
System Design - Estratégias de Deployment

Mais um texto rápido da série de System Design. O objetivo deste artigo é abordar, conceitualmente, os principais termos que envolvem as técnicas de deployment e entrega de software. O objetivo não é apenas dizer “o que cada um dos termos significa” entre os modelos de deployment que considerei mais importantes, mas explicar “o porquê” de eles existirem e quais são os reais benefícios da adoção dos mesmos em projetos reais.
Definindo um Deployment

O termo “deployment” vem de uma origem militar, onde os mesmos usavam para descrever o ato de disponibilizar tropas, recursos e equipamentos em locais estratégicos antes de iniciar as devidas operações. Dentro da engenharia de software, o Deployment, ou implantação, é um termo usado para designar o ato de disponibilizar uma versão de uma aplicação em um ambiente predefinido para ser testado, avaliado ou disponibilizado para os clientes utilizarem.
O deployment pode ser realizado em diversos contextos e recursos, sendo usado para distribuir itens de infraestrutura, configurações e versões de aplicações novas ou já existentes. O deployment, quando realizado de forma moderna, é estruturado em dois momentos que podem coexistir por meio de pipelines, que são o CI, Continuous Integration, ou Integração Contínua, e o CD, Continuous Delivery, ou Entrega Contínua.
Rollbacks de Versões
Mais importante do que entregar rapidamente é conseguir reverter uma versão com agilidade, caso um comportamento inesperado seja detectado. O processo de rollback ocorre quando, por meio de processos automatizados ou manuais, precisamos cancelar um deployment e retornar a uma versão anterior.
Existem diversas estratégias que podem ser adotadas para garantir excelência operacional, permitindo validar, promover ou reverter versões de forma eficiente. A maturidade dos processos de rollback é fundamental para sistemas críticos e deve estar integrada a todos os modelos de deployment.
Estratégias de Deployments
Após explicar conceitualmente os principais componentes de um fluxo de integração e entrega contínua, podemos avançar para a explicação dos principais modelos de deployment, abstraídos de ferramentas específicas. O objetivo não é apenas detalhar como eles devem ser executados, mas, principalmente, esclarecer por que existem e quais tipos de problemas cada um resolve.
Isso permitirá uma análise clara das necessidades de cada produto, garantindo que os times de engenharia tenham uma base sólida para decidir o melhor modelo de deployment para cada cenário.
Para exemplificar com exemplos do mundo real, imagine-se em uma padaria renomada e tradicional, onde você é o responsável pela panificação. Vamos desenvolver em torno desse exemplo para ilustrar o objetivo de cada um dos tipos de deployment apresentados.
Big Bang Deployments
Os Big Bang Deployments, ou Recreate Deployments, são estratégias que recriam todo o sistema de forma abrupta e simultânea. Embora essa abordagem possa parecer brusca e drástica, ela se torna necessária em cenários onde não é possível, de forma alguma, conviver com duas versões simultâneas do mesmo sistema ou quando uma transição gradual seria mais prejudicial do que uma indisponibilidade temporária até a reestabilização do serviço.
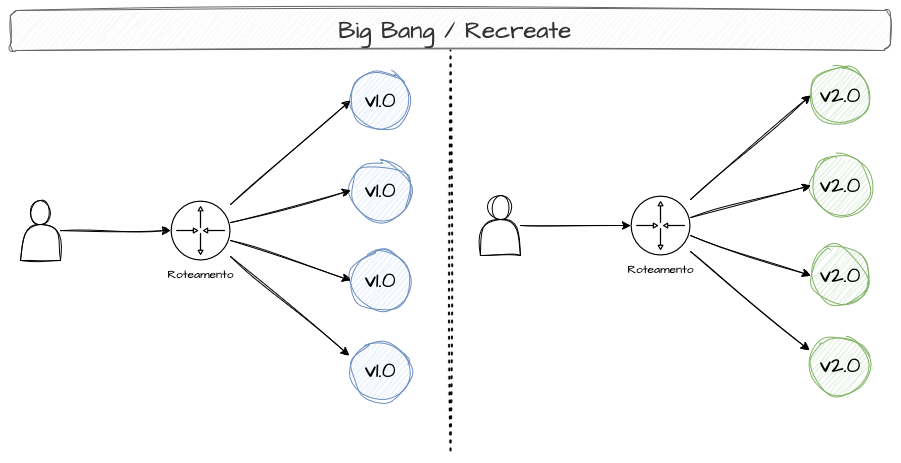
Esse tipo de estratégia pode ser necessário em aplicações que utilizam padrões de leasing, como consumidores de Kafka, onde a constante alternância de consumidores em um tópico pode gerar operações de rebalanceamento, afetando significativamente a performance do consumo. Nesses casos, a recriação total do sistema pode ser mais viável do que uma atualização progressiva. Além disso, esse modelo pode ser útil quando há necessidade de trocar esquemas de banco de dados ou modificar contratos de comunicação.
Imagine que você precisa testar uma nova farinha para os pães de sua padaria e decide fazer isso logo na primeira fornada da manhã. Assim que o dia começa, toda a panificação passa a ser realizada de uma vez com a nova marca de farinha, abrindo as portas para atendimento dos clientes já com a receita nova, sem chance para validação ou experimentação prévia.
Esse padrão só deve ser considerado viável quando as aplicações envolvidas adotam modelos de comunicação assíncrona e operam com consistência eventual.
Vale ressaltar que essa abordagem deve ser utilizada apenas como último recurso, seja nos exemplos citados ou em outros contextos, sempre com muito cuidado e parcimônia. Embora operacionalmente seja mais simples, por não exigir mecanismos de controle para progressão e validação, ela adiciona um alto nível de risco para o cliente.
Rolling Updates
Os Rolling Updates são, possivelmente, o tipo mais comum de deployment. Esse modelo promove uma atualização gradual da versão de um serviço, iniciando novas réplicas e, assim que estiverem estáveis, desligando as versões anteriores. Essa abordagem permite que o sistema continue operando, com parte das instâncias ainda executando a versão antiga, enquanto outras já utilizam a nova versão.
Se uma aplicação possui 10 réplicas, podemos configurar os Rolling Updates para atualizar uma a uma, duas a duas e assim por diante. Assim que a nova réplica estiver ativa e operando corretamente, o fluxo de progressão continua até que 100% das réplicas tenham sido atualizadas.
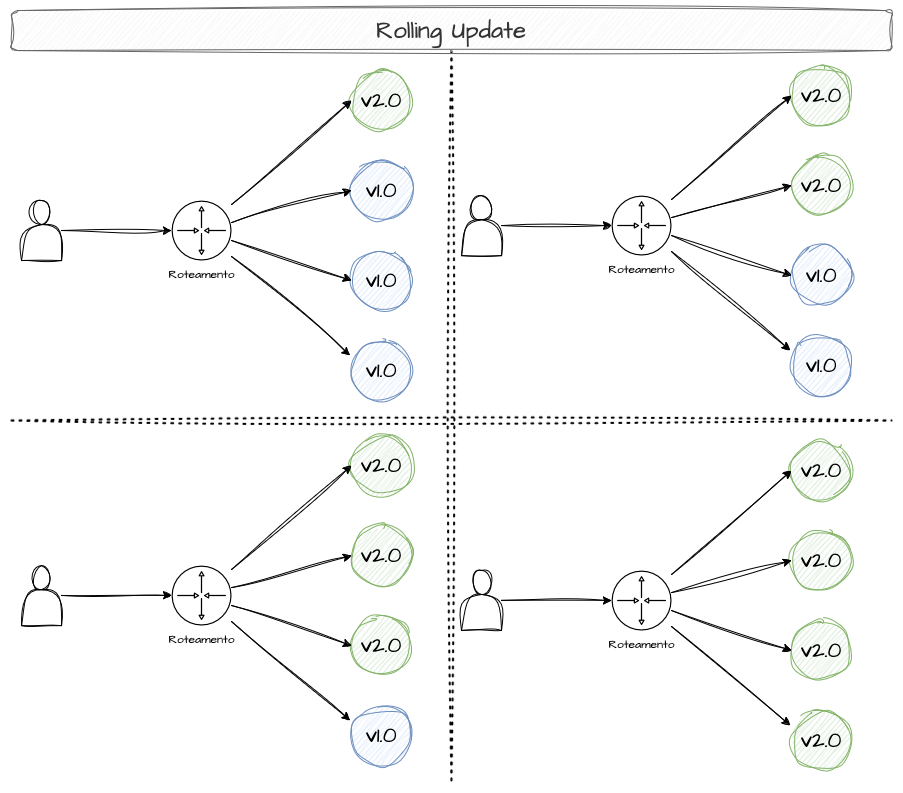
Ilustrando, imagine que você quer mudar a receita dos pães franceses da padaria. Numa estratégia de rolling update, conforme as unidades de pães forem sendo compradas pelos clientes e espaços forem surgindo para novas fornadas, o estoque vai sendo substituído pelos novos pães que foram feitos usando a nova receita, até que toda a prateleira seja substituída pelos pães da nova versão.
Embora os Rolling Updates promovam uma atualização escalonada, não há validações intermediárias entre as iterações. Ou seja, a única verificação realizada é se as aplicações estão em execução e passaram por um health check básico. Não há controle refinado sobre o direcionamento do tráfego nem mecanismos para validar previamente a nova versão. Esse tipo de limitação pode exigir abordagens mais estratégicas e com um maior nível de tecnologia envolvida.
No caso da padaria, caso os clientes levem o pão para casa, estranhem ou não gostem, não terão mais acesso aos pães feitos com a receita anterior.
Blue-Green Deployments
O Blue/Green Deployment é uma estratégia de deployment que visa buscar o “zero downtime” durante releases de novas versões e garantir o rollback rápido, caso necessário, assegurando alta disponibilidade durante o rollout de novas versões.
O modelo Blue/Green é uma estratégia que permite realizar releases de novas versões com segurança e garantir um rollback rápido, caso necessário, assegurando alta disponibilidade durante o rollout de novas versões.
Voltando ao exemplo da receita de pão, imagine que você tem uma fornada ativa com a receita anterior, da qual os clientes estão comprando da prateleira, e essa versão ainda está em vigor na produção da cozinha. Para substituir os pães que os clientes consomem, é necessário produzir o pão na mesma escala e quantidade, de modo a testar não apenas a receita em si, mas também toda a produção, os equipamentos e a logística de panificação. Esse novo lote de pães, feito com a receita em validação, é apreciado pelos funcionários da padaria, que dão suas impressões. Caso todos aprovem, os pães na prateleira são substituídos por essa nova fornada, permitindo que os clientes passem a comprá-los. Por segurança, a versão antiga permanece em estoque para que, caso alguém reclame, seja possível levar para casa a versão anterior e o processo de produção retorne à receita antiga nas próximas fornadas.
Esse modelo recebe essa denominação porque consiste em disponibilizar dois ambientes idênticos, divergindo apenas na versão do componente atualizado. O termo “Blue” identifica a versão estável que está em uso produtivo, sendo consumida pelos usuários do sistema, enquanto o termo “Green” representa a versão mais recente, candidata a substituir a versão estável.
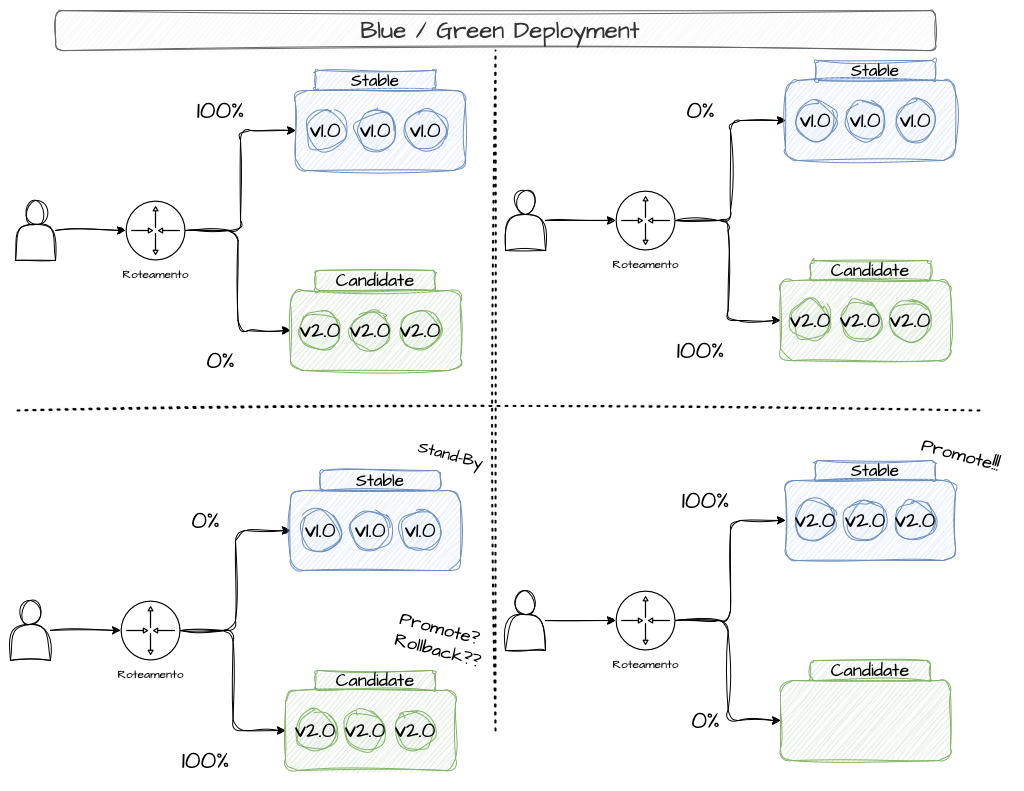
Essa abordagem permite que testes sejam executados na nova versão sem impactar o fluxo produtivo, tornando possível a execução de warm-ups das réplicas, a realização de smoke tests e a aplicação de validações automáticas ou manuais antes da promoção da versão, garantindo maior segurança no processo.
Quando a nova versão “Green” está pronta e testada, o tráfego de produção é redirecionado do ambiente Blue para o Green. Esse redirecionamento geralmente ocorre de forma instantânea, utilizando um Load Balancer ou um mecanismo de roteamento de DNS.
É comum que o ambiente Blue anterior permaneça ativo por um tempo para garantir um retorno rápido em caso de falha não detectada nos testes anteriores. Se algum problema for identificado na nova versão, o tráfego pode ser rapidamente revertido para o ambiente Blue, minimizando o impacto da release para os usuários.
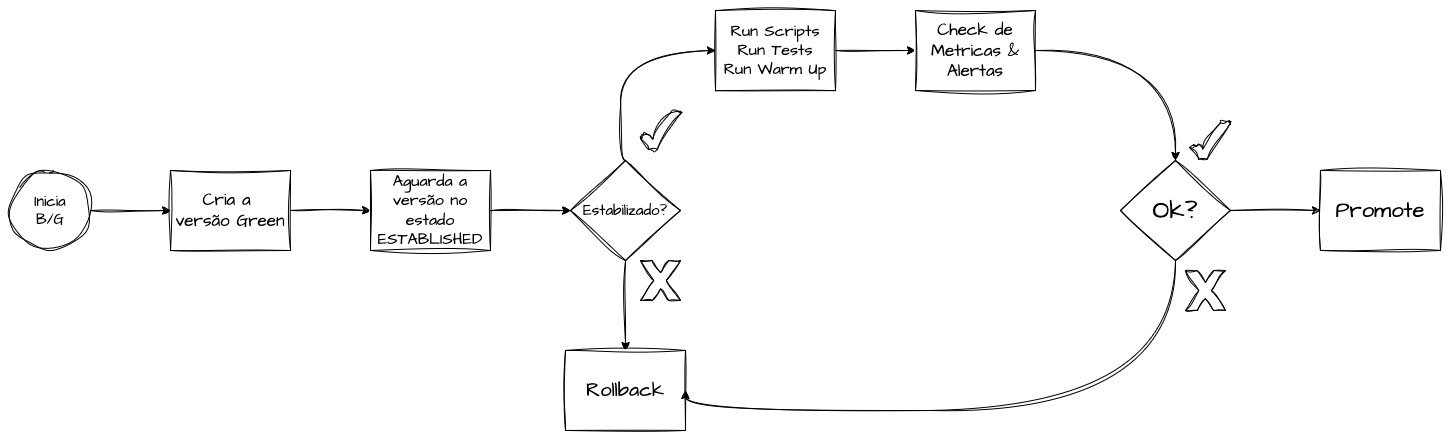
Para tirar o maior proveito possível do modelo Blue/Green, é essencial utilizar mecanismos que permitam realizar testes com segurança antes da promoção para os clientes finais. Dessa forma, podemos garantir, de forma manual ou automatizada, que as principais funcionalidades estão operando corretamente e que nenhum limite de erros ou tempos de resposta foi excedido na nova versão.
Por outro lado, manter um ambiente Blue/Green por longos períodos pode ser oneroso, especialmente em sistemas grandes e complexos.
O principal desafio desse modelo não está na gestão da versão do software em si, mas na migração e atualização de esquemas de dados. A sincronização entre versões de schema tende a ser a parte mais complexa de qualquer deployment moderno, especialmente no que diz respeito à gestão de rollback. Alterações no schema que tornem a versão Blue incompatível não são incomuns, e reverter essas mudanças em caso de falha pode ser um processo extremamente custoso e trabalhoso.
Canary Releases
O Canary Release, ao contrário do Blue/Green, que busca uma implantação direta após certas validações prévias, é um processo de implantação gradual, no qual mantemos duas versões da mesma aplicação em operação, mas apenas uma pequena porcentagem do tráfego ou dos clientes é direcionada para a nova release. O tráfego de produção é dividido entre a versão antiga da aplicação (chamada de stable) e a nova versão (chamada de canary).
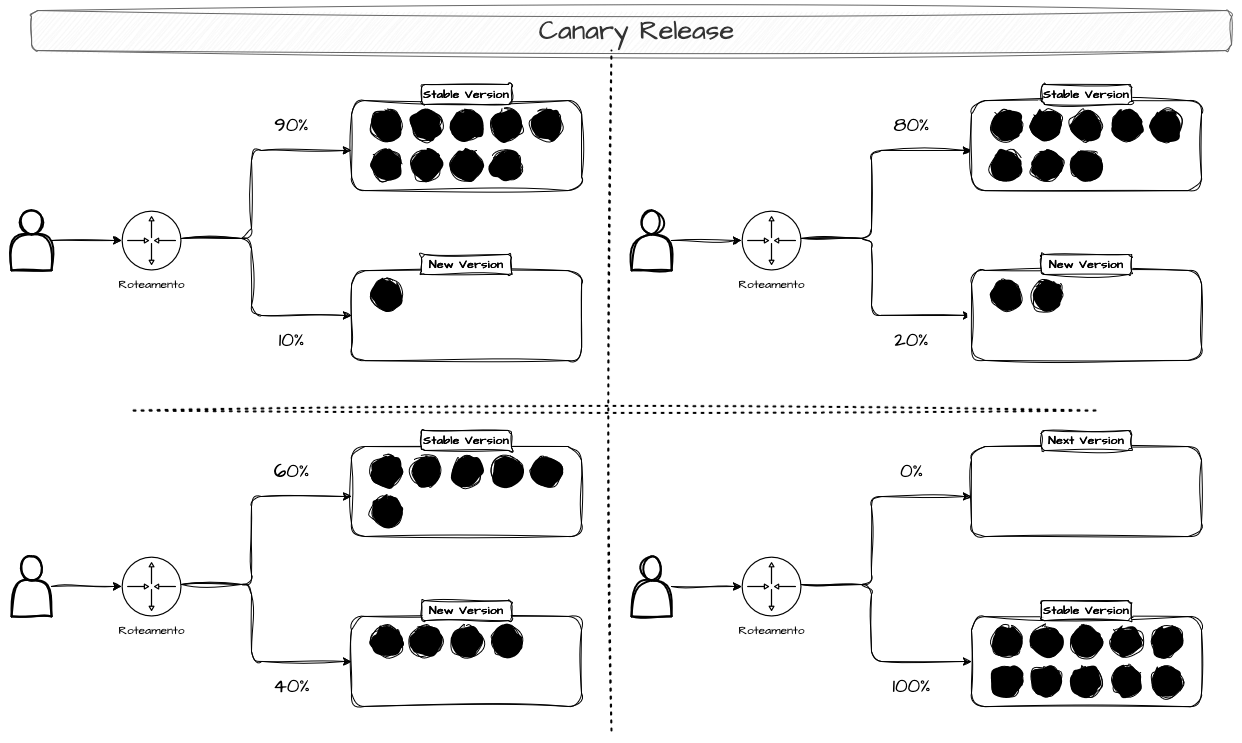
O Canary Release incrementa porcentagens seguras de tráfego para a nova versão, a fim de testar a versão canary com parte do tráfego real, aumentando essa participação gradualmente ao longo do tempo ou após determinadas validações. É fundamental que mecanismos de rollback sejam implementados, permitindo que o canary seja cancelado e a versão anterior restaurada a qualquer momento, seja manualmente ou por decisão de um mecanismo de validação automatizado. Após a confirmação de que a nova versão está estável, segura e atendendo aos critérios estabelecidos, todo o tráfego de produção é direcionado para ela, substituindo a versão antiga. Dessa forma, promovemos a versão canary para stable e preparamos o ambiente para o próximo rollout.
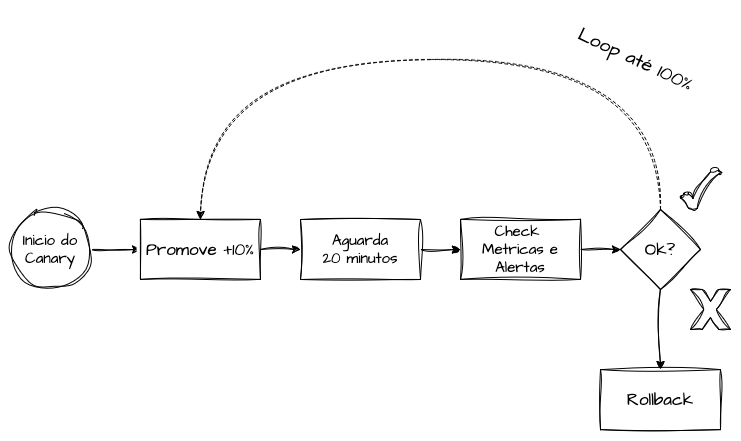
A maneira mais moderna e eficiente de orquestrar a progressão do tráfego no canary é associar o aumento das porcentagens a checagens de métricas, alertas e testes sintéticos, que podem ser executados durante o deploy para validar se o processo está ocorrendo de forma segura.
Imagine que você é um padeiro de uma padaria tradicional da sua cidade. A receita do seu pão é extremamente padronizada e já tem o seu público firmado. Para validar algum processo, ingrediente ou novas proporções, você começa a inserir uma pequena porcentagem de pães com a receita nova junto à receita tradicional todos os dias. Conforme você vai coletando feedbacks e impressões dos clientes, ou acostumando o paladar deles à nova receita, vai adicionando cada vez mais pães da receita nova nas fornadas e acompanhando, com calma e atenção, como os clientes reagem à mudança. Esse processo pode demorar semanas ou meses, até que toda a receita seja substituída nas fornadas, garantindo que a mudança resulte em pães melhores. Se, durante esse processo, os clientes que receberam os pães novos reclamarem, as unidades podem ser substituídas pela versão antiga ou, estrategicamente, você pode optar por retornar à versão antiga de forma total.
Mais importante do que acelerar a progressão do canary é garantir a possibilidade de rollback rápido. Durante o período em que o Canary Release está em operação, métricas essenciais podem ser monitoradas para verificar se tudo está ocorrendo conforme esperado, incluindo latência, taxa de erros e métricas customizadas que reflitam a operação do produto. A importância dessas métricas como indicadores facilita a automação tanto da progressão quanto do rollback do canary, garantindo segurança e confiabilidade no processo.
Migrations e Versionamento de Schemas
As Data e Schema Migrations são estratégias utilizadas para gerenciar mudanças em bancos de dados de forma segura, controlada e com o mínimo de impacto possível em aplicações em produção.
Elas são particularmente importantes em ambientes cloud-native e distribuídos, onde a atualização de dados e esquemas precisa ser feita de maneira gradual e resiliente.
Refere-se à alteração da estrutura do banco de dados, como adicionar, modificar ou remover tabelas, colunas, índices ou chaves.
Pode gerenciar a alteração dos próprios dados armazenados no banco de dados, como transformar, mover ou limpar registros.
Shadow Deployment e Mirror Traffic
O Shadow Deploy, também conhecido como Versão de Sombra, Mirror Traffic ou Shadow Traffic, é uma estratégia avançada de validação de novas versões. A ideia consiste em enviar uma cópia de uma porcentagem do tráfego para uma nova versão temporária e limitada, permitindo testar o comportamento da aplicação ou da infraestrutura sem impactar os usuários.
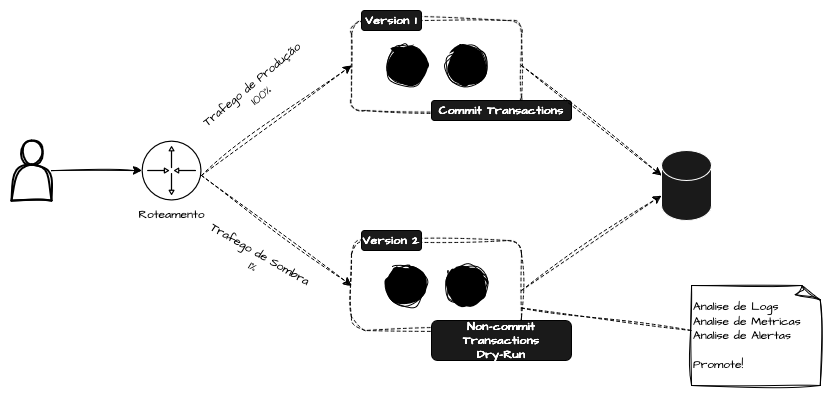
Esse tráfego é processado inteiramente pela nova aplicação, porém sua resposta não é enviada para o cliente. Tudo o que for espelhado não deve afetar, de nenhuma forma, a experiência do usuário. No Traffic Mirroring, a duplicação do tráfego ocorre em tempo real e normalmente é configurada em camadas mais baixas, como proxies reversos, sidecars ou service meshes, que adicionam esse comportamento diretamente na camada de rede.
Nesse processo, uma parte do tráfego real é duplicada e enviada para uma versão alternativa do sistema, que processa as requisições em paralelo, mas sem retornar os resultados para os clientes. É importante ressaltar que esse tráfego é duplicado, e não dividido, garantindo que as requisições sejam direcionadas para a nova versão sem interferir na produção. Isso permite que a versão prévia seja analisada antes de iniciar a progressão para outras estratégias de deployment, como Canary e Blue/Green, funcionando como um passo anterior ao início do deployment real. Dependendo do contexto, essa abordagem pode ser combinada com qualquer uma das estratégias já abordadas.
Esse modelo se encaixa perfeitamente em aplicações que não realizam operações de escrita, pois espelhar o tráfego diretamente poderia resultar na duplicação de registros e gerar inconsistências na camada de dados. Uma solução para esse problema é executar o ambiente shadow no modo “dry-run”, onde todo o fluxo é simulado, mas sem que nenhuma operação seja efetivamente confirmada dentro das transações. Isso possibilita a validação de grande parte da experiência da aplicação sem causar efeitos adversos.
1
2
3
4
5
if os.Getenv("ENVIRONMENT") == "shadow" {
tx.Rollback()
} else {
tx.Commit()
}
Esse deployment limitado pode ser analisado por meio de métricas e logs antes que o time tome uma decisão sobre a progressão do deployment. A grande vantagem dessa estratégia é que ela pode ser combinada tanto com Blue/Green quanto com Canary Releases.
Um shadow deployment com mirror traffic pode ser iniciado antes do Canary Release ou do Blue/Green, permitindo uma pré-validação antes de promover qualquer versão para os clientes ou realizar um provisionamento mais agressivo de infraestrutura.
Outro ponto crucial a ser considerado é a idempotência, tanto dentro quanto fora da capacidade de dry-run e da versão de sombra, para evitar duplicidades ou operações adicionais inesperadas.
Feature Flags
As Feature Flags, ou Feature Toggles, são técnicas que permitem o rollout de novas funcionalidades de forma controlada, possibilitando a ativação ou desativação dinâmica de certas features sem a necessidade de alterar o código-fonte ou realizar novos deployments. Para que a funcionalidade esteja disponível, é necessário um deployment, porém, sua liberação ocorre com a flag desligada. À medida que determinados clientes são selecionados para experimentar a nova funcionalidade, a flag é ativada de forma controlada.
Elas são amplamente utilizadas para gerenciar lançamentos, controlar funcionalidades em produção e conduzir experimentação controlada. Um exemplo clássico é habilitar uma nova versão da interface de um sistema apenas para uma pequena porcentagem de usuários, monitorando o feedback e comparando métricas com aqueles que ainda utilizam a versão antiga.
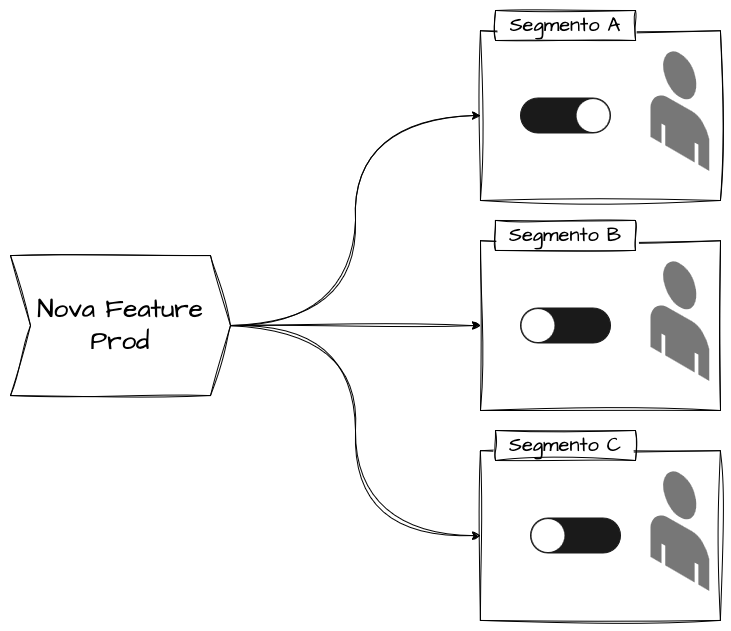
Feature Flags dependem de componentes centralizados para controlar a distribuição das funcionalidades, podendo ser gerenciadas por ferramentas de mercado ou backoffices administrativos que alteram flags armazenadas em bancos de dados, entre outras soluções.
Sistemas que segmentam clientes por categorias — como Pessoa Física e Pessoa Jurídica, ou setores como Varejo, Agropecuária, Mídia, Assinaturas e Serviços — podem utilizar Feature Flags para testar funcionalidades de forma controlada entre diferentes grupos de usuários.
O uso de Feature Flags pode ser estendido para times de negócio e produto, permitindo que eles validem novas funcionalidades diretamente com os clientes, sem depender da intervenção dos times de engenharia. Na nossa padaria, isso pode significar alguns clientes de confiança, para os quais você pode avisar que está validando algo novo em sua receita e direcionar esse produto pontualmente, a fim de coletar impressões e feedbacks antes de expandir a produção para pessoas com as quais você não tenha uma certa proximidade.
Clustering e Segregação de Segmentos
Uma técnica interessante que viabiliza a segregação de clientes por meio de características conhecidas é aplicar uma estratégia de algoritmo de clustering. Conhecendo uma base de dados prévia de características dos clientes, como segmento, volume, região, faturamento e períodos de uso, podemos agrupar essas informações e aplicar algoritmos como o k-means nessas variáveis, criando clusters de assimilação, facilitando as técnicas de feature flags e sharding, agrupando em bases cadastrais lógicas os clientes e usuários que mais se parecem entre si.
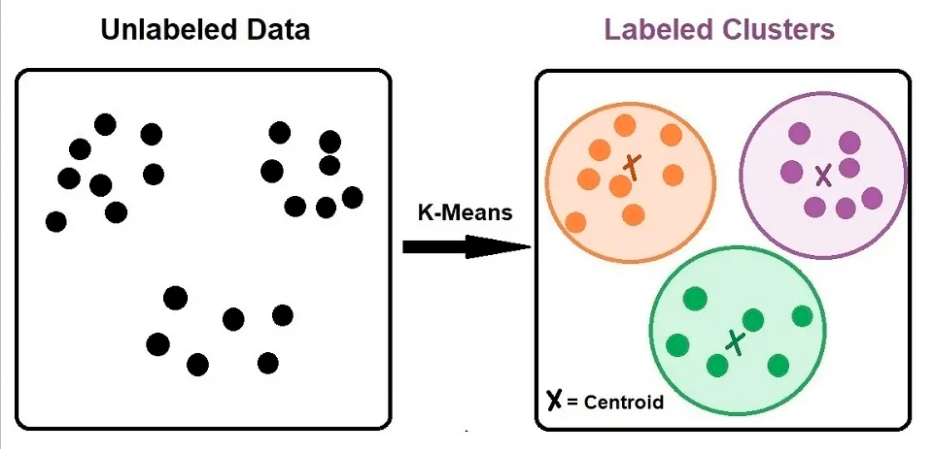
Aplicar estratégias de clustering na prática permite alocar esforço operacional e realizar o deployment de versões de forma segmentada, minimizando riscos, podendo ser feito em clusters menos críticos e habilitando a liberação de funcionalidades de acordo com o perfil do cliente, melhorando a experiência de testes e pilotos.
Na padaria, podemos selecionar os clientes por grupos similares, como idosos, jovens, pais e mães com muitas crianças em casa, clientes mais tradicionais, clientes mais experimentativos e, quando precisarmos testar uma versão nova da receita dos pães ou algum outro tipo de bolo ou salgado, podemos direcionar as recomendações e produtos para esse grupo específico.
Sharding Deployment
O tema de Sharding e Particionamento já foi abordado anteriormente sob as perspectivas de dados, computação e segregação de clientes. Aqui, seguimos os mesmos princípios. Utilizando chaves de partição bem estruturadas e definidas, podemos subdividir nossas infraestruturas de forma isolada e direcionar os clientes para esses shards de maneira consistente. Isso permite expandir as capacidades de deployment para shards menos prioritários, ambientes de teste ou pilotos, validando novas versões de forma parcial com apenas uma fração dos usuários e clientes.
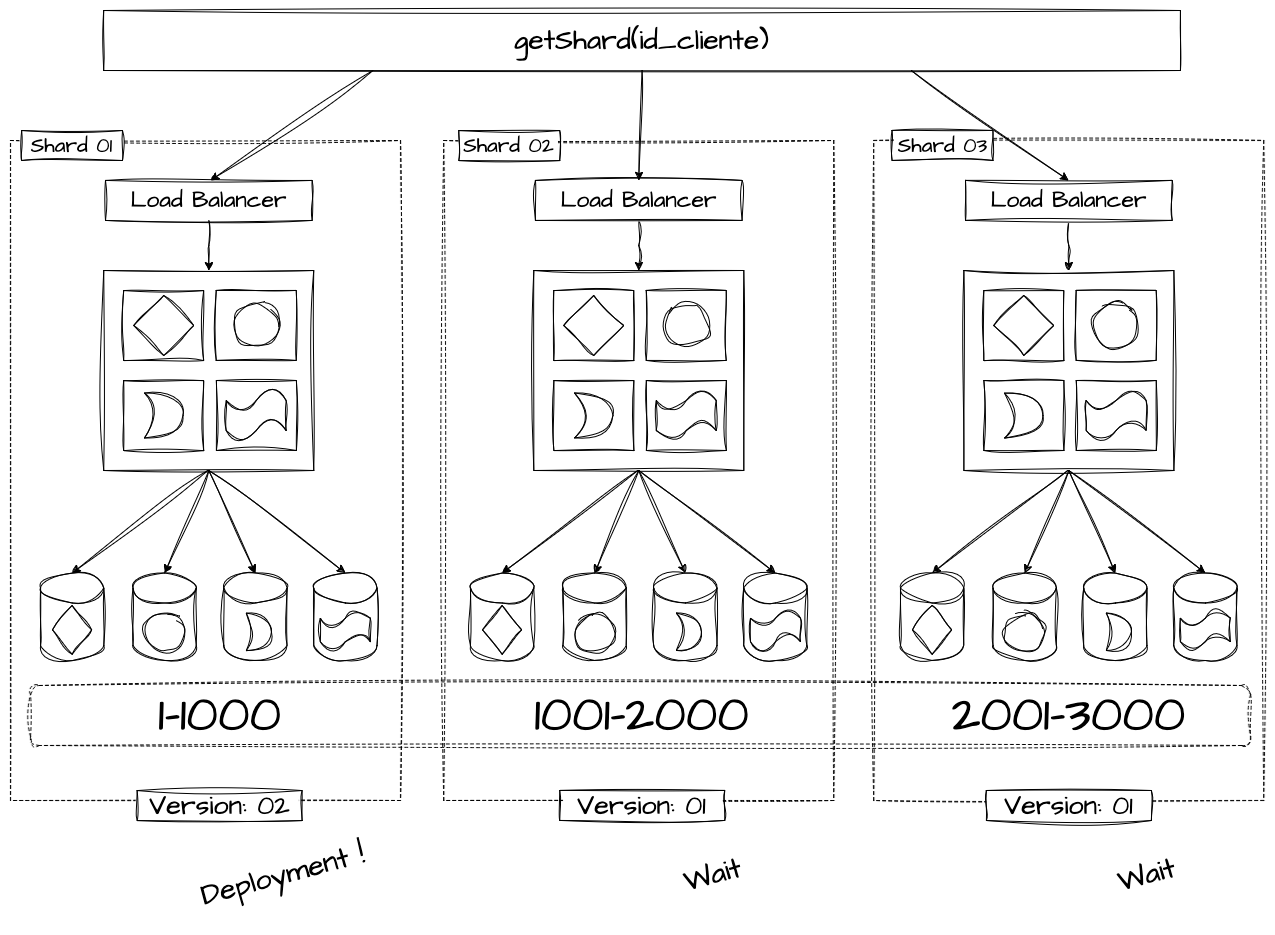
Essa abordagem é amplamente utilizada em arquiteturas multi-tenant, possibilitando a propagação controlada de novas versões para subconjuntos específicos de clientes, em vez de toda a base de usuários. Dessa forma, uma eventual falha não se espalha para o sistema inteiro, reduzindo o impacto e facilitando a mitigação de problemas.
No entanto, essa estratégia é altamente avançada e exige um planejamento rigoroso de capacidade e custos, pois tende a aumentar os gastos financeiros e operacionais, uma vez que envolve a replicação de componentes básicos da infraestrutura para isolar corretamente as cargas de trabalho.
Em padarias que atendem outros estabelecimentos, ao invés de clientes gerais, podemos experimentar modificações e receitas em empresas e encomendas específicas, oferecidas de forma clara ou não. Dessa forma, caso algo dê errado na produção, podemos garantir que o ocorrido não se deu em clientes que encomendam quantidades maiores e mais recorrentes.
Referências
Pros and Cons of Canary Release and Feature Flags in Continuous Delivery
Achieve Continuous Deployment with Feature Flags
SRE Workbook - Canarying Releases
What is blue green deployment?
What Is Blue/Green Deployment and Automating Blue/Green in Kubernetes
Advanced Traffic-shadowing Patterns for Microservices With Istio Service Mesh
Glossary CNCF - Blue Green Deployment
