implementações de backpressure podem basear-se em métricas de observabilidade e, ao detectar latências crescentes, aumento de erros ou filas internas que excedem thresholds configurados, o adaptador de backpressure aciona um feedback loop que desacelera chamadas a serviços externos ou redireciona parte do tráfego para fallbacks alternativos ou filas de offload. Esse mecanismo preventivo funciona como um circuito de segurança antes que os limites de capacidade sejam ultrapassados, reduzindo o blast radius de picos de carga inesperados.
Uma abordagem avançada de backpressure inteligente é integrá-lo ao monitoramento de SLIs e error budgets, tanto das aplicações quanto de suas dependências. Por exemplo, se o error budget de um endpoint crítico estiver próximo do limite em um dado período, o sistema pode reduzir proativamente sua taxa de ingestão, produção e processamento — via backpressure — para priorizar a estabilidade da malha de serviços, gerando métricas de retenção de tráfego que alimentam dashboards e alertas. Assim, o backpressure deixa de ser apenas um guardião da saturação de recursos críticos e torna-se um componente operacional que alinha resiliência técnica a metas de continuidade de negócio.
Algumas implementações de Service Mesh permitem aplicar essas políticas de forma agnóstica à aplicação, simplificando a adoção de backpressure em todo o ecossistema de microsserviços.
Resiliência na Camada de Dados
Quando falamos de dados, lidamos com a camada mais complexa para escalar e implementar mecanismos de tolerância a falhas. Projetar estratégias que garantam resiliência na camada de dados torna a adoção dos demais patterns consideravelmente mais simples. Nesta seção — assim como nas anteriores — vamos reunir diversos cenários já apresentados, pois esse tema tem sido o principal foco de estudo deste livro.
Read-Write Splitting
O Read-Write Splitting, isto é, segregar as operações de escrita e de leitura em instâncias distintas de banco de dados, oferece, além de ganho significativo de performance, mecanismos naturais de fallback.
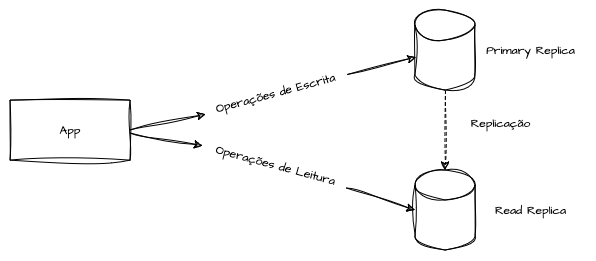
O uso de réplicas de leitura é amplamente adotado na indústria. O impacto direto dessa prática está no desempenho, pois permite que as escritas ocorram em uma instância principal, enquanto consultas, relatórios e acessos a dados básicos são direcionados para réplicas, dispersando o gargalo de I/O.
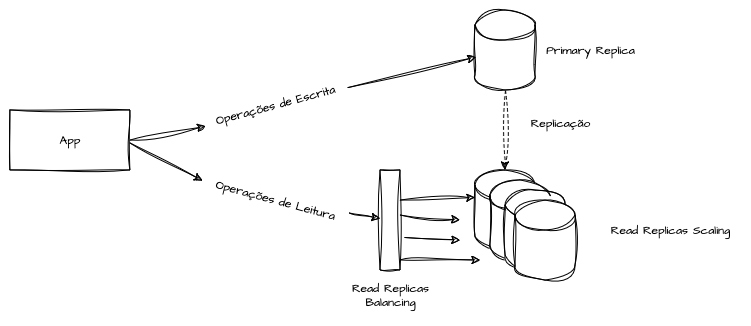
Em clouds públicas, essa arquitetura permite escalar horizontalmente o número de réplicas de leitura para atender picos de demanda ou facilitar a recuperação caso alguma delas falhe. O fallback entre réplicas de leitura é trivial de implementar, diferentemente da instância de escrita, que costuma ser o ponto único de inserções e atualizações.
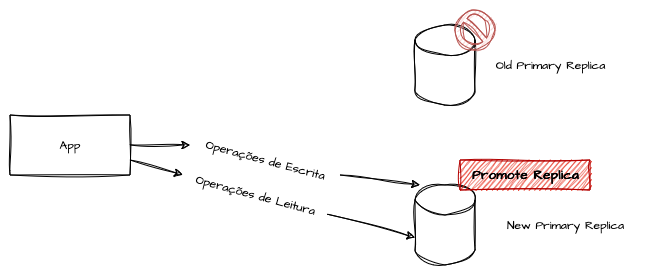
Outro recurso valioso de fallback é a promoção de réplicas de leitura a instância principal de escrita. Se a instância de escrita falhar, uma réplica — ou uma instância de stand-by — pode ser automaticamente promovida a ponto de gravação. Essa prática aumenta significativamente a tolerância a falhas na camada de dados e é recomendada em arquiteturas resilientes.
Caching de Dados como Resiliência
Os padrões de cache são muito versáteis e podem gerar diversos benefícios em arquiteturas de solução. Estratégias de cache visam criar cópias mais performáticas e econômicas de dados, sejam eles de backend, de dependências externas, de bancos de dados relacionais ou não relacionais, ou até de conteúdos estáticos do front-end.
Como o conceito de cache se baseia em manter versões dos mesmos dados em locais de acesso mais rápido e custo reduzido, tais cópias podem funcionar como mecanismo de resiliência em relação à fonte original.

Ao consultar o cache em vez da origem, o número de acessos ao backend ou ao banco de dados é significativamente reduzido, o que, além de aumentar a performance, diminui a carga sobre a camada de dados. Esse efeito é especialmente valioso em picos de demanda, prevenindo que a camada de dados atinja sua capacidade máxima e sofra falhas. Além disso, é possível projetar políticas de expiração e mecanismos de fallback que permitam ao cache suprir a indisponibilidade total da fonte de dados.
Recomendo a releitura do capítulo sobre estratégias de cache, revisitando padrões como Write-Behind, Write-Through, Lazy Loading e cache distribuído, agora sob a perspectiva de resiliência.
Quando cache e fonte original são mantidos sincronizados com as mesmas versões, ambas as camadas tornam-se altamente redundantes.
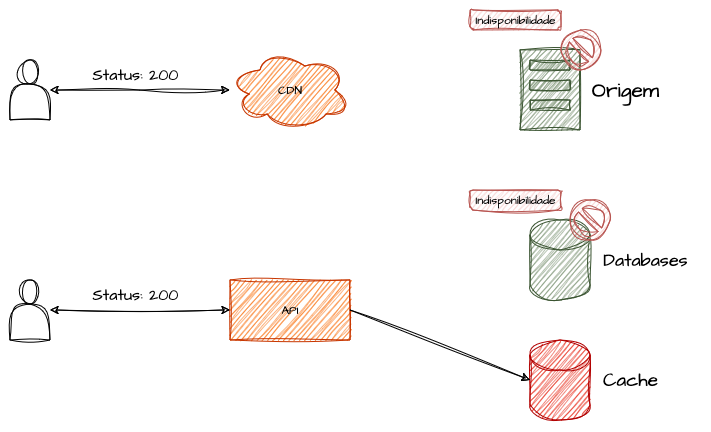
Por exemplo, uma CDN bem configurada pode sustentar longas indisponibilidades dos servidores de origem em front-ends, enquanto caches inteligentes de dados de banco permitem que o sistema continue operando de forma total, parcial ou minimamente, conforme critérios definidos.
Sharding e Particionamento de Clientes em Resiliência
Não colocar todos os ovos na mesma cesta é a analogia perfeita para explicar a implementação de sharding. O capítulo em que detalhamos sharding, particionamento e distribuição por hashing é, talvez, um dos meus favoritos nesta coleção, pois dediquei-lhe atenção especial para reunir referências e elaborar a revisão bibliográfica sobre o tema.
O objetivo de segregar um grande conjunto de dados em grupos menores é, por si só, muito intuitivo no contexto de resiliência. Dividir domínios — mesmo aqueles já fragmentados em microserviços — revela-se um caminho evolutivo eficaz em cenários de alta demanda e missão crítica.

A estratégia de particionar tanto os dados quanto as cargas de trabalho em dimensões significativas — como clientes, lojas ou inquilinos (tenants) —, de modo a isolar completamente cada fragmento em um único shard, é essencial. Embora essa abordagem possa gerar partições quentes ocasionais, ela permite testar novas funcionalidades com controle mais granular, sem propagá-las a todos os clientes. Além disso, esse particionamento ajuda a reduzir o blast radius de componentes de um shard, isolando impactos e elevando a resiliência do sistema.
Bulkhead Pattern
O Bulkhead é um padrão fortemente relacionado a conceitos como sharding, hashing consistente, arquitetura celular e estabilidade estática. O termo origina-se do transporte marítimo, em que os compartimentos de um navio são isolados, de modo que, caso haja dano em uma seção, as demais permaneçam intactas, prevenindo inundação por falhas sucessivas.
Considerando o Bulkhead como uma evolução do sharding, enquanto este está associado principalmente a dados, o Bulkhead amplia o particionamento para componentes de infraestrutura, e não apenas para a camada de dados.
O objetivo dos bulkheads é isolar recursos específicos para funcionalidades distintas, tais como pools de conexão, bancos de dados, balanceadores de carga, versões de uma mesma aplicação, prioridades de requisições e segmentação de clientes.
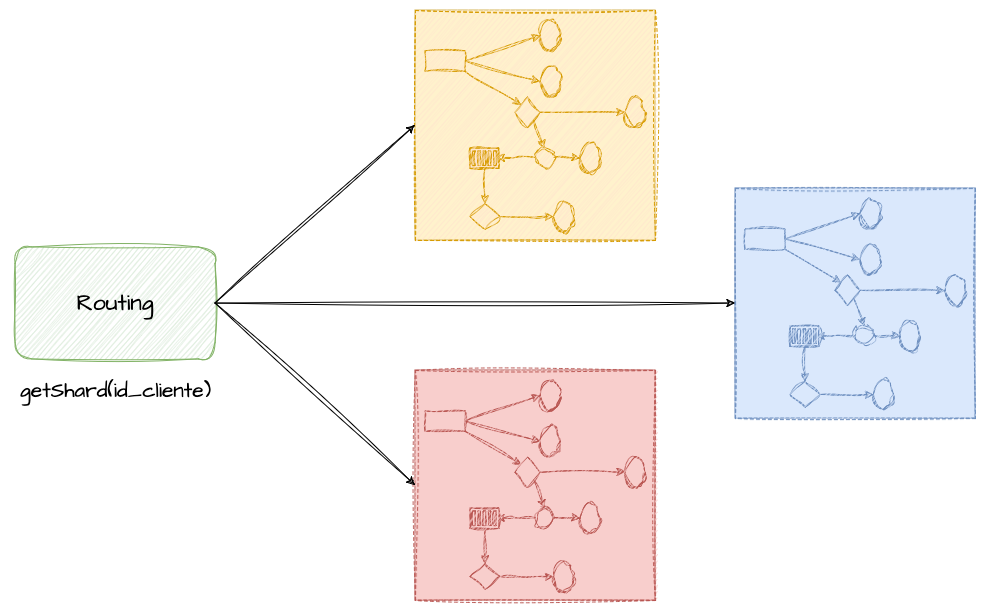
Com essa abordagem, se distribuirmos os clientes uniformemente em N bulkheads, o blast radius de uma falha em um compartimento fica limitado a 1/N dos clientes. Por exemplo, em 10 bulkheads, uma falha impacta apenas 10% dos clientes; em 100 bulkheads, apenas 1%; em 1.000, apenas 0,1%.
Uma implementação mais drástica é isolar todas as dependências de um domínio em bulkheads independentes, incluindo microserviços, bancos de dados, caches e até mesmo armazenamento de arquivos. Embora pareça extremo, essa estratégia é adotada em soluções multi-tenant baseadas em federação ou em arquiteturas celulares.
Lease Pattern
O Lease Pattern, ou “Arrendamento”, é um padrão presente em sistemas distribuídos que define concessões temporárias ou tempos de validade para uso ou alocação de recursos. Esses recursos podem incluir pools de conexão, tokens de acesso, alocação de consumo de mensagens, conexões persistentes entre clientes e servidores, entre outros.
A adoção do Lease Pattern evita que sistemas com alto volume de acessos fiquem sobrecarregados por recursos ociosos, garantindo que operações ativas não sejam bloqueadas por alocações expiradas.
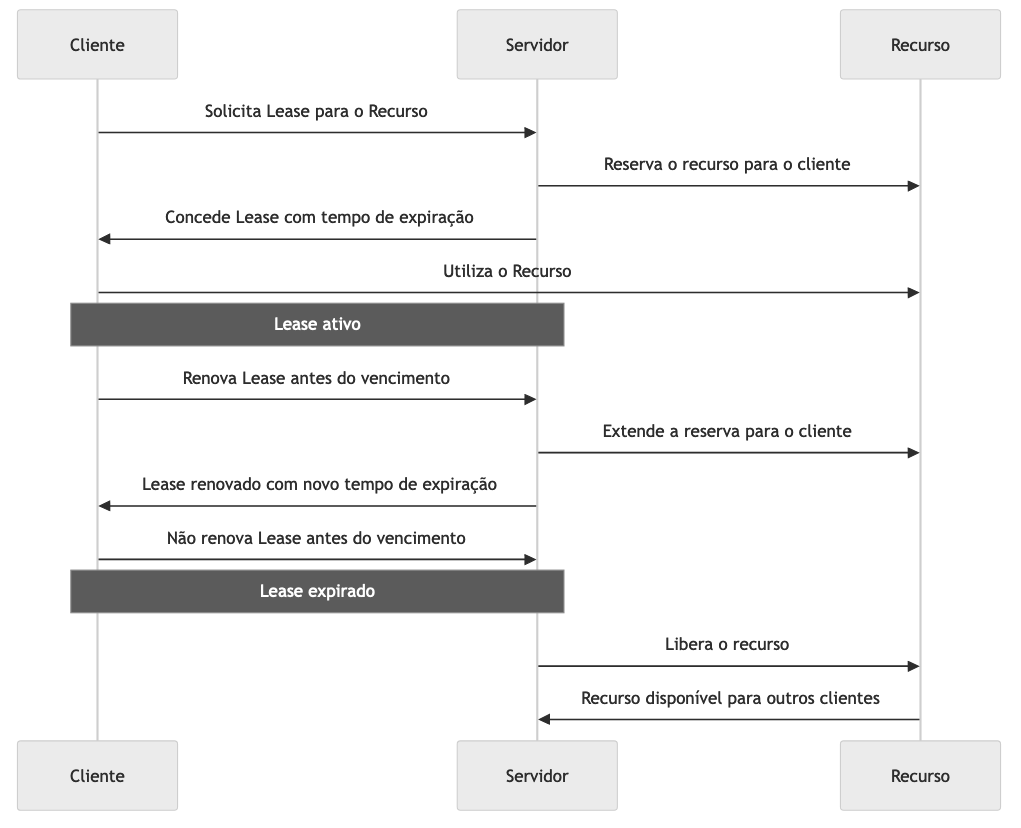
O leasing acontece quando um recurso inicia uma conexão com uma dependência, como, por exemplo, um consumidor de Kafka conectando-se a uma partição, uma conexão persistente a um banco de dados ou uma chamada gRPC em ambiente com limite de conexões simultâneas. O servidor concede essa alocação com prazo de validade ou tempo máximo de inatividade, durante o qual o cliente deve renovar o lease para indicar que continua ativo.
Se o cliente não renovar dentro do prazo, o lease expira e o recurso é automaticamente liberado para outro processo.
Em pools de conexão a bancos de dados, cada cliente ou thread recebe um lease para uma conexão. Se não houver renovação por meio de heartbeat ou liberação explícita ao término do uso, o lease expira e a conexão é devolvida ao pool, evitando que recursos fiquem monopolizados por clientes inativos. Esse mecanismo é fundamental em bancos transacionais, nos quais o número de conexões simultâneas é limitado e, ultrapassado esse limite, novas solicitações são rejeitadas até que haja leases disponíveis.
Referências
Best practices for retry pattern
Retrying and Exponential Backoff: Smart Strategies for Robust Software
Tempos limite, novas tentativas e retirada com jitter
Better Retries with Exponential Backoff and Jitter
How To Minimize Your Cloud Breach Blast Radius
Guidance for Cell-Based Architecture on AWS
Terraform Module Blast Radius: Methods for Resilient IaC in Platform Engineering
Bulkhead Pattern — Distributed Design Pattern
Como a estabilidade estática aumenta a resiliência da sua aplicação
Efficient Scalability and Concurrency implementing the Lease Management as a Locking Pattern
