
System Design - Databases, Modelos de Dados e Indexação

O objetivo desse capítulo é mostrar as principais implementações de databases e suas diferenças práticas para sistemas produtivos, para que as mesmas fiquem claras para eventuais escolhas arquiteturais. Foi um pouco complicado moldar esse artigo sem que o mesmo virasse um “painel de avião” com a quantidade de termos e conceitos que podem ser levados em conta em diferentes databases, e é muito difícil falar sobre engines de bancos de dados procurando por conceitos e termos comuns entre todos sem tornar o artigo sobre o próprio database em si. Ao contrário do padrão combinado dos capítulos dessa série, não conseguirei evitar utilizar exemplos nominais de tecnologia para explicar sua implementação. Espero que esse texto seja de grande ajuda e atue de forma complementar com os capítulos anteriores, onde falamos de ACID, BASE e o Teorema CAP. Aqui abordaremos também diversos modelos de dados e tipos de indexação que podem ser comuns entre diversos tipos de databases. Espero que seja de grande ajuda e influencie ainda mais a sua curiosidade sobre o tema para os próximos capítulos.
Definindo um Banco de Dados
Um banco de dados, em essência, é uma forma de organizar dados dentro de uma estrutura predefinida, que pode ser armazenada, gerenciada e disponibilizada para acesso de escrita e leitura através de um padrão de consulta pré-estabelecido. Um banco de dados trabalha como uma camada intermediária entre o cliente e o dado, permitindo que os mesmos sejam manipulados sem que o desenvolvedor precise lidar com alocação em disco, indexação e algoritmos de distribuição para buscar o dado de forma performática. Esse dado pode estar sendo persistido em storages duráveis, temporários ou uma combinação de ambos, escolhas que variam de sua implementação.
Em arquiteturas distribuídas, o papel de um banco de dados pode adquirir complexidades adicionais para elevar o nível de consistência, disponibilidade e performance, principalmente trabalhando com camadas de replicação geográficas, baixa latência ou realizando a melhor escolha entre consistência forte ou consistência eventual para as operações que precisam ser realizadas nos dados.
Tipos de Bancos de Dados
Quando avaliamos o banco de dados para uma determinada solução, devemos sempre tratar a escolha como um “racional de features” de cada um, e onde cada uma delas agrega ou ofende os níveis de performance, consistência e custo que o mesmo precisa. Para tornar isso um pouco mais claro, vamos abordar, de forma macro, porém bem detalhada a nível arquitetural, as principais possibilidades que podemos encontrar para nos auxiliar nas definições de engenharia de um produto. Esse tipo de cuidado é essencial para evitar escolhas que possuam muitas features que não são utilizadas pelo produto, enquanto não agregam aos requisitos do mesmo.
Bancos de Dados Relacionais SQL
Os bancos de dados SQL (Structured Query Language) são baseados num modelo proposto por Edgar F. Codd em 1970, sendo o modelo mais conceituado entre as opções arquiteturais. O modelo é organizado em tabelas compostas por tuplas (linhas) e atributos (colunas) e possui features que viabilizam schemas e estruturas rígidas, definindo, por um contrato, os tipos de dados, restrições de integridade, identificadores únicos e regras de coerência entre os relacionamentos das tabelas. Os bancos relacionais, como o próprio nome diz, são pensados para proporcionar relacionamentos internos e declarativos entre os dados de diferentes tabelas. A engenharia de software faz uso desse modelo relacional para trabalhar com entidades e agregados dentro de contextos de domínios de um software. Esses bancos contam normalmente com features do modelo ACID, como Atomicidade, Consistência, Integridade e Durabilidade.
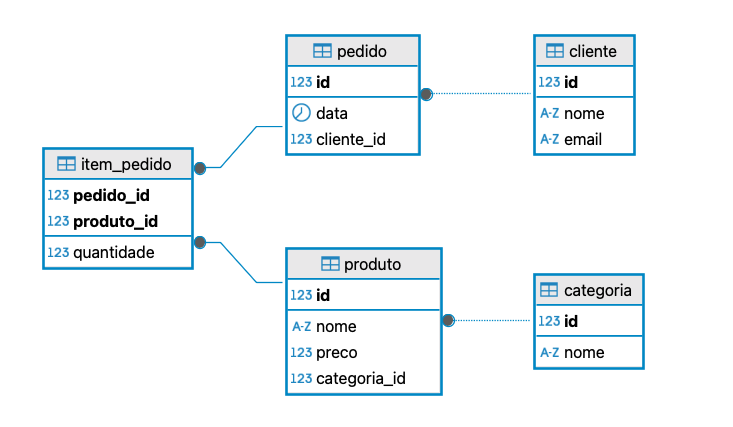
Para um exemplo ilustrativo, em um sistema de pedidos tradicional em um sistema de estoque, cada cliente é identificado por um registro único na tabela cliente, onde estão armazenados seu nome e e-mail. Quando esse cliente realiza uma compra, gera-se um registro na tabela pedido, que guarda a data e a referência ao cliente responsável por aquele pedido. Caso um pedido seja criado com um cliente_id inexistente na tabela cliente, o mecanismo de consistência e relacionamento de um banco SQL não permitiria a efetivação dessa transação, sem necessidade de verificações adicionais pela aplicação.
Em seguida, cada pedido pode incluir vários produtos, mas, como um produto pode aparecer em diferentes pedidos, criamos a tabela item\_pedido para mapear essa relação “muitos-para-muitos”: cada linha de item\_pedido associa um único pedido a um único produto, informando também a quantidade solicitada. Por sua vez, todos os produtos disponíveis estão listados na tabela produto, que contém atributos como nome, preço e uma chave estrangeira para categoria. Essa última tabela organiza os produtos em grupos — como “Eletrônicos”, “Alimentos” ou “Vestuário” — permitindo classificar e filtrar itens de forma eficiente. Dessa forma, ao consultar um pedido, o sistema une pedido → cliente para identificar quem comprou, pedido → item\_pedido para saber o que foi comprado e em que quantidade, e item\_pedido, produto, categoria para exibir detalhes e agrupamentos de cada produto solicitado. Essa estrutura relacional assegura a integridade referencial — já que um pedido não pode existir sem um cliente válido, e um item de pedido não pode referenciar produtos inexistentes — e facilita a construção de relatórios como total gasto por cliente, quantidade vendida por categoria ou itens mais pedidos em determinado período.
Banco de Dados Não Relacionais NoSQL
Os bancos não relacionais, ou NoSQL (Not Only SQL), são uma proposta mais flexível aos modelos rígidos dos bancos SQL, trocando níveis altos de consistência e integridade por escalabilidade. Os bancos NoSQL, por padrão, utilizam outros formatos de dados além de tabelas e linhas e não possuem relacionamentos diretos entre seus conjuntos de dados, tendo schemas mais flexíveis e, frequentemente, consistência eventual em troca de maior desempenho de leitura, escrita, escalabilidade horizontal e distribuição.
São nos bancos NoSQL que encontramos maior diversidade de formatos, como chave-valor, JSON, BSON, grafos etc., sendo que o principal foco é evitar joins custosos a favor de modelos de dados mais simples e com regras mais mutáveis, o que pode acarretar tanto em maior performance quanto em riscos de inconsistências de tipos de dados e contratos que precisam ser respeitados pela aplicação que consome o dado.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
{
"_id": ObjectId("60f5a2d1a2e9b5f1d4c8e918"),
"nome": "Ana Silva",
"email": "ana.silva@exemplo.com",
"pedidos": [
{
"pedidoId": "PED12345",
"data": "2025-07-27T14:35:00Z",
"itens": [
{
"produto": {
"id": ObjectId("60f5a3e8a2e9b5f1d4c8e91a"),
"nome": "Camiseta Manga Curta",
"preco": 79.90
},
"quantidade": 2
},
{
"produto": {
"id": ObjectId("60f5a3f2a2e9b5f1d4c8e91b"),
"nome": "Calça Jeans",
"preco": 149.90
},
"quantidade": 1
}
]
},
{
"pedidoId": "PED12346",
"data": "2025-07-28T09:20:00Z",
"itens": [
{
"produto": {
"id": ObjectId("60f5a3e8a2e9b5f1d4c8e91a"),
"nome": "Camiseta Manga Curta",
"preco": 79.90
},
"quantidade": 1
}
]
}
]
}
Seguindo o exemplo do sistema de pedidos e estoque, toda a cadeia de entidades como cliente, pedido, item do pedido, produto e categoria é representada de forma hierárquica dentro de um único documento por cliente, eliminando a necessidade de múltiplas coleções e joins de diversas coleções de dados distribuídos entre diferentes tabelas. Cada documento da coleção traz não só os dados básicos do usuário, mas também uma lista de pedidos, em que cada elemento inclui o ID do pedido, a data e, por sua vez, uma sublista de itens com os detalhes de cada produto e a quantidade comprada. A coleção produtos mantém a definição de cada item e já incorpora o objeto categoria, trazendo o nome e o identificador da categoria embutidos — assim, ao ler um produto, não é preciso buscar em outra coleção.
Bancos de Dados NewSQL
O maior desafio dos sistemas distribuídos é conviver com trade-offs encontrados nas camadas de dados. Os bancos NewSQL são databases que focam sua implementação em conciliar os dois mundos, buscando dar uma confiança transacional e relacional para as operações vindas dos modelos SQL e ainda agregar features de escalabilidade horizontal e alto throughput dos modelos NoSQL.
As implementações de databases NewSQL costumam ser extremamente focadas em necessidades distribuídas, realizando operações de sharding e replicação de forma transparente e síncrona, para garantir a confiabilidade ACID das transações, mas aplicando protocolos de consenso distribuído para realizar isso de forma mais distribuída e performática possível.
Bancos de Dados em Memória
Os databases em memória, ou in-memory databases, são bancos de dados especializados em volatilidade e em realizar a gestão de seus dados diretamente na RAM do servidor, ao invés de tratar a persistência de forma durável em discos e volumes físicos.
O objetivo dos bancos de dados em memória é reduzir latência e tempos de resposta da consulta do dado, uma vez que uma consulta em memória volátil pode ser realizada em nanossegundos na RAM, ao invés de milissegundos em um acesso em disco, cenário que pode ser agravado por um uso intensivo de I/O do volume.
Os modelos de dados encontrados nesse tipo de implementação costumam ser extremamente simples, e seu melhor uso possível se baseia em chave-valor, combinado com outros tipos de databases duráveis, sendo pensados para sistemas de cache de dados, fazendo uma camada de acesso rápido para dados caros e que não são alterados com grande frequência.
Os bancos de dados em memória, por serem estruturas simples e cujos dados podem ser recuperados da origem caso sejam perdidos, podem facilitar a escalabilidade horizontal, facilitando a adição e remoção de nodes, aplicando algoritmos de hashing consistente e seus derivados para distribuição das informações entre diversos data nodes. Um ou mais nós do cluster podem ser designados para receber as requisições de escrita, calcular o hashing da chave e designar um node responsável entre os existentes para armazenar o dado. Para a recuperação, o mesmo algoritmo é aplicado para saber para onde será redirecionada a solicitação de leitura. Dessa forma, conseguimos trabalhar redimensionamento de forma simplificada.
Utilizar somente a memória RAM para armazenar dados presume uma série de trade-offs consideráveis, como assumir a não durabilidade do dado, uma vez que, ao reiniciar o serviço ou o servidor, todos os dados podem ser perdidos. Logo, o uso só é recomendado para dados que podem ser reconstituídos a qualquer momento diretamente de sua origem, além de sua escalabilidade costumar ser financeiramente cara de forma horizontal e vertical.
Time-Series Databases
Os bancos de dados baseados no tempo são especializados em armazenar séries temporais com indexação baseada em tempo, e também são conhecidos como TSDBs (Time-Series Databases). Cada registro inserido em um Time-Series Database é como um “carimbo temporal” preciso daquela métrica ao longo do tempo. Os modelos desse tipo de banco de dados implementam o armazenamento por “append-only”, registrando cada ponto do dado de forma segmentada e sequencial. Esse tipo de banco de dados é utilizado em sistemas de observabilidade e monitoramento, sendo empregado para acompanhar o desempenho de determinada métrica ao longo de longos períodos — horas, dias, semanas, meses e até anos — garantindo buscas rápidas e a capacidade de realizar diversas operações e cálculos matemáticos sobre os dados de forma performática e econômica, além de alta capacidade de ingestão de dados distribuídos através de endpoints centralizados e escaláveis.
Os Time-Series Databases são otimizados para ingerir e consultar historicamente grandes volumes de dados sequenciais e aplicar operações matemáticas de forma eficiente. Há sempre um trade-off entre capacidade de relacionamentos, consistência, disponibilidade e confiabilidade, e seus principais usos são: agregadores de logs, métricas, preços, medições sequenciais de IoT etc. Para suportar alta ingestão de dados e grande número de consultas, é comum que elas sejam enfileiradas em processos de backpressure, caso alguma das capacidades internas do database seja comprometida. Não há garantia atômica de disponibilidade do dado após a solicitação de escrita, nem garantias de que todos os dados serão retornados de forma exata nas consultas, sendo desaconselhável para processos transacionais e indicado para processos analíticos.
Esse tipo de database possui também features inteligentes de expurgo de dados expirados, a fim de gerenciar de forma mais performática o storage e comportar diversas métricas ao longo do tempo.
Níveis de Consistência
Em sistemas distribuídos, o nível de consistência dos dados é um dos fatores mais importantes a serem levados em consideração na escolha arquitetural. Escolher entre consistência forte e consistência eventual pode elevar a escalabilidade e a confiabilidade transacional, tanto quanto gerar problemas de confiabilidade e afetar a experiência do usuário, caso seus trade-offs não sejam considerados na arquitetura de solução. Neste texto, iremos abordar diversos níveis em diferentes implementações de bancos de dados, e, nesta seção, deixaremos claras as diferenças entre os modelos.
Consistência Forte
A Consistência Forte, também conhecida por linearizabilidade ou sequential consistency em termos acadêmicos, representa um nível de consistência agressivamente transacional. Em um termo relativo de “níveis de consistência”, o termômetro hipotético estaria no grau mais extremo de temperatura possível.
Isso significa que, independentemente do número de réplicas que um banco de dados tenha, todas elas sempre irão retornar os mesmos dados. Isto é, todo acesso de leitura a uma réplica retorna o valor mais recente gravado por qualquer operação de escrita que tenha sido previamente completada.
Uma vez que um cliente recebe confirmação de um commit de uma transação, qualquer outra leitura, mesmo em outro nó ou região geográfica, refletirá esse valor comitado, até que outra transação completada da mesma forma seja efetuada para alterar o dado. Uma transação só pode levar o banco de dados de um estado consistente para outro estado consistente, sem flexibilidade nesse ponto.
Os databases com consistência forte normalmente estão no modelo CA (Consistency e Availability) do Teorema CAP, ou seja, os bancos de dados SQL tradicionais. Para alcançar esse comportamento, o sistema costuma empregar protocolos de consenso como Paxos, Raft ou commits síncronos entre réplicas, o que implica que cada operação de escrita deve obter acordos de um número mínimo de nós do quórum antes de ser confirmada, podendo acarretar em maior latência e maior consumo de I/O, dependendo da distribuição geográfica, em troca dessa confiabilidade do dado.
Consistência Eventual
A Consistência Eventual é um termo que define sistemas de dados onde, independentemente do volume de escritas que ele tem, em algum momento o sistema irá convergir para um estado consistente, mas, por um breve instante, diferentes réplicas do banco poderão retornar versões distintas do dado. Para viabilizar esse modelo, as replicações são feitas de forma assíncrona, sem bloqueios de escrita.
Quando uma escrita acontece, apenas um nó, ou um pequeno quórum de nós, precisa confirmar a operação; o restante é realizado por meio de replicação por logs ou outro algoritmo de propagação de operações. Se uma leitura for realizada em algum nó que ainda não recebeu a escrita, ele poderá retornar dados faltantes ou desatualizados.
Esse tipo de modelo sacrifica a consistência para elevar o nível de alta disponibilidade e performance, pois as confirmações de escrita são locais e não aguardam resposta de outros nós. Mesmo diante de partições de rede ou indisponibilidade parcial, escritas e leituras podem prosseguir em réplicas isoladas.
Esse modelo possui uma série de desafios além da inconsistência temporária dos dados, pois é preciso implementar, na própria engine ou na aplicação, estratégias de sincronização e resolução de conflitos, como o “last-write-wins”, que resolve conflitos por meio de checagem de timestamp, ou CRDTs, que aplicam algoritmos mais complexos de sincronização.
No geral, tudo que não possui consistência forte — o extremo do termômetro — é, de alguma forma, consistência eventual. Se seu banco de dados ACID SQL adota um quórum de commit onde somente 2/3 das réplicas precisam confirmar a escrita para considerá-la efetivada, isso indica que 1/3 pode lidar com dados desatualizados, tornando o sistema aberto a um “apetite” eventual, e essa arquitetura é inclinada a topologias geodistribuídas e a grandes volumes de operações concorrentes.
Modelos de Dados

Os modelos de dados definem, na engine de banco de dados, como os dados serão estruturados, armazenados e acessados dentro da engine. A escolha influencia diretamente diversos termos já citados, como desempenho, consistência e escalabilidade da solução. Cada modelo pode ser otimizado para cenários específicos; entender o funcionamento pode direcionar as melhores escolhas de engenharia de um produto.
Modelos de Tuplas (Row-Oriented)
Os modelos baseados em linha, ou row-oriented, são o modelo mais tradicional de dados que temos no mercado, e cada tupla, ou linha, com seus valores identificados por colunas, é gravada e gerenciada em disco ou memória de forma contínua e completa, guardando em sequência todos os seus atributos. Esse tipo de modelo é o mais comum que podemos encontrar, pois favorece operações ponto a ponto na mesma entidade ou registro, como as operações convencionais de leitura, escrita, atualização e deleção, sendo ideal para cenários transacionais que criam, editam e buscam registros inteiros com frequência.

Os sistemas baseados em linha são otimizados para granularidade com baixa latência e fazem uso intensivo de caches de páginas, otimizando a recuperação completa de uma linha e toda a sequência de campos, trazendo de uma só vez todos os valores armazenados no mesmo bloco do disco.
Modelos de Documentos
Bancos de dados orientados a documentos tratam cada registro como uma entidade completamente autônoma, geralmente em formato livre e sem restrições ou consistências rígidas de campos, normalmente estruturados em JSON ou BSON. Esse modelo flexível facilita a evolução da estrutura de dados e dos contratos pela ótica da aplicação consumidora, sem a necessidade de migrações complexas.
Os modelos de documentos normalmente são utilizados para agrupar dados relacionados diretamente no mesmo objeto ou entidade e fornecer indexação invertida ou full-text search, permitindo buscar por padrões em todo o documento sem se prender a um campo específico. Seus filtros são estruturados sobre atributos aninhados, agregações e pipelines de transformação, suportando indexação em campos internos de forma flexível e performática.

Seus usos mais comuns incluem implementações de catálogos de produtos, históricos de clientes, históricos de pacientes, agregadores de logs, armazenamento de crawlers e outros casos que exigem agregações, sumarizações e buscas desestruturadas. É comum que bancos de dados orientados a documentos sejam uma camada de consulta secundária após transformações de dados, sendo uma forma otimizada de consultas para implementações de CQRS.
Modelos Colunares (Column-Oriented)
Os modelos de dados colunares são inspirados em sistemas de Big Data e Data Warehouse. Os modelos transacionais, como apresentado no modelo de tuplas, organizam seus dados em formatos de colunas e linhas dentro de uma tabela. Todos os registros dessa tabela possuem o mesmo número de variáveis colunares. Caso seja necessário adicionar uma nova coluna para incluir um atributo, essa coluna será inserida em toda a tabela, adotando valores nulos ou default, caso definido no schema.
Em um banco colunar, cada coluna de uma tabela é armazenada de forma contígua em disco ou em memória, em vez de manter linhas inteiras juntas. Essa implementação permite que sistemas analíticos consigam analisar grandes volumes de dados em repouso e façam consultas e operações complexas e otimizadas em atributos específicos, por exemplo: média e desvio padrão dos valores de venda, idade de determinados segmentos de público, fechamentos contábeis de caixa e análise dos tipos de dispositivos móveis dos clientes, retornando-os de forma performática.
Modelos de Coluna Larga (Wide-Column)
Os bancos de dados wide-column ainda mantêm o conceito de linhas; porém, cada registro pode conter seu próprio conjunto de colunas.
Os dados são organizados em famílias de colunas agrupadas ao redor de chaves de linha. Para entender o agrupamento e a recuperação dos dados, uma linha pode ter um conjunto distinto de colunas agrupadas em “famílias de colunas”, e, quando se busca dados dessas colunas explicitamente via query, o sistema acessa apenas as linhas dentro dessas famílias. Isso é eficiente em cenários com dados dispersos, séries temporais, data warehouses e data lakes desestruturados e dispersos.
As implementações de databases wide-column são adaptadas para lidar com replicação e sharding de forma distribuída, com capacidade de escalar até milhares de nós, reduzindo pontos únicos de falha e oferecendo schemas altamente flexíveis, a custo de consistência eventual, além de apresentarem transações atômicas limitadas e joins restritos entre tabelas e famílias.
Modelos Key-Value (Chave-Valor)
Os bancos chave-valor, ou key-value, talvez sejam o tipo mais simples de bancos de dados NoSQL que podemos encontrar e trabalhar. Como o próprio nome sugere, eles armazenam seus dados em uma coleção de pares, sendo uma chave que funciona como um identificador único para o dado no conjunto e o valor, que pode estar em diversos formatos não estruturados, variando de simples strings, números, valores booleanos, JSON e até mesmo blobs complexos.

Os exemplos mais notáveis que temos são as engines de cache como Redis, Valkey e Memcached, mas, quando devidamente configurados e modelados, podemos encontrar implementações até mesmo em databases como MongoDB, DynamoDB, Elasticsearch etc.
Sua performance está embasada na extrema facilidade de indexação e recuperação dos dados, pois isso ocorre diretamente pela chave previamente composta e conhecida pelo cliente, permitindo facilmente uma replicação e distribuição para suportar grandes volumes de acesso e armazenamento, além da simplificação da forma de acesso, sendo realizado normalmente através de protocolos já bem estabelecidos diretamente via TCP/IP ou implementações RESTful, evitando a utilização de protocolos complexos.
Modelos Baseados em Grafos
Os bancos de dados baseados em grafos são tecnologias implementadas em estruturas onde o relacionamento entre as entidades é tão importante quanto o próprio dado em si.
Comparando com os modelos SQL, onde os relacionamentos são criados com chaves estrangeiras entre tabelas e JOINs gerados durante a consulta, os bancos de grafos aplicam o conceito de nodes (entidades) e arestas (relacionamentos) como objetos de primeira classe, permitindo relacionar vários tipos de dados entre diferentes entidades. Os dados são representados como propriedades chave-valor associadas aos vértices, e as arestas conectam esses vértices. Isso permite consultar, de forma performática, perguntas como “alunos da turma da manhã que moram no mesmo bairro e possuam média escolar maior que 8” ou “encontre amigos de amigos que vivem na mesma cidade e trabalharam na mesma empresa” sem a necessidade de joins custosos em diversas tabelas relacionais.
O uso dos bancos de dados baseados em grafos pode ser implementado para encontrar relacionamentos e proporcionar features de recomendação de produtos com base no comportamento de usuários similares, análise de redes sociais, modelagem de ameaças, detecção de fraudes e estudos de cadeias de valor e logística complexas. As consultas de um banco de grafos devem levar em conta o grau e a complexidade dos vértices, a seletividade de padrões e a cardinalidade de seus valores para construir padrões que minimizem leituras aleatórias de disco.
Armazenamento e Indexação
A forma como a engine de um banco de dados realiza seu armazenamento e indexação impacta diretamente o desempenho e a flexibilidade das operações de escrita, leitura e consultas complexas sobre os conjuntos de dados. O objetivo deste tópico é descrever as principais formas de indexação e armazenamento encontradas nas engines de mercado e seus principais trade-offs.
Sem a devida indexação, o banco de dados em questão precisaria escanear toda a tabela ou coleção para encontrar os dados desejados. Esta é uma operação extremamente lenta em tabelas grandes, inviabilizando uma escalabilidade saudável. Neste tópico, iremos explorar alguns conceitos comuns entre as implementações de bancos de dados que auxiliarão na compreensão dessas operações.
Page Size (Tamanho da Página)
O armazenamento em páginas em databases prevê que os dados serão organizados e armazenados em blocos de dados de tamanho fixo e configurável. Esses blocos, conhecidos como páginas, são usados por bancos de dados orientados a linhas — como a maioria dos relacionais e alguns não relacionais — que armazenam chunks de dados contendo múltiplas tuplas (linhas) dentro de cada página. Tamanhos comuns são 4 KB, 8 KB ou 16 KB, e essas páginas também contêm metadados para controlar relacionamentos e indexação.
O principal trade-off está no tamanho da página. Páginas maiores tendem a reduzir o número de operações de I/O necessárias para leituras de grandes volumes de dados ou para buscar múltiplos objetos fisicamente próximos, otimizando a leitura sequencial, já que mais informações são transferidas em uma única operação. Em contrapartida, elas aumentam o custo de transferência de dados em consultas simples, onde apenas alguns registros são necessários, pois a página inteira é lida desnecessariamente. Por outro lado, páginas menores minimizam a leitura de dados irrelevantes em consultas pontuais, mas geram um número maior de operações de I/O de disco para leituras extensas, pois mais páginas individuais precisam ser carregadas.
Diversos bancos de dados SQL e NoSQL aplicam o conceito de Page Size em conjunto com outros métodos de armazenamento e indexação. Exemplos notáveis incluem MySQL (InnoDB), MariaDB (InnoDB), PostgreSQL e SQL Server.
Indexação Colunar
A indexação por formato colunar, columnar format ou column-based indexing especifica padrões onde cada coluna de uma tabela é escrita em um segmento contíguo no sistema de arquivos. Essa separação, por mais contraintuitiva em termos de I/O, permite que as consultas sejam específicas ao nível de atributos recuperados, recuperando somente os componentes necessários que foram especificados. Nesse sentido, temos uma redução considerável de I/O ao otimizar pesquisas e processos analíticos. Esse cenário também facilita aplicar operações matemáticas diretamente nas consultas do banco.
Outro grande benefício é a compressão de dados. O formato colunar agrupa dados homogêneos (com pouca diversidade ou muitos valores repetidos) da mesma coluna, o que é ideal para a aplicação de algoritmos de compressão altamente eficazes, como a compressão por dicionários. Isso economiza espaço em disco e melhora ainda mais o desempenho de I/O.
Bancos de dados e engines otimizados para analytics, big data e data warehouses, como Amazon Redshift, Google BigQuery, MemSQL e SQL Server (modo Columnstore Index), utilizam essa arquitetura de armazenamento e indexação para alcançar alta performance em consultas complexas e analíticas.
LSM-Trees (Log-Structured Merge-Tree)
Os Log-Structured Systems, frequentemente implementados através do padrão LSM-Tree (Log-Structured Merge-Tree), aplicam modelos de dados que são salvos primeiro em tabelas em memória (memtables) e, posteriormente, exportados para arquivos imutáveis no disco (sstables), em um modelo de append-only.
O modelo append-only oferece extrema performance de escrita e baixa latência de confirmação do recebimento da transação, pois as operações são sequenciais (adicionadas ao final) e evitam ao máximo consultas aleatórias em disco. No entanto, ele não realiza atualizações in-place de registros. Em vez disso, novas “versões” do dado são inseridas como novos registros. Da mesma forma, a deleção de um dado é tipicamente realizada através da inserção de um registro especial chamado “tombstone”, que marca o dado como logicamente excluído. A remoção física dos dados antigos ou marcados com tombstone ocorre posteriormente, durante um processo de compactação (merge) dos sstables.
Esse tipo de cenário é ideal para sistemas que precisam garantir transações sequenciais e imutáveis para auditoria e rastreabilidade de modificações, pois mantém todas as versões anteriores do dado, que ainda podem ser recuperadas, se necessário. Isso permite a implementação de ledger tables, livros-caixa, registros de auditoria e rastreabilidade de transações financeiras, trace de operações de usuários em sistemas críticos, entre outros.
Engines de banco de dados como BigTable, DynamoDB, Apache Cassandra, InfluxDB e ScyllaDB implementam o modelo de LSM-Tree para otimizar sua escrita e indexação posterior, facilitando designs que priorizam alta performance de escrita e escalabilidade horizontal, muitas vezes em detrimento de uma forte consistência eventual.
As LSM-Trees funcionam organizando as operações de escrita em estruturas de memtables na memória, onde cada nova inserção ou atualização é registrada de forma sequencial e append-only, garantindo baixa latência na confirmação da transação. Periodicamente, essas memtables são descarregadas para o disco em arquivos sstables imutáveis. Durante esse processo, o sistema não bloqueia leituras nem escritas, permitindo um throughput alto mesmo sob cargas intensivas. A organização em camadas e a posterior compactação entre sstables reduzem a fragmentação e consolidam múltiplas versões de um mesmo registro, melhorando a eficiência de leitura e liberando espaço ocupado por dados obsoletos ou tombstones.
Para realizar operações de leitura, a engine primeiro consulta as memtables mais recentes e, em seguida, percorre os sstables em ordem de atualização, combinando os resultados conforme necessário. Esse modelo garante que a versão mais atual do dado seja retornada, mesmo que exista em diferentes níveis de armazenamento. A compactação periódica reúne sstables sobrepostos em um único arquivo, aplica a eliminação de tombstones e otimiza índices, reduzindo o número de arquivos a serem lidos. Dessa forma, as LSM-Trees equilibram alta performance de escrita com leituras consistentes, ao custo de um processo de manutenção (merge) que ocorre em segundo plano para consolidar os dados e manter a estrutura enxuta.
Indexação B-Tree (Árvores B)
A B-Tree (ou Árvore B) é uma estrutura de dados autobalanceada, projetada para gerenciar grandes volumes de informações armazenados em storage e volumes. Uma B-Tree é uma árvore multi-way, onde cada nó pode conter várias chaves e múltiplos ponteiros para outros nós. Essa característica permite que a árvore seja mais larga e menos profunda, otimizando o acesso a dados em disco, ao contrário de implementações de árvores binárias, que podem ter alta profundidade.
Os dados são armazenados de forma ordenada dentro dos nós, permitindo buscas, escritas, atualizações e deleções em tempo logarítmico. O armazenamento em B-Tree é construído para possibilitar que cada nó que contém uma parcela do dado seja alocado de forma eficiente em um bloco de disco. Isso minimiza a quantidade de operações de I/O, que costumam ser os maiores custos em bancos de dados de grande porte.
Quando você busca uma chave, o sistema carrega apenas os poucos blocos de disco necessários para percorrer o caminho do nó raiz até o nó onde a chave ou o ponteiro para o dado está localizado. Essa estratégia permite que, mesmo em tabelas gigantescas, as buscas sejam rápidas e com poucas operações.
Indexação por Hashing
A indexação baseada em hashing é uma técnica que permite localizar itens e valores em uma tabela através de valores exatos, ou exact matches. Ao contrário de estruturas como as B-trees (ou Árvores B+), que são otimizadas para buscas de intervalo (range queries) e minimizam operações de I/O de disco através de saltos logarítmicos, a indexação por hashing é projetada para buscas diretas e instantâneas.
Três conceitos fundamentais para a aplicação desse tipo de indexação são as funções hash, as tabelas hash e os buckets. Uma função hash é responsável por prover uma forma determinística e consistente de converter um dado (a “chave”) em um endereço numérico. Ou seja, aplicando a função hash sobre uma string como hash("fidelis"), ela resultaria em um identificador numérico para esse dado, como, por exemplo, 10. Se essa operação for repetida um milhão de vezes com a mesma entrada, o resultado deverá ser sempre 10. Esse valor numérico identifica o bucket específico na tabela hash onde o dado será armazenado ou procurado.
Em um contexto de resolução de colisões por encadeamento separado, um bucket não armazena um único dado, mas atua como um ponteiro para uma estrutura secundária, geralmente uma lista encadeada (ou, em implementações otimizadas, uma árvore binária balanceada para cadeias longas). Por exemplo, quando você calcula hash("fidelis") e o valor resultante aponta para o bucket 10 da sua tabela hash, o dado associado a “fidelis” será inserido nessa estrutura. Se esse bucket já contiver outros dados, é porque outras chaves, como hash("tarsila"), hash("sasha") e hash("saori"), também colidiram e resultaram no mesmo bucket 10. Ao inserir o valor de fidelis nessa lista, o dado referente será adicionado sequencialmente ao final dessa lista (ou inserido em ordem, se a lista for mantida ordenada internamente).
- Antes:
bucket[10] -> [ ("tarsila", "foo") -> ("sasha", "bar") -> ("saori", "ping") ] - Depois:
bucket[10] -> [ ("tarsila", "foo") -> ("sasha", "bar") -> ("saori", "ping") -> ("fidelis", "pong") ]
A busca pelo valor de uma chave específica também segue essa lógica. Quando precisamos recuperar o valor associado a uma chave, a mesma função hash é aplicada à chave, e o valor hash resultante aponta diretamente para o bucket exato onde o dado está armazenado. Isso possibilita que a engine do banco de dados recupere o dado de forma quase instantânea, realizando apenas uma breve travessia na pequena lista de dados localizada naquele bucket (no caso de colisões), sem a necessidade de múltiplas operações de leitura em disco.
Índices Invertidos
Os Índices Invertidos, ou Inverted Indexes, são estruturas de dados de busca que permitem encontrar documentos completos através de termos de busca específicos e dinâmicos, possibilitando executar processos de “full-text search” em grandes volumes de dados. Ao invés das estruturas convencionais que mapeiam um documento ou entidade para um valor ou termo, um índice invertido faz o trabalho oposto: ele mapeia termos, palavras ou tokens para os respectivos documentos onde aparecem, permitindo buscas em textos e valores longos por meio de termos simples. Essa técnica é característica de bancos orientados a documento, como Elasticsearch e Apache Solr, mas também pode ser implementada em bancos relacionais que possuam features de full-text search, como PostgreSQL, SQL Server e Oracle.
Esse tipo de estrutura facilita imensamente a implementação de engines de busca em dados desestruturados ou semiestruturados, como catálogos, listas de produtos de e-commerce, buscas por termos em contratos jurídicos e agregadores de logs. Imagine usar um motor de busca que precise escanear todos os atributos de todas as linhas de uma tabela em busca de padrões de texto: esse processo seria extremamente lento e custoso computacionalmente em grandes volumes de dados. Os índices invertidos resolvem isso. Eles funcionam como um catálogo de biblioteca ou arquivo de documentos: em vez de folhear cada livro para achar um termo específico, você consulta o catálogo — o índice invertido — que o direciona diretamente aos documentos que contêm aquela palavra, tornando a busca mais rápida e eficiente.
Por exemplo, em uma loja online, ao buscar por “geladeira verde 2 portas”, o índice invertido pode localizar rapidamente todos os produtos cujo campo de descrição (ou outros campos indexados) contenha as palavras “geladeira”, “verde” e “2 portas”, independentemente de como esses termos estejam dispostos ou em quais atributos do documento (seja um campo JSON ou uma coluna de texto) eles apareçam.
A construção de um índice invertido nas engines geralmente envolve uma pipeline de processamento no momento da gravação e indexação dos dados, incluindo: pré-processamento (normalização do texto), tokenização (divisão em tokens de palavras individuais) e, por fim, a criação do índice que lista todos os documentos em que cada token aparece.
Arquitetura
A escolha do banco de dados é uma representação direta da arquitetura do sistema. Sistemas distribuídos, no geral, envolvem escolhas que impactam diretamente o desempenho, disponibilidade, escalabilidade e consistência de uma parte ou do sistema como um todo. O delimitador do sucesso dessas escolhas é a tecnologia correta para a persistência, que deve levar em conta suas características e requisitos funcionais e não funcionais. A escolha equivocada de um banco de dados pode acarretar inúmeros problemas de performance e confiabilidade, caso não consideremos suas limitações. Dado isso, aqui listaremos os cenários mais comuns e sugestões iniciais para discussões de arquitetura.
Cenários Transacionais
Cenários em que precisamos realizar duas ou mais operações dentro de um banco de dados, envolvendo uma ou mais tabelas, caracterizam um ambiente transacional quando todas as operações devem ser concluídas em sua totalidade para garantir o sucesso da transação. Cada operação é tratada como um contrato: ou é concluída com sucesso e de forma integral, ou é revertida completamente, garantindo que o estado do domínio permaneça sempre válido e confiável para todos os consumidores na malha de dados. Esses cenários exigem consistência forte, permitindo leituras imediatas das últimas escritas.
Os cenários transacionais são ideais para funcionalidades críticas, como atualizações de saldo mediante o registro de uma transação ou ajuste de estoque em um e-commerce após compra e pagamento. Essas implementações demandam atomicidade e garantias ACID, e as implementações mais comuns são bancos relacionais que fornecem esse comportamento por padrão.
Os bancos transacionais normalmente são a fonte mais confiável para eventos de negócio, como criação de pedido, confirmação de pagamento ou registro de um novo cliente. A diretriz arquitetônica para essas engines não é a velocidade ou o volume, mas a integridade e consistência inquestionáveis dos dados, muitas vezes combinadas com camadas de cache (modelo chave-valor) ou CQRS para otimizar cenários de leitura intensiva, isolando a golden source transacional de picos de acesso sem comprometer sua disponibilidade.
A estratégia de indexação mais comum é a implementação de B-Trees, pois facilitam buscas rápidas em chaves primárias e índices secundários. Entretanto, as características atômicas acarretam maior latência em escritas, principalmente em cenários distribuídos: quanto mais réplicas, maior o tempo de commit, pois o dado precisa ser confirmado no quórum de nós antes de concluir a transação.
As soluções clássicas de bancos SQL escalam verticalmente sem impacto direto na latência de commit, porém exigem hardware cada vez mais caro. Iniciativas NewSQL escalam horizontalmente, mas pagam o preço de protocolos de consenso (Raft/Paxos), que adicionam latência e aumentam o consumo de rede e CPU entre os nós.
Cenários de Write-Intensive
Cenários Write-Intensive, ou escrita intensiva, são sistemas em que a taxa de escrita supera consideravelmente a de leitura. São aplicações que precisam ingerir volume contínuo e massivo de dados, garantindo que nenhuma informação seja perdida, mesmo abrindo mão de consistência forte e lidando com réplicas desatualizadas por períodos.
Exemplos incluem processamentos assíncronos corporativos, agregadores de logs, captação de dados de IoT e feeds de redes sociais. Para suportar alta taxa de escrita, a arquitetura geralmente adota NoSQL, projetado para escalabilidade horizontal e escritas rápidas. Internamente, usam modelos append-only (LSM-Trees) e replicação assíncrona.
Diferente das B-Trees, que podem exigir I/O custoso para escritas e atualizações, as LSM-Trees transformam cada escrita em operação sequencial de append, armazenando em memória e, depois, em disco de forma organizada, sem bloquear a solicitação até a confirmação nos nós. Essa arquitetura favorece consistência eventual, pois o sistema não espera replicação completa antes de responder ao cliente. Engines otimizadas para esse cenário incluem DynamoDB, Cassandra e ScyllaDB. Implementações on-premises permitem ajustar o quórum entre latência, disponibilidade e consistência.
Cenários de Read-Intensive
Cenários Read-Intensive, ou leitura intensiva, possuem necessidades inversas aos Write-Intensive, sendo ambientes onde a quantidade de leituras se sobressai sobre as escritas. O objetivo é maximizar o throughput de consulta e minimizar latências de leitura. Exemplos: feeds de redes sociais, catálogos de produtos, listagens de usuários e consultas de endereços.
Podemos realizar uma combinação de diversos métodos que iremos aprofundar em outros textos. Réplicas asseguram escalabilidade de leitura, permitindo que os nós escalem horizontalmente de forma dinâmica. As otimizações mais comuns combinam um banco primário consistente (por exemplo, PostgreSQL ou MySQL) com réplicas de leitura e camadas de cache (Redis, Memcached). Também podemos realizar processos de CQRS para otimizar dados capturados em um caminho otimizado para escrita e convertê-los em modelos otimizados para leitura.
Referências
Banco de dados NoSQL, SQL e NewSQL: diferenças e vantagens
NoSQL vs NewSQL vs Distributed SQL: A Comprehensive Comparison
SQL, NewSQL, and NOSQL Databases: A Comparative Survey
Clash of Database Technologies: SQL vs. NoSQL vs. NewSQL
Wide-column Database Definition FAQ’s
Pages and extents architecture guide
Choosing a Large or Small Page Size
Índices columnstore: visão geral
Row-based vs. Column-based Indexes
Understanding Hash Indexing in Databases
Understanding Inverted Indexes: The Backbone of Efficient Search
What is Time Series Database (TSDB)?
Sequential Consistency In Distributed Systems
